
藏文文本分类技术研究综述
2021-03-22 02:53苏慧婧群诺
电脑知识与技术 2021年4期
苏慧婧 群诺

摘要:该文介绍了藏文文本分类技术的研究与进展。首先对现阶段常用的文本表示以及文本特征选择方法进行了分析和比较,接着回顾了藏文在机器学习方面的分类算法特点,深入讨论了不同算法应用在藏文文本分类技术上的研究情况,最后指出了当前藏文文本分类所面临的问题和挑战,并对未来的研究提出了建议。
关键词:藏文文本分类;文本表示;特征选择;机器学习
中图分类号: TP391 文献标识码:A
文章编号:1009-3044(2021)04-0190-03
Abstract :This article introduces the research and development of Tibetan text classification technology. First, it analyzes and compares the commonly used text representation and text feature selection methods at this stage, then reviews the characteristics of Tibetan classification algorithms in machine learning, and discusses the application of different algorithms in Tibetan text classification technology. Finally, it points out the current problems and challenges of Tibetan text classification, and puts forward suggestions for future research.
Key words :Tibetan text classification; text representation; feature selection; machine learning
自然語言是人们日常使用的语言,是人类学习生活的重要工具。为此,自然语言处理是人工智能的一个重要应用领域,也是新一代计算机必须研究的课题。随着我国藏族聚居区信息化事业的快速发展,藏族网民人数快速增长,以藏语为载体的内容也在增多。对藏文文本分类技术的研究,能够拓宽藏文信息处理的应用领域,推动藏文语言文学在网络时代的发展。文本特征的表示方法和分类器模型的设计是有关文本分类技术的关键步骤,本文简要提出了文本分类系统的各个功能,依据现阶段藏文文本分类技术的研究进展,详细分析了文本表示以及特征选择的不同方法和多种分类器模型的算法特点和应用前景。目前,我国对藏文古籍文献的经典信息需求量很大,因此,针对藏文文本,深入研究高效精准的文本分类技术,具有十分重要的现实价值和历史意义。
1 藏文文本分类研究现状和发展趋势
在信息化时代背景下,藏文文本分类技术作为藏文信息处理的一个重要组成部分,在情感分类、检测垃圾邮件、用户意图识别、客服工单自动分类等方面应用广泛。贾会强[1]等人提出了基于规则的藏文文本分类方法;才让加[2,3]等人对藏文语料进行分词标注并利用词性特征建立分类语料库;孟祥和[4]提出了基于改进的聚类算法和KNN分类算法实现藏文网站话题发现与跟踪;袁斌[5]提出选用不同情感特征表示,基于SVM+TF-IDF进行藏文微博情感分类能达到比较不错的效果;周登[6]采用基于N-Gram模型的藏文文本分类技术;安见才让等人[7]实现了互联网藏文信息舆情分析的系统设计;胥桂仙等人[8]设计了基于栏目的藏文网页文本自动分类系统。贾宏云等人[9,10,11]分别选用藏文词以及n-gram的藏文音节作为文本特征,采用信息增益算法、前向逐步回归算法筛选最优特征子集进行文本表示,基于Logistic回归模型、SVM模型以及AdaBoost模型实现藏文文本分类并取得了不错的进展。王莉莉等人[12]采用长短时记忆加条件随机场模型的方法对藏文分类文本进行分词,运用TF-IDF公式计算特征权重得到向量空间模型以进行文本表示,通过互信息方法提取和选择特征,基于多种深度神经网络模型得到了较好的分类结果,但是该文选用的数据集在类别数量以及文本规模上都相对较少,这将使得分类模型性能不够稳定,泛化能力较低。
在目前藏文文本分类研究中,已有少量基于规则和使用传统机器学习方法的分类研究,将神经网络模型应用于藏文文本分类的研究仍处于最浅显层面,又因为平台上缺乏开源的藏文语料,而每个研究人员所使用的语料也大不相同,因此使得实验研究数据缺乏可比性,其分类准确率难以评估与分析。通过借鉴中英文中较为成熟的文本分类方法,如何在资源不足的条件下训练模型,如何将人类的先验知识融入神经网络中是藏文文本分类面临的挑战和亟待解决的难题。
2 藏文文本分类相关技术
藏文文本分类由四个模块组成:藏文语料获取、文本表示以及特征选择、模型训练、模型性能评价。
2.1 藏文语料获取
在对文本进行分类之前,首先要获取藏文语料,建立藏文数据集。我们可以从网上爬取藏文语料或者下载别人整理好的数据集,对其进行预处理,通过预处理过程,减少特征维数、去除噪声特征,以此提高机器学习算法的精准度和分类效果。过程包括分词、剔除符号和停用词,按类别进行人工分类,再按一定比例划分训练集和测试集。
2.2 分词
在英语的分词中,词与词之间具有很自然的空格作为标记,而对于藏文分词,藏文与汉语相同,文档的词语之间没有明显的分隔标志。藏文分词领域的主要困难在于词义消歧、命名实体识别。藏文自动分词技术主要有以下4类:
①通过最小匹配或最大匹配、正向匹配或逆向匹配方法切分字符串的机械分词方法;
②根据字符串的语义、句法信息进行词性标注的基于规则的分词方法;
③通过匹配方法然后将统计语言模型引入分词过程的基于统计的分词方法;
④基于统计与规则相结合的方法,目前使用最为广泛的是第四种方法。
2.3 剔除符号和停用词
在文本预处理过程中,会剔除掉对分类结果没有实际意义的词语和符号,比如藏文文本中存在的一些特殊符号、标点符号以及数字等。通过构造停用词表剔除掉这些對文本分类无意义的词项,利用已建好的藏文语料库,使用公式n/N来计算权重,(n表示文档中出现词w的文档数,N表示总的文档数),把其中权重高过某一阈值的词列入停用词表,阈值将由具体实验确定。
2.4 藏文文本分类特征工程
对于计算机而言,它不能够识别普通的文本中的字符串所要表达的信息,因此必须对文本中的字符串进行处理,这样的过程称为文本表示。藏文文本一般以音节为特征单位,按照一定的描述模型对文本进行表示,使机器能够对文本进行处理和运算。
2.4.1 文本表示
在藏文文本分类过程中,主要采用向量空间模型进行文本表示。向量空间模型以空间上的相似度表达语义的相似度,表示如下:[V(d)=((t1,a1),(t2,a2),...,(tn,an))],其中,[ti]为文档 d 中的特征项,[ai] 为[ti] 的特征值,一般取为词频的函数。有了这样的表示以后,就可以用分类器对样本分类。
2.4.2 文本特征选择
藏文语料文本经过处理,从文本中产生的特征数量可能非常庞大,特征空间的维数会高达几万维甚至几十万维。如果用这些特征向量来进行分类训练,不但会占用很大的存储资源,造成时间和空间的浪费,而且还会极大地影响分类算法的运行速度和降低分类准确度。为此可构造一个评价函数,通过实验设定一个阈值α,当评估分数低于阈值α就予以删除,高于阈值α的若干特征项重新组成一个新的低维特征空间。利用特征评价函数来计算每个特征的重要程度。目前,在藏文文本分类的研究过程中,常被运用的特征选择评估函数有逆文档频率(TF-IDF)、文档频率(DF)、互信息(MI)、信息增益(IG)、c2统计(CHI)、期望交叉熵(ECE)等。
大量的实验结果表明,过高的特征维数会导致时间空间复杂度急剧增加,造成更大的计算代价;特征项维数过低则可能造成文档重要信息的丢失,对文本的分类效果造成影响。所以如何高效地选择和提取特征,进行文本特征表示需要综合多种算法,反复实验。
2.5 分类器的选择与训练
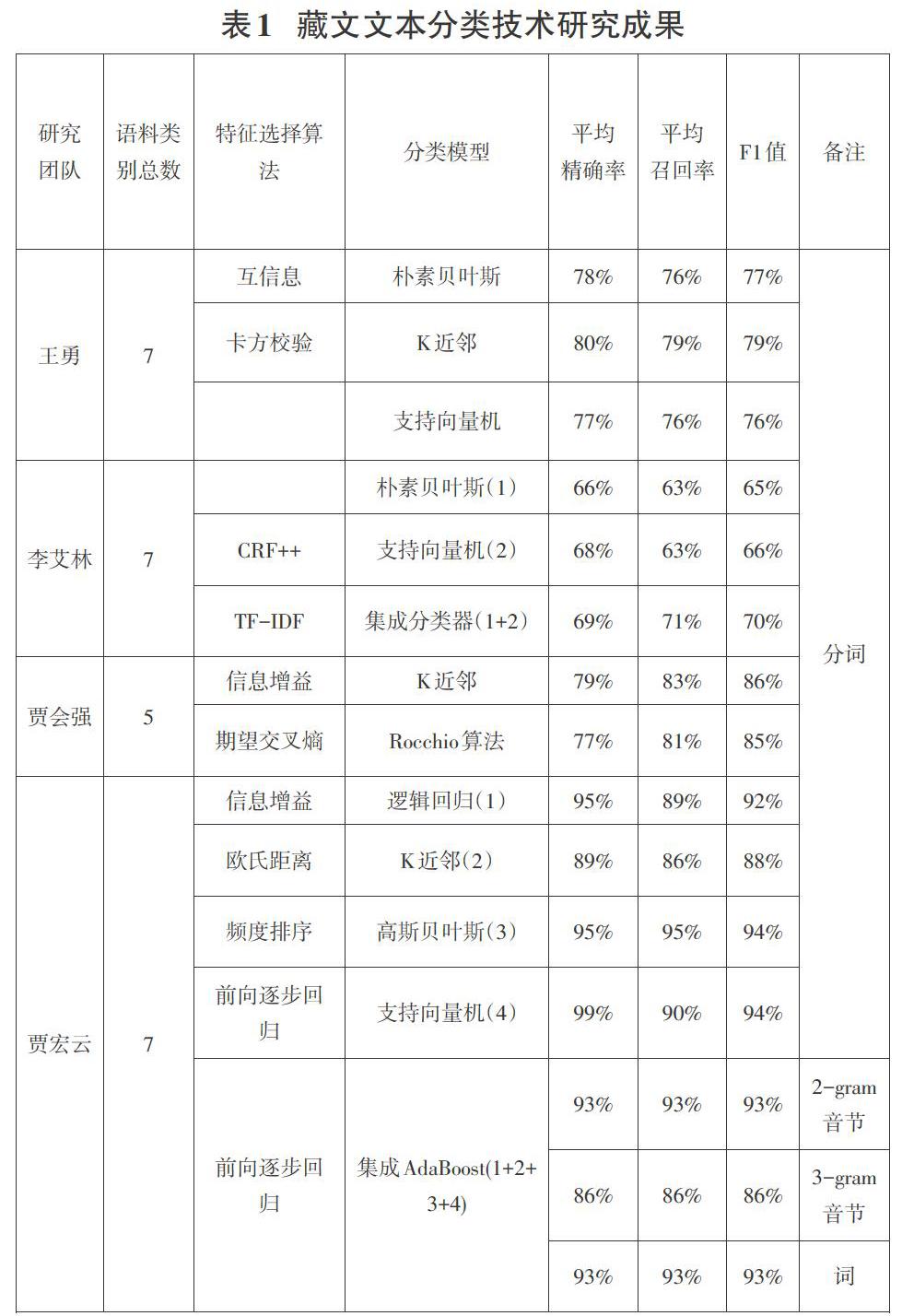
现阶段,有关中英文的文本分类模型种类很多,实际应用也相当成熟,在藏文文本分类研究领域,最近几年藏文文本分类技术研究的成果见表1所示。
表1实验中针对实际语料,选用特定特征选择算法进行特征降维和提取有效特征,基于浅层机器学习模型进行文本分类,可以看出将多种算法集成的分类模型可以有效提升分类效果。但这些算法大都需要人工参与定制规则,并且分类模型泛化能力较低。朴素贝叶斯算法简单,分类效果稳定;所需估算的参数少,但此算法适用于小规模数据的训练,且需要假设属性之间相互独立,而实际中往往难以成立。支持向量机可用于高维数据的计算,但对缺失数据较敏感;针对非线性问题没有通用的解决方案。近年来兴起的深度神经网络具有较强的并行处理能力,自学习能力强,能解决复杂的非线性关系,具有记忆的功能,但是在神经网络训练过程中需预先确定大量参数,且所得信息高度编码不易被解读,输出结果难以解释。
综合分析以上算法的优缺点,本文选用K近邻(KNN)、高斯贝叶斯(Gaussian NB)两种浅层机器学习模型算法和多层感知机(MLP)、深度可分离卷积(SepCNN)两种神经网络模型进行分类实验,整理实验数据,得到表2。
从表2实验数据可以看出,在大规模数据集下,基于深度学习的神经网络模型比基于浅层机器学习的单一模型分类效果要好,避免了烦琐的人工特征工程,节省了部分人力开销。因此研究文本分类,其方法与模型的选择和要解决的问题及问题的规模有关,根据文本分类的各个流程采取对应的解决办法,是当前藏文文本分类研究的重要方向。
2.6 分类结果的评价与反馈
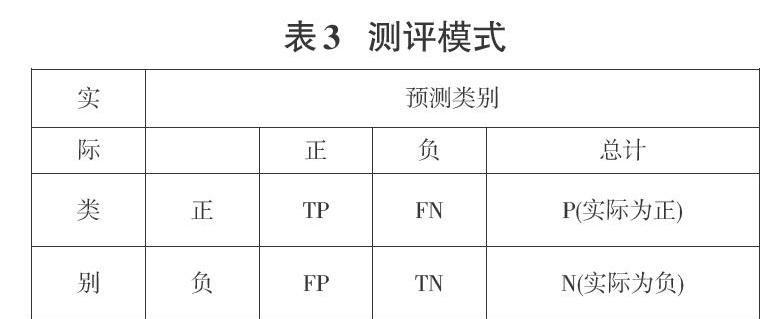
模型最终常用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值来对分类器的性能进行综合评价。假设只有两类样本,即正例(positive)和负例(negative)。TP表示将实际正类预测为正类预测正确的数值,FN表示将实际正类预测为负类预测错误的数值,FP表示将实际负类预测为正类预测错误的数值,TN表示将实际负类预测为负类预测正确的数值[13]。形成表3如下所示。
表中AB模式:第二个符号表示预测的类别,第一个表示预测结果对了(True)还是错了(False)。分类准确率(accuracy):分类器正确分类的样本数与总样本数之比, 精确率(Precision)反映了模型判定的正例中真正正例的比重,召回率(Recall)反映了总正例中被模型正确判定正例的比重[13]。F值是精确率和召回率的调和平均。各测评标准如表4所示。
3 面临的问题与挑战
目前藏文文本分类技术依旧面临着诸多问题与挑战。由于藏文信息处理技术缺乏统一规范化的标准,导致部分网页藏文资源字符编码方式不统一,使得计算机不能有效处理藏文字符;现阶段该领域还未能研究出较为成熟的分词技术;藏文文本分类的相关技术大都借鉴汉语、英语的处理方法,针对藏语自身的特点和规律研究欠缺;近年来发展较成熟的word2vec词向量预训练模型在藏文方面的迁移应用研究尚浅;藏文信息方面不仅缺少开源语料,也缺少基于深度学习取得的成果,这些问题都制约了藏文文本分类技术的研究与发展。
4 结束语
本文总结了到目前为止藏文文本分类技术的研究现状,分析了当前研究所面临的问题与困难,并针对问题的解决和未来的研究提出了建设性的建议。藏文文本分类系统和其他语种的文本分类系统相比还存在着很大的差距,对于藏文自身的语言特点,适用于大语种的研究方法并不能完全适用于藏文的研究。因此,对藏文在文本分类的基本理论和处理模型上进行针对性的创新是我们未来的研究方向。后续希望研究者能够不断对比各种分类技术并且参考各领域最新的文本分类的研究成果,在深度学习方法上,寻求突破,探讨实践出更加优化的藏文文本分类系统。
参考文献:
[1] 贾会强,李永宏.藏文文本分类器的设计与实现[J].科技致富向导,2010(12):30-31.
[2] 才让加.藏语语料库加工方法研究[J].计算机工程与应用,2011,47(6):138-139,146.
[3] 才让加,吉太加.藏语语料库的词性分类方法研究[J].青海师范大学学报(哲学社会科学版),2005,27(4):112-114.
[4] 孟祥和.藏文网站话题发现与跟踪技术研究[D].西北民族大学,2013.
[5] 袁斌.藏文微博情感分类研究与实现[D].西北民族大学,2016.
[6] 周登.基于N-Gram模型的藏文文本分类技术研究[D].西北民族大学,2010.
[7] 安见才让,拉毛措,孙琦龙.互联网藏文信息舆情分析系统设计[J].微处理机,2017,38(2):56-58,63.
[8] 胥桂仙,向春丞,翁彧,等.基于栏目的藏文网页文本自动分类方法[J].中文信息学报,2011,25(4):20-23.
[9] 群诺,贾宏云.基于Logistic回归模型的藏文文本分类研究与实现[J].信息与电脑(理论版),2018(5):70-73.
[10] 賈宏云,群诺,苏慧婧,等.基于SVM藏文文本分类的研究与实现[J].电子技术与软件工程,2018(9):144-146.
[11] 贾宏云.基于AdaBoost模型的藏文文本分类研究与实现[D].西藏大学,2019.
[12] 王莉莉,杨鸿武,宋志蒙.基于多分类器的藏文文本分类方法[J].南京邮电大学学报(自然科学版),2020,40(1):102-110.
[13] 郑雅文. 基于特征选择和支持向量机的乳腺癌诊断研究[D].太原理工大学,2019.
【通联编辑:唐一东】
猜你喜欢
电子制作(2017年23期)2017-02-02
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
电测与仪表(2016年23期)2016-04-12
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
振动工程学报(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
