
基于SSA-LightGBM的交通流量调查数据趋势预测①
2021-01-22 05:43孙朝云杨荣新
计算机系统应用 2021年1期
徐 磊,孙朝云,李 伟,杨荣新
(长安大学 信息工程学院,西安 710064)
随着国民经济的发展,我国机动车数量快速增长,道路拥堵时常发生,高速公路作为我国公路的楷模,其服务水平比一般的道路更好.交通流量调(交调)数据是研究高速公路通行能力的重要参考指标,为了提高高速公路的服务水平,对高速公路进行更好的整修和养护,亟需加强对交调数据的预测研究.
预测研究的关键在于预测模型的建立,提高预测结果精准度的重要方法便是选择合适有效的预测模型.序列预测通常分为时间序列预测和多元回归预测,目前在国内外研究中,大多是通过传统的神经网络方法对序列进行预测.例如,Zhou 等人针对传统数学统计方法的局限性等问题建立BP 神经网络预测模型,通过将BP 算法与指数平滑和线性回归方法进行比较,最后证明了BP 算法预测结果能为企业制定库存计划提供更好的建议[1].成云等人针对现阶段城市道路交通流预测精度不高的局限性,提出了一种基于差分自回归滑动平均和小波神经网络组合模型的预测方法来进行交通流预测,最后证明了组合模型可以提高交通流预测精度[2].Zhang 等人为了更准确的预测交通流量,实现交通控制和交通拥堵管理,提出了一种基于XGboost和LightGBM 算法的组合预测模型,实验结果表明组合模型比单个模型有更高的预测精度[3].Wu 等人针对2008-2018年云南省货运数据及其影响因素建立了灰色神经网络模型,对云南的货运量进行了预测,并将其与BP 神经网络预测结果进行比较最后证明了灰色神经网络具有更好的预测效果[4,5].Li 等人考虑到植物蒸腾量对温室自动灌溉具有重要的作用,在2020年建立了随机森林回归模型,通过整合植物和环境参数建立植物蒸腾量预测模型,该研究为温室种植蔬菜高效生产和智能灌溉提供了科学参考,为节约水资源也提供了一种有效途径[6].
上述方法中无论是采用单纯的数学模型还是采用机器学习模型对长期的周期性比较强的数据均不能实现精准预测,只能粗略的显示数据的大致走向,局部详细的信息表现较差,因此本文考虑到高速公路交调数据具有很强的周期性等特点提出了基于SSA-LightGBM的预测模型.
1 研究数据选取及算法流程
本文针对陕西省高速公路展开研究,对韩城高速公路进行实地考察调研,以韩城高速7~8月1344 条交调数据进行研究.
1.1 数据介绍
表1为韩城高速交调数据表(前5 行数据).从表中可以看出交调数据一共由观察日期、小时、观测站名称、观测里程、中小客流量、大客车流量、小货车流量、中货车流量、大货车流量、特大货车流量、集装箱流量组成.

表1 韩城高速交调数据表
为了使不同交通工具组成的交通流能够在同样的尺度下进行分析,使其具有可比性,在分析计算通行能力和服务水平时,需要将各类车辆交通量换算成标准机动车当量,需要用到车辆换算系数,如表2所示,这里只考虑汽车,将其分为3 档:小型车、中型车、大型车,其中小型车又分为中小客车和小型货车,折算系数为1;中型车分为大客车和中型货车,折算系数为1.5;大型车分为大型货车、特大货车和集装箱车,大型货车折算系数为3,特大货车和集装箱车折算系数为4.

表2 折算系数参考表
1.2 数据展示
通过对韩城高速交调数据进行换算,如图1对机动车当量进行可视化,展示了2019年7月1日-2019年8月25日韩城高速公路交调数据当量变化.从图中可以清晰的看出除了少数天呈现极小或者极大的情况,其他天数整体呈现周期状态.当量=小型车×1+中型车×1.5+大型货车×3+特大货车×4+集装箱车×4.

图1 韩城高速交调当量变化图
1.3 算法流程图
本文的算法流程图如图2所示对原始数据进行整合,计算出高速公路交调数据机动车当量,然后对原始数据利用奇异普分解方法(SSA)进行数据分解,得到周期信号和随机信号,再利用机器学习模型(LightGBM)对随机项进行预测,将预测结果和周期延伸信号结合得到最终的预测结果.另一方面利用XGBoost、LightGBM等单独的机器学习方法对当量数据进行预测,最后将预测结果同SSA-LightGBM 方法得到的结果进行对比分析,比较不同模型的预测效果.

图2 算法流程图
2 SSA-LightGBM 预测模型原理
2.1 奇异谱分解(SSA)
奇异谱分解(Singular Spectrum Analysis,SSA)是通过分解原序列中的时间主分量,得到不同层次上的分量序列,然后将分解出来的低频视为序列变化的长期趋势,最终得到数据序列的最佳谐波个数,以此确定时间序列的周期信号.
本文将奇异谱分解分为4 个步骤,分别是:
(1)嵌入.选择适当的窗口长度m,将一维时间序列Y(T)=((y1),···,(yT))转换为多维时间序列:X1,···Xn,(Xi=(yi,···,yi+m−1),n=T−m+1),得到轨迹矩阵,即:
(2)奇异值分解.通过对矩阵SVD 分解,得到XXT的L个特征值.具体步骤是:将X转置得到XT,然后利用XXT得到方阵,再利用方阵的性质求得矩阵的特征值[7-9],即利用(XTX)νi=λiνi,求得σ即是奇异值,µ是奇异向量.
(3)分组.假设有N个奇异值σ1,σ2,···,σN,定义第i个奇异值的方差贡献率为由大到小选择前M个奇异值,使其方差贡献率之和大于一定阈值.
(4)确定最佳谐波个数.利用前M个奇异值的方差贡献率之和大于一定阈值(0.85)来确定最佳谐波个数M.当P(i)≥0.85 时,我们认为此时的i即为最佳的谐波个数,即M=i.然后利用三角函数的性质将数据构造成周期函数.
2.2 周期项和随机项的确定
设{yt,t=1,2,···,N}为时间序列,若将其看作由周期项和随机项组成,可以用组合模式yt=pt+xt描述,其中pt为 周期项,xt为随机项.pt的表达式如下:

其中,M为谐波个数,
2.3 LightGBM 模型
LightGBM 是一种梯度Boosting 框架,使用基于决策树的学习算法,具有快速、高效、支持并行化学习、可以处理大规模数据等优点.
(1)梯度提升.
梯度提升是在不断的迭代过程中,对模型不停的增加子模型,同时保证最终的损失函数值在不断的下降.GBDT 是一种梯度提升决策树,是由多个决策树组成,利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值作为我们回归提升树算法的残差的近似值,来拟合一个回归树[10-12].
假设我们每一个单独的子模型为fi(x),我们的复合模型为:

损失函数为L[Fm(x),Y],每一次对模型中添加新的子模型后,使得我们的损失函数不断朝着0 发展.
(2)LightGBM 原理
LightGBM 是在传统的梯度提升树(GBDT)上使用直方图优化(Histogram)算法,先把连续的特征值离散化成k个整数,同时构造一个宽度为k的直方图.在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点.同时使用带深度限制的Leaf-wise 的叶子生长策略,经过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合[13-15].表3给出LightGBM 模型主要参数含义.

表3 LightGBM 模型参数含义
3 SSA-LightGBM 模型预测分析
3.1 对数据进行奇异谱分解
此处将2019年的7月1日到2019年8月25日的1344 条数据分为两部分,利用前70%的941 条数据预测后30%的403 条数据并将其与对应的真实数据进行对比.对前部分数据进行奇异谱分析时选取的窗口长度为200,可以得到方差贡献率图(见图3).从图中可以看出,当i≥56 时,P(i)≥85%,满足本文的数据处理要求,即当显著谐波个数M为56 时,对应个三角函数信号能表征序列的最主要趋势.

图3 方差贡献率图
然后,可构造周期函数,得到图4.周期函数对应的公式为:

式中,M为谐波个数56,

图4 周期函数对比图
表4详细介绍了周期函数Pt 中每一个参数的具体含义和取值.根据周期函数的性质,利用周期不变性对周期函数进行延伸得到2019年8月9日到8月25日周期函数延拓图(图5).然后由交调当量原始数据减去周期项(xt=yt−pt),可得到图6所示的随机项.

表4 周期函数各参数含义
本文采用LightGBM 机器学习方法对交调当量随机项数据进行预测,表5为LightGBM 模型常用参数的取值,其他参数均采用默认.图7中曲实线为交调当量随机项前941 条数据,后面虚线为使用LightGBM预测的403 条随机当量数据.
4 预测效果评价
我们将SSA-LightGBM 模型得到的2019年8月9日到8月25日周期函数延拓结果和随机项预测值相叠加得到最终交调当量预测值(见图8,红色曲线).为了验证SSA-LightGBM 模型的预测效果,本文还分别用XGBoost 和LightGBM 机器学习方法对数据进行了预测(利用2019年7月1日到8月8日的数据预测2019年8月9日到8月25日的数据).由于这2 种模型为单纯机器学习预测方法,且不是本文的研究对象,故此处不详细描述各种方法的预测过程.将不同预测模型得到的预测结果与韩城交调当量的原数据进行对比,得到图8.图中黑色曲线为韩城高速交调数据的原数据,红色曲线为SSA-LightGBM 模型的预测结果,XGBoost 和LightGBM 模型的预测结果分别对应蓝色和绿色虚线.从图中可以发现,单独使用XGBoost 和LightGBM 模型得到的曲线整趋势能表示原始数据,但是整体均低于原始数据不能完整的表示当量的局部特征.只有橙色虚线SSA-LightGBM 模型预测的结果能够实现高精度稳定预测2019年8月9日到8月25日交调当量变化趋势.
另外,本文还采用常用的平均绝对值误差(MAE)、均方根误差(RMSE)和相关系数(R2)分析评价了不同模型预测结果的精度(表6),各指标的公式、含义及评价标准见表7.从表中可以发现本文的模型MAE和RMSE均低于XGBoost 和LightGBM 模型说明模型的稳定性和平均误差优于单独的机器学习模型,R2大于另外两个模型说明预测效果好相关性强.

图5 周期函数延拓图

图6 交调当量随机项

表5 LightGBM 模型参数取值

图7 随机项预测结果

图8 不同模型预测结果对比图

表6 各模型评价指数
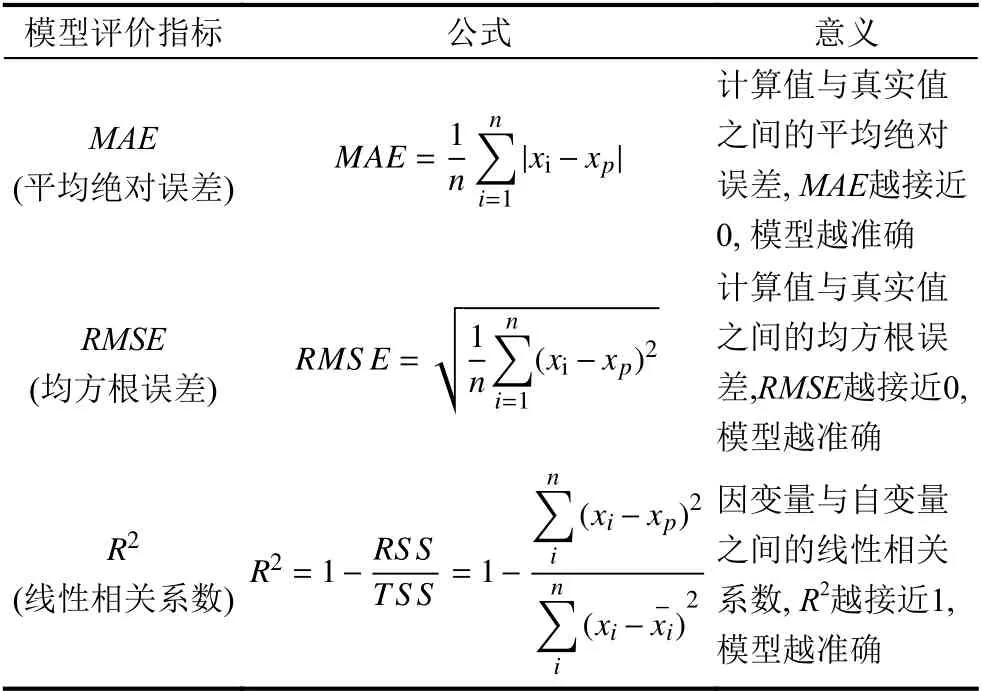
表7 评价指标
综上,无论是直观的曲线对比(图8),还是数学统计方法(表6),均证明SSA-LightGBM 模型可以高精度、高稳定性地预测2019年8月韩城高速交调数据当量变化趋势.我们可以使用该模型对全国的高速公路交调数据进行预测,这对我国高速公路更好的休整和养护以及服务水平的提升具有重要的参考价值.
5 结论
由于传统的时间序列预测模型和单独的机器学习模型对周期性比较强的时间序列预测存在一定弊端,本文采用SSA-LightGBM 模型进行预测,以韩城高速2019年7月到8月两个月1344 条交调数据为例,以前70%的数据作为模型的训练集,以后30%的数据作为验证集.将结果与单纯的机器学习模型XGBoost 和LightGBM 模型进行对比,发现本文提出的模型预测结果更接近真实值,同时该模型的MAE、R2和RMSE均优于其他两个模型,表明本文的模型可以很好地预测韩城高速交调当量数据,这对该地区高速公路的整修扩建、养护具有一定的指导意义.
猜你喜欢
当代陕西(2019年20期)2019-11-25
数学大王·低年级(2019年12期)2019-08-14
财会学习(2018年18期)2018-08-22
民间文学(2018年3期)2018-04-28
中国报道(2017年12期)2017-12-25
上海故事(2017年2期)2017-02-22
为了孩子(孕0~3岁)(2001年14期)2001-08-07
