
康养型住宅大数据分析与智能控制
2021-05-25 05:27江桃,张珣
软件导刊 2021年5期
江 桃,张 珣
(杭州电子科技大学电子信息学院,浙江杭州 310018)
0 引言
近年来我国老龄化人口比例不断增加,独生子女因工作等原因无法照顾老人,居家养老[1]是大部分老人的选择,但护理人员紧缺,老年人对常规的智能家居使用方式难以适应。在物联网技术、计算机网络技术以及数据挖掘技术跨越式发展的大背景下,智能家居发展呈现出突飞猛进态势[2],智能家居系统向更高级的具有学习能力的自主操控方向发展。
智能家居系统研究较多,如英国的“智能家居交互屋系统”[3],通过与日常生活数据对比来检测老年人健康状况,有异常时自主向外界求救;芬兰的“活跃家庭生活”居家养老科技产品,在各个房间安装传感器,通过传感器数据分析老年人的位置信息,监测活动信息有无异常;我国“基于物联网ZigBee 技术的智能社区居家养老系统”[4],利用物联网ZigBee 技术实现对老人的身体状况、居家安全、环境能耗等方面的智能监测,可实时将监测数据传输到社区监护中心。以上技术在一定程度上对老人健康与生活行为数据进行异常分析,但是忽略了老年人的认知特点,即他们对高智能设备的学习能力以及接受能力不及年轻人。另外,健康数据获取一般通过佩戴相应的检测模块,增加了老人的心理负担。
本文对数据挖掘算法进行优化改进,挖掘和识别用户多种生活行为,得出用户的习惯模型,根据用户的偏好自动调控设备参数,或者根据环境因素变化,按照用户在不同环境的使用习惯自动调控,以及对多个设备联动调控,为老年人提供精准的智能服务。
1 智能控制系统设计
1.1 系统总体架构
本系统架构采用B/S 模式即浏览器/服务器模式。系统前端页面采用HTML、CSS、JavaScript 等技术设计,前后端交换数据通信时采用Ajax 技术使页面不跳转,响应速度加快,在Web 客户端处理少量简单的业务逻辑和数据操作。服务端利用SSM(Spring,Spring MVC,Mybatis)等开源框架技术,在阿里云平台搭建Tomcat web 服务器、Hadoop+MySQL 数据库,解决智能家居用户海量的数据存储问题。而复杂的业务逻辑和数据分析通过在服务端MySQL 数据库采集智能网关的传感器数据以及无线智能设备使用的历史数据,进行大数据分析,获得用户习惯模式,与当前模式进行匹配从而实现系统的智能控制。系统框图如图1 所示。
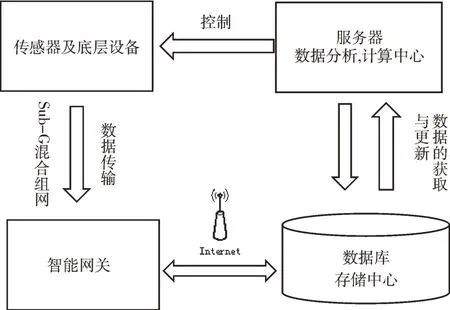
Fig.1 System architecture图1 系统架构
1.2 老年人群的特点与需求
老年人的认知特点:①感官能力(视觉、听觉、嗅觉等)逐渐衰退,身体的协调性、灵活性也相应下降;②注意力不易集中,警觉性较低,在异常情况中的应变能力降低;③记忆力下降,学习能力也大幅降低。
面向老年人的系统需求:操作简便实用、舒适的家居环境、智能化的设备、安全保障。
1.3 系统功能需求
(1)数据采集与传输需求。对家庭环境参数如温度、湿度、光照等诸多模拟量的采集,智能家电以及灯具的开关量采集。因为采集的数据要供后续的行为分析预测及建立行为偏好模型,所以要进行数据预处理,剔除孤立、敏感的数据点;要保证同步采集的数据能够完整存入服务器平台数据库,以供后续分析预测。
(2)服务器数据平台需求。服务器数据平台主要由Web 访问页和数据库管理系统构成。Web 页面提供基本的用户和设备信息操作,数据库管理系统主要负责用户和设备历史操控信息,以及传感器获取的上下文信息存储与管理。
(3)服务器数据分析模块需求。对数据进行挖掘,实现行为分析与预测,建立偏好模型,根据历史信息推断老人的异常行为,推送异常信息。
(4)用户信息模块需求。服务器平台用户分为使用设备的老人、老人子女和系统管理员3 类。注册老人基本信息、子女信息包括注册登录、个人信息修改和设备运行结果查询。系统管理员则登录至系统后台,对设备、平台以及用户数据进行管理。
2 操控行为大数据分析
智能家居数据非常庞大,可能涉及数百万条记录,每个记录通常达到数百个属性[13]。基于Hadoop 的数据处理平台对大量传感信息进行分布式并行处理,并根据处理结果向底层设备发送指令实现智慧化服务[14]。
2.1 Hadoop 技术
Hadoop 是对大量数据进行分布式处理的软件框架,以可靠、高效、可伸缩的方式进行大数据处理,以并行的方式工作,通过并行处理加快处理速度,具有高可靠性、高扩展性、高效性、高容错性的优点。
Hadoop 框架核心是HDFS 和MapReduce。HDFS 为海量的数据提供存储,而MapReduce 至少包含Map 函数、Re⁃duce 函数。Map 函数接受一组数据并将其转换为键值对列表,输入域中的每个元素对应一个键值对。Reduce 函数接受Map 函数生成的列表,根据它们的键缩小为键值对[9]。Hadoop 框架数据存储与处理框架如图2 所示。
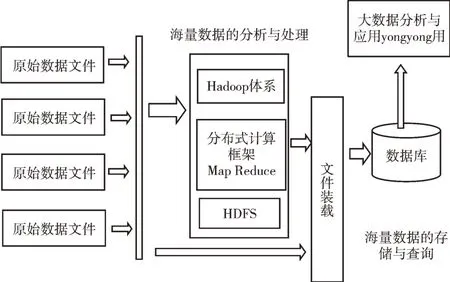
Fig.2 Hadoop framework data storage and processing framework图2 Hadoop 框架数据存储与处理框架
2.2 聚类分析算法
聚类分析属于无监督学习任务,在学习过程中不需要知道目标值,也不需要输入每条数据的标签。聚类分析主要任务就是从大量的无标签数据中分析出数据的共同特征,并尝试为每个数据分配一个比较合适的标签。可挖掘用户的某些属性进行聚类,得到用户对某一设备的控制习惯,从而建立用户偏好模型。传统K-means 聚类算法由于其简洁和高效的特性被广泛使用,K-means 聚类算法步骤如下:
(1)为每个聚类确定一个初始凝聚点。可选择K 个样品作为初始凝聚点,或者将所有样品分成K 个初始类,然后将K 个类的重心(均值)作为初始凝聚点。
(3)将计算得到的类内样本均值作为新的凝聚点。
(4)重复步骤(2)和(3),直到聚类中心位置几乎不变。
(5)输出:含有K 个M 维质心向量的集合。
由以上步骤可知,K-means 聚类算法选取的质心是随机的,生成的K 个类别簇也是人为选定的,而且对噪声和孤立的数据点异常敏感,这些都会导致聚类结果不稳定。为减少选取类别簇的数量K 的影响,提高算法自组织能力,提出融合自组织神经网络SOM 算法对数据特征向量进行训练,将此作为K-means 聚类算法的K 个初始聚类中心,得出最终的行为偏好模型。
2.3 融合自组织神经网络的K-means 算法
SOM 算法可以最大限度地保障训练不会陷入局部最优解,其代价是训练时间较长,而K-means 算法聚类时间短但是易陷入局部最优解。结合SOM 的优点可先将数据输入SOM 网络进行初始聚类,再将这些结果作为K-means 算法的初始聚类中心,从而得到最终的聚类结果[10-12]。实现框图如图3 所示,具体步骤如下:

Fig.3 Clustering process图3 聚类流程
(1)对每个神经元随机初始化,参考权值向量wj(j=1,2,……p)。
(2)寻找获胜的神经元。求出输入样本与所有神经元所对应的参考权值向量的欧式距离,与最小距离对应的即为获胜神经元。
两个m 维类别向量Xi,Xj的欧氏距离如下:
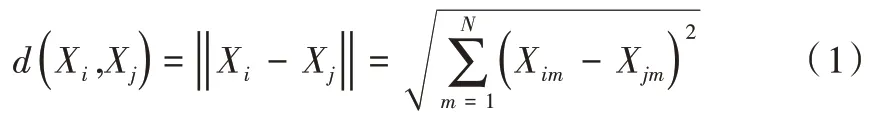
Wj中优胜者权值向量与输入样本Xi的距离为:
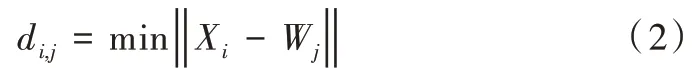
更新获胜神经元的邻域函数及其它神经元权值:
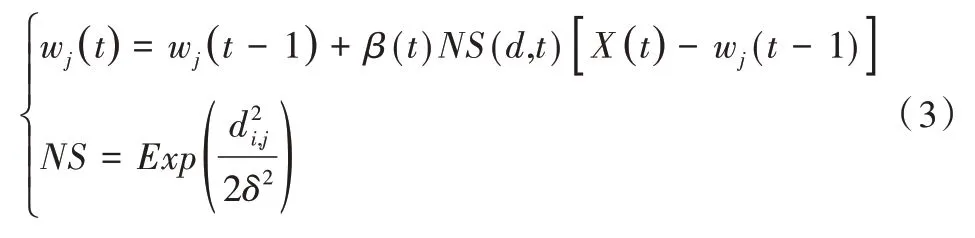
其中,i是输入的第i个神经元,j是第j个竞争神经元;wj(t)是在t次迭代后的权值更新;wj(t-1)是在前一次迭代的权值更新;β(t)是随着迭代t变化的学习率变化;NS(d,t)是邻域强度,由在迭代t时刻从获胜者到一个邻点神经元的距离d的函数表示;x(t)是在第t次迭代所表示的输入向量。
(3)迭代足够的次数获得最终的聚类中心。
(4)将SOM 算法得到的聚类中心作为K-means 算法的初始聚类中心和K 的数值。
(5)计算簇中数据对象到初始聚类中心的距离,所得距离靠近的划分为一个簇:
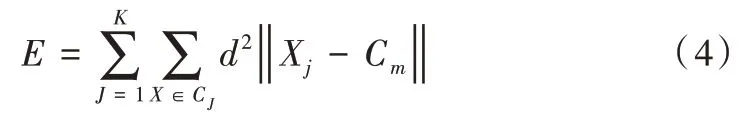
(6)将所得簇的均值作为新的聚类中心重新聚类,直到所得聚类中心不再改变。
2.4 关联控制算法
为让老年人群更加适应智能家居环境,本文采用关联分析算法Apriori 利用用户的历史设备使用信息分析多个设备控制模式之间的关联性,并将这个关联性转换为智能家居情景自动生成模式。
在大规模混杂的数据集中寻找出一些具有较强关联性的规则即关联规则。在智能家居领域挖掘出隐含在多个智能家居设备操作之间的相互关系可实现用户的“关联操控习惯”,对多个家居设备进行集成控制。
常用的频繁项集评估标准有支持度、置信度,流程框图如图4 所示,实现步骤如下:
(1)输入界定频繁与非频繁的最小支持度事物集T。
(2)从事件集合E 中抽取若干个事件组合生成多个元素互不完全相同的候选集合C。
(3)遍历所有的候选集,计算候选集的支持度support(包含X 和Y 的事件数与所有事件数之比)。
Support(X=>Y)=P(X∪Y)=count(X ∪Y)/|T|(5)
(4)如果支持度大于最小支持度,则将该集合认定为频繁项集保存到结果中。
(5)关联规则生成:从频繁项集中提取所有高置信度的规则,即一个事件出现后另一个事件出现的概率。
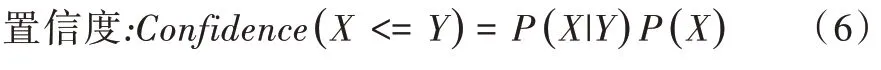
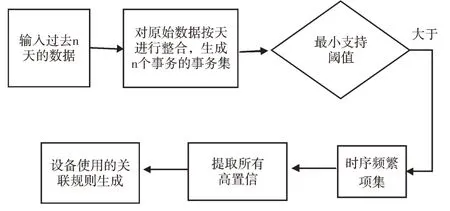
Fig.4 Flow of association analysis algorithm图4 关联分析算法流程
3 行为分析与预测模型实现
3.1 数据采集
在一个复杂的智能家居环境中,通过组建的无线传感器网络收集环境数据与设备的使用日志,即在服务端记录的设备和服务端交互通信产生的数据。数据对象对应于传感器和设备的状态和功能,用户活动标识符(ID)由该活动执行的服务ID 以及相关的对象ID 按时间顺序存储在数据库中。为老年用户提供传感器网络与家庭环境有效的智能交互,如用户在不同位置、不同的时间时的行为数据。传感器会获取当前环境的上下文信息,如时间、位置、温度、设备状态、压力等。以灯光为例日志数据如表1 所示。

Table 1 Log data generated by control lights表1 控制灯光产生的日志数据
3.2 数据预处理
对采集的数据进行清洗、去噪等操作,减少数据冗余,方便数据分析。将经过数据挖掘分析出的用户活动标识与设备使用习惯等行为特征作为活动唯一标识,ID 作为key,行为特征作为value,值之间用逗号隔开,以键值形式存储。
3.3 数据分析与实现
数据分析模块利用基于自组织神经网络SOM 改进的K-means 聚类算法,挖掘老年用户在不同时间段、不同位置对某一设备的使用习惯属性值,即聚类中的特征值,如用户在不同房间、不同时间段对灯光亮度的习惯使用属性值。卧房接近睡觉时间段的灯光亮度要柔和,在客厅活动的时段灯光要亮等,对其进行聚类分析,灯光控制参数可表示为Xi向量,其中包括时间段、位置、时间、亮度等p种属性,表示为{X1,Xi2,…,Xip}。将设备的历史使用信息数据采用基于SOM 改进的k-means 算法聚类。
服务端的数据分析模块利用关联规则算法Apriori 挖掘在同一时间段内多个设备使用的相互关系,以时间戳序列记录已经使用过的设备数据,从而得到用户关联操控数据。对用户在某一时间段的行为进行识别,对下一个行为进行预测,为老年用户提供基于其习惯的关联操控以及家居活动轨迹预测。如将设备使用进行事务序列化,不同设备用不同的字母表示,A、B、C…,同一设备的不同时间段用字母表示为:[A1,A2,A3…],[B1,B2,B3…]等。
利用数据聚类确定设备与时间和环境因素的关联,然后应用频繁模式挖掘发现设备与设备的关联,通过这两个过程提取不同设备按时间序列以及按区域划分的使用模式,将这些模式存入数据库中进行活动预测[13]。当系统无法判断当前新产生的模式时,先反馈给用户,由用户决定这一模式是否安全,作为新的模式存入数据库。模型建立流程如图5 所示。

Fig.5 Process of behavior analysis model establishment图5 行为分析模型建立流程
4 结语
本文基于SOM 算法改进的K-means 算法和Apriori 算法,结合大数据分析、无线传感器网络等技术,在传统居家智能家居系统基础上研究适合老年人生活的康养型智能住宅。简化智能家居设备的控制指令,通过关联规则分析,将某一时间的多个设备进行关联以推测老人当时的活动类型,为居家养老提供更加舒适智能的生活。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
电子制作(2018年1期)2018-04-04
学苑创造·A版(2018年11期)2018-02-01
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
电子设计工程(2015年6期)2015-02-27
河南科技(2014年7期)2014-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
