
基于网络日志的用户行为检测和画像构建系统
2021-03-24 11:26倪建伟李伟龙董文洁庄彦诚
计算机时代 2021年2期
关键词:用户画像
倪建伟 李伟龙 董文洁 庄彦诚


摘 要: 用户画像可以帮助企业更多地了解用户,从而更好地制定决策。目前,大多数用户画像构建模型均依赖于应用厂商提的内部数据,而数据源的局限性可能难以保证用户画像的精准性。文章利用网络设备中的多源访问日志,基于知识数据库构建和指纹匹配技术,设计了一种新的用户画像构建架构,并借助Pyspider和Hadoop分布式框架提高数据采集和画像生成的计算效率。大量实验表明,该方法可以比现有模型构建出更全面、更准确的用户画像。
关键词: 用户画像; 网络日志; 知识数据库; 指纹匹配; 分布式框架
中图分类号:TP391.1;TP392 文献标识码:A 文章编号:1006-8228(2021)02-42-04
Abstract: User portrait can help enterprises know more about users and do better decision-making. At present, most user portrait building models rely on the internal data provided by application vendors, and the limitations of data sources may be difficult to ensure the accuracy of user portrait. In this paper, by using the multi-source access logs recorded in the network node equipments, new user portrait architecture based on knowledge database construction and fingerprint matching is designed, meanwhile the computing efficiency of data acquisition and portrait generation is improved with the help of Pyspider and Hadoop distributed framework. A large number of experiments show that this method can build more comprehensive and accurate user portraits than that of the off-the-shelf models.
Key words: user portrait; access log; knowledge database; fingerprint matching; distributed framework
0 引言
隨着信息技术的不断发展,大量的传统行业正逐渐向着信息化转型。在此环境下,越来越多的企业开始重视通过数据对用户建立特征认知,进而更好得为各类业务决策进行辅助。互联网的普及使得PC和移动设备的日常使用频率大幅上升,在此过程中,各类软件应用记录了海量的用户操作日志,包括页面点击、浏览、添加、关注等原始用户交互行为数据。此类操作行为日志可以为,给每个用户打上标签从而实现精准推荐、客户分类、兴趣挖掘等任务提供有效数据支持。
当下,用户画像是使用范围最广的用户偏好刻画的概念,其概念最早由交互设计之父Alan Cooper提出,通过对现实生活中用户的各类数据的建模,最终以标签的形式对用户进行画像刻画。目前,用户画像已在互联网金融、电商营销等领域均取得了较好成效[1]。同时,当前用户画像的构建的数据源多是采用企业内部数据,因此所得画像存在一定的局限性。
除了各类应用厂商所掌握的内部数据外,网络设备中记录的访问日志来源更广泛,信息量更加丰富。运营商、各类公用wifi、公共交换机等所捕捉的访问日志中存在着诸多信息,此类数据通常为一系列的http请求记录,通过分析这些访问请求,可以获取其子网内部(例如一个商场、一个机构)所有用户的画像。但同时,这些数据又十分繁杂和抽象,难以直接从中获取有价值的信息。郭俊霞等提出了一种针对用户网页浏览日志数据的查询和行为分析方法[2],但是没有挖掘出用户查询访问网页的主题。基于上述问题,本文面向公共网关数据,提出了完整构建用户画像的解决方案。
1 整体架构
用户画像是对现实世界中用户的数学建模,把用户的一些行为进行量化,用数学的手段来进行统计[3]。用户画像的本质是深入分析客户,掌握具有实用价值的数据,找到目标客户,根据客户需求制定产品,并利用数据实现价值变现[4]。用户画像的构建过程主要包括对用户的基本信息、行为等数据的采集、过滤、挖掘分析,以标签的形式对用户进行画像刻画,最终依据不同分类标准形成用户特定类型,进而根据不同需求来设计用户画像平台的使用功能和应用流程。
在各类应用的使用过程中,产生的GET、POST等请求均在网关服务器节点的日志中有留存[5]。这些记录涉及到各类用户操作行为,其中蕴含了大量的用户行为、兴趣偏好等内容。与此同时,这些数据又十分抽象和混乱,通常为一串URL集合,无法快速刻画出用户画像,需要对其进行清洗、筛选、映射、匹配等步骤才能转换成有价值的信息。
本文基于上述问题提出了一套基于知识库指纹匹配用户画像构建模型(如图1),主要包括知识库管理模块、指纹匹配模块、用户画像模块。通过一定操作将每一个URL与知识库指纹映射,得到对应用户的标签信息,最终实现基于用户行为日志的画像构建。
2 知识库构建
构建用户画像需要精准的标签体系、真实的数据来源和可靠的逻辑架构。网关日志中的数据均为URL记录,获取每个URL背后隐含的信息需要预先构建对应的知识库,即站点知识库和每个站点下的二级网站知识库。站点知识库体现URL对应域名的信息,包括站点名称、站点类别标签等。网站知识库体现更具化的信息,包括用户每次访问的单品信息和对应的用户标签。
2.1 站点知识库构建
每个域名的基本信息和站点类别标签都存储在站点知识库中,这些信息可以利用数据采集技术从各类网站资源门户中获取。通过与站点知识库的匹配,可以大致映射出用户对每个领域的兴趣程度,为用户贴上基础标签。对于如何构建站点信息的标签体系,程元堃等预先定义了八大主题,构建基于Word2vec的词向量模型,通过词频统计和计算词中心向量的方法确定各主题的特征词及其词向量, 实现了网站主题分类[6],刘如娟基于用户自定义标签并通过聚类提高标签针对性[7]。
2.2 网站知识库构建
与站点知识库匹配获得的标签适用性较广,若要获取更细化的网站内部信息来刻画标签,则需要构建出包含所有站点的网站知识库。基于所构建的网站知识库,利用指纹匹配技术对每一次日志行为进行知识库映射并匹配出对应标签。
网站知识库构建中,最核心的是数据采集模块,利用网络爬虫技术将站点知识库中每个域名下不同网站的网页信息爬取下来。在对网站正文进行数据处理后,结合网站分类标准进行文本分析,得到该网站的标签,导入并更新网站知识库。如果中间有任何一个步骤失败则提交人工进行查看。
在信息每天都以爆炸式速度增长的今天,网站信息数据源过于庞大和分散,同时信息也以极高的频率持续更新,采取传统单节点线性爬虫框架来抓取网站信息会消耗大量时间和资源,导致效率低下。因此本文采用了基于Pyspider的分布式网络爬虫架构,进而大大提高了并发抓取的性能。同时使用了非关系型MongoDB数据库和Redis消息队列搭建了一套分布式爬虫环境,构建多源数据采集框架,提高数据采集的效率和稳定性。
在爬虫实际操作过程中,写入存储介质前需要预先判断写入内容是否已存在于介质中,剔除重复的URL。因此,本文采用Redis消息队列来实现数据的增量爬取,对爬取到的网站进行唯一标识,并将唯一标识存储至Redis的set中。在每一次数据爬取前,首先对将要发起请求的URL是否存在于set中做出判断,如果存在则不进行请求。此外,爬取到网站数据后且持久化存储前,先判断该数据的唯一标识是否存在于Redis的set中,再决定是否进行持久化存储。
将MongoDB中存储的网站信息数据经过字段验证、字段映射、字段清洗,存入较为规整的关系型数据库MySQL中,并为同一域名下的不同二级路由建立各自专属的网站知识库表,存放网站信息和标签信息,以便对记录的于指纹匹配。
3 指纹匹配
指纹库起着将用户、站点知识库、网站知识库连接起来的作用。针对操作日志中每一条用户浏览历史记录,从中提取URL依次与站点库、指纹库、网站知识库进行匹配,提取出标签信息为后续的用户标签构建提供必要的信息。
3.1 指纹库构建
指纹库表中每一条记录都需要有域名信息,从而与站点知识库相映射。同时也需要有不同Patten所对应的网站知识库信息。指纹库样例如表1。
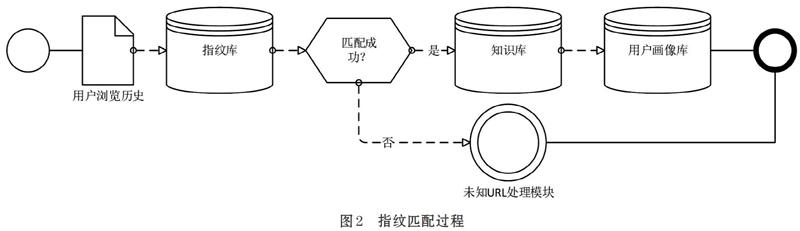
3.2 指纹匹配过程
整个匹配过程包括了知识库匹配、指纹库匹配。针对每一条用户浏览历史记录,从中提取URL信息与知识库、指纹库中的数据进行逐级匹配。如果匹配成功将网站标签提取并用于下一步用户画像构建,若失败则转入未知URL处理模块,将网站URL置入爬虫队列,如图2。
譬如url为http://www.*****.com/tour/210018300的一条记录:
第一步:首先切出域名www.*****.com,然后与站点知识库进行匹配,得相应记录,该站点属于交通旅游,旅游网站类别。
第二步:将该url的路由部分/tour/210018300与指纹库中host=www.*****.com的记录进行正则匹配,匹配到对应的patten, /tour/(\d+),其对应的知识库为traval_A2_wjx。
第三步:在相应的知识库中查询符合id=210018300的记录,再提取网站的标签信息。
第四步:如果无法在网站知识库和指纹库中匹配到的URL,则发送给相应的模块,再次进行网站信息的爬取,并更新网站知识库和指纹库。
4 用户画像构建
4.1 分布式计算框架
借助上述知识库构建和指纹匹配可以实现单条URL的网站匹配和正文信息提取和标签提取,但是在实际生产过程中,操作日记的记录量往往是上百万条,采用单URL匹配过程会使得时间复杂度过于巨大,因此本文提出一套基于Hadoop框架的分布式用户画像构建方法。基于Hadoop分布式并行計算框架能支持高吞吐量的数据访问,与本文所涉及的海量数据应用场景所契合,有助于在指纹匹配过程中采用分布式框架提取URL并进行匹配,提高整体处理效率。
4.2 用户画像可视化
标签体系应当具有原始数据层、事实层、模型层和预测层的层级结构[8]。在指纹匹配完成时,从站点知识库和网站知识库中得到的标签构成了用户动态行为属性信息,将之与用户静态属性信息结合,可以构建一个相对立体、精准的用户画像数据标签体系。再借助一定算法构建该用户画像,对比原有画像库,如果有差异则进行更新。在系统的最终实现过程中,当用户来访时,通过ID匹配用户画像库,借助Echarts将用户的上网频次、支付行为、活跃时间和一周兴趣变化等行为数据用图形化语言表现出来。最终呈现的画像页面如图3所示。
5 结束语
本文针对繁杂的公共网关数据,提出了一種基于知识库构建和指纹匹配技术的新型用户画像构建机制,同时采取分布式存储和计算框架提高了计算效率。整个系统高效充分提炼了用户操作日志信息中的网站信息和时间信息,更加便捷和准确得构建用户画像。系统对于庞大的用户画像库和网站知识库,在利用方式上还不是很成熟和完善,可以在最终的呈现方式和利用方式上再加以改进。
参考文献(References):
[1] 周光华,辛英,张雅洁等.医疗卫生领域大数据应用探讨[J].中国卫生信息管理杂志,2013.10(4):296-300,304
[2] 郭俊霞,高城,许南山等.基于网页浏览日志的用户行为分析[J].计算机科学,2014.41(3):110-115
[3] MobasherB, Dai H, Luo T, et al. Integrating web usage and content mining for more effective personalization[C]//Proceedings of the international conference on e-commerce and web technologies,2000:165-176
[4] 王晓霞,刘静沙,许丹丹.运营商大数据用户画像实践[J].电信科学,2018.34(5):127-133
[5] 黄雅萍,马可辛,周余洪,刘晓强.面向中小企业的电商平台挖掘系统设计[J].计算机时代,2015.4:18-20
[6] 程元堃,蒋言,程光.基于word2vec的网站主题分类研究[J].计算机与数字工程,2019.47(1):169-173
[7] 刘如娟.基于标签聚类与用户模型的个性化推荐方法研究[J].现代情报,2016.36(6):74-78,99
[8] Ng T W H, Lam S S K, Feldman D C. Organizational citizenship behavior and counterproductive work behavior:Do males and females differ?[J].Journal of Vocational Behavior,2016.93(4):11-32
猜你喜欢
数字技术与应用(2017年8期)2017-10-30
商场现代化(2017年18期)2017-10-14
现代情报(2017年6期)2017-07-17
新媒体研究(2017年11期)2017-07-16
电脑知识与技术(2016年32期)2017-03-17
现代情报(2016年10期)2016-12-15
现代经济信息(2016年24期)2016-11-09
电脑知识与技术(2016年7期)2016-05-19
