
融合社交关系与代价敏感的兴趣点推荐算法
2021-05-12 08:29张进孙福振王绍卿徐上上
山东理工大学学报(自然科学版) 2021年4期
张进,孙福振,王绍卿,徐上上
(山东理工大学 计算机科学与技术学院,山东 淄博 255049)
近年来社交网络应用的一个明显进步是引入空间技术,促进了基于位置的社交网络location-based social network, LBSN)的蓬勃发展,如Foursquare, Twinkle和GeoLife。在LBSN中,基于空间技术的位置也被称为兴趣点(point-of-interest, POI),例如餐馆、商店和博物馆等。然而,LBSN的兴趣点推荐面临很多的问题,例如矩阵稀疏、推荐精度不高、模型性能不高等。选择合适的上下文信息与推荐方法是提高推荐精度、更好地挖掘用户偏好的一种方法。在LBSN中,兴趣点推荐融合多种上下文信息,Jamali等[1]提出了SocialMF算法,将社交关系融合矩阵分解,集成信任传递机制,缓解了冷启动问题。Du等[2]将L1正则融入ListMLE算法损失函数中,缓解了排序列表的稀疏问题。Xu等[3]探究了基于Group的列表级排序学习算法,将关联性高和关联性低的标签划分为组的形式,结合无监督学习生成更准确的标签。Yu等[4]探究高斯建模用户签到分布,利用BPR优化泊松矩阵分解过程,Zhang等[5]使用高斯核密度估计计算用户的地理因素对兴趣点推荐的影响。
近年来,有研究者将排序学习方法融入推荐过程中。排序学习是利用机器学习方法对物品或兴趣点进行排序,输出符合用户偏好的兴趣点列表。按照训练数据的形式不同分为点级排序学习、对级排序学习以及列表级排序学习。Yin等[6]基于用户隐式反馈使用点级排序学习方法挖掘隐含特征矩阵。Pan等[7]考虑用户倾向于物品之间的偏序关系,在物品对集合上定义损失函数并学习排序模型。Li等[8]利用列表级方法ListNet处理特征矩阵,对比排序性能的差异。Chen等[9]将列表级排序应用到餐厅推荐中,利用排序模型学习基模型产生的结果,为垂直搜索提供了查询与推荐方案。上述算法融入不同的上下文信息,大部分采用矩阵分解的方式计算用户潜在特征向量,存在一定的局限性:仅仅考虑单个物品或两个物品之间的关系,未能考虑推荐列表整体的特性。对于分布不均匀的数据,物品对或兴趣点对的差异过大,从而对推荐精度的影响程度存在差异。
为挖掘个性化的用户偏好,从推荐列表整体出发,考虑用户推荐列表中不同位置的关注度存在差异。本文改进列表级排序学习方法,把ListMLE[10]引入兴趣点推荐,并融合社交信息作为打分函数计算方式,采用代价敏感方式赋予列表不同位置不同权重,最终得到排序模型,为用户产生推荐结果。
1 ListMLE算法

设定一个随机初始化打分函数Score对这n个兴趣点列表进行评价:
(1)
Sort函数呈降序排列,则它们对应的人工排名为
(2)
将集合表示为T={(U,H),Y},此集合作为ListMLE的训练集。将用户的兴趣点列表表示为向量x(j),每个向量都由打分函数得出对应分数。因此将训练集改写为T={X,Y}。

依据Plackeet-luce模型,定义排序模型中序列的概率为
(3)
式中:w为模型参数;y(i)和y(k)为排序列表中第i和k个兴趣点。因此排序似然函数为
(4)
对似然函数求导得梯度公式(5):
(5)
根据公式(5)使用梯度下降算法求得参数w,通过训练获取排序模型后,可以对用户的兴趣点列表进行排序后进行推荐。ListMLE算法的步骤如下:
1)首先预处理数据,将数据预处理成列表形式{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))} ,同时定义学习率η以及容忍误差ε。
2)其次初始化神经网络参数w,开始循环,将所有的样本输入到神经网络中,并计算梯度Δw,通过梯度依次更新参数w,直至所有样本已经训练完成。
3)每次循环计算训练集的损失,直至损失小于设定的容忍误差ε。循环结束后输出训练好的神经网络参数w并产生推荐结果。
在数据的处理过程中,ListMLE算法一般采用随机初始化函数Score的方式对每个列表进行初始化的打分,在基于位置的社交网络中,上下文信息是解决初始化问题以及冷启动问题的有效途径,本文接下来采用用户之间的社交关系信息作为初始化列表分数的依据,同时针对用户对于列表前后部分的关注度存在差异的问题,使用代价敏感的方式赋予列表中不同位置的兴趣点不同的权重,以此作为基于社交信任与代价敏感的得分函数。
2 融合社交关系与代价敏感的推荐算法
社交关系是基于位置社交网络环境下的一个重要的上下文信息,存在社交关系的用户在不断地相互影响他们之间的兴趣偏好。据此在训练前假设用户的兴趣爱好完全由社交关系决定,即用户A喜欢的兴趣点对于他的朋友用户B同样喜欢。在实际应用中,排序列表中不同的位置代表了用户对兴趣点不同的偏好程度,排名越靠前代表用户对于此兴趣点的兴趣越大,但列表中不同位置兴趣点排序出现错误的代价不同,用户往往关心排序列表前面的兴趣点,对于排序列表靠后的兴趣点的关心程度有一定的下降,代价敏感学习也是基于此原理。
2.1 社交关系影响
2.1.1 社交相似度计算
首先采用皮尔森相关系数计算用户之间的相似度,如公式(6)所示:
sim(u1,u2)=
(6)

2.1.2 信任度计算
在传统的社交关系矩阵Ru1,u2,用户u1与用户u2存在社会关系,则对应元素值为1,反之为0。社交关系集合为U{u1,u2|Ru1,u2=1}。
对于社交关系集合,本文利用信任度计算衡量用户之间的社交关系远近。信任度是由用户共同签到数量与用户签到质量决定。共同签到数量比值T1计算见公式(7):
(7)
式中Nu1u2表示用户u1与用户u2之间的共同的兴趣点数量。签到质量是具有社交关系用户对于兴趣点的频率与其他用户对于此兴趣点的签到频率之差是否小于一个阈值δ。签到质量T2计算见公式(8)和公式(9):
(8)
式中:Qu1,i表示用户u1对兴趣点i的签到频率;δ表示阈值。
(9)
用户之间信任度T计算见公式(10):
T=T1+T2。
(10)
2.2 代价敏感打分函数
融合社交相似度与信任度表示打分函数中社交关系的影响,公式如下:
Social_Score(u,i)=sim(u1,u2)·
T(u1,u2)·Uu,i。
(11)
代价敏感学习赋予排序列表中每个兴趣点不同的权重,计算排序列表时为列表中每个兴趣点学习权重αi,权重αi之和为1且随着排序列表兴趣点位置变化,权重由前向后不断降低。将计算出的社交关系影响与代价敏感方法结合得出打分函数的计算见公式(12):
(12)
式中:L表示兴趣点列表的长度;u表示用户;i表示兴趣点。
2.3 改进的ListMLE推荐算法
所提推荐算法考虑到用户信任关系,将用户间社交关系信息作为初始化列表分数的依据;同时考虑到列表前后关注度差异,使用代价敏感的方式赋予列表中不同位置的兴趣点不同的权重。为提升推荐质量,将社交关系与代价敏感打分函数融合到ListMLE算法中,算法伪代码描述如下:
输入:用户-兴趣点签到数据,用户-社交关系数据集,用户-兴趣点-地理位置信息数据集。
输出:TOP-K推荐列表
步骤1 数据预处理,依据数据集为每个用户生成一定数量的推荐列表 。
步骤2 社交关系影响计算。通过公式(6)计算兴趣点的相似度。通过公式(7)—公式(10)计算兴趣点之间的信任度,并最终通过公式(11)计算社交关系对每个用户每个兴趣点的影响。
步骤3 基于代价敏感设置推荐列表中每个兴趣点的权重,选取不同代价敏感列表长度,学习不同列表兴趣点的权重,依据评价标准选取最优参数作为推荐列表的最终得分
步骤4 将步骤2中得到社交关系影响与步骤3得到推荐列表长度与权重融合生成推荐列表分数即公式(12)。
步骤5 将推荐列表与分数输入神经网络,依据公式(4)排序损失函数利用梯度下降算法计算更新参数w,产生推荐结果。
3 实验数据分析
3.1 实验数据集与实验环境
实验所用数据集为Gowalla数据集。Gowalla是基于位置的社交网站,在此网站上用户通过签到分享位置,数据集源自SNAP网站,包括18 737个用户对于32 510个兴趣点的签到信息。
实验环境为Intel(R) Core(TM)i7-6700HQ,2.6 GHZ CPU 24 GB RAM,在Window10系统下采用Python3.6实现算法,选取PyCharm (Community Edition)作为开发平台。
3.2 实验对比
3.2.1 模型与其他模型对比
实验选取准确率、召回率作为算法评价标准[11],比较融合了社交关系与代价敏感的改进ListMLE、RankGEOFM[12]、ListNet[13]与对级排序学习方法BPR-MF[14-15]四种算法在Gowalla数据集下的评价标准的差异,讨论分析了融合社交关系与代价敏感打分函数的影响。
1)为探究列表级排序学习方法与对级排序方法在兴趣点推荐领域中的推荐精度差异, BPR-MF算法特征向量长度为10。四种模型在Gowalla数据集下的精度对比如图1和2所示。

图 1 改进ListMLE与其他模型在Gowalla数据集中准确度对比图Fig.1 Comparison of ListMLE and other models of accuracy in Gowalla dataset

图 2 改进ListMLE与其他模型在Gowalla数据集中召回率对比图Fig.2 Comparison of ListMLE and other models of recall in Gowalla dataset
2)改进ListMLE算法和ListNET算法随着TOP-K值的变化呈稳定下降趋势,而BPR-MF算法在TOP-K值为[10,20]之间出现了一定程度的波动,验证了列表级排序学习的健壮性和稳定性。当TOP-K值为5、10、15、20、25时,改进ListMLE算法相比于BPR-MF算法分别提升了18.8%、65.8%、29.7%、34.7%、51.2%。BPR-MF算法是基于对级排序学习的兴趣点推荐方法,训练数据是以用户与两个兴趣点的偏序关系对的形式,通过对比两种算法的准确度,改进ListMLE在准确度上相比BPR-MF算法有明显的提升,同时对比改进ListNET算法,RankGEOFM算法和BPR-MF算法,可以看出列表级的排序学习方法在推荐精度上比对级的排序学习方法在兴趣点推荐中有明显的提升,验证了将训练数据以列表的形式输入更符合实际的理念和贴近用户的偏好。此外,通过四种算法召回率的对比,改进的ListMLE算法在召回率上也优于其他四种算法。
3.2.2 融合社交关系与代价敏感的打分函数对比
为验证融合社交关系的代价敏感函数对于ListMLE算法的影响,设计实验选取Gowalla数据集,设置TOP-K值为5、10、15、20。对比未加入代价敏感权重的ListMLE算法与加入代价敏感权重的ListMLE算法的准确度,实验结果见图3。有代价敏感的ListMLE算法在准确度上相对于没有加入代价敏感学习的ListMLE算法分别提升了16.3%、15.2%、12.5%、14.5%。在准确度的对比下,代价敏感学习对于推荐结果有较为显著的提升,验证了代价敏感学习的意义,即用户往往对于排序列表前面的兴趣点更为看重,对于排序列表后面的兴趣点的关注程度会有一定的下降。
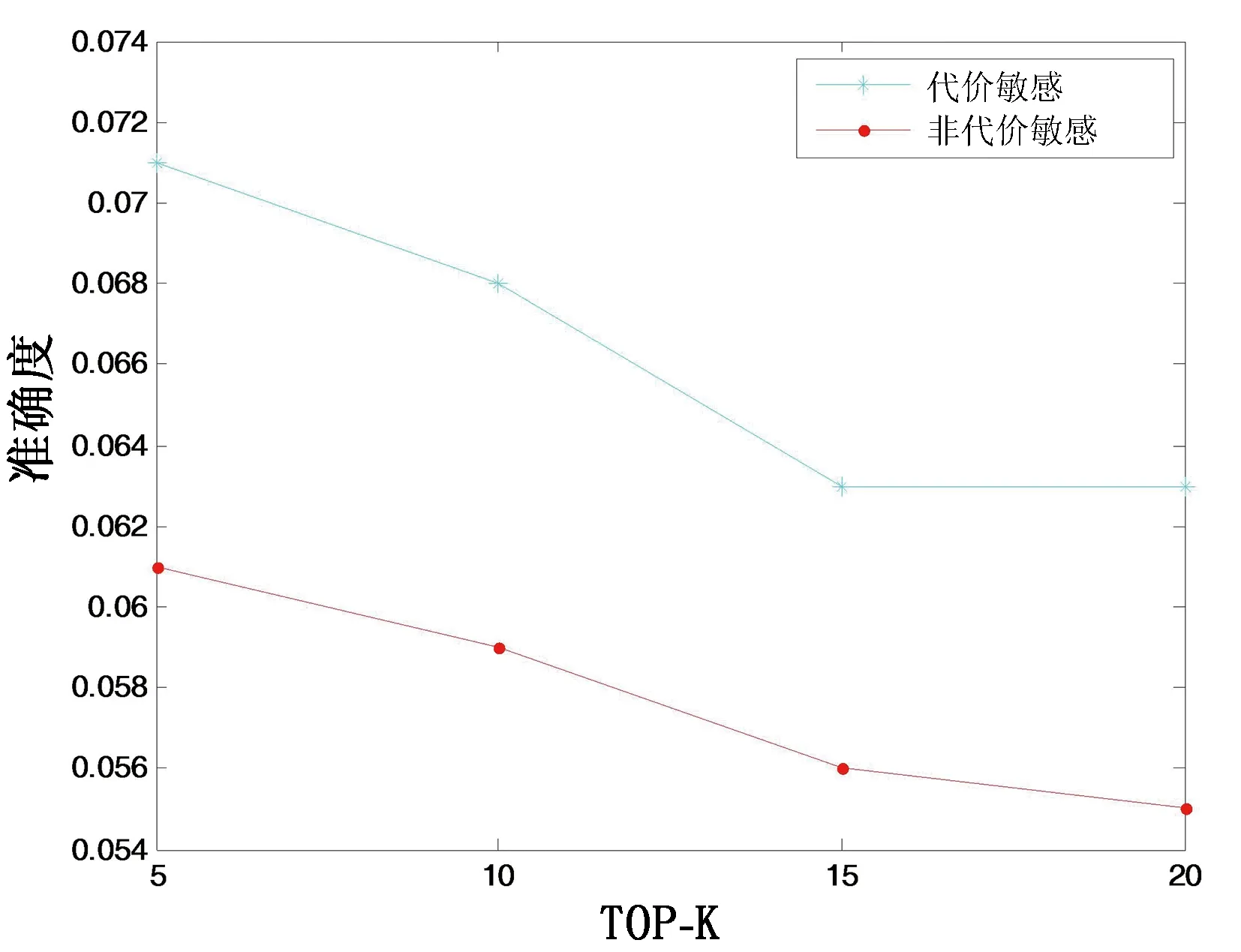
图 3 代价敏感函数与非代价敏感函数准确度对比Fig. 3 Comparison of cost-sensitive function and non-cost-sensitive function in precision
3.2.3 代价敏感的排序列表长度
图4表示在Gowalla数据集下改进ListMLE算法在不同的兴趣点列表长度下的准确度和召回率。首先选取实验区间[4,12],设置步长变化为1,改进ListMLE算法的准确度在权重赋值列表长度为6时取得最优值0.071,召回率取得最优值0.042,在4时准确度取得次优值0.068,召回率为0.04,之后呈现不断下降趋势。由图4可以看出,用户对于排序列表的重视仅限于排序列表中的头部位置,随着列表长度的增加,用户对于兴趣点的重视也在不断下降,侧面反映了用户的偏好,也验证了代价敏感的思想的有效性。
实验表明在代价敏感函数中,将兴趣点列表的长度设置为6时,ListMLE算法的推荐精度达到最优。
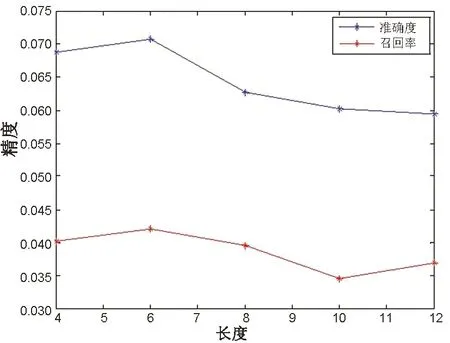
图4 代价敏感列表长度Fig.4 Length of list with cost-sensitive
4 结束语
为缓解兴趣点推荐过程中的数据稀疏问题,进一步提高推荐精度,提出一种融合代价敏感与社交关系的改进ListMLE推荐算法。针对ListMLE算法中打分函数不能很好地拟合用户兴趣偏好问题,提出了融合社交信任的方式作为打分函数的依据,并依据用户对于推荐列表的不同位置存在不同的关注程度,将代价敏感学习融入打分函数,生成基于社交信任与代价敏感的打分函数应用到兴趣点推荐过程中。实验结果证明,改进的ListMLE算法在兴趣点推荐领域中不同数据集下的准确度和召回率优于基线算法。
未来将尝试对多种上下文信息融合展开深入研究,并使用深度学习模型与算法结合,以进一步提高推荐性能。
猜你喜欢
名家名作(2021年4期)2021-05-12
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
中学生数理化·教与学(2017年4期)2017-04-22
作文与考试·初中版(2017年12期)2017-04-19
中学生数理化·中考版(2015年10期)2015-09-10
小说月刊(2012年3期)2012-05-08
