
基于改进谱聚类的热点区域挖掘方法
2021-02-28 14:22梁卓灵元昌安乔少杰范勇强
重庆理工大学学报(自然科学) 2021年1期
梁卓灵,元昌安,覃 晓,乔少杰,韩 楠,范勇强
(1.广西大学,南宁 530004;2.南宁师范大学,南宁 530001;3.成都信息工程大学,成都 610225;4.成都市环境保护信息中心,成都 610015)
近年来,随着GPS(global positioning system)设备、卫星和无线电传感网络[1-2]等定位技术的快速发展,人们能更方便快捷地对全球范围内各类移动对象进行有效跟踪,并由此采集到丰富的移动轨迹数据[3]。热点区域是移动轨迹中隐含的重要信息,能够表示移动对象经常出没的、带有重要语义信息的地区。提取热点区域能为人类日常出行、观光旅游等推荐个性化路线,也能为城市交通管理、道路规划等提供辅助决策依据[4-6]。
在现有的研究工作中,主要使用空间聚类的方法来挖掘热点区域。如Ashbrook等[7]采用K means算法挖掘轨迹数据中的重要地点,但它存在初始中心点选择困难且影响结果等缺点,容易取得局部最优解。吕绍仟等[8]提出基于轨迹结构的框架(TS_HS),以实现区分识别多密度的活动热点区域。郑林江等[9]提出基于网格密度的热点区域提取方法,便于处理大规模的空间数据,但其网格大小k和网格密度阈值γ都难以选取。还有利用DBSCAN算法[10]对用户运行速度较慢的区域进行聚类,从而发现用户的兴趣区域,但是DBSCAN对参数的设定比较敏感,当不同簇类的样本集密度相差较大时,算法的聚类效果较差。
综上所述,多数挖掘算法需要调试参数,且参数的选取对聚类结果有较大影响。为了更好地挖掘用户出行的热点区域,针对K means算法对初始值敏感易陷入局部最优解,DBSCAN算法在密度不均匀数据集上聚类效果差[11]等问题,本文提出基于改进谱聚类的热点区域挖掘算法(hot regionmining algorithm based on improved spectral clustering,ISCRM)。
1 基本概念
1.1 GPS轨迹及位置点
定义1 用户位置点(user location point)。
由GPS设备记录的用户所处的位置点P定义为一个三元组,记为P=(Lat,Lng,t)。其中Lat代表纬度坐标,Lng代表经度坐标,t代表当前时间戳。
定义2 GPS轨迹(GPS trajectory)。
一条GPS轨迹(trajectory)[12]是由一系列采样时间间隔相等的用户位置点Pi以时间顺序连接而成,如轨迹Tra=(P1,P2,Pi,…,Pn),其中Pi∈P,Pi+1.t>Pi.t,(1≤i<n)。如图1所示,用户位置点序列(P1,P2,…,Pi,P8)即组成轨迹Tra1。

图1 GPS轨迹及停留点示意图
1.2 改进的NJW 谱聚类算法
NJW(Ng Jordan Weiss)是谱聚类中的经典算法[12],其基本思想是:以每个样本数据为顶点V,以样本相似性为顶点间连接边E赋权重W,由此得到基于样本数据点及其相似性度量的无向加权图G=(V,E,W),从而将聚类问题转化为图划分问题。
1)传统NJW 算法在计算相似度矩阵W 时,一般用高斯核函数来度量两数据点间的相似性,两个样本之间的相似度。其中 σi=dist(xi,xT)是样本点i到其第T个近邻点的欧氏距离[15-16]。
2)针对传统NJW 算法不能自动确定聚类数目的问题,改进的NJW 算法[17]采用基于本征间隙的自动谱聚类算法[18]来解决。即在计算规范Laplacian矩阵的特征值时,将其按从大到小的顺序排列为λ1≥λ2≥…≥λn。然后根据矩阵的扰动理论,计算本征间隙序列{g1,g2,…,gn-1|gi=λi-λi+1},求得相邻特征值之间的差。在这系列差值中找到第一个极大值,则该值对应的下标就是聚类数目,即类别数k=arg min{gi-gj|j<i>0&&gi-gi+1>0}[19]。但尺度参数σ需要人为选取,且其无法准确反映数据集样本的真实分布。为此,改进的NJW 谱聚类算法,借鉴Self Tuning[14]相关算法的思想,在计算相似度矩阵W 时使用针对样本i的自适应尺度
2 改进谱聚类的热点区域挖掘算法
经典的热点区域挖掘算法对参数的选取较为敏感,容易影响最终对热点区域的挖掘效果。如采用K means算法,它对孤立点较为敏感,存在初始中心点选择困难且影响结果等缺点,在非凸数据集上表现较差[20];而采用DBSCAN算法,需要对扫描半径Eps,最小样本数阈值Min Pts联合调参,当不同簇类的样本集密度相差较大时,难以选取合适的参数组合,算法的聚类效果较差。因此本文提出基于改进谱聚类的热点区域挖掘算法(hot region mining algorithm based on improved spectral clustering,ISCRM)。
ISCRM算法的主要思想是:首先,依据时间阈值和距离阈值从移动轨迹数据中提取用户停留点;其次,引入自适应尺度参数σi,以用户停留点为顶点集合,构建停留点间相似矩阵及拉普拉斯矩阵;接着,自动确定聚类数目k,计算拉普拉斯矩阵前k个最大特征值及其对应的特征向量,构建特征向量空间;最后再用K means算法对向量空间中的特征向量进行聚类,获得k个簇类及其簇类中心,从而得到热点区域。为此,需对提取用户停留点、构造停留点集的相似性矩阵、拉普拉斯矩阵等步骤进行设计。
2.1 提取用户停留点
定义3 停留轨迹段(stay trajectory)。
停留轨迹段L是一系列位置点的集合,可定义为:L={Pi|i∈[m,n],且Distance(Pm,Pn)≤Dthreh,|Pn.t-Pm.t|≥Tthreh,Pi.v<max_speed}。其中,Distance(Pm,Pn)表示位置点Pm和Pn之间的距离,Dthreh表示指定的距离阈值,Pi.t表示位置点Pi的采样时间,Tthreh表示指定的时间阈值,max_speed是指定的用户移动最大速度阈值。
定义4 停留点(stay point)。
停留点s定义为一个三元组,记为:s=(s.Lat,s.Lng,s.T)。其中,s.Lat,s.Lng分别是计算停留轨迹段L={Pm,Pm+1,…,Pn}的平均纬度和平均经度,也就是停留点的经纬度坐标,其计算公式如下:

s.T=|Pn.t-Pm.t|代表用户在停留点s处的停留时间。
如图1所示,L1={P3,P4,P5,P6}等一系列点可组成停留轨迹段,图1中红色点即为从轨迹段中提取到的停留点位置。
停留点是指用户停留时间较长的地点,而热点区域就是停留点聚集的地区。因此本文对热点区域进行挖掘,需从移动轨迹数据中提取用户出行的停留点。
算法1 停留点提取算法。
输入:轨迹点列表(gps_obj_list),max_time(时间阈值),max_speed(速度阈值)
输出:停留点列表
1)counts=len(gps_obj_list);//获取轨迹点对象数量
2)i=0,j=1; //设置i,j初始值
3)while i,j<=counts do//遍历列表(gps_obj_list)中的轨迹点
//插入轨迹点i,j,保存在位置点小组L中
4) L←insert(point_i,point_j)
//计算两点间距离
5) ed_distance=get_distance(point_i,point_j);
6) t_diff=get_timestamp(point_i,point_j); //计算两点间时间间隔
7) Mean_speed=ed_distance/t_diff; //计算轨迹点间的速度
8) if t_diff>max_time&&Mean_speed <max_speed then
9) Cal_means_pos(s,L);//根据位置点小组L及公式(1)、公式(2),计算得停留点信息
10) Stay_point_list.append(s);//并入停留点
11) i=j;
12) end if
13) j=j+1;
14) if j==counts then
//如果j等于counts,即遍历到最后一点
15) Cal_means_pos(s,L);
//计算得停留点信息
16) Stay_point_list.append(s);//并入停留点
17) end if
18)end while
19)return stay_point_list//返回停留点列表。
2.2 构造停留点集的相似度矩阵
将用户停留点集S构造为无向加权图SG=(SG.V,SG.E,SG.W)。其中SG.V为图顶点集合,指代各个停留点;SG.E为图的边集,是停留点之间关联边的集合;SG.W是权重集,是各停留点间的相似性的集合,边上的权值wij表示停留点si和停留点sj之间的相似性。将加权图进行最优切割,使各个子图间的相似性小,子图内部的连接紧密,由此形成多个簇类。停留点无向加权图见图2。

图2 停留点无向加权示意图
如图2所示,顶点集合S.V由{s1,s2,…,s4}等停留点组成,边集S.E={(si,sj),1≤i,j≤4},表示连接两两停留点的边的集合。权重集S.W={wij,1≤i,j≤4},表示停留点间的相似性集合。
在构造停留点集的相似度矩阵W 时,停留点间的相似性wij通常用高斯核函数来定义,即:

式(3)中,dist(si,sj)表示两点间的欧氏距离。其计算如下:

自适应局部参数 σi=dist(si,sT),代表停留点si到它第T个近邻点的欧氏距离,即sT为停留点si的第T个近邻点。据文献[12-13]选取的经验值,以及本文停留点数据集的验证,T=7。
2.3 计算停留点集的拉普拉斯矩阵
在给定的由用户停留点构成的无向图中,一般非规范拉普拉斯矩阵定义为:

式(5)中:W 为相似度矩阵;D为图的度矩阵。图中与某顶点i连接的所有边上的权重和即为该顶点的度,计算如下:

由于本文采用的是对称规范化的拉普拉斯矩阵,因此需在式(6)基础上进一步规范化,有:

在构造拉普拉斯矩阵后,需计算其特征值,将前k个最大特征值对应的特征向量组成一个n行k列的特征矩阵Xn×k,对矩阵的每一行数据进行聚类操作。在此之前,需对Xn×k中的行向量进行归一化,公式如下:

2.4 计算本征间隙估计类个数
传统谱聚类算法无法确定聚类数目,本文采用基于本征间隙的自动谱聚类算法解决。根据矩阵的扰动理论,首先计算规范拉普拉斯矩阵的特征值,将其排列为λ1≥λ2≥…≥λn。特征值之间的差值可排列为本征间隙序列{g1,g2,…,gn-1|gi=λi-λi+1}。
本征间隙序列中第一个极大值对应的下标即为聚类数目k,计算如下:

至此,已介绍了ISCRM算法的全部过程。下面给出ISCRM算法的具体描述。
算法2 ISCRM算法。输入:轨迹数据集
输出:聚类结果
Begin
Step 1 调用算法1提取轨迹数据中的用户停留点;
Step 2 利用式(3)、式(4)构造用户停留点的相似度矩阵W;
Step 3 根据式(5)和式(6)计算非规范的拉普拉斯矩阵L,进一步规范化,由式(7)获得对称规范化矩阵L sym;
Step 4 计算规范矩阵L sym的特征值,据特征值之差计算本征间隙序列,最后由式(9)计算得聚类数目k;
Step 5 取L sym前k个最大特征值对应的特征向量组成特征矩阵Xn×k,据式(8)对Xn×k中的行向量进行归一化,得到矩阵Y;
Step 6 将矩阵Y中的每一行看做是空间中的一个点,使用K means算法对数据点进行聚类。
End。
3 实验分析与比较
3.1 实验数据分析
实验中使用的数据来自微软研究院Geolife项目,该项目共记录了182位对象的户外活动轨迹,数据采集历时超过5年(2007.04—2012.08)。该数据集包含17 621条轨迹,分布在30多个城市(大部分在北京创建)。
首先对轨迹点进行提取,去除速度过大而导致异常的噪声点[21],并选取速度较小而驻留时间较长的停留点[22]。在从移动轨迹数据中提取用户停留点时,需要设置时间阈值、速度阈值和距离阈值,本文参考文献[23]对城市移动对象的研究,为排除红绿灯路口停留点设置时间阈值为120 s,为选取速度较小的移动对象设置速度阈值为2 m/s,而距离阈值设置为200 m。不同的阈值取值会影响提取到的用户停留点集,进而影响到挖掘效果[24-25],给定时间阈值,当距离阈值和速度阈值越低时,提取到停留点数量也随之减少,挖掘到的热点区域较小且分散,当距离阈值和速度阈值较高时,挖掘到的热点区域较大且集中。
此处以北京和上海为例,设置阈值后提取停留点,调用百度地图API对城市内部分用户停留点进行可视化展示[26]。由于终端定位到的GPS点坐标与百度地图的坐标不在同一个坐标系,显示到百度地图上时其位置有较大偏差。通过使用百度地图提供的转换接口[27],将停留点原始坐标转换为百度坐标,保存在json文件中,然后找到百度地图开发文档-加载海量点API进行调用展示。效果如图3所示,其中粉红色的星型点即为用户停留点分布地点。
从图3(a)、(b)可以看出,由于大多数轨迹数据在北京市创建,因此上海地区分布的用户停留点较稀疏,而北京地区的用户停留点数量更密集。

图3 用户停留点的可视化展示示意图
3.2 性能对比实验
为了说明ISCRM算法的有效性,本节特将其与K means算法、DBSCAN算法进行了性能对比分析。本次实验环境为:Win10 64bit操作系统,8GB内存,CPU 2.60GHz;使用python语言在pycharm上实现。实验数据为从Geolife数据集中提取,共包含100个用户的10 949个出行停留点数据。
3.2.1 实验1
对于用户停留点数据集在未知实际类别信息的情况下,可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果,此处采用常见的评价指标轮廓系数SC(silhouette coefficient),其计算式表达为

式(10)中:a代表样本到同簇类其他样本的距离平均值;b代表样本到其他簇类样本的距离均值。SC取值在[-1,1]。如果SC越接近1,说明样本所在簇越合理;若SC接近-1则说明样本点更应该分到其他簇中。
本次实验中,K means算法和DBSCAN算法在一定区间内选取不同的参数进行聚类,发现K means算法及DBSCAN算法均易受参数选择的影响,实验结果波动较大;而ISCRM算法无需人工调试参数,可直接获得最好结果。其中K means算法随机选取k个初始中心,通过不断迭代最终形成k个聚簇,而k个初始中心不同的选取将对聚类结果产生极大影响。本文算法通过自适应局部参数σi构建尽可能准确反映样本分布信息的相似度矩阵,并通过计算本征间隙估计的聚类数,把对原始数据集的聚类转为对向量空间的k个特征向量进行聚类,避免了对初始值设置的敏感性。另外根据矩阵扰动理论,对于给定的数据集合包含k个彼此分离的簇类,规范拉普拉斯矩阵的特征值之间的差距由这k个簇类的空间分布决定。在理想情况下,前k个最大特征值应等于1,而紧邻的第k+1个特征值则小于1,因此第k个和第k+1个特征值之间的本征间隙即为极大值。所以计算本征间隙估计聚类数是具有理论依据的,得到的聚类数k具有一定准确性,而在此基础上选取的k个特征向量组成的特征空间,可有效反映原始数据集,与原数据空间构造的k个簇类相对应。
从运行时间来看,K means算法耗费时间最短,而ISCRM算法最长;但在轮廓系数指标中,K means算法及DBSCAN算法均不及ISCRM 算法高,且试验结果也不如ISCRM算法稳定。对比表1中各聚类算法在停留点数据集上的表现,尽管K means和DBSCAN算法运行时间较短,但在其繁琐的参数选取环节上会耗费额外的时间。而ISCRM算法依据自适应局部参数σi描述样本实际分布,以及自动估计聚类数目,可获得更贴近样本真实分布的特征向量空间,并对特征空间进行聚类,也在一定程度上加快了收敛速度。ISCRM算法通过自适应调节参数直接获得的结果轮廓系数最高,代表聚类结果最合理。

表1 停留点数据集上聚类结果
3.2.2 实验2
在实验1基础上对数据集中的轨迹进行处理,仅提取北京市内的用户出行停留点,利用3种算法分别对其聚类。为了方便检测实验结果,采用python的matplotlib库,以经纬度为坐标画出用户停留点的空间分布以及3种算法的聚类结果。图4为北京市内的用户停留点分布图,图5和图6直观反映了K means算法和DBSCAN算法在不同参数条件下得到的聚类结果。ISCRM算法实验结果如图7所示。

图5 K means算法实验结果示意图
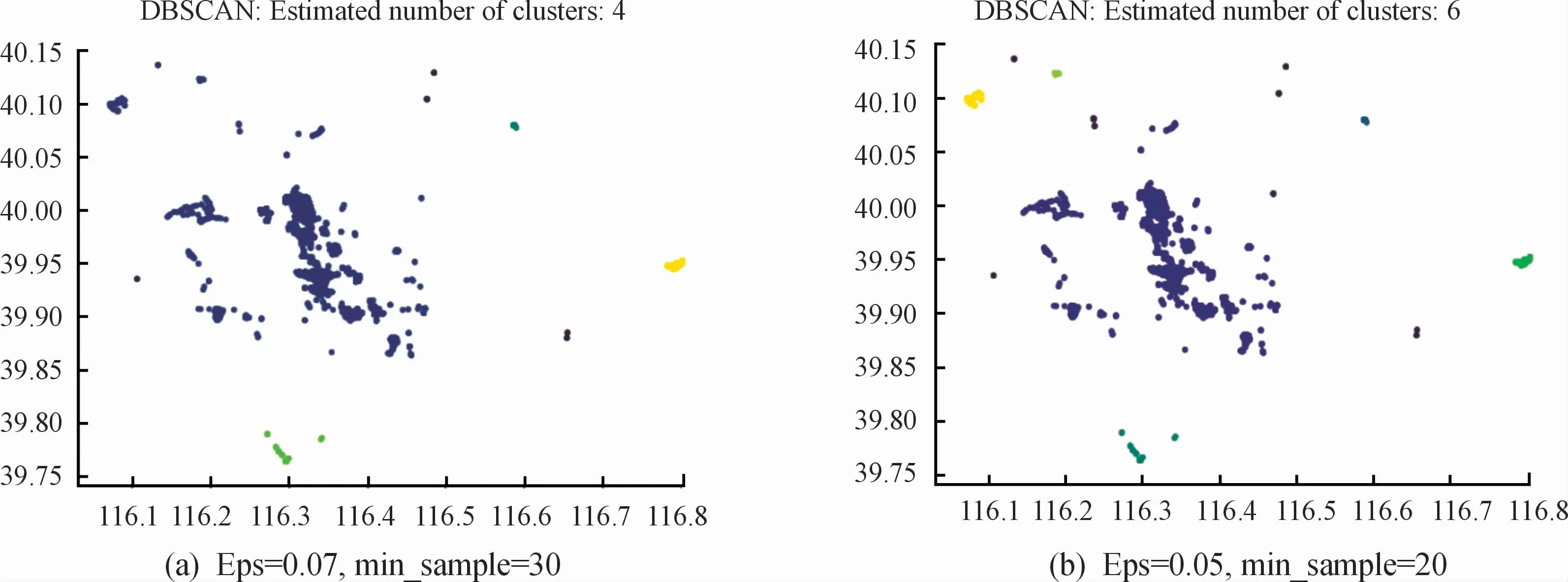
图6 DBSCAN算法实验结果示意图
从图5和图6中的聚类结果可以看出,K means算法选取不同k值时,得到的簇类数也不同,其将中部距离较近的数据点分成了多个簇类,距离较远的数据点反而分到同个簇类,不适于非凸数据集,无法很好地划分簇类;DBSCAN算法的聚类结果也易受参数选择的影响,如果选用固定参数识别簇类,当簇类的稀疏程度不同时,较稀的簇类可能被划分为多个类,而密度较大且距离较近的簇类可能被合并成一个类,如图6(a)、图6(b)中部的一大块区域被合并为一个簇类。
ISCRM算法进行聚类时,其依赖于相似矩阵和拉普拉斯矩阵的构建,利用自适应局部参数来反映样本数据集的真实分布,把聚类操作转换为对图分割操作,相比传统方法更能适用于不同类型的样本空间。图7实验结果显示,其通过自适应聚类获得7个簇类,相比前2个算法,其簇类分布最为均匀合理,不同簇间样本点距离更远,同簇内样本点更为紧密。

图7 ISCRM算法实验结果示意图
3.3 热点区域挖掘
为了更直观展示聚类效果及用户停留点的热点区域,我们通过百度地图API,将利用ISCRM算法得到的聚类结果直接投影在实际的地图上。图8为调用海量点API显示用户停留点聚类结果,图9为调用热力图API展示用户出行热点区域的中心位置。

图8 北京市内用户出行停留点聚类结果示意图

图9 北京市内用户出行热点区域中心位置示意图
通过计算,我们可获得各簇类停留点个数以及各簇类中心点位置,设定簇类中心位置为热点区域,簇类停留点个数即为热点地区的热度值,由此可得出北京市内用户出行的热点区域,并根据区域内的热度值对这些热点区域进行由高到低的排列。分析图8和图9中的簇类中心及热度值,我们发现热度值排第一的区域为:北京大学,清华大学,圆明园等地;热度值排第二的区域为:首都师范大学,中国工商大学,北京动物园等地;热度值排第三的区域为:中央音乐学院,天安门,人民大会堂等地;热度值排第四的区域为:北京站,夕照寺等地。
纵观图中热点区域分布,我们发现排在前列的热点区域主要集中在大学城、公园及天安门、火车站一带,这些区域在一天中都具有较大的人流量,以及较高的出行需求,是人们密集出行的重点区域。
4 结论
本文中主要提出了基于改进谱聚类的热点区域挖掘算法。其引入自适应尺度参数σi以及计算聚类数目k的方法,以用户出行停留点为顶点集合,构建相似矩阵及拉普拉斯矩阵,再用K means算法进行聚类。其中,利用自适应尺度参数σi能更准确反映停留点数据集的真实分布;且通过计算本征间隙来自动确定聚类数目k,有效避免了因为参数选取而获得不好结果的情况。该方法保留了谱聚类算法的优势,对比传统方法,其对孤立点不敏感,适用于任意形状的样本空间,能够准确地获得聚类结果。在性能对比试验中,该方法在对用户出行停留点聚类问题上,其聚类结果更合理,同簇类点更紧密。在对北京市内用户出行热点区域的挖掘实验中,通过调用百度地图API在实际地图上展示了用户停留点的聚类结果及聚类中心,成功识别出七大热点区域,验证了本文所提方法的可行性。
未来的研究可以使用更大规模的数据量,通过文献[24]提出的分布式并行化处理缩短运行时间,更加详尽地挖掘多个城市用户频繁活动的热点区域。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
铁道通信信号(2019年6期)2019-10-08
车迷(2019年10期)2019-06-24
现代装饰(2018年5期)2018-05-26
快乐语文(2018年7期)2018-05-25
中国三峡(2017年2期)2017-06-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
