
R-dedup:一种重复数据删除指纹计算的优化方法
2021-02-01 01:36王龙翔董凯王鹏博董小社张兴军朱正东张利平
西安交通大学学报 2021年1期
王龙翔,董凯,王鹏博,董小社,张兴军,朱正东,张利平
(1.西安交通大学计算机科学与技术学院,710049,西安;2.西安美术学院信息中心,710065,西安)
近年来,随着半导体技术的不断发展,固态硬盘(SSD)的每字节存储成本在不断下降。无论是个人计算机还是数据中心服务器,SSD正在逐渐取代机械硬盘(HDD)成为主要存储设备。与HDD相比,SSD具有更高的性能和更低的功耗,并且更加抗振动干扰。随着3DXpoint等新型非易失性介质(NVM)的发展,基于NVM的新一代SSD将具有更加优异的性能。
重复数据删除作为一项高效的数据精简技术,在存储系统中得到了广泛应用[1]。随着SSD成为了主流的存储设备,如何针对SSD的特点优化重复数据删除方法的性能成为了研究者关注的问题[2-5]。Gupta等指出,在普通文件系统的I/O负载中存在重复数据,对SSD写入数据进行重复数据删除是有效的[6]。Chen等提出CaFTL方法,在SSD内部FTL层实现了重复数据删除[7]。通过在SSD的写入路径中识别重复数据,避免这些数据写入flash介质中,可以延长SSD寿命。重复数据删除需要对数据块计算SHA-1哈希值作为指纹进行数据查重操作。然而,计算SHA-1哈希值是一项计算密集型任务,在SSD的写入路径中加入重复数据删除会增加写入延迟,降低数据写入吞吐率。在基于NVM的SSD中,由于数据I/O操作延迟不断降低,吞吐率不断增加,该问题会更加严重。文献[8]指出,在传统HDD设备中,基于SHA-1的指纹计算执行时间约占重复数据删除操作总时间的21%,在NVM存储系统中,这一比例上升至44%。因此,如何降低SHA-1指纹计算开销成为了提高高性能SSD中重复数据删除性能的关键问题。
为了降低SHA-1指纹计算时间开销,CaFTL提出了采样和预哈希方法[7]。该方法假设上层负载中只存在少量重复数据,因此每次请求都会被抽样,只有当某次写入请求中被抽样数据块为重复时才进行重复数据删除操作,否则认为该次请求包含重复数据的概率较低,不对该次请求进行重复数据删除。同样,Wang等提出了类似的思想,在执行重复数据删除之前,对数据集进行采样,以获得估计的重复数据删除率[8]。只有重复率高的数据集才会执行重复数据删除,而重复率低的数据集则不会执行。采样方法通过减少需要进行重复数据删除操作的数据量来降低指纹计算开销,存在的问题是会降低重复数据删除率。Chen等提出的NF-Dedup用弱哈希算法(如CRC)替代SHA-1作为数据块指纹,以此来减少指纹计算开销[9]。该方法的原理是CRC等弱哈希算法的计算开销远小于SHA-1这类强哈希函数的。当弱哈希在指纹库中检索不到时,可以确定对应的数据块不存在,但是当检索到弱哈希存在时,不能确定对应的数据块是否存在。这是由于弱哈希具有较高的哈希碰撞率,即若干个不同的数据块可能具有相同的弱哈希值。因此,NF-Dedup通过逐字节比较所有具有相同CRC指纹的数据块来判断是否为重复数据块。该方法随着存储数据量的增大,产生哈希碰撞的几率会持续上升。例如:在存储数据量较小时,可能存在两个数据块具有相同的CRC哈希值,当存储数据量增大后,具有相同CRC哈希值的数据块可能上升为10。此时,需要对10个数据块都进行逐字节对比才能判断数据块是否重复,这会显著增加数据写入延迟。
为了解决上述问题,本文在弱哈希方法思想基础上,提出了面向基于内容分块算法(CDC)的重复数据删除指纹计算的优化方法R-dedup。CDC能够实现可变长度分块,是目前应用最广泛的重复数据删除分块算法[10-11]。在此算法基础上,又衍生出了许多改进算法,如TTTD[12]、Bimodal CDC[13]、fastCDC[14]等。由于这些算法都是基于CDC进行的改进,因此R-dedup也可应用于这些算法。R-dedup的核心思想是将数据块划分为更小粒度的48 B等长数据片,利用CDC滑动窗口过程中已计算的数据片Rabin指纹,替代原始数据作为SHA-1函数的输入,计算数据块对应的SHA-1指纹。因为Rabin指纹长度通常为10 B,远小于48 B,因此R-dedup减少了SHA-1函数的输入数据量。Rabin指纹可以直接利用CDC算法滑动窗口过程中生成的结果,无需重复计算。实验结果表明,R-dedup的SHA-1指纹计算吞吐率提升至标准CDC方法的165%~422%,系统总体吞吐率提升至标准CDC方法的6%~54%。
1 背景知识
1.1 基于内容的分块算法
重复数据删除需要先对数据流进行切分,将其划分为更细粒度的数据块,以数据块为单位进行重复数据检测。可变长度分块能够避免因为字节变化造成的数据块漂移问题,检测到更多的重复数据,因此目前被重复数据删除系统广泛使用。
CDC是目前可变长度分块的标准算法。CDC的主要原理如图1所示,通过设置大小为48 B的滑动窗口,从数据流的起始处开始滑动,计算窗口内数据的Rabin指纹[15]。之后,通过将Rabin指纹和掩码进行与操作,判断所得结果是否等于预先设定的魔数。如果等于预先设定的魔数,则将当前窗口的最后一个字节作为分块的边界点,当窗口在数据流中滑动结束后,所形成的边界点将数据流划分为长度不同的一系列数据块集合。为了避免出现分块过大或过小的情况,可设置分块大小的最小值与最大值。当分块大小小于最小值时,舍弃当前边界点;当分块大小大于最大值时,强制设置当前窗口最后一个字节为边界点。
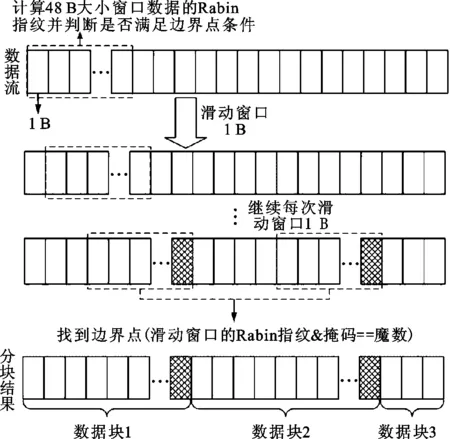
图1 CDC原理
1.2 Rabin指纹计算
Rabin指纹由哈佛大学的Rabin于1981年提出。对于任何一个n位字符串b0,…,bn-1,可将其表示为有限域GF(2)上的n-1次多项式
f(x)=b1xl-1+b2xl-2+…+bl
(1)
随机选择有限域GF(2)上的k次不可约多项式p(x),定义字符串m的Rabin指纹为GF(2)上f(x)除以p(x)后的余数,即k-1次多项式r(x)
r(b1,…,bl)=
(b1xl-1+b2xl-2+…+bl)modp(x)=
r1xk-1+r2xk-2+…+rk
(2)
在CDC算法中,设置一个大小为48 B的数据窗口,计算当前窗口的Rabin指纹,判断是否为块边界。滑动1 B后,窗口数据发生变化,因此需要重新计算当前窗口的Rabin指纹。如果再次用式(2)计算Rabin指纹,会造成不必要的计算开销。事实上,当前窗口与滑动前窗口的数据只有一个字节不一样,因此可以利用上一个窗口Rabin指纹来计算当前窗口Rabin指纹,公式为
f(b9,…,bl+8)=(b9xl-1+…+bl+8)modp(x)=
(x8(b9xl-9+…+bl)+bl+1x7+…+
bl+8)modp(x)=(x8(b1xl-1+…+
b8xl-8+b9xl-9+…+bl+b1xl-1+…+
b8xl-8)+bl+1x7+…+bl+8)modp(x)=
(x8(r1xk-1+r2xk-2+…+rk+b1xl-1+…+
b8xl-8)modp(x)+bl+1x7+…bl+8)modp(x)=
((x8(f(b1,…,bl)+(b1xl-1+…+
b8xl-8)modp(x))modp(x)+(bl+1x7+…+
bl+8))modp(x)
(3)
通过式(3)可以看出,通过对多项式做变化,可将f(b9,…,bl+8)表示为f(b1,…,bl)的多项式,从而利用已计算窗口的Rabin指纹结果。与式(2)相比,式(3)只需要将f(b1,…,bl)做移位运算。
在窗口滑动1 B(8 b)后,当前窗口从b1,…,bl变为b9,…,bl+8,而b9,…,bl+8的Rabin指纹可根据式(3)利用b1,…,bl已计算的Rabin指纹f(b1,…,bl)得到。
2 R-dedup设计
R-dedup的核心思想是将数据块划分为更小粒度的48 B等长小数据片,先计算每个数据片的Rabin指纹,再将数据块包含的所有数据片对应的Rabin指纹替代原始数据,用于计算数据块对应的SHA-1指纹。R-dedup框架如图2所示。
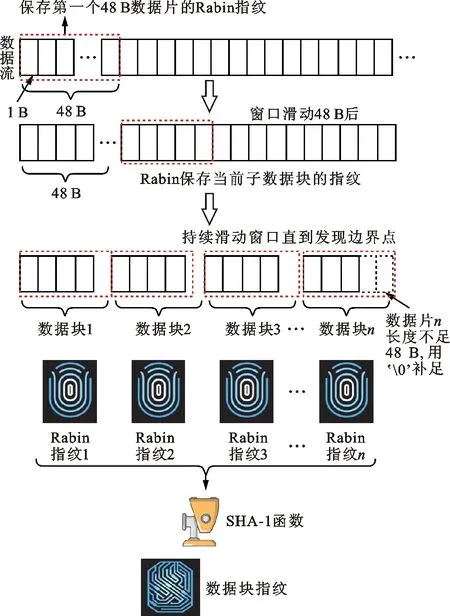
图2 R-dedup框架
2.1 重复数据检测
重复数据删除系统检测重复数据的原理是使用一个函数h(x),如果两个数据块a≠b,则h(a)≠h(b),反之如果a=b,则h(a)=h(b)。SHA-1哈希函数符合这一要求,目前普遍被重复数据删除系统作为h(x)函数使用。R-dedup通过计算f(g(x))作为数据块的指纹来加速指纹计算,令g(x)=w(x1)·w(x2)·…·w(xn),其中,·是字符串连接运算符,x1,x2,…,xn是数据块x按48 B切分后形成的数据片,w(x)为弱哈希函数,例如Rabin哈希函数。由于Rabin哈希值的长度通常小于80 b(10 B),小于数据片xi的长度48 B,因此g(x)的长度小于x的,h(g(x))的计算量小于h(x)的。CDC分块过程中需要不断计算48 B窗口的Rabin哈希值,因此只需每隔48 B保存一次Rabin哈希值,即可得到w(xi),无需再次计算。R-dedup算法伪代码如下。
输入:数据流
输出:SHA-1指纹
1 获取数据流长度
2 计算数据片数量
3 初始化数据流指针为0
4 初始化48 B窗口
5 初始化Rabin指纹数组
6 从数据流中读取48 B数据填满窗口,并将数据流指针加48
7 while 数据流指针未指向数据流末尾do
8 计算窗口数据的Rabin指纹
9 if Rabin指纹形成边界点then
10 跳出循环
11 end if
12 if 已滑动长度等于48 B的倍数then
13 保存当前窗口数据的Rabin指纹值到数组
14 end if
15 数据流指针加1
16 end while
17 if 窗口数据不足48 B then
18 用‘�’填充窗口
19 计算窗口Rabin指纹
20 保存窗口数据的Rabin指纹值到数组
21 end if
22 将Rabin指纹数组作为输入,计算对应SHA-1指纹并返回
2.2 指纹计算
在R-dedup中,将CDC切分后形成的数据块再进一步切分成大小为48 B更细粒度的数据片。在CDC切分数据块的过程中,需要保存下所有48 B数据片对应的Rabin指纹。当数据块边界点寻找到后,用48 B数据片对应的Rabin指纹而不是原始数据流作为输入来计算数据块的SHA-1指纹。因此,R-dedup可以减少SHA-1函数需要计算的数据量。例如,选择度为64的不可约多项式计算Rabin指纹,则Rabin指纹长度小于64 b(8 B)。在用数据片Rabin指纹而不是48 B的原始数据做SHA-1计算后,R-dedup可将SHA-1的输入数据大小至少减少到原始输入数据大小的8/48=1/6。理论上,R-dedup可将SHA-1的计算速度提高6倍以上。
2.3 数据块指纹碰撞
数据块发生指纹冲突是指两个不同的数据块具有相同的SHA-1哈希值。SHA-1哈希函数本身就可能发生哈希碰撞,但是由于这一概率极低,所以目前学术界普遍认为SHA-1哈希碰撞问题可以忽略。Venti系统是最早采用重复数据删除的存储系统,该系统采用了SHA-1函数生成数据块指纹。文献[16]指出:在EB级存储系统中,发生指纹哈希碰撞的概率为10-20,碰撞概率足够小,可以忽略不计。因此,只要哈希碰撞的概率足够低,在工程应用中就可以忽略哈希碰撞问题。R-dedup通过Rabin指纹替代原始数据进行SHA-1指纹计算,如果Rabin指纹发生碰撞,则数据块对应的SHA-1指纹也会发生碰撞。

为了避免指纹冲突,可以设置更大的预期块长度。较长的数据块有更多的48 B数据片,所有数据片同时发生Rabin哈希碰撞的概率将更低。此外,还可以使用度更高的不可约多项式来计算Rabin哈希,以降低Rabin哈希碰撞的概率。
考虑一个比较极端的大规模存储场景。假设存储系统保存了1 EB的非重复数据,如果数据重复率为10∶1,则实际存储了10 EB数据。由此可得,48 B数据块数n0=260/48,m=48×8,碰撞概率为
(4)
如果选择一个度为200的不可约多项式,则发生Rabin指纹碰撞的概率为2-41/3≈1.38×10-25。因此,如果想降低Rabin指纹碰撞概率,可根据数据存储规模选择度更高的不可约多项式。
3 实 验
3.1 实验环境
本文实验均在同一台高性能服务器下进行,服务器具体配置如下:①CPU,2路英特尔Xeon E5-2650 v2@2.6 GHz处理器;②内存,128 G DDR4内存;③操作系统,Ubuntu 16.04;④存储设备,Memblaze Pblaze3 PCIe 1TB SSD。
重复数据删除参数设置如下:①预期分块大小平均值,4 096、8 192、16 384、32 768、65 536 B;②预期分块大小最大值,131 072 B;③预期分块大小最小值,1 024 B;④不可约多项式,0xbfe6b8a5bf378d83。
3.2 数据集
收集了5组具有代表性的数据集进行测试。为了保证R-dedup结果可以复现,所选的5组数据集都是公开数据集,可通过互联网进行下载。
5组数据集情况如下:①Linux内核源代码[18],从版本4.01到4.19,包含641个版本的内核源码数据,该数据集记为kernel;②著名机器学习网站kaggle上的视频数据集[19],包含大量用于机器学习的视频文件,该数据集记为video;③Flickr30k数据集[20],用于机器学习的基准测试数据集,包含大量来自Flickr网站的图像文件,该数据集记为image1;④斯坦福计算机视觉视频数据集[21],由斯坦福大学研究团队录制的斯坦福校园场景视频数据集,用于计算机视觉研究,该数据集记为video2;⑤Imagenet数据集[22],用于机器学习的著名公开图像训练数据集,包含大量图像数据,每一类图像数据存储为一个tar包,该数据集记为image2。
3.3 数据集重复率信息
预期分块大小是重复数据删除系统在分块过程中期望形成数据块的大小,但是受到文件自身大小等因素的限制,实际分块大小可能与预期分块大小差异较大。在预期分块大小为4、8、16、32、64 kB的情况下,分别对R-dedup方法和标准CDC方法进行了实验,结果如表1所示,表中重复数据率为原始数据大小与重复数据删除后实际存储数据大小的比值,反映了数据冗余程度。可以看出:kernel数据集由于包含数量众多的不同版本Linux内核源文件,存在大量冗余数据,因此具有相当高的重复数据率,达到了70.13~134.67,其他两组数据集的重复数据率则在2左右。另外,由于kernel数据集由大量小文件组成,而实际分块大小必定小于文件本身大小。因此,在设置预期分块大小大于8 kB以后,实际分块大小也不会明显上升。

表1 重复数据删除实验结果
3.4 数据分块吞吐率对比
数据分块吞吐率对比结果如图3所示。可以看出,R-dedup方法与标准CDC方法没有显著的数据分块吞吐率差异。这是由于R-dedup与标准CDC方法在分块过程中的唯一差别是R-dedup会临时保存数据片的Rabin指纹,这一操作并不会对性能造成显著影响。暂存Rabin指纹的内存空间在当前数据块的SHA-1指纹计算完成后即可释放,仅造成少量的内存空间开销。例如,如果预期分块大小为4 kB,则将4 kB分块再切分为48 B的数据片后,共形成4×1 024/48≈86个数据片。假设Rabin指纹长度为10 B,则需要临时分配860 B的内存空间。

图3 数据分块吞吐率对比
3.5 SHA-1指纹计算吞吐率对比
SHA-1指纹计算吞吐率对比结果如图4所示。可以看出,R-dedup的总体吞吐率提升至标准CDC方法的165%~422%。R-dedup方法有效降低了SHA-1指纹的计算时间开销,提升了吞吐率。这是由于R-dedup利用Rabin指纹减少了SHA-1函数需要计算的数据量,从而降低了计算开销。

图4 SHA-1指纹计算吞吐率对比
3.6 数据读写吞吐率对比
数据读写吞吐率对比结果如图5和图6所示。可以看出,R-dedup和标准CDC没有显著的数据读写吞吐率差异。这是因为R-dedup和标准CDC方法在数据读写方面没有区别,都是使用标准POSIX接口对数据进行读写操作,吞吐率主要受到数据集自身特点以及SSD本身性能的影响。kernel数据集由大量小文件构成,因此在读取过程中需要进行大量文件打开、关闭操作,造成了大量性能开销,导致读取性能较低,吞吐率只有约30 MB/s。其他3组数据集读取吞吐率可达2 GB/s以上,写入吞吐率可达400 MB/s~1 GB/s。

图5 数据读取吞吐率对比

图6 数据写入吞吐率对比
3.7 指纹查寻时间对比
指纹查询时间对比结果如图7所示。可以看出,R-dedup和标准CDC方法的指纹查询时间基本相同。指纹索引表采用哈希表结构实现,同样存储在SSD中,同时在内存中维持缓存提升性能。指纹查询时间与指纹数量成正比,kernel与image2数据集消耗的时间最多。预期分块数量设置越大,产生的指纹数越少,查询时间也会减少。由于R-dedup产生的指纹数和标准CDC方法的一样,因此两种方法的指纹查询时间基本相同。

图7 指纹查询时间对比
3.8 系统总体吞吐率对比
重复数据删除系统的总体吞吐率主要受分块性能、SHA-1指纹计算性能以及数据块读写性能影响。由于R-dedup相比标准CDC方法有效提升了SHA-1指纹计算性能,且在分块性能、数据读写性能方面没有明显差异,所以R-dedup相比标准CDC方法提升了总体吞吐率。主要操作消耗时间分布对比如图8所示,可以看出,相比标准CDC,R-dedup方法能够提升总体性能约6%~54%。性能提升程度取决于I/O等操作开销所占比例,例如,kernel数据集中读操作占总体时间开销比例大,因此即使R-dedup显著降低了SHA-1指纹计算开销,提升的系统整体吞吐率也较为有限。

图8 系统总体吐率对比
3.9 主要操作消耗时间分布对比
在预期分块大小设置为4 096 B时,R-dedup和标准CDC方法主要操作时间消耗分布如图9所示。重复数据删除消耗时间由I/O时间、分块时间和指纹计算时间构成,I/O时间由数据读写时间和指纹查询时间构成。随着数据规模的增长,指纹索引表过大无法完全维持在内存中。因此,目前主流重复数据删除系统采用内存作为缓存、外存作为存储的方式保存索引表。在指纹查询过程中,如果缓存未命中则会产生I/O操作。在标准CDC方法中,除了kernel数据集由于读时间占比过高,导致指纹计算比例较小(10%)外,其他4组数据集的指纹计算比例为26%~39%,印证了在高性能SSD中,SHA-1指纹计算成为了主要的性能瓶颈的现象。R-dedup方法中指纹计算比例下降为4%~20%,验证了R-dedup方法的有效性。

(a)image1数据集

(b)image2数据集

(c)kernel数据集
4 结 论
重复数据删除作为一种高效的数据精简技术,在存储系统中得到了广泛应用,然而随着高性能SSD的不断普及,重复数据删除系统的主要性能瓶颈由I/O操作变为了SHA-1指纹计算。本文提出的R-dedup方法通过用Rabin指纹替换原始数据作为SHA-1指纹的输入来减少计算量,缓解了SHA-1指纹性能瓶颈。本文得出的主要结论如下。
(1)提出了利用Rabin哈希替代原始数据以减少SHA-1指纹计算的重复数据删除指纹计算优化方法R-dedup。R-dedup在基于内容分块算法基础上,将切分后形成的每一个数据块进一步切分为更小粒度的48 B等长数据片。基于Rabin哈希长度小于原始数据、多个Rabin哈希同时发生碰撞概率极低以及数据片的Rabin哈希可从基于内容分块算法滑动窗口的中间计算结果获取的观察,用数据片的Rabin哈希替代原始数据作为数据块的SHA-1指纹输入,以减少SHA-1函数数据计算量,提高指纹计算性能。
(2)相比标准CDC,R-dedup在I/O性能、索引表检索性能方面与标准基于内容分块的重复数据删除方法只有4%的误差波动,性能基本一致。R-dedup提升SHA-1指纹计算吞吐率达到165%~422%,提升重复数据删除系统总体性能达到6%~54%。R-dedup较好地缓解了高性能SSD中重复数据删除系统的SHA-1哈希计算性能瓶颈。
未来将进一步选取规模更大的数据集做更大范围测试,观察R-dedup是否会出现SHA-1哈希碰撞问题,并分析发生碰撞对实际存储系统可能造成的影响。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
电脑爱好者(2021年8期)2021-04-21
物联网技术(2020年12期)2021-01-27
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
计算机应用与软件(2020年5期)2020-05-16
新生代·下半月(2019年5期)2019-09-10
科技创新与应用(2017年17期)2017-06-16
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
