
一种多头注意力提高神经网络泛化的方法
2021-05-25 05:26陈曦,姜黎
软件导刊 2021年5期
陈 曦,姜 黎
(湘潭大学物理与光电工程学院,湖南湘潭 411100)
0 引言
众所周知,深度神经网络具有较强的函数逼近能力,能够表征复杂函数[1]。最近研究表明,神经网络的表征能力随着网络深度指数增长而增强[2]。在机器学习领域,泛化能力指学习到的模型对未知数据的预测能力[3]。根据可能近似正确(probably approximate correct,PAC)理论[4]理解为以e 指数形式正比于假设空间的复杂度,反比于数据量。目前提高泛化能力方式有增加数据量[5]、正则化[6]、凸优化[7],这些方法因为实际条件差异在使用时有一定的局限性。如今神经网络在许多领域大放异彩,然而在某些场景中却不尽如人意[8]。由于神经网络的泛化问题会影响其推广,所以提高神经网络泛化对生产生活都极具意义。
提高泛化能力研究目前主要有基于神经网络剪枝[9]和基于多个独立单元结合的方法。基于神经网络剪枝的方法提高泛化能力效果甚微,其主要作用是减少神经网络参数量。基于多个独立单元结合的研究将多个相同的子模块独立运行,然后再对子模块信息进行整合,从而提高模型性能。这种方法提高泛化效果较好,但参数量明显多于剪枝方法。Li 等[10]提出一种新的循环神经网络——独立循环神经网络方法,即同层的神经元相互独立,跨层连接;Henaff 等[11]在Entnet 结构中应用独立的门从每个记忆单元中读写,能够在bAbI 任务中有优于基准模型的表现;Clemens 等[12]采用激活层控制多个模块信息交流,但只有在特定的时间步才能进行信息交流[13]。这些研究未对交流的信息进行筛选,在一定程度上保留了冗余信息,因此影响网络的泛化能力;Vaswani[14]提出的Transformer 模型在两项机器翻译任务中表现远优于当前的最优模型,其中提出的注意力机制能够极大提高模型的泛化能力。
受上述方法启发,本文沿用多个独立单元结合思想,采用多头注意力以提高并行长短期记忆网络(Long Shortterm Memory,LSTM)模型的泛化能力。多头注意力根据当前时间步的输入和LSTM 状态的相关度进行选择性激活,激活的LSTM 包含当前输入重要的信息。在信息交流时,激活的LSTM 会读取其它LSTM 信息(包括未激活LSTM中的信息),未激活的LSTM 则按照原有的状态独立更新。于是,当某个LSTM 信息被改变后,其它激活的LSTM 中还存有其信息。如此操作即能提取到样本普遍性特征,增强了鲁棒性,与很多提高泛化的研究思想不谋而合。为了验证本文方法可行性,与传统并行LSTM 进行对比实验,证明本文方法比传统并行LSTM 更稳定、更泛化。将本文方法与3 种相关研究方法进行对比,结果表明本文方法比相关方法能更显著地提高泛化能力。
1 基本结构
1.1 LSTM 结构
当输入为长序列时,传统的循环神经网络(Recurrent Neural Networks,RNN)会出现梯度消失和梯度爆炸问题,LSTM 就是为解决该问题而专门设计的。LSTM 能够在长或者短的序列输入中保留关键信息[15]。实践证明,LSTM性能优于传统RNN。LSTM 状态参数在每个隐藏节点是共享的,就是每个细胞参数可以对整个反应链状态作出修改,Colah 将这种细胞状态的更新机制类比为传送带。LSTM 内部结构如图1 所示(彩图扫OSID 码可见,下同)。
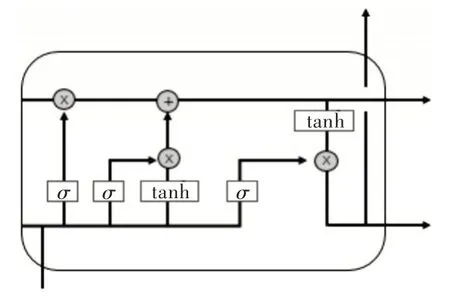
Fig.1 LSTM internal structure图1 LSTM 内部结构
如图1 所示,LSTM 关键在于细胞状态和整个穿过细胞上方的那条水平线,细胞状态在这条水平线上传递,只有少量的线性交互[16]。若只有上面那条水平线是无法实现添加或者删除信息的,只有通过一种叫做“门”的结构来实现。门可以控制信息流通,通常是利用非线性激活sig⁃moid 函数和点积运算实现。sigmoid 层输出的每个元素都是0 和1 之间的实数,表示让对应信息通过的比例。比如0 表示“不让任何信息通过”,1 表示“让所有信息通过”。LSTM 通过3 个这样的门结构实现信息的保护和控制,分别为遗忘门、输入门和输出门。
遗忘门可以过滤之前计算出的状态向量,然后加入到后续运算中,其数学表达式如下:
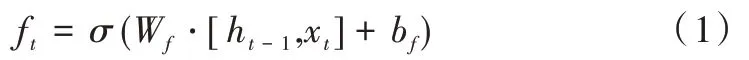
遗忘门输入来自当前时间步的输入向量xt和上一个时间步输出门的输出向量ht-1,其中Wf和bf为遗忘门的权重及偏置向量。经过sigmoid 运算将结果映射到[0,1],得到遗忘门的输出ft。ft控制旧状态信息舍弃,可以和上一时间步的细胞状态进行点积运算,从而更新旧状态。
输入门则是通过激活函数控制上一时间步的状态和当前输入信息,然后参与当前细胞状态更新,其数学表达式如下:
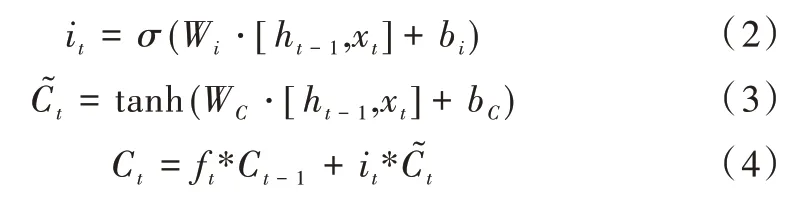
式(2)表示对细胞状态进行更新,式(3)计算出一组候选的细胞状态来取代更新细胞状态中的旧值,式(4)将这两个向量逐元素相乘,接着与经过遗忘门的细胞状态相加,如此完成输入门更新。
输出门建立在之前两个门基础上,数学表达式如下:
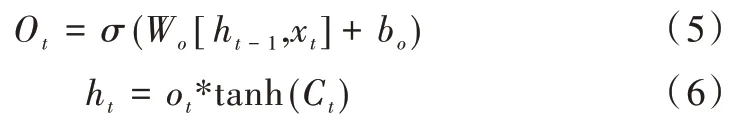
输出门的输出是基于当前输入门更新过的细胞状态。式(5)决定输出的状态信息,式(6)中tanh 层将当前细胞状态压缩到(-1,1)区间内,该输出变量同时作为下个单元的ht-1加入到循环。
1.2 多头注意力机制
对于单个注意力模型可以理解为给定查询向量到一系列键值对的映射,本文查询向量来自LSTM 的状态信息,键向量和值向量来自于当前输入。在给定目标中查询某个元素向量后,通过计算其和各个键向量的相似度得到每个查询向量对应值向量的权重系数,再经过softmax 归一化,将权重系数和相应的值向量加权求和,最终计算出注意力数值。所以,本质上注意力机制是对给定目标中元素的值向量进行加权求和,而查询向量和键向量用来计算对应值向量的权重系数[19]。最常用的两种注意力机制是加性注意力和点积注意力,本文采用点积注意力,其数学表达式如下:
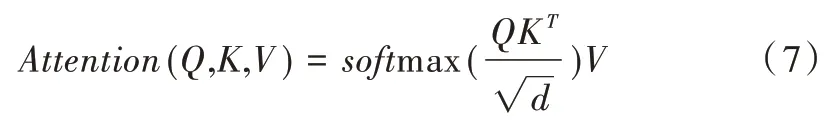
Q,K,V分别是查询向量、键向量、值向量,d是键向量的维数,除以d可以防止softmax 之后的值变得很小。
对于多头注意力模型,可以认为是结合多个单独的注意力而成,其数学表达式如下:
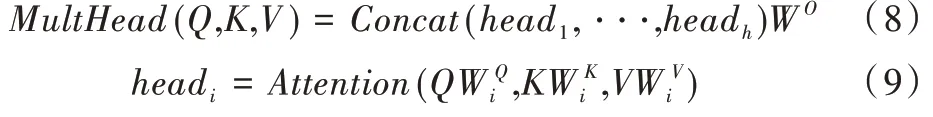
其中,Q、K、V经过线性变换后输入到单个注意力运算[11],这里要做h次,也就是所谓的多头。每次计算一个头,头之间的参数不共享,每次Q、K、V进行线性变换的权重参数W不一样。接着将h次的注意力运算结果进行拼接,最后执行线性变换,就可计算出多头注意力。
2 泛化方法
本文首先利用多头注意力根据并行LSTM 状态信息求出每个LSTM 的注意力权重,然后从中挑选出权重较大的LSTM 进行激活,再将激活的LSTM 中的状态信息通过多头注意力按照一定比例进行信息交流。虽然采用多个网络结构并行的方法较多,但是结合多头注意力激活子网络并进行信息交流的方法却没有,且多次对比实验表明本文方法有较强的泛化性和稳定性。
2.1 本文网络结构
神经网络研究发现,通过增加网络层数可以学习到任务的更高层特征以解决更复杂的任务。虽然增加层数可以提高网络性能,但是模型的运算成本也大幅增加。为了减少深度神经网络的训练时间,基于各种计算平台设计的并行神经网络逐渐成为研究热点[17]。
对于神经网络的并行化主要有数据并行和模型并行两种方法[18]。数据并行是当数据量十分庞大时,将数据分成多个小的子数据集,再将各个子数据集在多个相同模型上并行训练,最后由参数服务器完成参数交换[19];模型并行指将网络结构分解到各个计算设备上,依靠设备间的共同协作完成训练。本文实验在Cuda 平台上进行模型并行训练测试,并行网络中每个LSTM 就是独立的结构单元,如图2 所示。
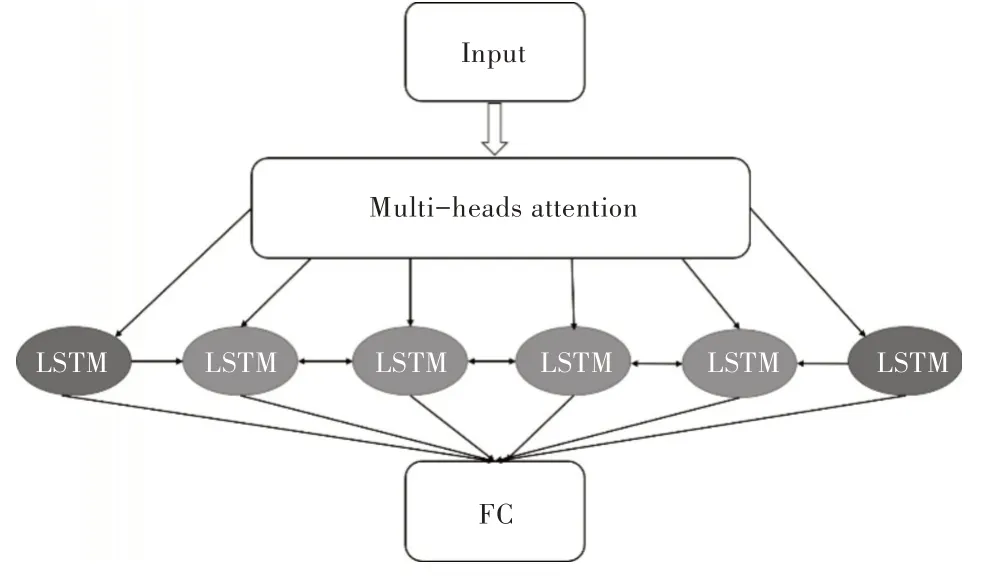
Fig.2 Structure of this paper图2 本文结构
多头注意力结合当前LSTM 状态与输入的相关度选择性激活LSTM,其中绿色框表示已激活的LSTM,蓝色为未激活。在每一时间步,激活的可从其它LSTM 中读取信息,未激活的则保持隐藏状态不变。最后经过神经元个数为10 的全连接层得出预测结果。本文中LSTM 总个数为6,每个时间步激活4 个LSTM,每个LSTM 的神经元个数为32。
2.2 采用多头注意力进行信息交流
起初每个LSTM 是相互独立的,初始状态也是随机的,然后进行自身动态更新。经过多头注意力选定与输入相关的LSTM 设置激活,激活的LSTM 读取其它激活或未激活LSTM 一定比例的信息[20]。本文中每个激活的LSTM 都可以读取其它LSTM 中1/10 的信息。因此,不仅能保留当前任务的重要信息,还能通过信息交流提高鲁棒性[21]。
设每个LSTM 都是相互独立的,它们之间没有信息交流。对于未激活的LSTM,其隐藏状态保持不变,如式(10)所示。

此为第k个LSTM 在t时间步的状态。模型会动态地在每个时间步挑选出和当前输入相关的LSTM 激活,激活的LSTM 得到真实的输入,未激活则得到由全0 组成的空白输入。令xt为时间步t时的输入,如果未激活则:

式(11)是将xt在行方向上进行连接。
接下来用线性操作建立:

R的每行对应一个独立的LSTM 隐藏状态。Wv是将输入映射到对应的V向量矩阵,Wk是将类似的矩阵输入映射到K。是将LSTM 从其隐藏状态映射到Q。
注意力运算结果如下:
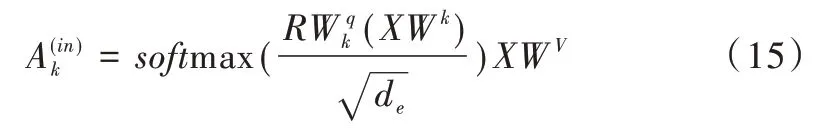
基于上式softmax 计算的值,在每个时间步将较大的softmax 值设置为1,其余则为0。将这几个值与其对应的LSTM 执行点积运算就完成了激活步骤。未激活LSTM 的梯度保持以往的更新,其状态可以被激活的LSTM 读取。对于激活的LSTM 将进行如下更新:
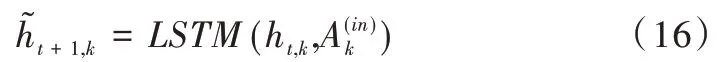
LSTM 在t时间步经过多头注意力作用得到下一时间步的状态ht+1。本文方法即按照上述步骤进行循环更新。
3 实验研究
3.1 实验数据
本文采用MNIST[22]、Fashion-MNIST[23]、CIFAR10[24]、Animals-10 开源数据集进行实验验证。MNIST 是手写数字(0-9)数据集,Fashion-MNIST 是时尚穿搭衣物数据集,CIFAR10 是常见物体彩色图片数据集,Animals-10 是10类常见动物图片数据集,各数据集详情如表1 所示。
3.2 实验对比并行LSTM
本文实验在Linux 系统下搭建的Pytorch 环境进行,批量大小设置为100,损失函数采用交叉熵损失函数,优化函数采用SGD,学习率为0.1,迭代训练1 000 次。
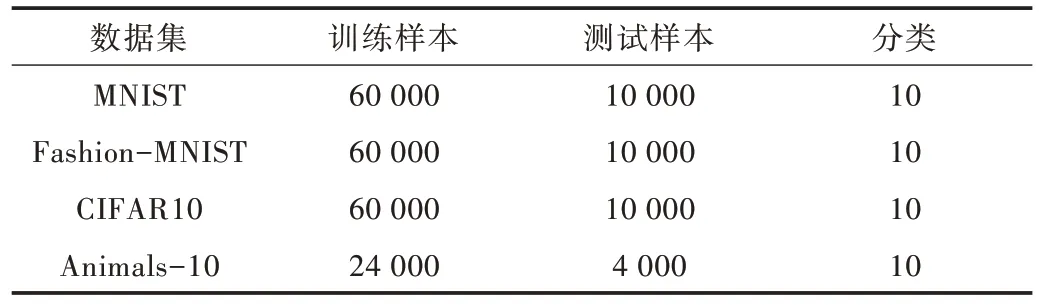
Table 1 Distribution of experimental data sets表1 本文实验数据集分布
实验中LSTM 总个数为6,设置每一时间步激活的LSTM 个数为4,单个隐藏层神经元为32。对比实验中采用4 个并行的LSTM,单个隐藏层神经元也为32,其它参数设置与本文方法相同,这样的设置排除神经个数对实验的干扰。4 种数据集的对比实验如图3 所示。
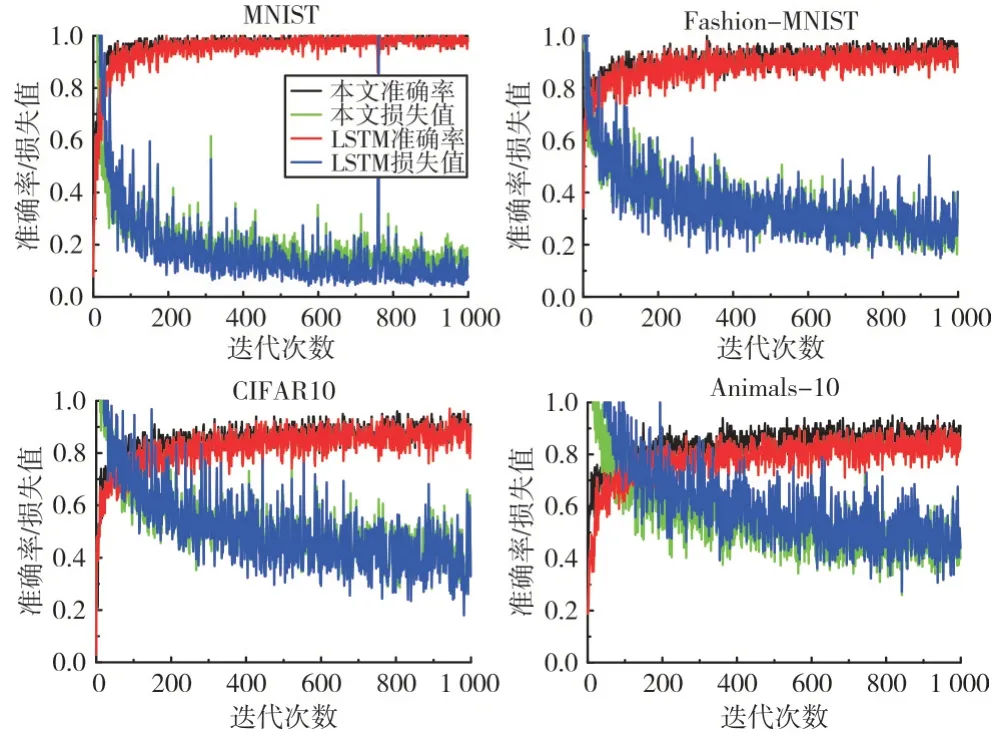
Fig.3 Comparison between the proposed method and parallel LSTM training图3 本文方法与并行LSTM 训练对比
如图3 所示,黑色曲线和绿色曲线分别对应本文方法在训练中的准确率、损失函数值,红色曲线和蓝色曲线对应并行的LSTM 准确率、损失函数值。在4 种数据集上,本文方法均比并行LSTM 的训练准确率高。两种方法在MNIST 数据集上的训练准确率差距极小,但是并行LSTM的训练损失值波动较大。本文方法在Fashion-MNIST 和CIFAR10 的训练准确率明显高于并行LSTM,训练损失值同样比并行LSTM 稳定。在Animals-10 数据集上,本文方法的训练准确率比并行LSTM 有较大提升,训练损失值也更低、更稳定。从训练表现来看,采用本文方法的性能优于并行LSTM 模型。
通常采用测试误差来衡量神经网络的泛化能力,其中测试误差为1 减去测试准确率。将本文方法与并行LSTM在4 种数据集的测试误差进行对比实验。在测试集进行10 次测试,计算出平均测试误差,如表2 所示。
由表2 可知,本文方法在4 种数据集的测试误差均低于并行LSTM。其中,由于MNIST 数据集的任务较为简单,两种方法的测试误差仅相差0.35%。Fashion-MNIST 数据集和CIFAR10 数据集的分类任务较难,测试误差相差约1%,能明显看出本文方法的泛化能力强于并行LSTM 模型。Animals-10 数据集由于任务较难且训练数据较少,导致测试差距较大,达到3.03%。实验表明,本文提出的方法能够有效提高泛化能力。

Table 2 Comparison of test errors between the proposed method and parallel LSTM表2 本文方法与并行LSTM 测试误差对比(%)
3.3 实验对比相关研究
为进一步探究本文方法的泛化能力,继续在4 种数据集上对本文方法与相关研究进行实验。对比的方法有基于门控交流的Entnet[11]方法、基于注意力机制读写信息的RMC[25]方法、基于多个循环结构结合的方法[10]。训练参数设置前保持一致,依旧采用测试误差作为衡量泛化的指标。对比实验测试误差如表3 所示。
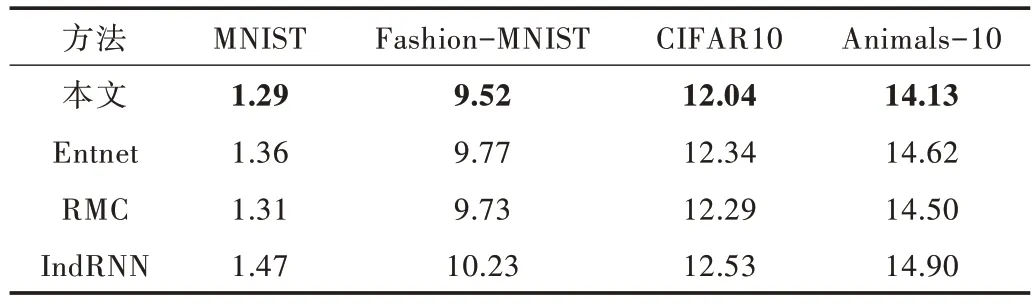
Table 3 Test error comparison between the proposed method and related research表3 本文方法与相关研究的测试误差对比(%)
由表3 可知,本文方法在4 种分类任务中都取得了最好成绩。其中在MNIST 数据集上,本文方法比RMC 方法测试误差低0.02%。由于这个数据集上的分类任务比较简单,所以各种方法差距都很小,并不能明显看出泛化性能的强弱。在其它分类难度大的数据集上,本文方法的测试误差分别比次优方法低0.21%、0.25%、0.37%。因此本文方法比其它3 种相关研究更具泛化能力,表明本文方法能提高神经网络泛化能力。
3.4 图片加噪测试
泛化能力是在真实场景中依然能够发挥出色,对数据的变化具有鲁棒性。本实验使用Python 中的skimage 库将测试集的图片添加高斯噪声,其中高斯噪声均值为0,方差为0.01,训练集则保持原有状态。然后基于前述的训练模型,在4 种数据集上对比相关算法的测试误差,详情如表4所示。
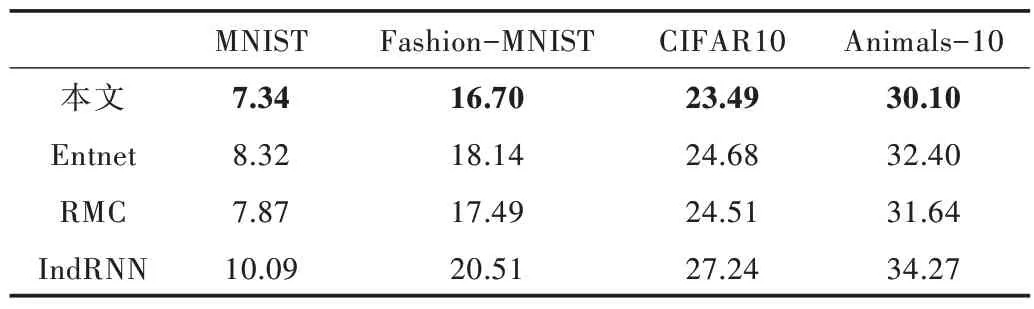
Table 4 Test error comparison between the proposed method and related research表4 本文方法与相关研究测试误差对比(%)
由表4 可知,在加噪情况下本文方法的测试误差都是最小。和未加噪情况相比,本文方法测试误差的变化值均小于相关方法,分别比次优方法低0.35%、0.62%、0.77%、1.19%。这意味着本文方法对于数据的变化有更强的鲁棒性,泛化能力也优于相关方法。综上所述,本文方法能够显著提高神经网络的泛化能力和稳定性。
4 结语
本文采用多头注意力以提高神经网络泛化能力,通过多头注意力选择性激活LSTM 进行信息交流,保留任务中普适性信息,从而提高神经网络的泛化能力。与并行LSTM 网络相比,本文方法表现出更强的泛化能力和稳定性。与其它相关方法相比,本文方法的泛化能力也更强。但本文方法参数量较大,会耗费大量的计算和内存成本。后续研究方向为将本文方法推广到简单的并行结构中,使其能够移植到硬件中。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
传媒评论(2017年3期)2017-06-13
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
