
重构特征的用户-项目代反馈推荐模型研究
2021-05-12 08:29王帅孙福振王绍卿常万里徐上上
山东理工大学学报(自然科学版) 2021年4期
王帅,孙福振,王绍卿,常万里,徐上上
(1.山东理工大学 计算机科学与技术学院,山东 淄博 255049;2.约克大学 计算机科学学院,英国 约克 YO10 5GH)
网络空间中蕴含的信息爆炸式增长制约了搜索引擎提供有效信息服务的能力,推荐系统作为一种主动式信息服务的新方式,通过构建用户与项目关系模型实现对用户需求的挖掘与匹配,为传统搜索引擎提供可行的替代和补充方案以解决信息过载问题。
协同过滤作为个性化推荐算法中最经典的类型,用户数据可以整理为用户-项目评分矩阵[1]。对评分矩阵进行矩阵分解可以完成对未知值的预测[2-3],同时减少计算时间与存储空间。因此改进奇异值分解最早由Koren应用于隐语义模型LFM[4](latent factor model),将用户-项目评分矩阵(m*n维)分解为用户特征矩阵(m*k维)和项目特征矩阵(k*n维)。该模型存在的问题是难以对推荐结果进行合理的解释,同时矩阵分解会造成评分矩阵的信息损失与预测失效[5]。
为充分利用辅助信息提升推荐效果,学术界提出了多种基于特征重构的反馈模型,如SVD++[6],能够有效利用隐信息预测评分,同时也存在算法复杂度高和信息损失问题。Wang等提出了矩阵分解的非负模型NMF[7](non-negative matrix factorization),在理论上存在可行性,但由于特征非负的限定导致预测误差较大,需要收敛效率极强的优化模型才可得到较好效果。Yu等提出了图信息模型[8](GraphInfo),通过构建用户与项目的拉普拉斯矩阵,利用拓扑图关系挖掘同类间的相似性信息,并通过GRALS优化[9]将拉普拉斯矩阵融入正则项。该模型提供了一种可扩展的模型,但对图信息内部的优化极其复杂且对结果不可解释。上述模型难以将辅助信息数据通过建模转为评分矩阵需要的逻辑回归类型[10-13],对评分预测提高不明显,辅助信息对推荐结果的解释是单薄且不可靠的。
本文针对推荐过程中的信息损失和辅助信息建模问题,提出一种重构特征的代反馈推荐模型。通过向量相似性计算重构特征,获得代反馈信息,增强训练过程中的特征挖掘能力,并完成对辅助信息的交替反馈。运用代反馈信息融入矩阵分解模型对评分预测进行补充,以提高推荐的准确性。
1 重构特征
特征重构首先将评分矩阵利用二分类分解为观测矩阵与未观测矩阵。利用k最近邻模型(kNN)排序对观测矩阵中用户与项目的相似性进行排序,排序结果利用jaccard系数对每个相似单元进行权值化特征表示,将每个相似单元的评分与权值特征结合,形成用户与项目的显性特征分量。对显性特征分量进行高斯标准化,求和获得用户与项目的显性特征,将未观测矩阵进行矩阵分解得到隐性特征,将显性特征与隐性特征结合得到重构特征。
1.1 显性特征
提取评分矩阵的已观测数据,对未观测数据进行矩阵分解以缓解特征信息损失问题。如图1所示,将原评分矩阵分为观测矩阵与未观测矩阵:

(1)


图1 User-item矩阵的二分类Fig.1 User-item matrix binary classification
对显性特征提取需要得到用户与项目的相似实体,对具有相似性的同类实体进行排序。用户与项目的相似性使用kNN计算得到,kNN使用欧式距离表示,其定义为

(2)
用kNN得到的前k个相似性数据组成用户与项目的相似排序,排序定义为:
(3)
(4)
式中Θ(ui)和Θ(vi)分别表示用户ui与项目vi经过kNN排序之后的相似实体组合。
为了提取用户与项目的每个已观测数据的特征,需要对排序集合中每个相似实体与集合的总体实体对比计算权值,即显性特征分量的权值化特征。权值运用jaccard系数计算,权值特征的计算过程如下:
(5)
(6)
式中:Γui与Γvi分别代表用户ui或项目vi的权值化特征,由指示函数Y与jaccard函数J的乘积得到;指示函数Y指示用户ui与uk在同一项目上有评分或项目vi与vk在同一用户上有评分。
每个用户和项目的显性特征分量由权值与每个已观测评分的积构成。定义为

(7)
每个用户的显性特征分量是行向量,而每个项目的显性特征分量是列向量。由于观测评分矩阵是稀疏矩阵,因此显性特征分量也是稀疏的。由图2的示例可知,用户u1的显性特征分量存在4个,项目v1的显性特征分量存在2个。

图2 权值特征计算过程Fig.2 Weight characteristic calculation process
显性特征由每个特征分量的高斯标准化向量之和表示。定义为:
(8)
(9)
式中:μ(φui)与μ(φvi)代表用户ui与项目vi显性特征分量的均值;σ(φui)与σ(φvi)代表用户ui与项目vi显性特征分量的高斯标准差。利用式(8)和式(9)计算所得到的显性特征Δui,Δvi是将观测矩阵中每个用户与项目的特征降维后的单向量形式,在减少信息损失的同时亦降低重构特征模型的复杂度。
1.2 隐性特征及重构
未观测矩阵分解之后得到用户与项目的隐性特征。分解公式为
(10)
将用户与项目的显性特征与隐性特征组合为用户特征向量与项目特征向量,重构表达式为
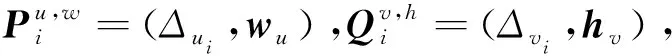
(11)

显性特征将已观测数据中相关信息高度提取并将辅助信息一并融入,能够充分表达用户与项目在已观测数据中表现的显性信息。隐性特征来源于未观测数据的矩阵分解模型,由于未观测矩阵中有效信息含量较少,因此隐性特征需要从显性特征中挖掘辅助信息。显性特征与隐性特征的重构能够相互影响,使得模型拥有表达复杂特征的基础能力,也为辅助信息融入评分预测提供了矩阵化的处理模式。
2 补充反馈
2.1 代反馈
完成显性特征和隐性特征的重构后,对矩阵分解的特征乘积交互过程做补充预测,提高预测结果的准确性与可解释性。预测过程是将显性特征与隐性特征组合,采用向量间相互投影的运算规则,定义为代反馈模型,公式为

(12)
图3所示是利用向量相似性将用户与项目特征向量相互投影,在交互过程中将用户显性特征信息投影至项目隐性特征,以及项目显性特征信息投影至用户隐性特征。通过交互过程完成对用户信息与项目信息的交替反馈,构成完整的特征信息。

图3 代反馈模型示例Fig.3 Generation feedback model example
2.2 辅助信息反馈
利用向量投影将辅助信息进行补充反馈,反馈过程如图4所示。在用户对项目进行评分的过程中,利用用户辅助信息解释项目的隐含特征,反之亦可用项目辅助信息解释用户的隐含特征。例如该项目可能适合某年龄段,某性别,某职业的用户;该用户喜欢某类别,某作者,某名称的项目。
代反馈模型利用交替反馈过程提供特征的全信息能力,实现特征的可解释化与显隐性复杂特征表达能力。

图4 辅助信息的代反馈Fig.4 Generational feedback of auxiliary information
3 算法伪代码
3.1 重构特征伪代码
表1的初始化参数是观测矩阵,对观测矩阵中所有的用户与项目分别计算相似性。计算过程遍历观测矩阵中所有的用户与项目,在遍历过程中分别对用户和项目利用kNN排序模型中的欧几里得距离作为相似性的判别标准,将计算结果加入相似性集合Θ中,取集合中前k个相似实体作为最终结果。k的取值由特征维度决定。

表1 显性特征kNN排序伪代码Tab.1 Dominant feature kNN ranking pseudo code
表2的初始化是每个用户与项目实体的相似性集合。计算过程是对每个实体与其相似性集合中的其他实体遍历计算对应元素特征,利用jaccard计算本体与实体在对应元素上的权值特征。当实体之间在同一行或同一列的对应元素同时存在评分时,则Y(0,1)函数结果为1,否则为0。经过Y(0,1)函数的判别后,将权值特征写入实体的对应矩阵。
对每个权值特征标准化,其计算过程为:首先对每个实体的所有权值特征计算其均值,再由实体的每个权值特征减去均值的平方之后再除以权值特征的维度值,最后对此结果取平方根得到每个权值特征的高斯标准化分量。

表2 显性特征权重伪代码Tab.2 Explicit feature weight pseudo code
表3的输入是权重特征与其高斯标准化分量,目标是计算用户与项目的显性特征向量与重构特征向量。首先通过权值特征减去其均值再除以对应的高斯标准化分量得到每个显性特征分量,将显性特征分量累加得到每个用户或项目实体的线性特征向量。然后对未观测矩阵进行矩阵分解,将显性特征与隐性特征进行重构得到新的用户与项目特征向量。

表3 显性特征与隐性特征重构伪代码Tab.3 Features reconstruction pseudo code
3.2 代反馈预测伪代码
表4是代反馈预测模型的算法流程,目标是通过对参数的不断迭代更新得到最优模型,从而进行预测。首先计算当前预测评分与实际评分的误差求解Λ矩阵,然后根据误差函数对代反馈矩阵E和隐性特征矩阵W、H求解梯度,利用随机梯度下降法对代反馈矩阵与隐性特征矩阵进行参数更新构建预测模型。

表4 代反馈预测算法伪代码Tab.4 Generation feedback prediction algorithm pseudo code
4 数据实验结果与分析
实验数据来自美国Minnesota大学的MovieLens站点提供的数据集(https://grouplens.org/datasets/movielens)与Yahoo提供的R4-Yahoo数据集(https://webscope.sandbox.yahoo.com)。两个数据集的特征见表5。

表5 数据集特征Tab.5 Dataset features
评价标准选用平均绝对误差MAE(mean absolute error)与均方根误差RMSE(root mean squared error)。
实验环境为Windows系统平台,Intel(R) Xeon(R) CPU E3 1230 V2 @3.30 GHz,32 GB内存。开发平台为Windows Visio Studio,编程语言为Qt,数据对比工具为Matlab。
对比模型采用SVD++[6],非负矩阵分解模型NMF[7],图信息模型GraphInfo[8]。结果分别从MAE与RMSE,训练时间方面进行比较,如图5—图7所示。

图5 MovieLens中的RMSE与MAEFig.5 RMSE and MAE in MovieLens

图6 R4-Yahoo中的RMSE与MAEFig.6 RMSE and MAE in R4-Yahoo
4.1 MAE与RMSE对比结果
从图5与图6的对比结果可以发现,本文重构特征的代反馈模型RFGF利用用户特征与项目特征交替反馈充分挖掘了潜在信息,因而在4种模型中的效果最好。而且随着数据集的扩大,RFGF模型在R4-Yahoo上的效果更加明显。由此证明RFGF模型在获取更深层次的特征能力上强于其他3种模型,在深层次特征转化为预测结果的过程中也具有优势。
4.2 模型效率与影响分析
由图7可知,RFGF模型不仅在RMSE指标上优于其他3种基线模型,且特征迭代更新首次便将RMSE的结果收敛在1左右,表明RFGF模型不仅拥有深层次特征挖掘能力与特征准确结合的能力,同时也拥有较高的模型迭代效率。

图7 MovieLens中的RMSE迭代效率Fig.7 RMSE iteration efficiency in MovieLens
5 结束语
重构特征丰富了特征的表达能力并且完善了特征信息,代反馈推荐模型通过向量投影思想解释用户与项目的交互过程,提高了模型对隐含信息的挖掘能力。特征重构的代反馈模型缓解了矩阵分解带来的信息丢失与预测失效的问题,实验结果表明推荐质量明显提升。将代反馈模型中描述显隐性特征的相似度度量方法与图信息模型结合,融合跨类别的异构信息,有待进一步提升推荐准确率。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
天津诗人(2017年2期)2017-11-29
中国科技纵横(2016年15期)2016-12-29
甘肃教育(2016年22期)2016-12-20
课程教育研究·下(2016年3期)2016-04-19
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
