
辽代历史文化资源知识图谱构建研究
2021-04-01 07:04谭楠楠
大连民族大学学报 2021年1期
刘 爽,谭楠楠,杨 辉
(大连民族大学 计算机科学与工程学院,辽宁 大连116650)
随着语义网的发展,目前互联网上发布越来越多的结构化数据、半结构化数据、非结构化数据,并将其作为链接数据发布。在此背景下,Google在2012年提出知识图谱(Knowledge Graph)这一概念,旨在改善搜索引擎效果[1]。知识图谱以结构化三元组的形式来进行存储,基本组成单位由头实体、尾实体以及描述这两实体之间的关系组成。通用表示方式为G=(E,R,S),其中E={e1,e2,e3…,e|E|}表示实体集合,R={r1,r2,r3…,r|R|}表示关系集合,S⊆E×R×E表示知识图谱中的三元组集合。目前对知识图谱的研究应用主要分为通用领域知识图谱和垂直领域知识图谱。典型的中文通用领域知识图谱有CN-DBpedia[2]、zhishi.me[3]、Ownthink[4]、XLore[5]等。上述通用领域知识图谱虽收集了大量的领域知识,但无法深入对某一领域内的知识进行详细描述。垂直领域知识图谱在这方面的优势大于通用领域知识图谱,但是该领域知识图谱构建通常采用手工构建,需要消耗大量的人力财力。
经过调查发现,现有通用领域知识图谱中含有部分关于辽代历史文化资源相关的内容,但是现有知识图谱从规模化、规范化、形式化等方面任有很大的提升空间[6]。目前垂直领域中关于辽代历史文化资源的知识图谱还没有,如何基于高效的知识工程方法以及先进的文本数据挖掘技术,构建大规模、高质量的辽代历史知识图谱,仍是极具挑战性的课题。
本文初步探讨了辽代历史领域知识图谱当前面临的机遇和挑战,从新的领域知识图谱角度提出了辽代历史领域知识图谱构建技术。针对辽代历史领域的特点对知识各个环节的关键技术流程进行专项研究,利用自然语言处理、文本数据挖掘技术和知识抽取、知识融合等知识图谱构建技术,采用人机结合的方式构建了辽代历史文化资源知识图谱。
1 相关研究
命名实体识别(Named Entity Recognition,NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别[7]。目前命名实体识别的主要技术方法分为:基于规则和词典的方法、基于统计的方法、基于神经网络的方法等。其中基于规则的方法多采用语言学专家手工构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、中心词等方法,以模式和字符串相匹配为主要手段,这类系统大多依赖于知识库和词典的建立。基于统计机器学习方法将NER视作序列标注任务,利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。常用的方法主要包括:隐马尔可夫模型[8](HMM)、最大熵[9](ME)、支持向量机[10](SVM)、条件随机场[11](CRF)。基于神经网络的方法在硬件能力的发展以及词的分布式表示(word embedding)的出现,成为可以有效处理许多NLP任务的模型。其中主要模型有CNN-CRF、RNN-CRF、LSTM-CRF等。
随着互联网技术的高速发展,人们在对通用领域数据进行实体抽取的同时开始关注垂直领域的实体抽取,然而垂直领域的数据文本有其自身的特点,进行实体抽取时需考虑其自身特点[12]。
在命名实体识别的工作中,主要分为基于规则的方法、基于统计机器学习的方法和基于神经网络的方法。其中常见的基于统计机器学习的模型主要有隐马尔可夫模型、最大熵模型、支持向量机和条件随机场等。然而,这些方法在进行特征提取时需要人工进行完成。同时在模型训练方面需要大量的人工标注样本,并且效果不明显[13]。
基于神经网络的方法在命名实体识别任务中通常被当作序列标注任务,通过建立序列标注模型对文本进行实体识别。2011年Collobert[14]等采用卷积神经网络(CNN)进行特征提取,同时通过融合其他特征效果上取得不错的识别效果。丁晟春[15]等人针对网络公开平台上的多源异构的企业数据的散乱、无序、碎片化问题,提出Bi-LSTM-CRF深度学习模型进行商业领域中的命名实体识别工作。何春辉[16]等人利用电子文档在糖尿病领域中取得了较好的应用,实验结果表明该模型在包含15种实体类别的数据集上准确率达到了89.14%。李永苗[17]利用BiLSTM网络对中文电子病历中的实体进行提取,构建出了中文电子病历知识图谱。Feng[18]等提出了一种基于BiLSTM的神经网络结构的命名实体识别方法。买买提阿依甫[19]等人根据维吾尔语的特点,提出了BiLSTM-CNN-CRF模型。李丽双[20]等人将CNN-BiLSTM-CRF模型应用在生物医学语料上,获得了当时最高F1值。柳润杰[21]通过使用BiLSTM-CRF模型将《二十四史》中的人名、地名、时间等实体识别后,在此基础上构建了《二十四史》知识图谱。
本文在进行辽代历史文化实体识别中将使用BiLSTM-CRF的深度神经网络模型。首先将输入的词由one-hot向量映射为低维稠密的字向量(character embedding),然后将得到的字向量序列作为输入传入到BiLSTM神经网络模型中进行实体识别,然后CRF模型将会对BiLSTM模型输出的结果进行解码操作,得到一个最优标记序列,最后得到识别的实体信息。
2 辽代历史文化知识图谱整体构建方案
目前关于辽代历史文化知识图谱还未出现。因此本文定位于辽代历史文化知识图谱工程构建研究,旨在介绍我们开发的辽代历史文化知识图谱,其构建过程主要包括本体构建、知识抽取、知识融合等步骤。本体定义了辽代知识图谱构建中所需要的实体及关系类型。基于本体对结构化数据、非结构化数据进行处理后存储于Neo4j图数据库中。辽代历史知识图谱构建流程图如图1。
在辽代历史文化知识图谱的构建过程中,本文中知识图谱构建所有数据类型包括结构化数据、半结构化数据和非结构化数据,其中结构化数据来自网络上通用领域百科知识图谱中的数据,本文中所有的通用领域知识图谱为Ownthink及CN-DBpedia;半结构化数据主要来自百度百科、互动百科,针对半结构化数据通过使用包装器来进行获取,其中包装器的生成方法有三大类:手工方法、包装器归纳方法和自动抽取方法。本文主要使用手工方法,通过人工分析构建包装器信息抽取的规则,以此来获取网页中的半结构化数据;针对非结构化数据来自互联网上关于辽代历史相关网页数据,通过使用网络爬虫技术进行获取大量的辽代历史网页文本数据,然后在将获得的网页文本数据进行处理。处理过程主要通过增量迭代的方式逐步扩大知识规则。辽代历史的非结构化数据主要包括网页文章、史料书籍等,适合采用基于深度学习的有监督方法。
通过上述技术手段大大的提升了辽代历史知识图谱构建的自动化程度。但作为一个辽代历史知识图谱,不仅要确保构建图谱信息来源真实性和可靠性,还要保证知识来源的充分性。针对后者,充分利用现有知识库中关于辽代历史信息对其进行补充,通过抽取现有知识库中与辽代历史相关的三元组信息来充实本文中使用方法构建的知识图谱,以保证有足够多的数据量。
在数据处理过程中,充分使用中文分词工具jieba分词、正则表达式;在知识抽取过程中通过命名实体识别、关系抽取来获取文本数据中的实体和关系,在进行命名实体部分本文采用BiLSTM-CRF神经网络模型来进行抽取非结构化文本数据中的实体;在关系抽取过程中,使用网络上集成的关系抽取工具DeepDive进行抽取文本的实体与实体之间的关系,从而构建知识图谱所需要的三元组数据。在知识抽取和数据整合完成后,在对不同来源的同一实体进行对齐、合并的操作,最后获得质量较高的三元组数据,通过LOAD 语句存入Neo4j数据库。

图1 辽代历史文化知识图谱构建流程
3 辽代历史文化知识抽取
3.1 模型整体框架
本文的BiLSTM- CRF模型框架如图2。BiLSTM- CRF模型由三部分组成:第一部分输入层,第二部分隐藏层,第三部分是标注层。其过程如下:首先将输入的词由one-hot向量映射为低维稠密的字向量,然后将得到的字向量序列作为输入传入到BiLSTM神经网络模型中进行实体识别,最后CRF模型将会对BiLSTM模型输出的结果进行解码操作,得到一个最优标记序列。
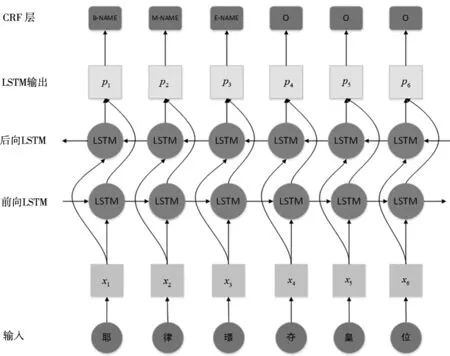
图2 辽代历史文化实体识别模型
3.2 BiLSTM 模块
循环神经网络(RNN)是神经网络中一类重要的结构,从理论上来说,RNN可以动态的捕获序列数据信息,但是在实际使用过程中容易出现梯度消失和梯度爆炸等问题,长短期记忆网络[22](LSTM)可以很好的解决这类问题。对于命名实体识别来说,由于需要识别的实体句子分布位置不同,其文本中的上下文信息的重要程度也不同。为了更好的利用上下文中的信息,本文采用双向LSTM结构进行模型训练。
3.2.1 LSTM单元
LSTM是RNN的变体,旨在解决这些梯度消失的问题。基本上,一个LSTM单元由三个乘法门组成,这些门控制信息遗忘和传递给下一时间步骤的信息比例。这些门控单元为输入门(Input Gate)、遗忘门(Forget Gate)、输出门(Output Gate)。LSTM单元的基本结构如图3。

图3 LSTM网络结构
其LSTM单元在t时刻更新公式如下:
it=σ(Wiht-1+Uixt+bi),
(1)
ft=σ(Wfht-1+Ufxt+bf),
(2)
(3)
(4)
ot=σ(Woht-1+Uoxt+bo),
(5)
ht=ot⊙tanh(ct)
。(6)

3.2.2 BiLSTM


图4 BiLSTM网络结构图
3.3 CRF模块
条件随机场是一种概率无向图模型[23],同时是序列标注任务中较为常见的一种算法,可以用于实体类别的标注。本文将CRF层作为神经网络结构的最后一层,对BiLSTM模块输出的结果进行处理,获得最优的全局最优标签序列。
对于一个给定的文本,用X=(x1,x2,x3…xn)表示输入句子,用y=(y1,y2,y3…yn)表示输出标签序列,那么该标签序列得分为
(7)
式中:A转移分数矩阵;Ai,j表示从标签i转移到标签j的分数。
对所有可能的序列路径进行归一化处理,产生输出序列y的概率分布,如
(8)
在训练过程中,最大化关于正确标签序列的对数概率如

(9)
式中,YX是对于输入句子X的所有可能标签序列。
在最终进行解码时,选择预测总分最高的序列作为最优序列,公式为
(10)
4 实验及结果分析
4.1 实验数据准备
由于目前网上公开的数据集中缺乏关于辽代历史文化的相关数据,因此本文使用的数据集由10万字左右的辽代历史文化相关文本构成。通过爬虫获取网上相关文本数据,然后将获取的语料已经进行分词、去停用词等处理,对语料进行了人名、地名、时间、朝代等信息进行了实体标注。
监督学习方式的主要标注模型包括BIO、BIEO、BMESO等,为了能够清楚的表示语料中待识别的命名实体,本文在自建数据集采用BIO标记法进行标注。对于每个实体,将其第一个字标记为“B-(实体名称)”,中间字标记为“I-(实体名称)”,对于非实体标记为“O”,见表1。
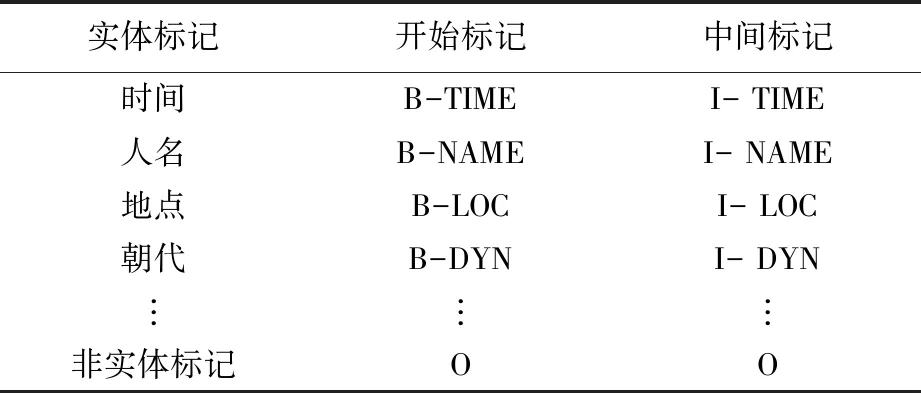
表1 BIO标注策略
使用BIO标注策略对给定的辽代历史文化文本进行实体标注示例见表2。

表2 历史文化文本命名实体标注示例
本实验采用准确率P(Precision)、召回率R(Recall)以及F1值对模型进行评价。具体公式如下:
(11)
(12)
(13)
其中TP表示被判定为正样本,实际预测也为正样本,即判断为正例的正确率;TN表示判定为负样本,实际预测也为负样本,即被正确预测的负例;FP表示判定为正样本,实际预测为负样本,即把负样本判断成了正样本的误报率;FN表示判定为负样本,实际预测也为正样本,即把正样本判断成负样本的漏报率。
4.3 实验环境
所有实验采用的环境见表3。

表3 实验环境
4.4 参数设置
本文所提及模型采用TensorFlow框架进行搭建,具体实验参数设置见表4。

表4 实验参数分
通过对学习率与迭代次数的调整,提升了模型的训练精度和模型的泛化能力。
4.5 实验结果
为了验证本文方法的识别效果,分别采用CRF、BiLSTM、BiLSTM-CRF方法对自己构建的数据集进行命名实体识别。
(1)条件随机场CRF。采用条件随机场开源工具CRF++工具包,本文实验所使用的版本为CRF++0.58,通过建立模型从而实现实体识别。
(2)BiLSTM。采用双向LSTM神经网络模型在自建数据集上进行实体识别。
(3)BiLSTM-CRF。采用双向LSTM-CRF神经网络模型在自建数据集上进行实体识别。
上述实验对比结果见表5。

表5 实验结果对比 /%
从表5中的实验结果可以看出,在CRF模型和基于神经网络的模型比较的过程中,基于神经网络的模型在各个方面的性能都优于CRF模型;在BiLSTM和BiLSTM-CRF模型的比较中可以看出,在添加了CRF进行序列标注的BiLSTM-CRF模型在各方面的效果都优于BiLSTM,这说明CRF在进行解码的过程中考虑到了全局的标签信息,提升了模型的性能,在自建数据集上识别实体的效果相对较好,可以很大程度上识别出需要的三元组信息中的实体。
因此可以确定本文实验中所使用BiLSTM-CRF模型可以较好的提取文本数据中的实体,达到构建知识图谱的要求。
5 知识图谱可视化展示
将获取的辽代历史文化知识图谱的实体和关系采用Neo4j数据库进行存储,其中获取的有朝代、帝王名称、首都等,关系有主要国家、主要语言,所属时期等,最后存储的部分结果展示如图5-图6。

图5 辽代部分知识图谱可视化效果图
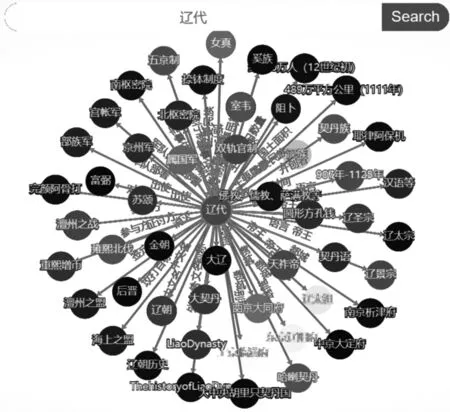
图6 历史知识图谱可视化查询效果图
6 结 语
本文提出了一种辽代历史文化知识图谱的构建流程,首先介绍了数据的获取,获取数据包括结构化数据、半结构化数据和非结构化数据。然后主要介绍了针对非结构化文本数据如何进行知识抽取,提出一种BiLSTM-CRF神经网络模型进行实体抽取,F1值达到84.55%,根据实验结果可知采用BiLSTM-CRF较好的抽取出非结构化文本中的实体。最后根据得到的实体关系构建知识图谱三元组,将其存储到Neo4j数据库中,使用Echarts和Web 编程进行可视化展示。后续工作中,将会尝试使用其他网络模型进行非结构化文本中的实体关系抽取,同时会考虑加入Bert模型,进一步来提升实体识别的效果。同时会在本领域中标注更多的数据,以此来获得更好的实体关系抽取结果,保证得到的三元组信息更加可靠。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
学习与科普(2022年17期)2022-04-23
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
福建基础教育研究(2020年3期)2020-05-28
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
