
一种面向不完备数据的集对粒层次聚类算法
2021-03-22 01:37张春英高瑞艳范雨祥王龙飞裴天帅冯晓泽
小型微型计算机系统 2021年3期
张春英,高瑞艳,范雨祥,王龙飞,裴天帅,冯晓泽,任 静
1(华北理工大学 理学院,河北 唐山 063210) 2(河北省数据科学与应用重点实验室,河北 唐山 063210)
1 引 言
数据聚类[1]是将相似的样本分配到同一类簇,将不同的样本分配到不同的类簇.聚类技术可以发现潜在的数据结构,其发现的聚类有助于解释数据集的隐藏特征,目前已广泛应用于模式识别、图像对象提取、和数据压缩等多个领域.现有的聚类算法根据聚类策略粗略地划分成划分聚类[2]、密度聚类[3]、层次聚类[4,5]几种类型,本文将着重对层次聚类算法进行研究与讨论.
聚类是一种重要的数据分析方法,在数据集中往往会出现不完整的数据,不适当地处理不完整的数据会显著降低聚类性能.目前关于不完备数据的聚类研究,已提出了一些有意义的成果.Aydilek[6]等提出了一种支持向量机和遗传算法的混合方法来估计FCM算法中的缺失值并对参数进行优化.Zhang[7]等利用预先分类的聚类结果设计了一种改进的区间构造方法,并通过粒子群优化寻找最优聚类.Lu[8]等采用改进的亲和传播(AP)算法,在不完备数据被填充后进行聚类分析,得到了较好的聚类结果.在不完备数据聚类中,针对缺失值的处理,主要分为两种方式:1)将含有缺失值的样本进行删除,虽然计算简单,但是若存在大量缺失样本,则会导致部分有效信息的丢失;2)利用样本之间的相似性和样本本身特征,来有效的恢复和填充缺失的属性值,例如可以采用区间值的形式来估计缺失属性值[9],或者根据其最近邻的均值来估计缺失属性值[10].
另外,在大多数聚类算法中,对于每个类簇通过单一的集合表示,如果样本在类簇中,则属于这个类簇,否则不属于这个类簇.实际上,样本与类簇之间存在3种关系:一定属于、可能属于和不属于.姚[11,12]提出了一种作为复杂问题解决的新的研究领域-三支决策,通过添加延迟决策来扩展常用的二支决策模型,对信息充足的对象进行决策,等待新的信息来对信息不充分的对象做出进一步的决策.在三支决策的启发下,Yu[13]将其应用于聚类,提出了三支聚类的概念,很好地解释样本与类簇之间的三种关系.最近,Wang等[14]针对数学形态学的腐蚀和膨胀,提出了三支聚类(CE3)的总体框架.Zhang[15]根据三支权重和三支分配,将粗糙k-means(RKM)进行扩展,提出了一种三支c-means聚类算法.Yu[16]等提出了一种基于改进的DBSCAN的三支聚类,对样本间相似性计算进行了改进,并用一对嵌套集来表示一个类簇.RKM算法其时间复杂度较低但聚类效果依赖于聚类中心的初始化;DBSCAN算法虽然可以对异常点进行处理,但其对于密度不均匀的类簇,得到的聚类效果不佳;并且以上聚类算法,虽然考虑了样本间的不确定关系,但主要针对完备数据集,对于不完备数据集并不适用.
CURE[4]算法通过代表点的收缩可以有效的控制异常点的影响,而且能够识别非球形和尺寸变化的类簇,对于数据输入顺序也不敏感,其是一种处理完备数据集的有效方法,但对于存在缺失值的数据,不能做到对所有数据综合考虑.缺失的数据值自身具有不确定性,对于不确定性问题的处理,集对论[17,18]展现了良好的优势,其从确定-不确定系统角度出发,通过关联度对事物进行统一刻画,可以很好地对不确定信息进行表示.Zhang等[19]基于集对论提出了集成正同、负反和差异三维粒度的集对信息粒,并用集对信息粒的方法,对三支决策的思想进行了阐述,提出了基于集对信息粒空间的三支决策模型.本文将集对信息粒的思想引入到CURE算法中,提出了一种面向不完备数据的集对粒层次聚类算法-SPGCURE,通过UCI数据库中的数据集,将算法SPGCURE涉及的参数通过实验进行了讨论,并与其他7种算法进行实验对比分析,结果表明该算法具有不错的聚类性能.所提SPGCURE算法创新之处体现在以下几方面:1) 缺失属性本身具有不确定性,将缺失属性删除或者填充,都不能很好表达数据中的原有信息,本文采用集对信息粒的知识对缺失值进行处理,用集对联系度中的差异度来表示缺失属性值,进而可以提高缺失属性估计的鲁棒性.2) 与现有距离度量方法不同,本文根据集对信息粒的相关理论提出的是一种集对信息距离度量方法,可以用于处理不完备数据集.3) 基于改进后的距离度量,给出了各个类簇的类内平均距离的定义,形成以正同域Cs(样本一定属于类簇),边界域Cu(样本可能属于类簇),负反域Co(样本不属于类簇)表示的集对粒层次聚类.
本文结构如下:第2节对基础知识进行简要介绍;第3节给出了所提算法SPGCURE,包括运用集对信息粒知识提出的集对信息距离度量、集对粒层次聚类的处理与结果表示;第4节,选用5个经典数据集,与常用的经典及改进聚类算法进行实验评价,并报告了实验评价SPGCURE的结果;第5节是本文的结论。
2 基本理论
2.1 不完备信息系统
信息系统S是由四元组S=(U,A,V,f)表示,式中U={X1,X2,…,Xi,…,Xn}是有限非空的样本集合,n为样本的个数;A={A1,A2,…,Am}是非空有限的属性集,其中,m为属性的个数;V={V1,V2,…,Vm}是U关于属性A的值域集合,Vs是属性As的值域;f是信息函数,f:vis=f(Xi,As)∈VS,表示样本Xi在属性As上的取值为vis.
Xi是论域中第i个样本,其具有|m|个属性值,当样本Xi的某些属性值vis(1≤s≤m)未知时,信息系统S成为一个不完备信息系统.
2.2 集对信息粒
集对分析是一种新的研究确定性与不确定性系统的理论,将两个事物所具有的特性作同异反分析,得出的同异反联系度表达式为:
ρ=a+bi+cj
式中,a表示正同度,b表示差异度,c表示负反度,其中,i∈[-1,1],j=-1分别称为差异度和负反度标记符号,用以识别分类信息的方向和不确定程度.

τXC:W0→[0,1],x→τXC(x)=aR+cR
τXU:W0→[0,1],x→τXU(x)=bR


τXCs:XC→[0,1],x→τXCs(x)=aR
τXCo:XC→[0,1],x→τXCo(x)=cR

定义3. (集对联系度矩阵)设待聚类信息系统为W=(U,A,R),A为属性集,在关系R下,任取W中的样本Xp和Xq(p≠q;p,q=1,2,…,n),令Xp与Xq建立集对联系度,用矩阵A表示为:
式中apq,bpq,cpq满足apq+bpq+cpq=1,其中,apq是正同度,bpq是差异度,cpq是负反度.
2.3 CURE聚类算法
层次聚类算法是从不相交的聚类集合开始,将每个输入样本放在一个单独的类簇中,然后,对各个类簇进行连续合并,直到类簇的数量减少到k.在每一步中,合并的对簇都是距离最小的簇,簇间距离的常用度量方式如下:
dmean(Ci,Cj)=‖mi-mj‖
式中,Xi,Xj是类簇中任取的样本,mi和mj分别是类簇Ci和Cj的中心点,|Ci|是类簇Ci中的样本个数,|Cj|是类簇Cj中的样本个数.
CURE算法的簇间距离度量方式与以往常用度量方法不同,采用多个代表点来表示类簇,代表点是从类簇中选择的足够分散的点.通过收缩因子,使得分散的点向中心聚拢,可以消除异常点的干扰;针对大型数据集,选择随机抽样和分割的方式,去减少输入集的样本数目;对于异常点的处理,分为两个阶段:1)在层次聚类中删除增长速度慢的类簇;2)当类簇总数减少到大约为k时,删除簇中样本个数较少的集合.CURE算法中代表点,中心点和距离度量方法的定义如下:
定义4[4].设样本集为U={X1,X2,…,Xn},n为样本个数,将拥有最小距离的两个类簇Ci,Cj进行合并,合并后的新类簇记为Cw,Cw的中心点计算方法如下:
(1)
Cw的代表点集为Cw.rep,计算方法如下:
式中,Xp∈U,Xp={Xp1,Xp2,…,XpR},α是收缩因子,R表示代表点数目.
定义5[4].将任意两个类簇Ci,Cj之间的距离定义为:
式中,Ci.rep和Cj.rep分别是类簇Ci和Cj的代表点集,m为样本属性数目,vis和vjs分别为样本Xi和Xj的第s维的属性值.
3 算法描述与分析
3.1 集对信息距离度量
聚类分析通过对一组样本进行分组任务,使得同一组中的样本比其它组中的样本更相似.样本间距离的度量是影响聚类效果的关键之处,然而由于缺失值的存在,一些常用的计算相似度的方法不能直接用于计算不完备数据之间的相似度,为此,本文基于集对信息粒理论,提出了基于集对联系度的距离公式,将原本聚类过程中不同样本之间的距离扩展成包含正同度、差异度和负反度3个维度的距离定义,能有效处理含有缺失值的不完备数据集.
定义6(集对联系度).任意给定两个样本Xi和Xj,每个样本Xi={vi1,vi2,…,vim}由m个属性A1,A2,…,Am描述,设定阈值ε1,ε2(ε2>ε1),将样本Xi和Xj建立集对联系度,令满足|vis-vjs|≤ε1(1≤s≤m)的记为正同信息粒S,满足|vis-vjs|≥ε2的记为负反信息粒P,满足ε1<|vis-vjs|<ε2以及缺失的属性值均记为差异信息粒F,则建立的集对联系度公式为:
(2)
式中,N代表属性值的总数目,S代表属性值数据差的绝对值小于等于ε1的数目;P代表属性值数据差的绝对值大于等于ε2的数目;F代表其它属性值数目,其包括缺失的属性值.
式(2)也可以简化为:
ρij=a+bi+cj
(3)

定义7(势函数).对于一个三元联系数ρ=a+bi+cj,其势函数记为:
(4)
定义8(样本间集对距离度量).两个样本Xi和Xj之间建立的三元集对联系度为ρij=a+bi+cj,为了衡量两个样本之间的距离大小,将以集对联系度中的正同度a以及联系数的势函数Shi(ρij)来反映两个样本之间的距离大小,其公式为:
(5)
式中,d(Xi,Xj)越小说明两样本之间的距离越小.a用来衡量样本间确定性距离的大小,a越大表示确定性距离越小,Shi(ρij)用来衡量两样本之间的距离变化趋势,Shi(ρij)越大表示距离变大的趋势越小.

式中,maxv.j,minv.j表示第j个属性的最大值,最小值.特别注意的是,进行距离度量时所需的数据为标准化之后的数据.
定义10(类簇间距离度量). 将类簇Ci和Cj合并后的类簇记为Cw=Ci∪Cj,类簇Cw中的第一个代表点记为p1,其选取公式为:
p1=max{Xd(Cw.mean,X)(X∈Ci.rep∪Cj.rep)}
(6)
剩余R-1个代表点的选取,按照公式:
(7)
将取出的R个点记为新类簇的代表点集Cw.rep,再将选取的代表点根据收缩因子α进行收缩,收缩后的代表点集记为Cw.zoom_rep,其公式为:
Cw.zoom_rep=p+α*(Cw.mean-p)(p∈Cw.rep)
(8)
任意两个类簇Ci和Cj之间的距离结合式(5)定义为:

(9)
式中,R代表选取的固定代表点的个数,p为类簇中选取的将要收缩的代表点,Ci.zoom_rep,Cj.zoom_rep,Cw.zoom_rep代表收缩后的代表点集.需要注意的是,选取新类簇代表点集Cw.rep时,待选取的点是类簇Ci和Cj中未收缩的代表点集Ci.rep和Cj.rep中的点,进行类簇间距离计算时,需要将代表点进行收缩,选取收缩后的代表点间的最小距离作为类簇间的距离.

表1 类簇Cw的部分距离信息Table 1 Partial distance information for cluster Cw
例:对类簇Ci和Cj进行合并,合并后的类簇记为Cw,假设类簇Ci和Cj的代表点个数为3,其中代表点为X1,X2,X5∈Ci.rep,X3,X4,X6∈Cj.rep,表1给出的是类簇Cw的部分距离信息,包含样本点Cw.mean,X1,X2,X3,X4,X5,X6中任意两者之间的距离,选取代表点的过程如图1所示,最后得到的类簇Cw的代表点为X3,X5,X6.

图1 代表点选取过程Fig.1 Represents the point selection process
定义11(类内平均距离).根据建立的集对距离度量方式,对各个类中样本Xi∈Cj(1≤i≤n,1≤j≤k)与该类簇中心点Cj.mean进行距离计算,得到n个距离值,d(X1,Cj.mean),d(X2,Cj.mean),…,d(Xn,Cj.mean),由此定义类内距离的平均值为:
(10)
3.2 集对粒聚类结果表示
在集对信息粒空间中,定义了3种信息粒集:正同粒集、差异粒集和负反粒集,正同粒集和负反粒集属于确定信息粒,差异粒集属于不确定信息粒,这3种信息粒集与聚类中存在的3种关系相一致,因此将集对信息粒的思想引入到CURE聚类中,形成基于集对信息粒的聚类结果.从集对信息粒中的3种信息粒集的概念出发,提出了以正同域Cs,边界域Cu和负反域Co组成的集对粒层次聚类,其中正同域中的样本一定属于这个类簇,边界域中的样本可能属于这个类簇,负反域中的样本不属于这个类簇,其具有如下性质:
i)Cs(Ci)≠Ø
iii)Cs(Ci)∩Cs(Cj)=Ø,i≠j
性质(i)表明每个类簇的正同域不是空集且至少有一个样本;性质(ii)表明每个样本都必须进行聚类分析;性质(iii)表明任意两个类簇的正同域相交为空集.
3.3 算法描述
1)算法思想

C={{Cs(C1)∪Cu(C1)},{Cs(C2)∪Cu(C2)},…, {Cs(Ck)∪Cu(Ck)}}.
其中,Cs(Ck)是类Ck的正同域,Cu(Ck)是类Ck的边界域,正同域和边界域共同构成一个类簇,图2展示的是一个类簇的聚类结果.

图2 SPGCURE聚类示意图Fig.2 SPGCURE clustering diagram
2)数据结构
U={X1,X2,…,Xn}:输入数据集,n为样本点的个数;
Xi={vi1,vi2,…,vim}:样本点,通过m个属性A1,A2,…,Am进行描述;
Ci:储存每个类簇中的样本点;
Ci.mean:储存类簇的中心点;
Ci.rep:储存类簇的代表点;
Ci.zoom_rep:储存类簇收缩后的代表点;
Ci.losest:用来跟踪距离每个类簇Ci最近的簇;
d{Xi,Xj}:表示两个样本点之间的距离;
d{Ci,Cj}:表示两个类簇之间的距离;
Heap结构:将各个类簇根据与其最近簇之间的距离,按照递增顺序布置在堆中;
k-d tree结构:用来存储每个类簇的代表点的数据结构.
3)算法流程
算法.SPGCURE clustering
输入:从原数据集中抽取的随机样本,记为样本集U={X1,X2,…,Xn},聚类数目k,代表点个数R,收缩因子α
输出:集对粒层次聚类结果:C={{Cs(C1)∪Cu(C1)},{Cs(C2)∪Cu(C2)},…{Cs(Ck)∪Cu(Ck)}}
1.T:=构建kd_tree(U);
2.Q:=构建heap(U);
3.whilesize(Q)>kdo
4. 提取Q中顶部元素Ci,寻找Ci的最近簇Ci.closest=Cj,并从Q中删除Cj;
5. 将Ci与Ci.closest=Cj合并为Cw=Ci∪Cj,公式(6)-公式(7)计算得到Cw的代表点集Cw.rep;
6. 将Cw的代表点插入到T中,并从T中删除Ci和Cj的代表点;
7. 寻找并设置Cw的最近簇Cw.closest;
8. forQ中的任意一个类簇Cqdo
9. ifCiorCj是Cq的最近簇或Cw成为Cq的最近簇
10. 重新计算Cq的最近簇,并在Q中重新定位Cq;
11. end if
12. end for
13. 将Cw插入到Q中;
14.当类簇总数减少到k时,删除异常点;
16.fori=1,2,…,ndo
17. 计算各个样本Xi与其所在类簇Cj.mean(1≤j≤k)的距离:d{Xi,Cj,mean};
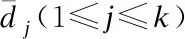
20. 将样本Xi划分到正同域Cs(Cj);
21. else
22. 将样本Xi划分到边界域Cu(Cj);
23. end if
24.end for
26.fori=1,2,…,n′ do

30. 将样本划分到Cj的正同域;
31. else
32. 将样本划分到Cj的边界域;
33. end if
34.end for
35.returnC={{Cs(C1)∪Cu(C1)},{Cs(C2)∪Cu(C2)},…{Cs(Ck)∪Cu(Ck)}}
4)聚类分析
第1阶段(步骤1-步骤14):步骤1-步骤2是对数据结构进行初始化,将所有输入样本点作为代表点插入到k-d tree中,Heap的构建是通过距离公式(9)确定任意两个簇之间的距离,由此得到每个输入点的最近簇Ci.closest,然后按照距离递增的顺序将每个类簇插入到heap中.步骤3-步骤13是层次聚类迭代的过程,根据迭代的次数不同,可以获得不同层次的聚类结果,其中步骤5是计算新合并的类簇Cw的代表点,要注意的是若类簇中样本点的个数少于固定代表点个数,则将所有点记为代表点.

SPGCURE聚类算法的流程框图如图3所示.

图3 SPGCURE聚类算法流程框图Fig.3 SPGCURE flow block of clustering algorithm
5)时空复杂度
时间复杂度:设数据集的样本点个数为n,在第1阶段,算法的计算量主要由while循环产生.在while循环内,计算量最大的是for循环,产生的复杂度为O(nmlogn)[4],m是计算最近簇过程中参数调用的次数,另外步骤5中合并两个类簇产生的复杂度由原CURE算法中的O(n)减少为O(1).由于while循环的主体被执行O(n),且在其每一次迭代中有for循环的O(n)次迭代,故第1阶段的时间复杂度为O(n2mlogn).在第2阶段,计算量主要由for循环产生,k为类簇数目,n为样本点数目,产生的时间复杂度为O(kn).第3阶段是将未抽取的样本进行划分,产生的时间复杂度为O(kn′),n′是未抽取的样本个数.所以本文的时间复杂度为O(n2mlogn+kn+kn′),即为O(n2mlogn).根据文献[20]可得,m的取值通常比n小很多,因此当数据点的维数较小时,聚类算法的时间复杂度为O(n2logn),虽然增加了以正同域、差异域和负反域的划分,但仍与原CURE算法的时间复杂度保持一致.
空间复杂度:算法用到的heap和k-d tree两种数据结构,其二者都需要线性空间,则聚类算法的空间复杂度为O(n).
4 模型验证
为了验证所提出的SPGCURE算法的性能,在实验部分选取了5个数据集进行测试,主要进行了3方面实验:1)对自身算法进行性能分析;2)以不完备数据集为实验数据,将本文算法SPGCURE与两种可以处理不完备数据的算法进行对比分析,分别是Su等基于q近邻提出的不完备三支聚类TWD-QNN[21]以及Yang等基于密度峰值提出的不完备三支聚类算法,依照原文将其记为Adopted methods[22];3)以完备数据集为实验数据,选取了经典聚类算法k-means[23]和CURE[4],以及近几年提出的三支聚类算法CE3-k-means[14]、TCM[15]和3W-DBSCAN[16]进行对比分析.
本文所提算法和对比算法是在一台MBP(macOS Catalina 10.15.3,Quad-Core Intel Core i5 CPU@ 2.3 GHz,8 GB 2133 MHz LPDDR3)上使用Anaconda 2019.10环境实现的.
4.1 数据集
所选数据集的样本个数最小为150,最大为5473;数据集的属性个数最小为4,最大为34,实验中涉及的这5个数据集都是来自UCI数据库,数据集的详细信息如表2所示.

表2 实验数据集信息Table 2 Information on experimental data sets
4.2 评价标准
聚类评估是评估学习方法在确定相关集群方面的性能的关键过程.良好的聚类质量测量将有助于比较几种聚类算法的优劣,以下评价指标通常用于评估聚类算法的性能.
1)准确率(Accuracy)
式中,n为样本的总数,θk为簇Ck中正确划分的样本数目.
2)F-measure同时兼顾精确率和召回率,是其二者的调和平均数,公式为:
式中:

式中TP表示真实为正,预测也为正的个数,FP表示真实为负,预测为正的个数,FN表示真实为正,预测为负的个数.
3)调整兰德系数(ARI)
4)标准互信息(NMI)
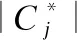
4.3 实验结果与分析
4.3.1 SPGCURE算法性能分析
算法中涉及到了4个参数:ε1,ε2,k和α.为了使得聚类效果最佳,以Iris数据集为例对这4个参数讨论的结果进行展示.由Guha的研究得知[4],代表点的个数k一般选取大于10的值,对于收缩因子α的值,一般选取0.2-0.7中的值,故这两个参数在此范围内进行实验讨论.本文的研究对象包括完备数据集和不完备数据集,为了模拟含有缺失值的不完备数据集,则将数据集中样本的属性值按照5%、10%、15%和20%的比例进行缺失化处理.对随机生成的不完备数据集,根据评价指标ARI和NMI对不同阈值下的聚类结果进行评价.

图4 数据集Iris的阈值变化曲线Fig.4 Threshold variation curve of the dataset Iris

表3 算法性能分析Table 3 Algorithm performance analysis
图4给出的是在缺失率10%下,两个评价指标随着阈值ε1,ε2的改变的波动情况.从图4中可以看出在ε1=0.1,ε2=0.11的情况下,ARI和NMI的值达到最大,使得聚类结果最优.表3中给出的是在最优阈值ε1=0.1,ε2=0.11下,对应不同缺失率下的聚类结果,通过评价指标ARI和NMI可以分析出,随着数据中缺失率的增加,聚类的性能会有所下降,导致下降的原因是缺失数据越多,具有的不确定性越高,相应做出错误分类的可能性就越高.

表4 数据集Iris在不同收缩因子下的聚类结果Table 4 Clustering results of Iris under different shrinkage factors
同样,为了算法的聚类效果最佳,对收缩因子α和代表点的个数k也进行了实验讨论.表4中给出的是Iris数据集在收缩因子为0.2-0.7之间的聚类结果,实验结果显示在α=0.6时达到的最优聚类,ARI的值为0.835,NMI的值为0.851.表5是针对Iris数据集,选择对代表点的个数最少为5,最多为25,步长为5的聚类结果进行了展示,在实验过程中,发现当k的值超过20对聚类结果产生的影响不大,故本文选择最佳代表点个数为20.对于其他4个数据集通过实验的方式,也得出了最佳参数的值,具体结果如表6所示.

表5 数据集Iris在不同代表点下的聚类结果Table 5 Clustering results of the dataset Iris under different representative points

表6 5个数据集的最优参数情况Table 6 Optimal parameters for the five datasets

图5 数据集Iris的集对粒层次聚类结果Fig.5 Set pair granule hierarchical clustering results of Iris data set
在最优参数下,对数据集Iris的集对粒层次聚类结果进行了可视化,如图5所示,数据集聚成了3个类簇,分别用圆圈,菱形和方块区分,另外针对每个类簇的正同域和边界域,是以同符号的实心和空心进行区分.从图5中可以看出正同域中的样本位于类簇的中心区域,与该类簇具有较强关系,边界域中的样本位于类簇的边缘区域,与该类簇具有较弱的关系.
4.3.2 与其它算法对比分析—不完备数据集
本文所提算法既可以用于处理不完备数据集,也可以处理完备数据集,运用随机生成的不完备数据集将本文算法SPGCURE与其它两个聚类算法TWD-QNN、Adopted methods进行对比,通过评价指标Accuracy得到的聚类结果见表7.

表7 不完备数据集的聚类结果对比Table 7 Comparison of clustering results of incomplete data sets
在表7中可以看到,在Iris和Page-blocks数据集中,所提出的SPGCURE算法的准确性高于比较算法.在Ionosphere数据集中,即使它不是最好的算法,但准确性确实接近最好的比较算法.此外,这3种聚类算法表明,随着缺失率的增加,算法的聚类效果会降低,这也与实际一致,缺失的属性值越多,原始信息的保留越少.本文所提算法还实现了即使缺失率增加,精度也不会大幅下降.
4.3.3 与其它算法对比分析—完备数据集
本文所提的集对粒层次聚类算法,不仅是在CURE基础上改进得到了3个域表示的聚类结果,而且涉及到了划分的思想,故对于完备数据集,选择k-means、CURE、CE3-k-means、TCM和3W-DBSCAN算法进行对比分析.对于本文算法SPGCURE,CE3-k-means和3W-DBSCAN分别使用下界(所有簇的正区域Cs)和上界(所有簇的正区域和边界区域Cs∪Cu)来计算评价指标F-measure.由于原TCM算法中只计算了一个聚类结果,故k-means、CURE和TCM的聚类结果被认为是上界的性能.通过评价指标F-measure得到的聚类结果见表8.
如表8所示,CE3-k-means、3W-DBSCAN以及本文所提算法SPGCURE,对于几乎所有数据集,评价指标均在下界给出了较低的值,在上界给出了较高的值,归因于这两个集合是通过对二支聚类的收缩或扩展一些样本得到的,上界的性能优于下界是合理的.为了更清楚地比较不同算法的性能,针对上界(Cs∪Cu)的聚类结果,生成了如图6所示的曲线图;针对下界(Cs)的聚类结果,生成了图7所示的柱状图.可以清楚的看到,在Seeds,Contraceptive和Page-blocks数据集中,SPGCURE算法在评价指标F-measure下得到的聚类结果均优于比较算法,最优的结果已用加粗标记,对于Ionosphere数据集,最优的算法虽是3W-DBSCAN,F-measure值达到0.831,但其在Ionosphere数据集的下界中得到的结果却是最差的,仅为0.391.从图7分析得出,单独考虑在下界(Cs)中得到的结果,算法SPGCURE在Seeds,Ionosphere和Page-blocks这3个数据集中,均得到了最优聚类结果.总体来说,SPGCURE算法不仅实现了可以处理不完备数据集聚类问题,而且得到了较好的聚类效果.

表8 完备数据集的聚类结果对比Table 8 Comparison of clustering results of complete data sets

图6 F-measure下不同数据集的方法差异Fig.6 Differences in methods on different datasets under F-measure

图7 F-measure下针对下界(Cs)不同方法的比较Fig.7 Comparison of different methods for lower bounds (Cs) under F-measure
5 结 论
在聚类的实际应用中,样本与类簇之间实际上存在3种关系,并且由于数据遗漏、读取限制等原因存在大量不完备数据集,为此,本文提出了一种面向不完备数据的集对粒层次聚类算法-SPGCURE.对于缺失的属性值,采用集对信息粒的相关理论进行处理,将原本聚类过程中不同样本之间的距离扩展成包含正同度、差异度和负反度3个维度的距离定义,可以更加全面的对不完备数据集进行距离度量.另外,为了更好地表示样本与类簇之间的关系,基于改进后的距离度量,给出了各个类簇的类内平均距离的定义,提出了以正同域Cs,边界域Cu和负反域Co表示的集对粒层次聚类.通过对5个数据集在指标ARI,NMI,Accuracy和F-measure上的值对聚类性能进行评价,并且选取了7个算法进行对比分析,实验结果表明,SPGCURE具有较好的性能.然而,阈值ε1,ε2的变化会对聚类结果产生较大的影响,如何确定参数也是下一步的工作,其将会对聚类性能的提高有重要影响.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
学生导报·东方少年(2019年27期)2019-01-14
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
读写算·小学低年级(2015年12期)2015-12-12
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
西南学林(2011年0期)2011-11-12
