
代码生成器形式化验证技术研究
2021-04-19 01:53侯荣彬
仪器仪表用户 2021年4期
侯荣彬,马 权,兰 林,蒋 维,杨 斐,李 昂,李 丹
(中国核动力研究设计院 核反应堆系统设计技术重点实验室,成都 610213)
0 引言
在安全关键嵌入式实时系统中,软件可靠性方面的问题越来越突出。为了保证系统的安全,认证机构制定系统(系统认证)和系统开发工具(系统开发工具认证资质)开发的指导原则。为了降低系统在验证规范和设计方面的成本,开发过程中通常使用自动代码生成器,以便从规范和设计模型自动生成源代码,然后从源代码(传统编译器)中生成二进制可执行文件。另外,模型驱动工程技术的发展也需要使用代码生成器,实现从模型语言到通用编程语言的转化。然而,许多有错误的代码生成器,特别是编译器,它可以把一个正确的安全程序变成一个不正确的不安全的可执行代码。因此,应该给予代码生成器的V&V 以更多的关注。认证机构通常要求代码生成器必须与它生成系统的部分有相同的安全级别。
编译器要求在语义上是透明的:编译后的代码应该按照源程序的语义所规定的方式运行。然而,编译器尤其是优化编译器是执行复杂符号转换的复杂程序。编译器中错误引发的事故,它们会悄悄地把正确的源程序变成不正确的可执行程序。对于低可靠性要求的软件,仅通过测试验证,编译器引入的错误的影响可以忽略不计。测试过程验证的是编译器生成的可执行代码,经过严格的测试可发现源程序的错误。对于高可靠性要求软件,这一问题变得至关重要,需要使用形式化方法(模型检查、程序验证等)来保证。使用形式化方法进行验证几乎都是在源代码级别,编译器中的漏洞会将这些经过验证的源程序转化为可执行程序。如果编译器中存在错误,则可能使在源程序上的形式化验证失效。从形式化方法的角度看,编译器是源程序与硬件处理器之间的一个薄弱环节,而后者已经被形式化验证。安全关键软件行业意识到了这个问题,并使用了各种技术来缓解这个问题,例如在关闭所有编译器优化之后对生成的汇编代码进行手动代码审查。然而,这些技术并不能完全解决这个问题,并且在开发时间和程序性能方面代价高昂。更好的方法是将形式化方法应用于编译器本身,以确保它保留源程序的语义。显然,更好的方法是将形式化方法应用于编译器本身,以确保它保留源程序的语义。目前,已经有很多方法和相关研究,包括书面、机器上的语义保持证明[1-3]、证明携带代码[4-8]、可信编译[9-11]、翻译确认[12-19]。
1 代码生成器形式化验证方法
编译器的形式化验证就是证明源程序S 和目标程序C之间满足给定的正确性属性Prop(S, C)。正确性属性包括:
I. S 和C 在可观测行为上是等价的。
II. 如果S 有良好定义的语义(不出错),那么S 和C是可观测行为等价的。
III. 如果S 有良好定义的语义并且满足功能属性Spec,那么C 满足Spec。
IV. 如果S 是类型和内存安全的,那C 也是。
V. C 是类型和内存安全的。
对于可信代码生成器的正确性属性,选择第2 种。理由如下:完全可观测行为等价(性质I)太强,它要求当源代码语义发生错误时,编译生成的目标代码也会出错。在实践中,编译器可以为具有未定义行为的源程序自由地生成任意代码。因此,这个属性很难证明。通常情况下,如果规范Spec 依赖于程序的可观察行为,则规范的保持性(属性III)由属性II 蕴含。因此,一劳永逸地证明属性II,可满足很多属性III 中的规范。属性IV 是典型的类型保持编译器,只是属性III 的一个实例。最后,属性V 是一个与源程序无关的属性,这是一种典型的编译器,要么直接在编译器代码上建立感兴趣的属性(类型安全),要么在源程序上建立感兴趣的属性,并在编译过程中保存这一属性。
一个编译器Comp 是一个从源程序到编译生成的代码(记作Comp(S) = Some(C))或错误(记作:Comp(S) = None)的全函数。错误的情况必须考虑,因为编译器可能生成代码失败。例如,源程序有语法或类型错误、编译的程序超出了编译器的能力。
1)经过验证的编译器
使用上面的定义,一个经过验证的编译器是任何完成下面定理的形式化证明的编译器Comp:
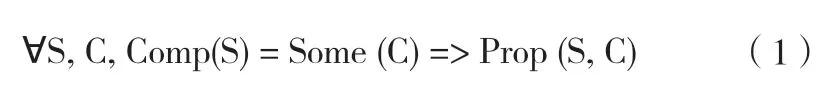
换句话说,要么编译器报告错误,要么生成满足所需正确性的属性的代码。注意,当Comp(S) = None 时,这一规则也同样成立。编译器是否成功地编译感兴趣的源程序不是一个正确性问题,而是一个编译器实现质量问题,这是由诸如测试之类非形式化方法解决的。从形式化方法的观点来看,重点是编译器从不默默地产生错误的代码。
2)携带证明的代码
携带证明代码和可信编译使用验证编译器,它可以生成代码失败(CComp(S) = None)或返回一个编译产生的C代码和属性Prop(S, C)的证明π(CComp(S) = Some(C,π))。证明π可以被使用者独立检查。这种方法没有必要相信代码产生者,也不需要验证代码生成器本身。验证编译器可以产生正确的证明π,而不是建立Prop(S, C)。
3)翻译确认
在翻译确认方法中,标准的编译器Comp 还辅助于一个验证器:一个布尔值函数Verif(S, C)通过静态分析S 和C来验证属性Prop(S, C)。为获得形式化保证,验证器自身必须被验证,也就是必须证明:
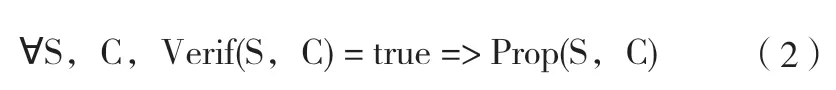
然而,这种方法不需要对编译器本身进行形式化验证。因此,不能保证编译器产生的代码总是能够通过验证器。
4)混合方法:结合经过验证的编译器和验证编译器
通过重新组合,可以形式化地结合经过验证的编译器方法和验证编译器。如果CComp 是一个验证编译器并且Verif 是一个正确的验证器,那么下面的函数是一个经过验证的编译器。定理(1)可以直接从定理(2)获得。
Comp(S) =
match CComp(S) with
|None ->None
|Some(C, A) -> if Verif(S, C, A) then Some(C)
else None
类似地,设Comp 是一个经过验证的编译器并且Π 是一个定理(1)的Coq 证明项。根据Curry-Howard 同构机制,Π 是一个函数包括S,C 和一个Comp(S) = Some (C)的证明,并且返回一个Prop(S, C)的证明。一个验证编译器定义如下:
CComp(S) =
match Comp(S) with
| None -> None
|Some(C) -> Some(C, Π S Cπeq)
其中,πeq 是命题Comp(S) = Some(C)的证明项。伴随的验证器是Coq 证明检查器,就像是携带证明代码方法一样。
5)编译过程的组合性
编译器通常由很多阶段组成,这些阶段之间通过中间语言进行连接。上面提到的两种编译器构造方法,经过验证的编译器和验证编译器都可以通过这种方式进行分解。如 果Comp1 和Comp2 分 别 是 从L1 到L2 和L2 到L3 的 经过验证的编译器,他们的组合:
Comp(S) =
match Comp1(S) with
| None -> None
| Some(I) -> Comp2(I)
假设属性Prop 是可传递性的,那么Comp 是一个从L1到L3 的经过验证的编译器。也就是Prop(S, I)和Prop(I, C)蕴含Prop(S, C)。
相似地,如果CComp1 和CComp2 分别是L1 到L2 和L2 到L3 的验证编译器,Verif1 和Verif2 是伴随的验证器,那么一个从L1 到L3 的验证编译器为:
CComp(S) =
match CComp1(S) with
|None ->None
|Some(I, A1) ->
match CComp2(I) with
|None->None
|Some(C, A2)->Some(C, (A1 ,I, A2))
Verif(S, C, (A1, I, A2)) = Verif1(S, I, A1)/Verif2(I, C, A2)
2 代码生成器正确性定义
编译阶段的语义正确性是根据形式化源语言和目标语言的模拟关系来定义。上面已经介绍了4 种正确性属性,其中最重要的是编译过程的语义保持性(属性II),这种属性由向前模拟关系来实现。编译器正确性的核心是确定计算与编译交互的精确定义。对于一个编译阶段的源语言Src和目标语言Tgt,可以通过向前模拟关系实现编译器正确性的定义,如图1 所示。
其中:
1)编译过程Src →Tgt 沿水平方向演变,从左到右。
2)程序执行过程垂直方向,从上到下。
3)两种语言的状态分别为σ_Src 和σ_Tgt。其中,σ_Src = (c1, m1),σ_Tgt=(c2, m2)。c1 和c2 分别是源语言和目标语言的语句,并且这两种语言具有独立的内存。
4)过程→是程序的执行方向,根据编程语言的小步语义关系σ→σ'或多步语义σ→nσ'确定。
5)水平关系采用二元匹配关系的形式,它将源语言状态与目标语言状态相关联,并且在执行过程中保持这一关系。
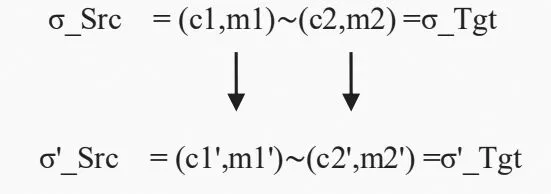
图1 向前模拟关系示意图Fig.1 Diagram of forward simulation relationship
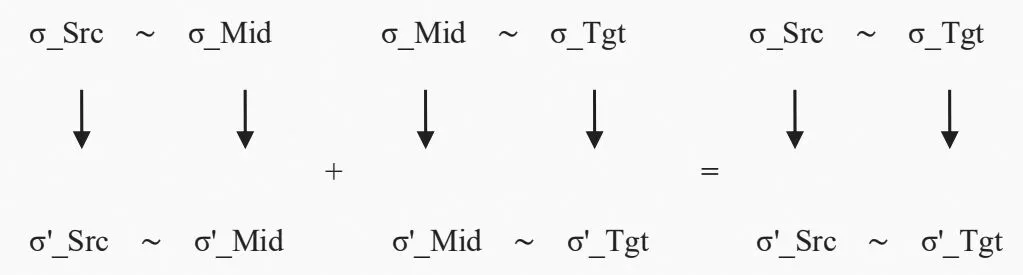
图2 模拟关系传递组合性示意图Fig.2 Schematic diagram of simulation relationship transfer combination
为了更清楚地表示程序运行的各种情况,匹配关系(c1,m1)→(c2,m2)蕴含如下命题:
a)如果c1, m1 →Src c1',m1',那么存在c2' 和m2' 使得c2, m2 →Tgtn c2', m2',并且(c1', m1')→(c2', m2')。
b)如果c1 终止,那么c2 终止,并且返回值和内存都满足匹配关系。
c)如果是函数调用语句c1 = (f, a1 →) , c2 = (f, a2 →),要求执行前参数列表a1 →~ a2 →,并且m1~m2,执行完毕后返回值和更新后内存满足匹配关系。
对于真实的编译器,编译器的正确性证明必须沿着编译过程的各个阶段可传递性的组合。通过这种方式每个阶段可以相互独立地进行证明,然后将这些证明串联起来。这明显比单块地证明编译器是正确的更加模块化,并且简化了证明难度。
沿着编译过程的模拟关系的可传递组合性可以通过图2 进行表示。
3 编程语言语法

图3 Lustre 和C语言抽象语法Fig.3 Lustre and C language abstract syntax
Lustre 是一种广泛应用于嵌入式控制和信号处理系统的面向应用的编程语言。著名的SCADE[20]和Simulink[21]都是基于Lustre,将Lustre 转换为可执行代码。SCADE 广泛应用于航空控制和反应堆监视软件开发中。Lustre 的主要特征包括:易于构建反应式控制;程序的执行有静态有界的空间和时间;具有基于数据流的良好数学语义;可追溯和模块编译框架;可实现自动化程序验证。Lustre 的抽象语法如图3 所示,这些抽象语法都是通过递归定义的。在表达式层,可分为一般表达式,如变量、常量、一元操作表达式、二元操作表达式、时钟运算表达式等;控制表达式,如条件表达式;时钟表达式,如基本时钟、子时钟。在语句层,Lustre 只有等式语句,等式的类型包括一般赋值、延时赋值、函数调用。一个完整的Lustre 程序是类型声明、函数声明和主函数调用的集合。对于C 语言,大家都比较熟悉,其抽象语法如右半部分所示,其结构和Lustre 很类似,不再赘述。
4 Lustre和C语义一致性的定义
如图4 所示,Lustre 语言到C 语言的翻译过程的语义保持性,实际上就是在相同的初始状态下,接受相同的输入,分别执行各自程序的语义,程序执行完毕后,最终的状态满足匹配关系,并且在最终状态中查找到相同的程序输出值。源语言Luster 和目标语言C 之间通过一个转换函数Comp 建立联系。只要完成Lustre 语言到C 语言的语义保持性证明,也就间接证明源语言Lustre 和经过Comp 处理生成的C 之间满足语义保持性。语义保持性证明基于编程语言的操作语义和状态的匹配关系以及程序和环境的交互。操作语义是一种基于状态转换关系的推理规则,匹配关系表示两个环境中标识符和值之间的对应和相等关系。程序和环境的交互关系较为复杂如图5 所示。根据程序的语法结构,程序执行语义分为类型和函数声明语句与主函数的调用,主函数的调用是函数调用的一个实例,函数调用又分为局部变量声明和语句执行,语句的执行实际就是控制表达式的求值。其中,声明类语句,如类型、函数声明语句和变量声明语句会创建新的环境和标识符,申请新的内存块。控制类语句如函数调用、语句执行、表达式求值则会更新状态,改变标识符对应的值或内存空间。求值类语句,则会根据当前的状态来确定自身的值。
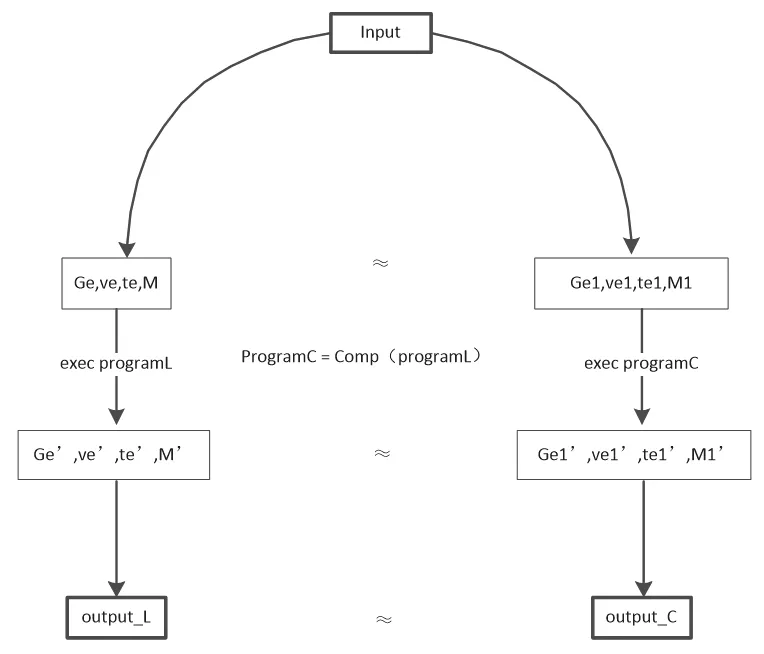
图4 程序执行一致性的定义Fig.4 Definition of program execution consistency
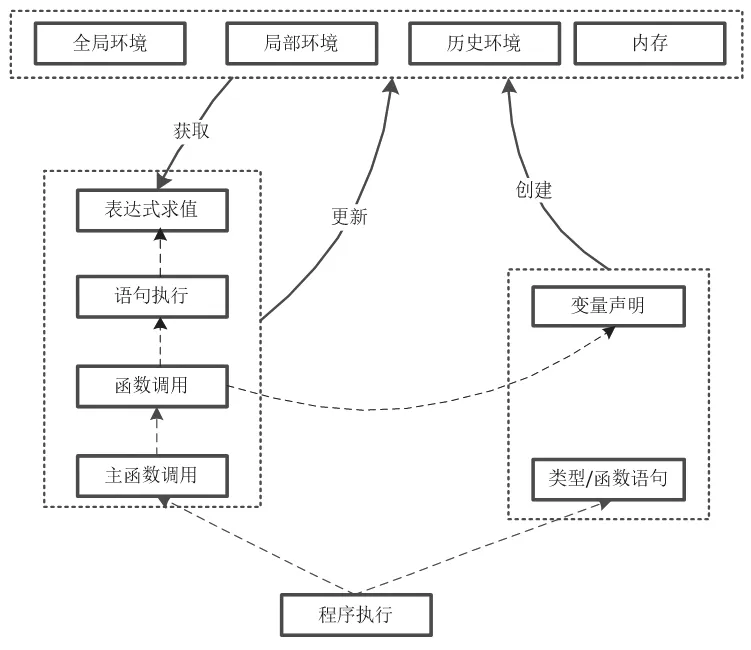
图5 程序和环境的交互关系Fig.5 Interaction between program and environment
5 结束语
本文针对一种Lustre 到C 的代码生成器,准备采用形式化方法对其翻译过程的语义保持性进行证明。第一部分介绍了应用形式化验证技术构建代码生成器的方法,包括经过验证的编译器、验证编译器、翻译确认、混合方法,以及将翻译阶段分解组合的技术;第二部分介绍了语义保持性定义的方法即单向模拟理论;第三部分介绍了源语言Lustre 和目标语言C 的抽象语法;第四部分定义了Lustre到C 翻译过程的语义保持性,将前面的理论应用于实际翻译过程的定义中,并详细介绍了程序和语言状态之间的交互。这是程序操作语义的基础,而操作语义又是语义保持性证明的基础。本论文为后续实际代码生成器的开发提供理论指导,也是后续代码生成器形式化语义保持性定义的依据。
猜你喜欢
仪器仪表用户(2020年5期)2020-05-04
铁道通信信号(2020年7期)2020-02-06
现代电子技术(2019年22期)2019-11-20
成都信息工程大学学报(2019年2期)2019-08-28
科技创新与应用(2017年3期)2017-02-18
电子世界(2016年15期)2016-08-29
单片机与嵌入式系统应用(2016年3期)2016-03-13
电子科技(2015年2期)2015-12-20
广西科技大学学报(2015年4期)2015-02-27
组合机床与自动化加工技术(2014年10期)2014-03-01
