
病历数据挖掘技术的应用研究*
2021-03-11 13:26陈小文唐翠娥
科学与信息化 2021年6期
陈小文 唐翠娥
贵州医科大学 计算机教育与信息技术中心 贵州 贵阳 550025
引言
电子病历(Electronic Medical Record,EMR)是医务人员在医疗活动过程中形成的电子化病人记录,是现代医院诊疗、科研及管理工作所必需的重要临床信息资源[1],其蕴含了大量的、准确的详细的患者的医疗信息。通过对住院电子病历完成知识分析和实体识别,准确提取患者各项医疗信息,可帮助医学研究者构建临床决策支持系统,减少个人的医疗失误问题。文献[2]提出了一种基于双向长短时记忆网络与 CRF(conditional random field)结合的实体识别和实体关系抽取方法,对识别结果知识图谱化。文献[3]提出了基于bootstrapping的识别算法和基于条件随机场的识别算法,有效地提高了条件随机场识别结果的准确率、召回率和F1值。利用快速树算法降低了抽取算法的时间复杂度,获得了标准树片段库和局部树片段库;提出了启发式和机器辅助的方法来解决数据不一致问题;提出了一种基于多特征和CRF相结合的命名实体识别方法,利用分层融合聚类的方法对存储库中从未出现的实体进行聚类;提出了一种基于卷积神经网络的多类别分类方法,用于从EMR中挖掘命名实体;设计了病历数据到RDF三元组格式的转化方案和存储方案,提高了数据检索速度,同时避免空值所导致的问题。采用否定术语对中文电子病历进行检测,降低了标点录入错误而出现假阳性术语的概率。提出了改进后的逆向最大匹配算法,提高了分词准确度和分词效率。分别采用C4.5、BP对肿瘤病历数据进行了分类实验,结果表明:C4.5算法更有利于辅助医生进行肿瘤疾病诊断。针对国际疾病分类标签提出端到端的深度学习方法,在分类性能上有显示的提升。
1 数据提取与模型描述
病历文本数据中包含了非常重要的医疗信息,通过对住院电子病历完成知识分析和实体识别,准确提取患者各项医疗信息,可协助医学研究者构建临床决策支持系统,帮助医生解决知识上的局限性问题,从而减少个人的医疗诊断失误。借鉴OEM(Object Exchange Model)模型描述方式,采取四元组(oid,label,type,value)来表示,type可为原子型也可为集合,value表示具体的值。其结果如图1所示。
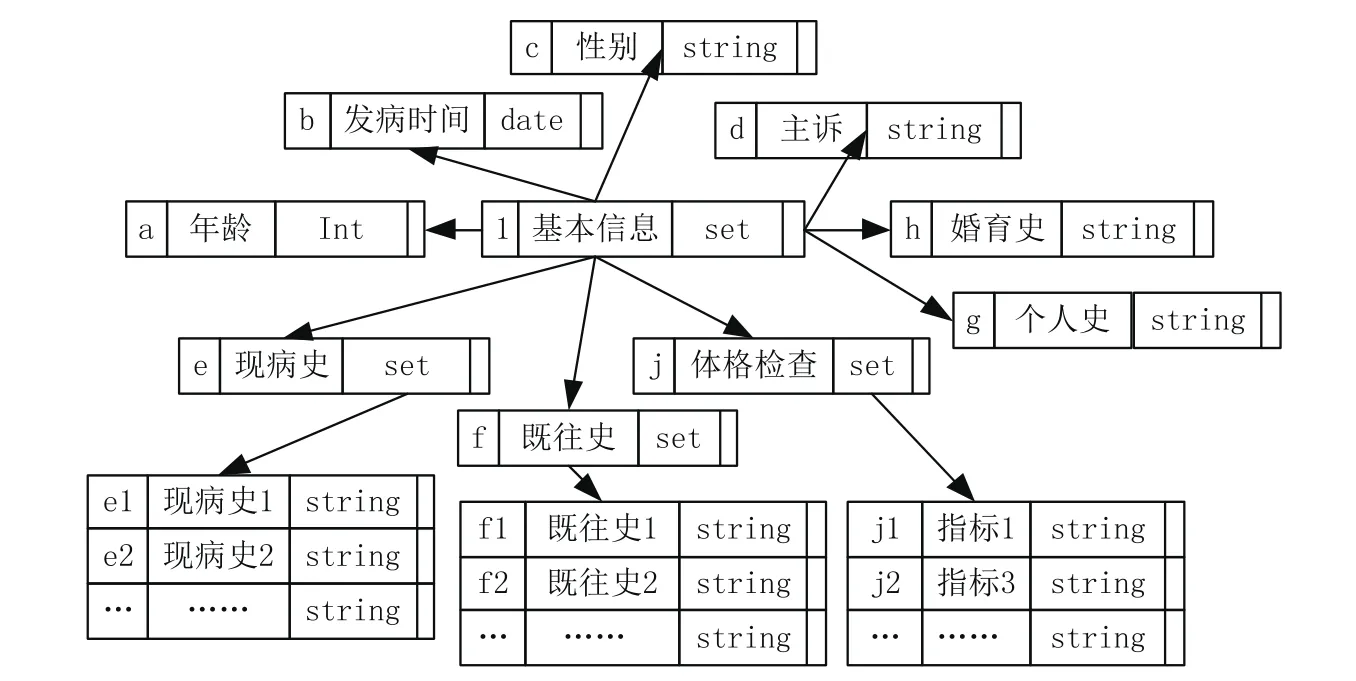
图1 病历基本信息模型图
病历文本数据以半结构化数据居多,构建病历文本数据提取和分类规则,将非结构化、半结构化的数据转换成可挖掘的结构化数据,并创建数据模型结构化模型M={N,F,I,P,D},其中N为当前病史集合、F为既往史集合、I为人个史集合、P则为体格检查集合,D为诊断结果集合。其中N={恶心、呕吐,头昏,畏光、畏声,头痛,乏力及麻木,大小便异常,体重明显增减},F={伤寒、结核,肝炎,糖尿病,高血压,冠心病,中毒史,过敏史},I={吸烟,戒烟,饮酒},P={体温,呼吸,脉搏,血压},D={脑供血不足,脑出血,脑梗,紧张性头痛,神经症焦虑,椎基底动脉供血不足,帕金森病,前庭神经元炎,后循环缺血,良性位置性眩晕}。
2 数据预处理
电子病历中包含的医疗信息十分丰富,借助数据分割提取从Word文件中提取相应的关键信息,按患者基本信息模型进行数据关联与存储,并将最终生成的二维表以EXCEL格式导出,项目组累计完成384份神经内科住院电子病历数据提取工作,依据诊断结果进行分类汇总,其中脑供血不足113份、脑梗89份、紧张性头痛67份、脑出血28份、后循环缺血23份、神经症焦虑状态19份、良性位置性眩晕18份、帕金森氏病11份、椎基底动脉供血不足8份、前庭神经元炎7份。在数据预处理阶段进缺失数据记录进行补充或丢弃,针对缺少5项以下的数据记录采取填充众数的方式进行补充,对缺失5个及以上数据项的记录进行丢弃处理。为避免数据提取的数据类型异常而导致的错误,将所有的对象数据编码成数值型。考虑到病历数据的特征以文本形式呈现且跨度大,特将所有数据进行标准化处理,并统一到0~1范围内。
3 算法分析
挖掘算法直接影响实验数据的结果,依据病历文本数据的自身特征、数据项,选择合适的算法进行数据挖掘、分析尤为重要。在前期算法调整阶段设定验证集的比例为10%,等待超参数调整结束并稳定后,训练与验证数据的比例分别为80%和20%。实验所采用的处理器为Intel(R) i5-8250U 1.8GHz 4核 8个逻辑处理器,内存24G。
3.1 决策树
决策树是一个预测模型,它是对象属性与对象值之间的一种映射关系。决策树是一种树型结构,每个叶子代表一种类型。决策树能直接体现数据,而且能够同时处理数据型和常规则属性,相对较为易于理解和实现。设置起始深度为1、终止深度为15、深度探索步长为4进行模型训练与测试,模型训练与测试花费130ms,其测试结果为51.04。在对超参数进行调整后,测试结果波动较小。由模型结果而知,当深度为4时能获取最大的准确率。
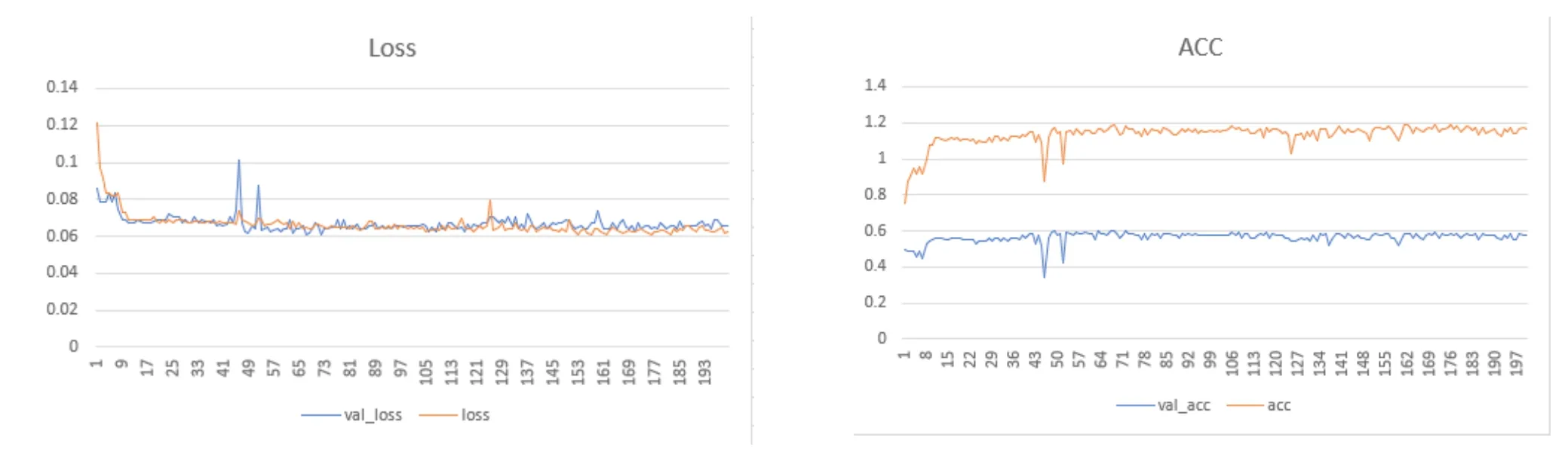
图4 深度学习结果趋势图
3.2 深度学习
深度学习是学习样本数据的内在规律和表示层次,最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。借助深度学习模型对病历数据进行训练与测试。以batch_size=8进行200轮训练,其训练与测试结果如下图所示,模型训练与测试花费63000ms(每轮315ms),其测试结果为57.29。深度学习运行结果如图4所示。
3.3 随机森林
随机森林利用多棵树对样本进行训练并预测的一种分类器,其利用平均决策树可降低过拟合的风险性。其分类性能非常稳定,当半数以上的基分类器出现差错时才会导致错误的预测。随机森林的算法较为复杂,对其模型训练和测试的成本相对较高。模型训练与测试花费0.92秒,其测试结果为65.62。
3.4 实验小结
深度学习、决策树、随机森林三种算法的执行时间、测试结果如下表1所示。在算法执行性能上,决策树的执行时间最短,测试结果得分近为51.04。深度学习的执行时间是决策树的2.42倍,在测试结果方面提高了6.25。随机森林的执行时间是920ms,模型的执行时间为决策树的7.07倍,在测试结果方面相比决策树和尝试学习分别提高了14.58和8.33。

表1 分类实验性能与结果对比
4 实验小结
在电子病历挖掘过程中有两个重要的步骤:①从半结构化、非结构化的电子病历中提取相应的现病史、既往史、个人史、体格检查等重要信息,病历数据特征的提取质量直接影响到后续的数据挖掘的质量和执行速度。②挖掘算法的选取,通过对三种不同挖掘算法测试结果可知:随机森林准确率较高65.62,但耗时相对较高。后续研究将改进数据提取的算法和挖掘算法数据结构。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
数学小灵通·3-4年级(2020年9期)2020-10-27
计算机教育(2020年5期)2020-07-24
作文评点报·低幼版(2020年25期)2020-07-23
福建基础教育研究(2020年3期)2020-05-28
电子制作(2018年16期)2018-09-26
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
