
基于深度确定性策略梯度的虚拟网络功能迁移优化算法
2021-03-17 09:44贺兰钦陈前斌
电子与信息学报 2021年2期
唐 伦 贺兰钦 谭 颀 陈前斌
(重庆邮电大学通信与信息工程学院 重庆 400065)
(重庆邮电大学移动通信技术重点实验室 重庆 400065)
1 引言
在软件定义网络(Software Defined Network,SDN)环境下,网络功能虚拟化(Network Function Virtualization, NFV)技术根据当前的用户服务请求创建服务功能链(Service Function Chain, SFC),SFC由多个虚拟网络功能(Virtual Network Function,VNF)按照特定的顺序编排构成[1],将VNF部署在不同服务器上,进而为用户提供服务,增强了网络的灵活性以及拓展性,使得基础设施资源高效利用[2]。由于SFC的资源需求是动态变化的,带来了资源利用率低等问题,因此研究VNF迁移机制十分有必要。
目前,已有大量工作对VNF迁移机制展开了研究,主要考虑触发VNF迁移的时机,待迁移VNF的选择和迁移的目的节点选择,文献[3]考虑在某台服务器的资源利用率过低时,触发VNF聚合,将该服务器上的所有VNF迁移至其他服务器,进入休眠状态,降低系统的整体能量消耗,但是没有考虑用户服务质量(Quality of Service, QoS)降低,而且当服务器的资源利用率达到阈值时立即触发迁移,会造成频繁迁移,降低系统的稳定性。文献[4]主要考虑低时延网络,当系统监测到VNF迁移后能够降低SFC端到端时延,则触发迁移,但是忽略了VNF迁移后网络能耗的增加。文献[5]建立成本模型来评估迁移开销,同时提出一种贪婪算法最小化VNF迁移开销,但是它采用的是静态迁移策略,由于网络环境是动态变化的,需要考虑长时间的优化。
综上所述,现有的VNF迁移机制均没有对网络能耗最小化及SFC端到端时延最小化进行联合考虑,而且大多数文献研究都是基于环境状态已知的情况下,没有考虑到环境随时间的动态变化,另外,针对有生命周期的SFC,在长时间尺度下研究VNF迁移的工作并不多。因此本文提出了一种基于深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)的VNF迁移方案,该方案首先考虑SFC资源需求动态变化,在保证底层物理资源和用户QoS需求的前提下,通过VNF迁移,并确定每个通用物理服务器的工作状态,实现网络能耗与SFC端到端时延的联合优化。其次,由于本文所提问题为随机优化问题,因此将该优化问题转换成马尔可夫决策过程(Markov Decision Processes, MDP)。最后,由于本文的状态转移概率是未知的,状态和动作空间都是连续值集合,故提出一种基于DDPG的VNF迁移算法求解MDP,得出近似最优的VNF迁移策略。
2 系统模型
2.1 网络场景
本文采用NFV编排和控制架构[6],如图1所示,主要分为3层。应用层主要为网络业务请求创建SFC,通过SFC为用户提供服务。虚拟化层主要负责网络状态监控和底层网络负载分析,物理层为SFC提供其实例化的物理资源,包括计算资源和链路带宽资源,物理网络主要由通用服务器组成。
2.2 网络模型
2.2.1 物理网络
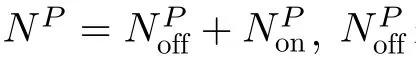
2.2.2 SFC请求
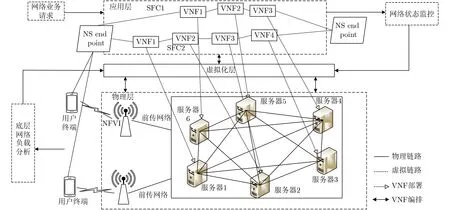
图1 系统模型
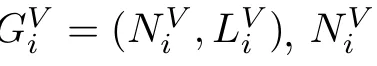
2.2.3 SFC时延模型
本文在计算SFC端到端时延的时候,因为传播时延的值可以忽略不计,所以主要考虑处理时延和传输时延。
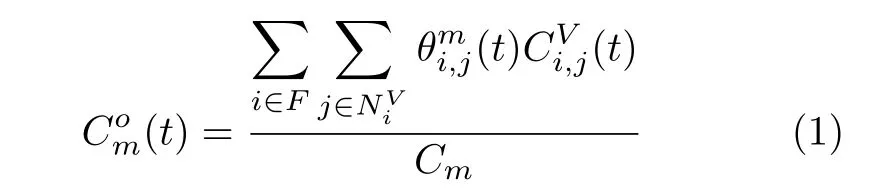
当映射到服务器上的VNF资源需求增加时,将导致服务器的CPU负载增大,进而SFC的处理时延也将增大。参考文献[7],假设处理时延是处理负载的凸函数,使用分段线性化来近似凸时延曲线。所以底层物理服务器的处理时延可以表示为

其中, εi和χi表示近似凸时延函数曲线的线性函数的系数。
SFC的传输时延与SFC上的虚拟链路映射到物理链路的位置有关,假设每跳虚拟链路映射到物理链路的时延为djk, 第i条SFC传输时延为

因此,第i条 SFC的端到端时延可以表示为
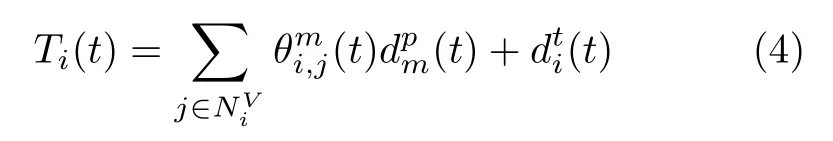
2.2.4 网络能耗模型
本文的网络能耗主要考虑底层物理服务器的能耗,网络能耗包括服务器运行状态时能耗和服务器状态切换时能耗P(t),基于文献[8],服务器的运行状态时能耗分为服务器待机时的能耗 P(t)和服务器CPU资源负载产生的能耗P(t), 因此服务器m在t 时隙的待机能耗和CPU负载能耗,分别用式(5)和式(6)表示。

其中, Pidle表示服务器待机时产生的能耗,为服务器m 中CPU资源全部占用时所产生的能耗。
另外,参考文献[9],基站切换工作状态时会有能量消耗。本文假设服务器工作状态发生变化时会产生能耗, 服务器m 在 t 时隙产生的切换能耗为
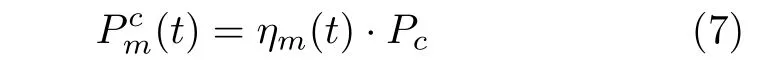
其中,ηm(t)表 示服务器m 在t 时隙状态是否发生了改变,用式(8)表示。
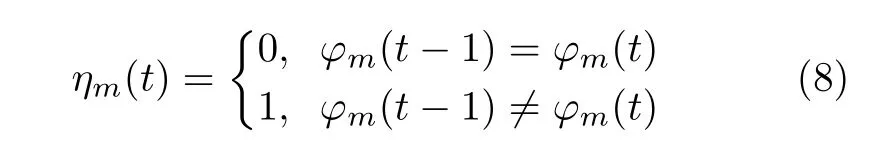
因此网络能耗可以通过每台服务器的能耗之和表示,即
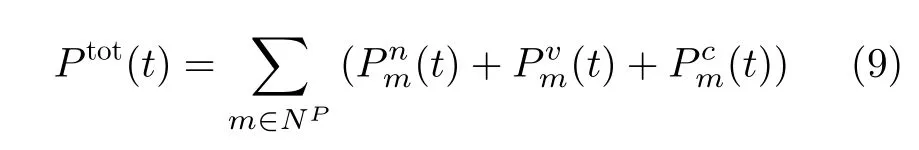
2.3 优化目标
本文要解决的问题是:在最小化网络能耗的前提下最小化SFC端到端时延,同时把底层物理资源等作为限制条件。故该优化问题属于多目标优化问题,具体表示为
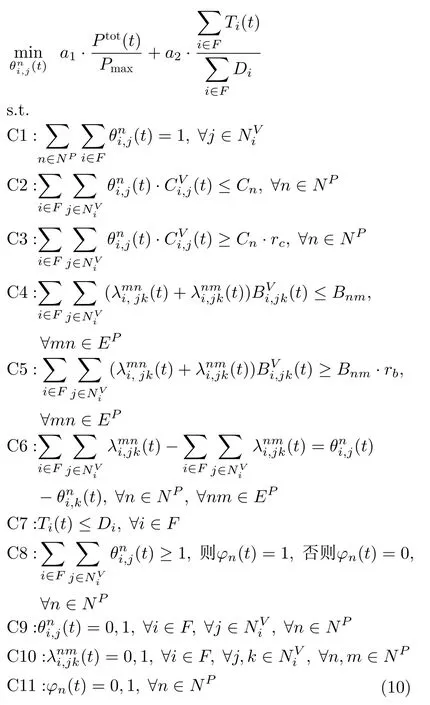
其中, a1,a2是 权重系数,且a1+a2=1, Pmax表示网络能耗的最大值。
该优化目标受到C1~C11限制条件约束,保证优化目标的有效性。C1用于保证一条SFC上的VNF只能选择一个服务器进行映射。C2~C5表示物理网络CPU资源和带宽资源限制。C6表示SFC中相邻两个VNF映射到底层服务器 n和m 时,nm之间必须存在一条连续路径,满足流守恒原则。C7表示每条SFC在任意时隙都要满足时延要求。C8表示如果某一台服务器上有VNF映射,那么这台服务器一定处于开启状态。C9~C11分别表示VNF映射,虚拟链路映射和底层服务器状态的二进制变量约束。
3 本文算法
3.1 MDP模型
本文先将优化问题建模成MDP模型,得到深度强化学习的基础框架,用一个四元组(S,A,P,R)对其进行描述。
(1) 状态空间为S:定义状态空间为S(t)={(φ(t),c(t),b(t)|∀φ ∈ψ,∀c ∈C,∀b ∈B} ,其中,φ 表示底层物理网络拓扑, ψ表示网络拓扑状态空间,c(t), b(t)分 别表示在t 时隙VNF的CPU资源和链路带宽资源需求,而 C, B则分别表示VNF的CPU资源和虚拟链路带宽资源需求状态空间:
(2) 动作空间为 A :在t 时隙定义动作空间为A(t)={θ(t)|θ ∈Θ} ,其中θ 表示VNF的映射动作,Θ则表示VNF的映射动作空间。
(3) 状态转移概率为 P :在t 时隙状态s (t)采取动作a (t), 将转移到下一时隙的状态s (t+1),状态转移概率为P (s(t+1)|s(t), a(t))。
(4) 奖励函数 R:本文定义一个效用函数r (t)作为即时奖励,通过式(10)转化得到

环境在 t 时隙处于状态s (t) , 会根据策略π 采取一个动作 a(t)=π(s(t))。 通过该映射策略π ,环境在t 时隙会通过值函数Qπ(s(t),a(t))来评判采取映射动作的好坏,可以将其表示为
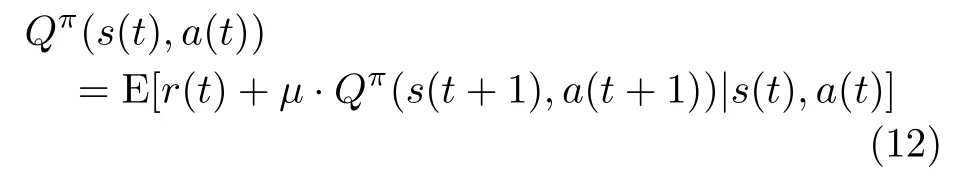
VNF最优迁移策略就可以表示为

3.2 基于DDPG的VNF迁移算法
MDP 模型通常由动态规划(Dynamic Programming,DP)或强化学习(Reinforcement Learning, RL)方法来解决[10],因此本文采用深度强化学习算法进行求解,但是常见的深度强化学习算法如深度Q学习(Deep Q Network, DQN)[11]等不适合解决连续动作问题,因此本文提出一种基于DDPG的虚拟网络功能迁移算法,DDPG算法以确定性策略梯度(Deterministic Policy Gradient, DPG)算法为基础,首先采用行动者-评判家(Actor-Critic, AC)框架,其次在评判家网络和行动者网络里面采用双神经网络架构,分别构成了估计行动者网络( θπ),目标行动者网络( θπ′), 估计评判家网络( θQ)与目标评判家网络( θQ′) , 其中θπ, θπ′, θQ和θQ′分别代表各个深度神经网络的权重值,并且它们具有相同的神经网络架构。最后采用经验回放池打破数据的关联性和非平稳分布问题。
在评判家网络中,估计critic网络负责近似式(13)中的Q值函数,即
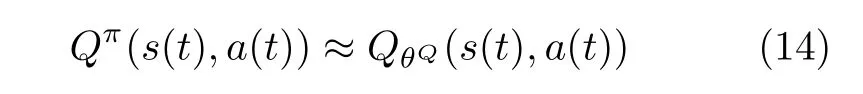
近似过程通过深度神经网络(Deep Neural Network, DNN)完成。首先对输入的状态 s(t)和VNF映射动作 a (t)进行预处理,文献[12]通过状态标准化来预处理训练样本状态,加快梯度下降求最优解的速度,进而加快神经网络模型的训练,因此本文对状态和动作做归一化处理。
最后,DNN的输出为当前状态s (t)采取VNF映射动作a (t)对 应的Q (s(t),a(t))值,而在对估计评判家网络进行参数更新时,主要通过最小化损失函数,即

当损失函数对参数θQ连续可微时,估计评判家网络参数可以用损失函数的梯度进行更新,即
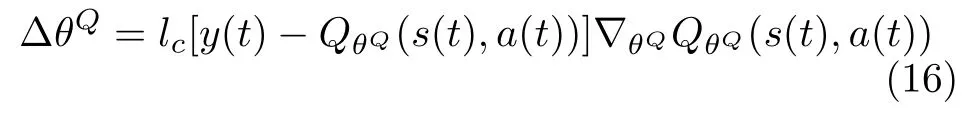
其中,lc表示估计评判家网络的学习率。
在行动者网络中,估计行动者网络使用策略梯度算法评估和改进策略,该算法会迭代评估策略,然后按照梯度进行改进以优化策略。策略梯度更新思想为:代理根据采取某种动作得到结果的好坏而决定是否增加或者减少采取该动作的可能性。
估计行动者网络同样采取DNN架构,将预处理后的状态s ˆ (t) 作 为输入,输出为当前环境状态s(t)采取的策略π (s(t)|θπ)。对估计行动者网络参数更新时,先从经验回放池随机抽取一部分样本训练DNN参数,接着以最大化长期平均回报为目标,迭代改进策略,策略目标函数可以表示为
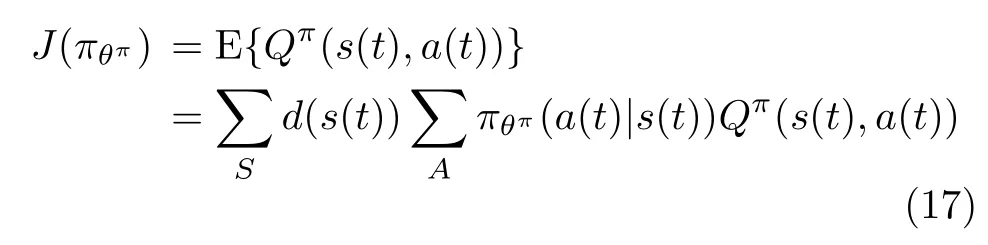
其中,d (s(t))表示状态分布,然后对策略目标函数偏微分,得到策略目标函数梯度

其中, Qπ(s(t),a(t))通过估计critic网络近似得到。如果式(14)中, QθQ(s(t),a(t)) 很 接近Qπ(s(t),a(t)),就可以用QθQ(s(t),a(t))代 替Qπ(s(t),a(t)),将式(18)转化为
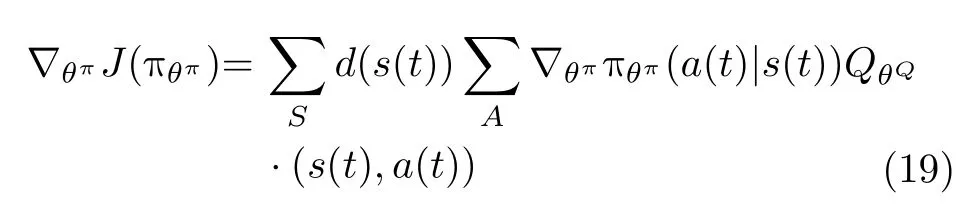
最后沿着目标策略函数梯度上升方向更新DNN参数

其中,la表 示估计actor网络的学习率。
为了探索VNF迁移最优动作,筛选出更好的策略问题,DDPG算法引入随机噪声 n,从而获得动作a (t),即

其中,n 表示高斯随机噪声,均值为n0。
目标评判家网络和目标行动者网络采用软更新参数,可以将其表示为
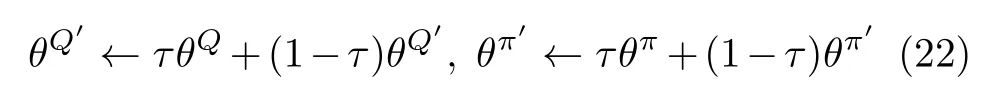
具体的VNF迁移策略训练如表1所示。
4 性能仿真与分析
本文通过调整评判家网络的学习率 lc ,保持行动者网络的学习率不变,验证DDPG算法的收敛性能。由图2可以看出,当评判家网络学习率 lc为0.0020时,损失函数的收敛速度最快,抖动最明显,但是梯度可能会在最小值附近来回波动,容易得到局部极小值,随着学习率的降低,收敛速度较缓慢,但是损失函数曲线较平稳,会使得在收敛时,损失函数值更加趋近于最优值。由图3可以看出,当评判家网络学习率 lc为0.0010时,得到的累积奖励值最多,更加利于本文求得最优解。因此本文选取评判家学习率l c为0.0010。
本文将权重 a1分别取值为0.7, 0.5和0.3,验证算法的有效性,考虑应用层有10条SFC的情况下,经过15000次训练迭代后,得到系统总时延和网络能耗情况如图4、图5所示。随着 a1的减小,系统总时延占的优化比重减小,故收敛时的时延值逐渐增大。随着 a2的增大,网络能耗占的优化比重增大,故收敛时的能耗值逐渐增大。基于以上分析,本文算法能够在优化网络能耗的同时,降低迁移带来的时延增量,保证用户的QoS。
本文首先从DDPG算法可以实现系统总时延与网络能耗联合优化的角度,与迁移仅实现SFC端到端时延最小化的实时VNF迁移(Virtual Network Functions Real-time Migration, VNF-RM)算法[4],及仅实现网络能耗最小化的VNF映射最小化能耗(VNFI Mapping Minimizing the Power Consumption, VMMPC)算法[13]进行对比,验证算法的性能。此时a1=0.5, a2=0.5。

仿真参数
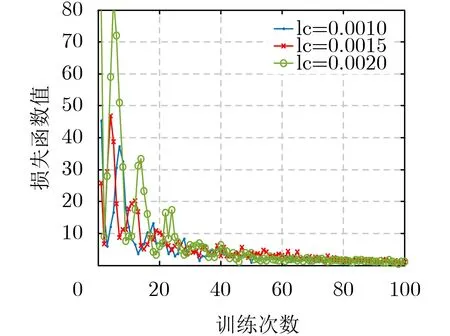
图2 不同评判家学习率下的损失函数值
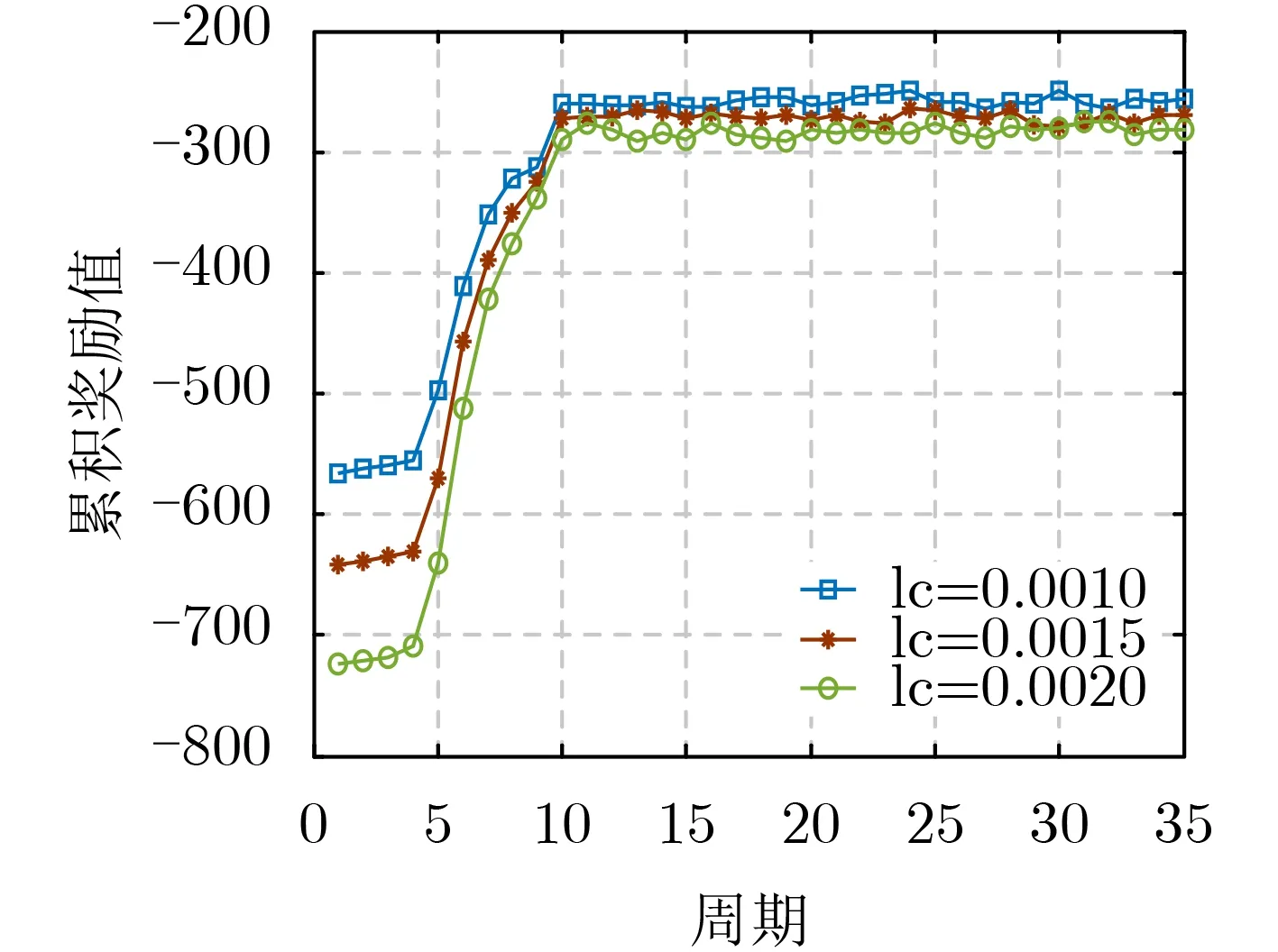
图3 不同评判家学习率下的累积奖励值
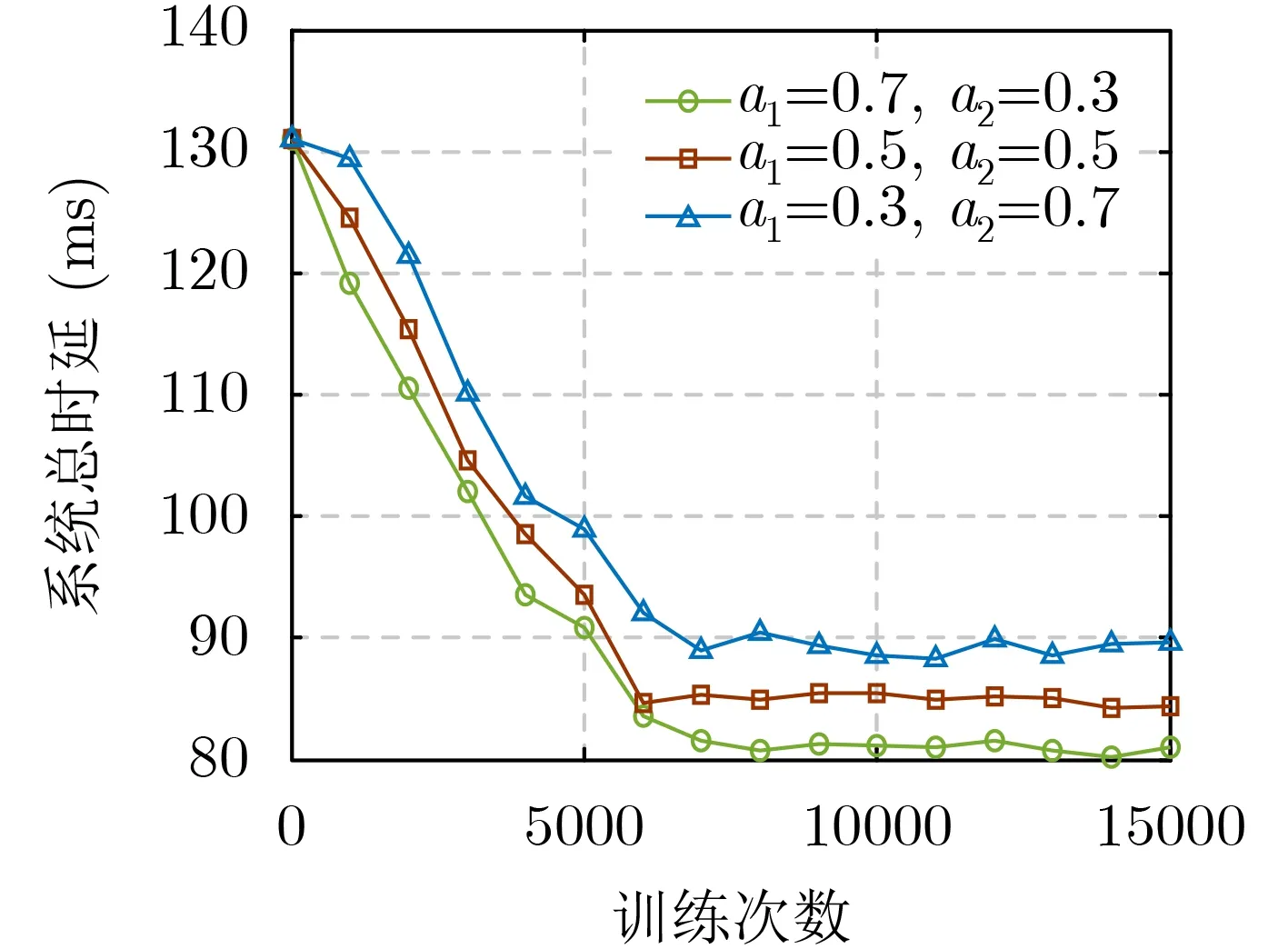
图4 权重对系统总时延的影响

图5 权重对系统总能耗的影响
从图6,图7可以看出,由于VNF-RM算法只考虑在VNF迁移前后,SFC端到端时延是否减少,而忽略了对底层低负载服务器的整合,因此通过VNF-RM算法得到的能耗必然会高于通过DDPG算法得到的能耗。同样地,VMMPC算法尽可能整合底层服务器资源,最小化网络能耗,但是没有考虑SFC端到端时延是否增加,因此通过VMMPC算法得到的SFC端到端时延必然会大于通过DDPG算法得到的SFC端到端时延。基于以上分析,DDPG算法能够实现网络能耗与系统总时延的联合优化。
其次,本文与同样可以实现网络能耗与SFC端到端时延联合优化的AC(Actor-Critic)算法进行对比,得到物理网络计算资源利用率情况如图8所示,由于AC算法主要取决于Critic的价值判断,但是Critic难收敛,再加上Actor的更新,就更难收敛,故AC算法很容易得到一个局部最优解,DDPG算法通过神经网络近似价值函数,解决了收敛难问题,因此通过AC算法得到的资源利用率必然要低于通过DDPG算法得到的资源利用率,进一步说明在VNF迁移过程中,DDPG算法能够有效提升物理网络计算资源利用率。

图6 系统总时延对比

图7 网络能耗对比
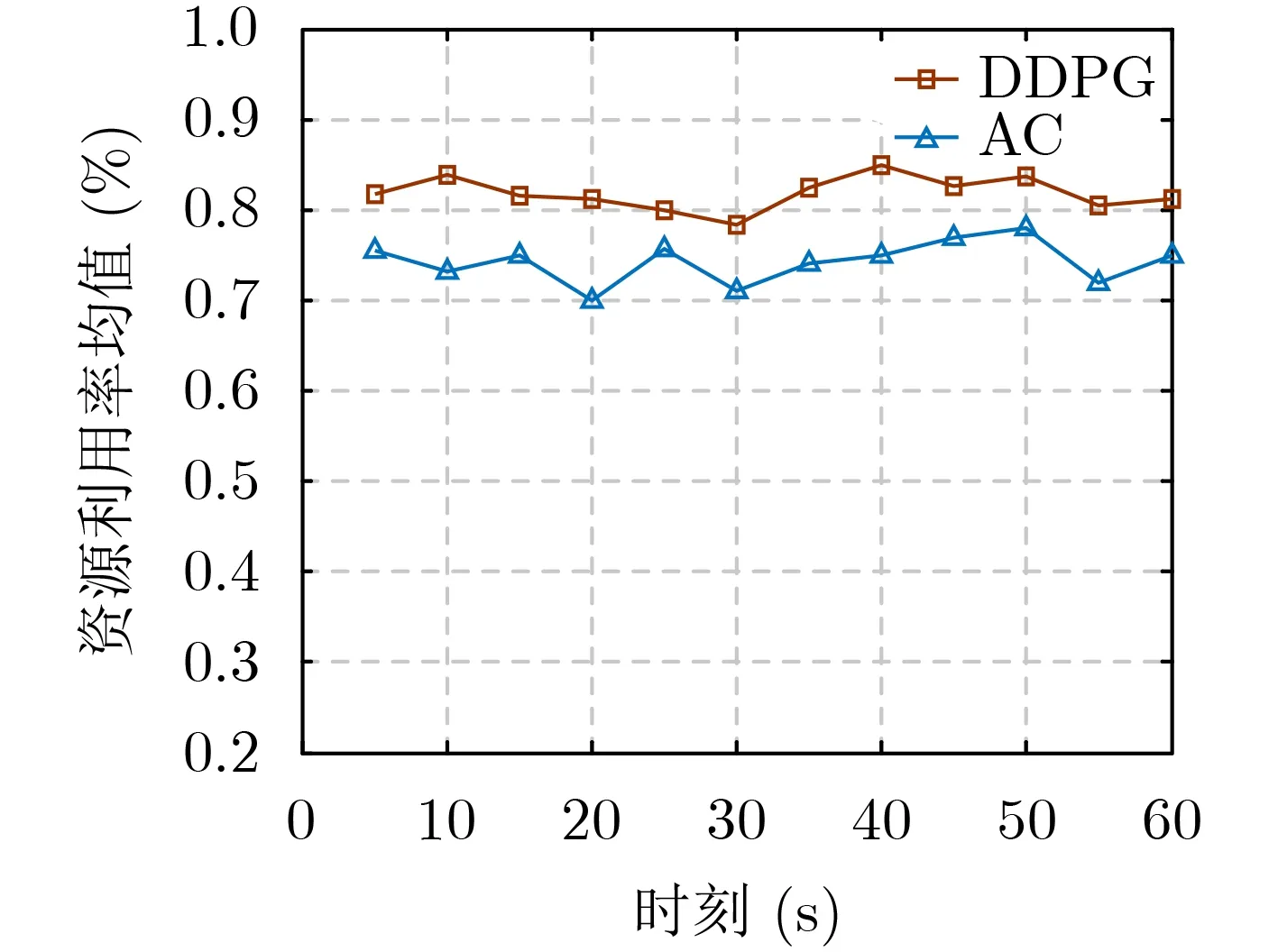
图8 计算资源利用率
5 结束语
本文基于NFV/SDN架构,针对 SFC资源需求动态变化引起的VNF迁移问题,联合优化SFC时延与系统能耗,然后将该随机优化问题建立成MDP模型,由于状态转移概率未知,以及状态空间过大和动作维度高,本文提出一个基于DDPG算法的VNF迁移方案,通过VNF迁移,实现收益最大化。仿真结果显示,本文所提算法能够有效地收敛,并可以实现SFC时延和网络能耗折中,提高服务器资源利用率。
猜你喜欢
贵州社会科学(2022年8期)2022-10-12
疯狂英语·新悦读(2020年1期)2020-02-20
自动化学报(2019年6期)2019-07-23
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
系统工程与电子技术(2016年7期)2016-08-21
绿色中国(2016年1期)2016-06-05
电测与仪表(2016年17期)2016-04-11
文学教育(2016年27期)2016-02-28
新闻传播(2015年3期)2015-07-12
