
Implicit Attribute Recognition of Online Clothing Reviews Based on Bidirectional Gated Recurrent Unit-Conditional Random Fields
2021-04-08 11:09WENQinqin温琴琴TAORanWEIYaping卫亚萍MILiying米丽英
WEN Qinqin(温琴琴), TAO Ran(陶 然)*, WEI Yaping(卫亚萍), MI Liying(米丽英)
1 College of Computer Science and Technology, Donghua University, Shanghai 201620, China
2 School of Foreign Studies, Shanghai University of Finance and Economics, Shanghai 200433, China
Abstract: Sentiment analysis has been widely used to mine users’ opinions on products, product attributes and merchants’ response attitudes from online product reviews. One of the key challenges is that the opinion words in some reviews lack obvious evaluation objects (product attributes). This paper aims to identify implicit attributes from online clothing reviews, and presents a unified model which applies a unified tagging scheme. Our model integrates the indicator consistency (IC) module on the basis of bidirectional gated recurrent unit (BiGRU) with a conditional random fields (CRF) layer (BiGRU-CRF), which denoted as BiGRU-IC-CRF. On the 9640 comments data set of a certain clothing brand, the comparative experiment is carried out by BiGRU, BiGRU with an IC layer (BiGRU-IC) and BiGRU-CRF. The results show that this method has a higher recognition rate, and the F1 value reaches 85.48%. The method proposed in this paper is based on character labeling, which effectively avoids the inaccuracy of word segmentation in natural language processing. The IC module proposed in this paper can maintain the consistency of the product attributes corresponding to the opinion words, thereby enhancing the recognition ability of the original BiGRU-CRF method. This method is not only applicable to the implicit attributes recognition in clothing reviews, but also helpful to other fields implicit attribute recognition of product reviews.
Key words: implicit attribute; clothing reviews; indicator consistency; a unified tagging scheme
Introduction
The online product reviews contain various opinions and experience of users. Through effective analysis of these review information, it can not only help consumers make purchase analysis, but also help merchants improve product quality, improve service quality, and optimize sales strategies[1-2]. Therefore, the need for sentiment analysis of online reviews has become more and more urgent, and has attracted the attention of a wide range of researchers[1-4]. According to the granularity of the processed text, sentiment analysis research can be divided into coarse-grained sentiment analysis and fine-grained sentiment analysis[5]. Coarse-grained sentiment analysis includes text-level and sentence-level sentiment analysis, and fine-grained sentiment analysis is mainly used to analysis the product attributes and the opinions. In most applications, users are more concerned about which attribute people like or dislike, so sentiment analysis for a certain attribute of a product is more meaningful.
Product attributes in product reviews are divided into explicit attributes and implicit attributes. Explicit attributes refer to a noun or noun phrase that clearly describes the attributes of the product in the comments[1,6], such as “款式很漂亮(the style is very beautiful)”, where “款式(style)” is the explicit attribute of the product; the implicit attributes means that no nouns or noun phrases that clearly describe the attributes of the product appear in the reviews, but the attributes described can be known through semantic understanding[1,6], such as “有点偏小(a little too small)”, which contains only the adjective“小(small)”. Through semantic analysis, we can know that it describes the “尺码(size)” of the product, so “尺码(size)” is the implicit attribute of the comment.
Existing research often ignores the implicit commodity attributes, and most of them focus on the explicit commodity attributes[1-2,4,7]. However, implicit product attributes are very common in online reviews. For example, Wangetal.[8]used the comment sentences containing implicit attributes in the women’s sweater comments accounted for about 36.71% of the total comments, and the car reviews captured by Zhang and Xu[9]contained implicit attributes review sentences accounting for 15.99% of the overall reviews.
In this paper, we regard the implicit attributes recognition problem of the online clothing reviews as a sequence tagging task and design a unified model, indicator consistency(IC) module on the basis of bidirectional gated recurrent unit (BiGRU) with a conditional random fields (BiGRU-IC-CRF) to handle it in an end-to-end fashion. The proposed model is combined a BiGRU network, an IC module and a CRF network to improve the performance of the original BiGRU-CRF in processing sequence tagging task. We employ IC module to maintain the consistency of the product attributes corresponding to the opinion words. It is based on the gate mechanism that is designed to consolidate the features of the current character and the previous character. In addition, in order to avoid the inaccuracy of Chinese word segmentation from affecting the effect of the model, we adopt the unified tagging scheme with characters as the unit. The unified tagging scheme will be discussed in detail in section 3. Experimental results on real data show that BiGRU-IC-CRF is an effective implicit attribute recognition method.
1 Related Work
The main method of implicit attributes recognition is used to construct the explicit attribute words and the emotion words pairs in comment sentences, and then match the emotion words in the implicit comment based on the matching relationship between the attribute words and the emotion words.
Liuetal.[2]proposed to construct the explicit attribute words and the emotion words pairs in 2005, and then extracted implicit attributes through mapping relations. Qietal.[6]proposed an implicit attributes extraction method based on the co-occurrence relationship of attribute words and emotion words. That was, by clustering explicit attribute words and emotion words in turn, attribute word clusters and emotion word clusters were formed, and the association between single attribute words and emotion words was extended to the relationship between attribute word clusters and emotion word clusters. Zhang and Xu[8]used the car review corpus containing explicit attributes to construct a dictionary in the form of “attributes, opinions, weights”, and used the dictionary as a basis to extract implicit attributes with a multi-strategy implicit attribute extraction algorithm.
In recent years, machine learning has been widely used in the field of sentiment analysis, and as people study neural networks, deep learning has gradually become the focus of research[4, 7, 10-13]. Xuetal.[14]combined explicit topic models with support vector machines for implicit attributes recognition. Several support vector machine classifiers were constructed to train the selected attributes and use them to detect the corresponding implicit attributes. Cruzetal.[15]manually marked whether a word or phrase in the comment text is an indicator of implicit attributes, and then applied CRF to machine learning. The experimental results showed that this method was better than the naive bayes method, but only the indicator of the implicit attribute was recognized, and the specific attribute was not given. Chen and Chen[16]applied convolutional neural network (CNN) to the recognition of implicit attributes, and achieved good implicit recognition results on the T41-test data set. Wang and Zhang[13]annotated the attribute words and emotional words in the comment corpus after word segmentation to obtain the word sequence, part of speech sequence and annotation sequence, and then used the bidirectional long short-term memory (BiLSTM) with a CRF layer (BiLSTM-CRF) and BiGRU-CRF network to identify the implicit attributes. The experimental results show that the recognition effect of BiLSTM-CRF model and BiGRU-CRF model is better than that of single CRF model. This method can identify the product attributes (including implicit attributes) in the comment sentences, but it does not specify the implicit attributes in the comments.
The above studies indicated the need to conduct more research on the recognition of implicit product attributes in online reviews, but also provided insights and guidance for our study. We regard the implicit attributes recognition task as a sequence tagging task, and take the character as the sequence annotation unit. BiGRU is used to train the labeled corpus. In order to maintain the consistency of the product attributes corresponding to the opinion words, the feature vector obtained from BiGRU training is transferred to IC module training, and then CRF layer is added to learn some constraints in training data.
2 Implicit Attributes Recognition Model
2.1 Task description
We regard the task of implicit attributes recognition as a sequence labeling problem, and employ a unified tagging scheme. For a given input sequenceX={x1,x2, …,xn} with lengthn, our goal is to predict a tag sequenceY={y1,y2, …,yn}, whereyi∈ys,ysis the set of all possible tags, with a total of 29 tags.
2.2 BiGRU-IC-CRF model
As shown in Fig. 1, we integrate IC module on the basis of BiGRU-CRF network to form the BiGRU-IC-CRF model. The IC module is empowered with the gate mechanism, which explicitly integrates the features of the previous character into the current prediction, aiming at maintaining the consistency of the commodity attributes corresponding to the opinion words. The BiGRU-IC-CRF model is mainly composed of four parts: character embedding layer, BiGRU layer, IC layer and CRF layer. First, the comment sentences segmented by character are vectorized. Next, the vectors are input to BiGRU for training to obtain features containing context information, and then, the obtained feature vectors are input to the IC module. Finally, the CRF layer is added to learn some constraints in the training data to obtain the optimal tag sequence. More details of the BiGRU-IC-CRF model is followed in later sections.

Fig. 1 Structure of BiGRU-IC-CRF model
2.3 Character embedding
The character embedding layer is used to map the real input into the computable tensor of the model. The input is a sequenceXcomposed ofncharacters. Thed-dimensional pre-training word vector is obtained by word2vec software, and the outputV={v1,v2, …,vn},V∈Rn×d. Word2vec is a software tool for training word vectors[17], which can quickly and effectively express a character into a vector form through an optimized training model based on a given corpus. We use the continuous bag of words (CBOW) algorithm of Word2vec model to train the character vector (d=128) on the unlabeled online clothing review corpus.
2.4 BiGRU layer
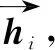

Fig. 2 Structure of BiGRU
(1)
(2)
(3)
(4)
(5)

(6)
(7)
(8)
(9)
The working principle of the backward GRU is the same as that of the forward GRU. However, different calculation orders are used, one is from front to back, the other is from back to front, so that the calculated feature vector has context information.
2.5 IC layer
The output of BiGRU layer is taken as the input of this layer, and the current feature and the previous feature are obtained through IC layer to predict the current unified label.
Considering that opinion words is mainly composed of multiple characters, such as “穿起来很帅(looks handsome)”, these five characters indicate the same attribute. However, in the labeling task, they may be labeled as opinion words of different attributes. In order to avoid this phenomenon, the method of sentiment consistency(SC) module was designed by Lietal.[7]to maintain the consistency of emotion within the same opinion target. This module introduces a gate mechanism, which uses the features of the previous state and the current state to predict the label of the current character. Because it is to maintain consistency of corresponding attributes within the opinion words, we call this module IC, and the internal structure of the module is shown in Fig. 3.
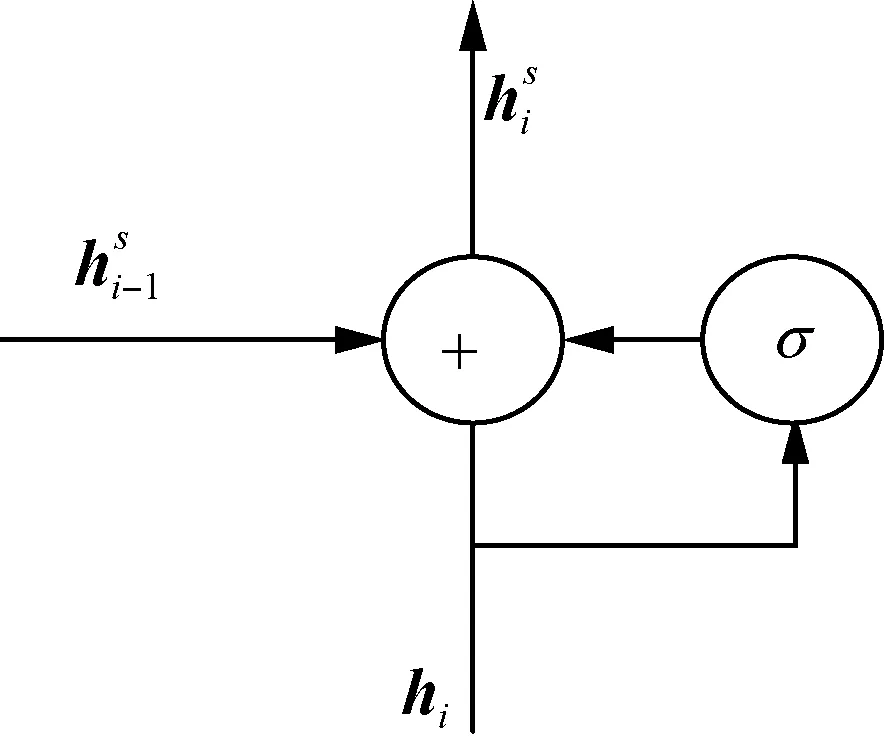
Fig. 3 Internal structure of IC module
The equations of IC module is
gi=σ(Wghi+bg),
(10)
(11)
2.6 CRF layer
CRF is an undirected sequence model proposed by Laffertyetal.[19]in 2001. It obtains an optimal label sequence by considering the relationship between adjacent labels. For a sentencex={x1,x2, …,xn} and the prediction sequencey={y1,y2, …,yn}, its score can be defined as
(12)
whereTis the state transition matrix, and each elementTi, jin the matrixTrepresents the probability of changing from stateito statej;Pis the scoring result calculated and output by the IC layer, andPi, jrepresents the probability of outputting thej-th label at thei-th character. The dynamic optimization algorithm can be used efficiently to calculate the optimalS(x,y), see Ref.[19] for details.
3 Unified Tagging Scheme for Implicit Attribute Recognition of Clothing Reviews
We introduce a unified tagging scheme for implicit attributes recognition of clothing reviews, which is a combination of boundary labels and attribute labels to jointly label opinion words that lack evaluation objects (product attributes). We call opinion words that lack evaluation object in online reviews as implicit attribute indicators. The boundary label is BIEOS, respectively expressed as: B (Begin), the beginning of the implicit attribute indicator; I (Inside), the middle of the implicit attribute indicator; E (End), the end of the implicit attribute indicator; O (Other), other non-implicit attribute indicators; S (Single), the implicit attribute indicator represented by a single character. The term frequency-inverse document frequency (TF-IDF) algorithm is used to extract the top 20 key words from clothing reviews, and then combined with clothing details to manually select seven attribute tags, namely clothing “价格(Price, P)”, “做工(workmanship, W)”, “面料(Fabric, F)”, “款式(Style, S1)”, “性价比(Cost performance, C)”, “尺码(Size, S2)”and “上身效果(Upper body effect, U)”. The label of each attribute indicator is shown in Table 1.
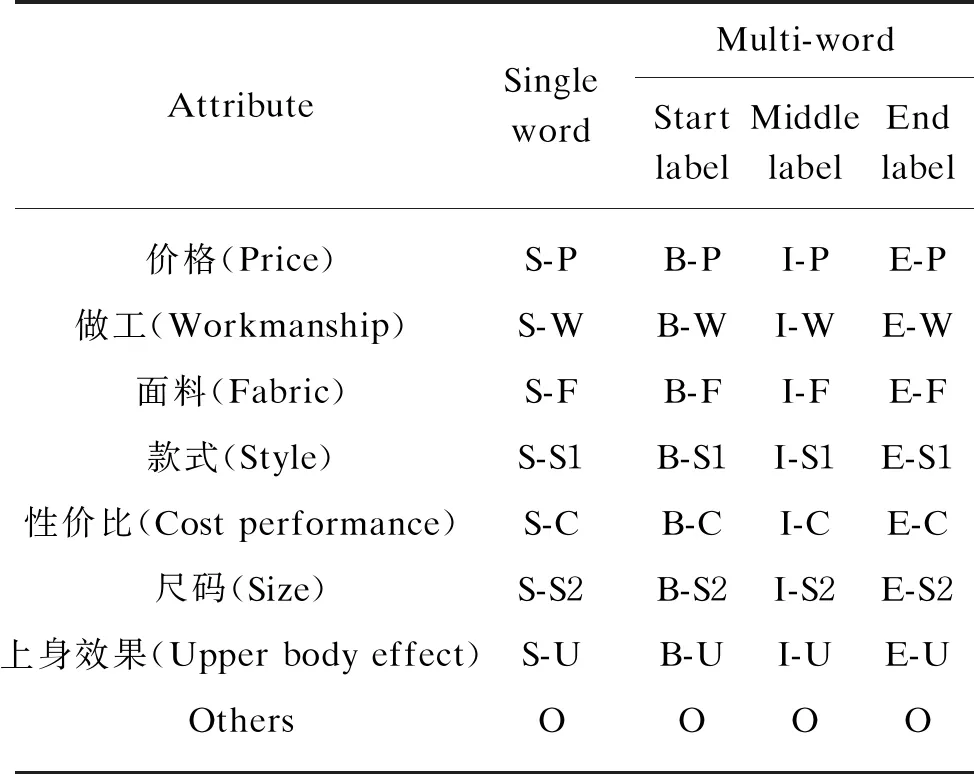
Table 1 Attribute indicator label
The implicit attribute indicator of a single word can be represented by a unified tag like “S-P”, and multiple words are marked together by three tags from the “Start label” column to “End label” column of Table 1. Table 2 gives an example of the unified tagging scheme.
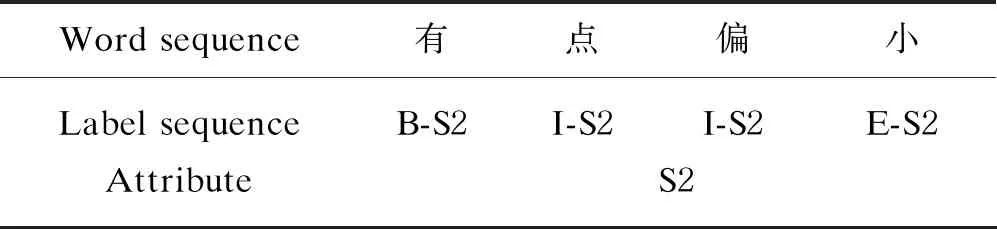
Table 2 Annotation example
As shown in Table 2, in the sentence “……有点偏小……(...a little too small...)”, the opinion words “有点偏小(a little too small)” is the implicit attribute indicator of the size. We marked the character “有” as “B-S2”, the characters “点” and “偏” as “I-S2”, and the last character “小” of the opinion words as “E-S2”.
4 Experiments and Analyses
4.1 Data sources and preprocessing
As one of the basic needs of people’s lives, clothing ranks first in the online shopping category. It is of great significance to analyze the data in the field of clothing e-commerce. We took online reviews in the clothing field as the research object, and crawled 12 983 reviews of 10 T-shirts of a certain brand on the T-mall website through crawler technology. After deduplicating the collected data, removing line breaks and other illegal characters such as network symbols, and filtering out comments with less than 10 words, 9 640 valid comments were obtained. Divide the training set, validation set and test set according to the ratio of 8∶1∶1.
4.2 Experimental results and analyses
On the corpus labeled under the unified scheme of the section 3, we compared BiGRU-IC-CRF with three models BiGRU, BiGRU-IC and BiGRU-CRF in the environment. We use the commonly used evaluation indicators in sequence labeling tasks, precision (P), recall (R) andF1 value[4, 7, 13]to evaluate the performance of the model.

Fig. 4 F1 value of different models varying with the number of epochs
The experiment is based on the PyTorch framework. The learning rate is set to 10-3, and the dimension of the hidden for BiGRU is 128. As shown in Fig. 4, models BiGRU-IC-CRF and BiGRU-CRF tend to be stable after epoch reaches 20. However, models BiGRU and BiGRU-IC reach the highest when epoch is 30, so the models are trained up to 30 with Adam[20]. The experimental comparison results are shown in Table 3.

Table 3 Test results of different models
Through comparative experiments, it can be found that theF1 value of the BIGRU model integrated with IC or CRF is 0.17% and 2.99% higher than that of the single BiGRU model, respectively. The IC module is used to further optimize the feature vector of BiGRU, and the CRF is used to obtain a globally optimal label sequence considering the relationship between adjacent labels. Therefore, the effect of integrating IC is not as good as that of integrating CRF.
Compared with BiGRU, BiGRU-IC and BiGRU-CRF, theF1 value of BiGRU-IC-CRF method is increased by 4.15%, 3.98% and 1.16% respectively, which shows that BiGRU-IC-CRF method achieves better results in the implicit attributes recognition of clothing reviews.
5 Conclusions
We investigate the implicit attributes recognition task of the online clothing reviews, which is formulated as a sequence tagging problem with a unified tagging scheme in this paper. The basic architecture of our model is used to integrate the IC module on the basis of the BiGRU-CRF model, which further improves the recognition effect of the model. The IC module is mainly based on the gating mechanism to maintain the consistency of corresponding attributes within the opinion words. We employ the BiGRU to obtain the contextual information of the data, which effectively solves the polysemy problems in Chinese and the problem of emotion words modifying different attributes in different contexts. Moreover, due to the unified tagging scheme, our model can not only extract the opinion words that without evaluation object in the online comments, but also identify the attribute of the commodity indicated by the opinion words. The experimental results show that compared with the commonly used model BiGRU-CRF, the unified model BiGRU-IC-CRF proposed in this paper has a higherF1 value and a better implicit attribute recognition effect.
Considering that the corpus of this article only involves comments on clothing T-shirts, the next step will be to increase the corpus of various clothing comments to improve the recognition effect of the model.
猜你喜欢
小康(2021年13期)2021-05-11
安庆师范大学学报(自然科学版)(2021年1期)2021-03-14
小学生学习指导(中年级)(2020年11期)2020-11-26
好日子(2019年4期)2019-05-11
喜剧世界(2017年2期)2017-02-15
小天使·二年级语数英综合(2016年11期)2016-12-12
小学阅读指南·高年级版(2016年3期)2016-05-27
Coco薇(2015年11期)2015-11-09
Coco薇(2015年10期)2015-10-19
视野(2015年11期)2015-06-24
 Journal of Donghua University(English Edition)2021年1期
Journal of Donghua University(English Edition)2021年1期
- Journal of Donghua University(English Edition)的其它文章
- Polyacrylonitrile/Graphene-Based Coaxial Fiber-Shaped Supercapacitors
- Highly Stretchable and Transparent Hydrogel as a Strain Sensor
- Effect of Processing Parameters on Morphology and Mechanical Properties of Hollow Gel-Spun Lignin/Graphene Oxide/Poly (Vinyl Alcohol) Fibers
- Characteristic Analysis and Harmonic Feature Identification of Micro-Vibration on Flywheels
- Defect Detection Algorithm of Patterned Fabrics Based on Convolutional Neural Network
- Tufting Carpet Machine Information Model Based on Object Linking and Embedding for Process Control Unified Architecture