
结合前馈神经网络和装袋算法的电力日负荷预测
2021-04-29 08:40肖琦敏陈锐陈爽
微型电脑应用 2021年4期
肖琦敏, 陈锐, 陈爽
(国网福建省电力有限公司 信息通信分公司, 福建 福州 350001)
0 引言
随着电力市场的日益发展,电力负荷的低估或高估都会给电力系统带来巨大挑战,影响电力系统运行的稳定性和可靠性,所以精准负荷预测能够有利于电网的决策调度,具有重要的现实意义。
随着现代智能用电技术的不断进步,负荷预测理论和技术得到快速发展,研究方法及手段也越来越多样。如果以预测时区作为分类依据,可以将负荷预测分为超短期、短期、中期、长期四类[1],研究中多侧重于短期负荷预测[2]。但目前已有的算法仍存在局限性。神经网络算法存在着网络构建问题、过度拟合问题和训练样本数据量大问题,这些问题使得神经网络算法难以实现短期负荷的精准预测。回归分析方法是在统计平均意义下定量描述所观察变量间的关系,往往对数据量有所限制。
在以上文献的研究基础上,从研究96点日负荷序列出发,提出一种结合前馈神经网络和装袋混合算法的日负荷预测模型。利用前馈神经网络计算成本函数及误差,并基于梯度下降法更新权重及偏差,最后将日负荷序列预测结果叠加得出最终预测值。
1 前馈神经网络
前馈神经网络(Feedforward neural networks)是一种从信息处理的角度将神经元进行相互联接的人工智能运算模型,是人工神经网络的一类。神经网络由输入层、隐藏层和输出层三部分组成,隐藏层选择考虑权重和偏差的Sigmoid激活函数,如式(1)。
(1)
定义特征向量输入层为x,第l层(总计L层)第i个神经元的输出函数,如式(2)。
(2)

wlj,k为权重矩阵Wl的矩阵元素,权重矩阵,如式(3)。

(3)
第L层第j个神经元的输出函数,如式(4)。
(4)
式中,f′(x)为关于x的线性函数。
输出函数plj构成的行向量,如式(5)。
(5)
偏差函数qlj构成的行向量,如式(6)。
(6)
神经网络由三层组成,其中输入层神经元选择Sigmoid函数,输出层神经元节点选择线性函数,这样就能够解决训练那些有限数量但不连续的样本函数。
利用最小化样本函数来确定偏差和权重,如式(7)。
(7)
式中,yt为t时刻所需要求得的负荷向量,pLt为L层t时刻输出函数向量。
采用随机梯度下降算法对代价函数进行最小化,权重矩阵更新函数,如式(8)。
(8)

偏差矩阵更新函数,如式(9)。
(9)

2 装袋算法
装袋算法是一种将多个弱学习器集成为一种强集合学习器的提高机器性能的学习算法[3],可以提高弱学习算法的准确率。装袋算法的思想是通过多轮训练数据样本,每轮训练过程中通过自助(Boot strap)方式提取N个训练样本,得到新的预测函数序列,每次完成D次训练得到D个预测函数,通过得到的预测函数序列对预测样本进行预测[4]。文献[5]采用等权重平均值法来获取预测结果,并表明该算法类似于求解预测样本的平均值,可以有效地减少过度拟合。若当训练样本之间存在差异时,装袋算法就显得更有效,因为如果每个样本的输出极度相似,那么对平均值的影响就非常小[6]。其具体算法流程,如图1所示。
设定初始样本数据集,如式(10)。
(10)

确定训练样本的神经网络模型数量D,同时确定每个神

图1 装袋算法流程图
经网络的子训练样本集合数n。
针对每个神经网络通过bootstrap自助方式重新抽取n个子训练样本集,如式(11)。
(11)
设定样本测试数据集,如式(12)。
(12)
最小化代价函数,如式(13)。
(13)
预测估计值,如式(14)。
(14)

那么,式(13)可变形,如式(15)。

(15)
3 结合前馈神经网络和装袋算法的模型预测
通过装袋算法进行训练初始负荷样本,则需要大量的自助引导时间。仅通过前馈神经网络算法进行预测也存在着参数选择困难、变量选择不明显和过拟合问题[7]。其具体过程如下:
(1) 定义迭代总次数=不同神经网络总模型数量=引导带的样本数量H。
(2) 在迭代n次时,构造一个自助样本
根据训练样本的经验分布,随机抽样并替换为
(3) 通过计算求出引导预测估计值
(4) 定义神经网络的总层数L,第一层的输入函数定义为
对于接下来的第l=2,3,…,L层,按下式计算
zxl=Wlpx(l-1)+ql
式中,px(l-1)为f(zx(l-1))。
(5) 计算成本函数
∇pCx=pl-y
(6) 计算输出误差向量
δxL=∇pCx⊙f′(zxL)
(7) 从L层开始逐层反向传输计算误差
δxL=((Wl+1)δx(l+1))⊙f′(zxl)
式中,l=L-1,L-2,…,2。
采用梯度下降法,对(6)中的l层利用权重更新公式进行计算
偏差更新式
(8) 若训练停止,则神经网络的预测输出值为
(9) 经过上述步骤1~8,所提混合算法最终的预测日负荷值为
对于自助引导迭代次数n∈1,2,…,D。D选择通常在50范围上下浮动,具体数值与所预测的样本大小和计算成本具有直接关系[5-7],预测值定义,如式(16)。
(16)
4 实验结果分析
实验数据来自中国东部某地区2015年8月份共31天的负荷信息。为衡量预测模型的准确程度,引入平均绝对百分比误差指标进行分析。
相对误差百分比,如式(17)。
(17)
平均绝对百分比误差,如式(18)。
(18)

实验一:样本数量与迭代次数的关系
以该地区历史负荷数据为基础,其不同算法的MAPE对比结果,如图2所示。

图2 样本数量与迭代次数性能对比图
由图可知,随着迭代次数的增大,系统的MAPE值有逐渐减少的趋势,系统的性能通常会提高。从整体可以看出,若保证系统更高的性能,样本容量越小,就需要更多的迭代次数,然而迭代值和样本值的具体关系还是不明确的,存在着种种特殊性。但是当迭代次数在50次以上时,MAPE的结果随着样本数量的增加呈递减趋势。
实验二:不同算法间的预测精度
以该月份15日的日负荷数据为例进行不同算法间的预测,各算法的日负荷预测分布图,如图3所示。
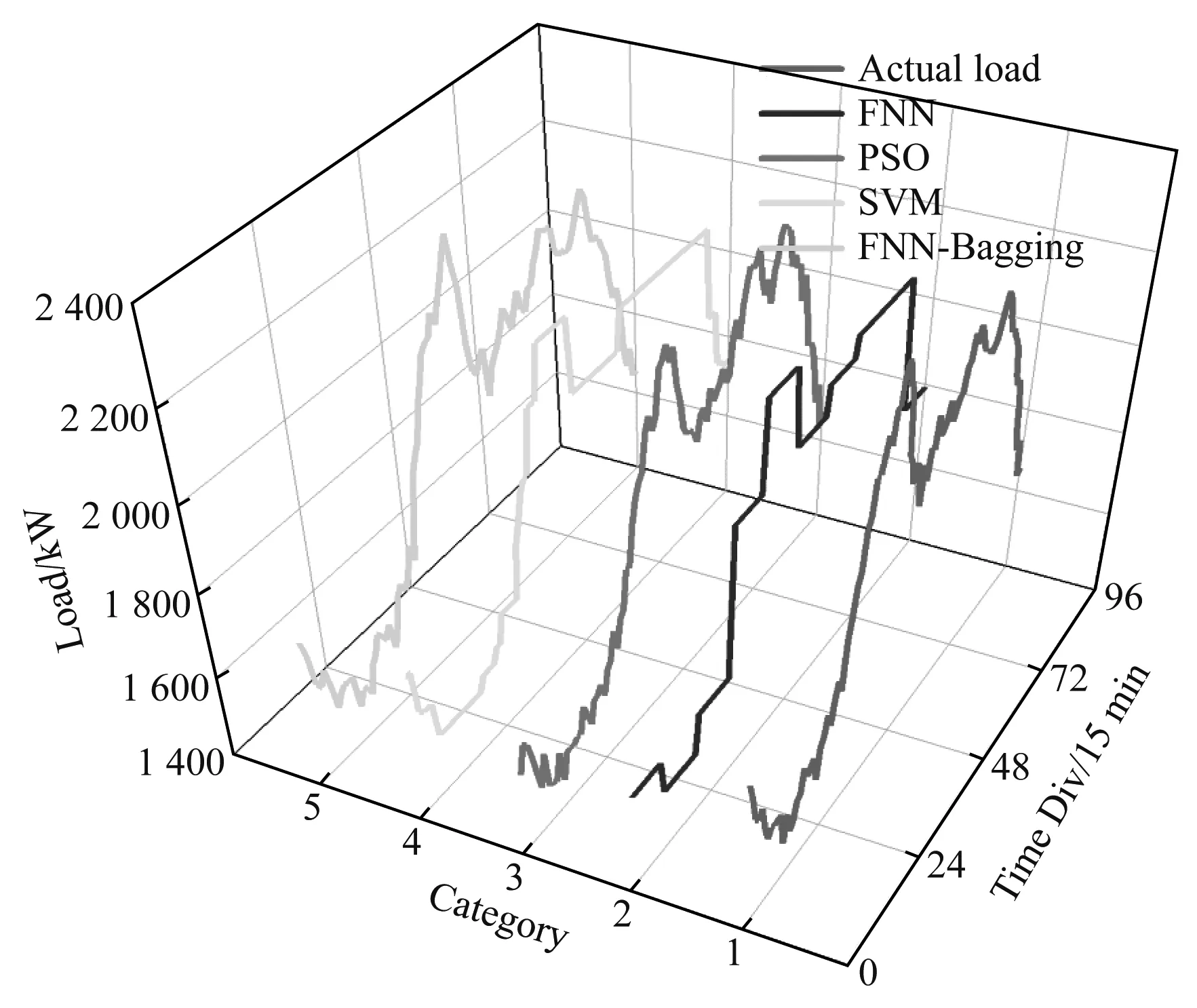
图3 日负荷预测分布图
为明确研究各算法的精确程度,下面通过误差指标式(17)的e来衡量。不同算法的相对百分比误差分布关系图及误差棒,如图4所示。

图4 相对误差百分比对照图
从图4中可知,所提出的FNN-Bagging算法的e最低,误差线最短,整体预测数据准确性更高、变异程度更低。从当日96点负荷的最低e出现的次数来看,FNN-Bagging算法占总数的61.45%。就整体日负荷分布情况来看,负荷曲线呈现中间低,两头更低的趋势,用电峰值集中在上午44点、傍晚68点、晚上80点负荷附近,初步可以判断该负荷为居民用电负荷,判断依据是用电峰值多集中在居民用餐时间前夕,家用电器设备的大量使用是负荷增加的主要原因。在48点到52点之间出现短暂的负荷下降,有可能是一部分居民在午间休息。在88点到96点及0点到6点日负荷值均相对较低,该时间段为大部分居民的睡眠时间。
实验三:不同时间段的预测精度
日负荷在不同时间段的特性能够反映该地区的用电特征,现以表格的方式进行分类,如表1所示。

表1 时间段的日负荷分类表
各算法的MAPE对照图,如图5所示。
由图5可知,上午的综合MAPE值最高,预测效果最不理想,下午和傍晚的综合MAPE值较低,预测效果较好。FNN-Bagging算法每个时间段的MAPE值均低于0.8%,而SVM算法的MAPE平均值为1.73%,其他算法的值就更高了,明显看出,FNN-Bagging算法具有更好的预测效果。
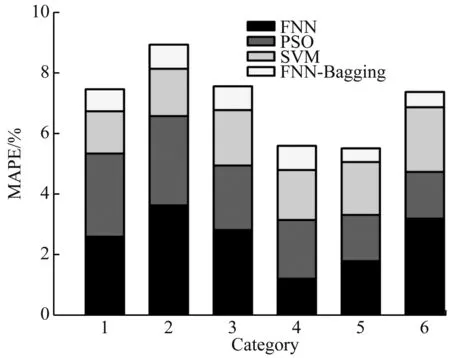
图5 不同算法间MAPE对照图
为分析算法间MAPE的准确性,各算法MAPE的误差棒分布,如图6所示。

图6 算法间的MAPE误差棒对照图
由图6可以看出,FNN算法在下午的MAPE值最低,下午和傍晚的误差线较短。PSO算法在晚上的MAPE值和误差线均最小。SVM在凌晨和早上具有更好的预测精度。FNN-Bagging在晚上的MAPE值和误差线最低,整体的均值标准差为0.221 7%,且均低于同一时间段的其他算法。
5 总结
本研究利用装袋算法可以将弱预测模型通过自助方式训练成强预测模型序列,FNN-Bagging算法可以在训练样本过程中并行计算,能够有效地减少训练样本和运行过程所需的时间。迭代次数在50次以上时,样本数量越高,系统预测性能越好。其中FNN-Bagging模型算法的MAPE误差指标值在不同时间段均较小,具有更好的预测精度。
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
中国食用菌(2020年9期)2020-11-11
科技创新与应用(2020年6期)2020-02-29
农家之友(2018年4期)2018-01-30
中学生数理化·中考版(2017年12期)2017-04-18
北京理工大学学报(2016年6期)2016-11-22
系统工程与电子技术(2016年7期)2016-08-21
食品安全导刊(2014年7期)2014-10-21
