
不同模型预测土壤有机质含量空间分布对比分析
2021-05-25 03:27李梦佳刘洪斌
西南农业学报 2021年3期
李梦佳,王 磊,刘洪斌*,武 伟
(1.西南大学资源环境学院,重庆 400716;2.西南大学计算机与信息科学学院,重庆 400715;3.重庆市数字农业重点实验室,重庆 400716)
【研究意义】土壤有机质(Soil Organic Matter,SOM)是土壤的重要组成部分,与土壤肥力存在正相关关系,是反映土壤肥力的重要特征,与环境、大气圈、生物圈等的可持续发展存在联系[1-2],受到不同因素的综合影响,具有高度的空间差异性。利用不同模型预测有机质的空间分布,分析不同预测模型的差异,对土壤肥力研究、农业可持续发展有重要的意义[3]。【前人研究进展】近几十年来,地统计学方法被普遍用来描述和预测土壤数据的空间分布,已有的研究表明地统计学是研究土壤特征及其不一致性空间分配、减少评估误差的有效方法[4-6]。普通克里格因其操作简便而成为最广泛使用的地统计学方法之一,国内外研究者运用普通克里格预测了土壤有机碳、pH、有机质、碱解氮、有效磷、速效钾及微量元素的空间分布,并分析了与其他预测模型预测结果的差异,认为普通克里格可以用于预测不同土壤数据的空间分布[7-11]。随着信息技术的发展,分类与回归树、随机森林等机器学习算法被应用到土壤数据空间分布预测中,国内外研究者运用机器学习模型预测了土壤水分、有机碳、pH、有机质及全氮的空间分布[12-16],研究表明随机森林等能较好地模拟环境变量与土壤数据变量的关系,能够有效地解决土壤数据变量与环境变量之间的非线性问题,是现在被广泛应用的方法。【本研究切入点】普通克里格之所以具有较好的预测效果,是因为它有能力使估计误差变化最小化[17]。普通克里格方法基于变量的空间自相关性,依赖于所有样点的空间关系确定,一般情况下,获得有较好代表性的空间关系需要数量足够大和空间覆盖比较好的样本集,因此普通克里格要求样本数量较多、分布均匀及代表性好[12]。克里金法的主要缺点是当样本量少时预测将变得不确定,并且无法模拟因海拔高度、气候和植被等差异引起的土壤特性局部变化,这个缺点可以通过大量采样和使用与土壤特性高度相关的环境变量来解决[17]。随着信息技术的发展,机器学习预测模型被广泛应用,但随机森林等属于黑箱技术,依据它们所获得的结果难以直观地了解土壤与环境变量之间的定量关系[18],而且寻找与研究变量相关性强的、容易获取且廉价的环境变量具有一定挑战性[19],此外研究变量可能受到人为活动的影响,但是人为因子影响不稳定且不易获得定量数据。由此可知,不同的预测模型各有优缺点,本研究是要利用充分的采样点比较不同模型的预测能力。【拟解决的关键问题】本文结合地形、气候、植被和成土母质等9个环境变量,利用分类与回归树、随机森林、随机森林残差克里格和普通克里格4种预测模型对研究区土壤有机质含量进行空间分布预测制图,得到研究区有机质含量空间分布特征,为土壤属性空间变异研究提供依据,并比较不同预测模型的预测精度,分析不同预测模型绘制空间分布图的差异,为高密度采样区制图方法的选取提供参考。
1 材料与方法
1.1 研究区概况
长寿区位于重庆市中部、长江三峡库区上游,地理位置为106°49′~107°27′E,29°43′~30°12′N,总面积为1423.62 km2,研究区DEM及样点分布见图1。该地区属四川盆地东部平行岭谷褶皱低山丘陵区,为典型低山丘陵地带,低山丘陵区的坡度较缓、起伏不大。亚热带湿润季风气候,常年平均气温17.68 ℃,常年降水量1162.7 mm,常年平均无霜期360 d。研究区土类包括水稻土、紫色土、潮土、黄壤和石灰土,其中水稻土占总耕地面积61.69 %,紫色土占总耕地面积35.05 %,潮土占总耕地面积0.25 %,黄壤和石灰土占总耕地面积3.02 %[20]。研究区成土母质包括二叠系和三叠系灰岩,三叠系须家河组砂岩,下侏罗统自流井组粉砂岩,中侏罗统沙溪庙组粉砂岩和上侏罗统遂宁组砂泥岩(图2)。
1.2 数据获取
1.2.1 土壤有机质数据获取 土壤有机质样点数据从长寿区测土配方施肥项目中获取,共有5162个样本点,采样时间集中在2009年,采样深度为20 cm,采样点空间分布情况如图1所示。采集土壤样本的同时,记录采样点经纬度、高程、土壤类型、地形部位等信息。采样点土壤类型包括:紫色土(50.4 %)、水稻土(45.4 %)、黄壤(2.6 %)、潮土(1.3 %)、石灰土(0.3 %)。土壤样品带回实验室后在室内自然风干,过筛后采用重铬酸钾测法测定土壤有机质含量。
1.2.2 环境变量数据获取 土壤有机质的空间分布受到地形、气候、植被和成土母质等因素的影响,本文选取9个环境变量:高程(Elevation,ELE)、相对坡度位置(Relative Slope Position,RSP)、沟谷深度(Valley Depth,VD)、地形湿度指数(Topographic Wetness Index,TWI)、垂直到沟谷距离(Vertical Distance to Channel Network,VDCN))、归一化植被指数(Normalized Difference Vegetation Index,NDVI)、年均温(Annual Average Temperature,ANTP)、年降水量(Annual Precipitation,ANPR)和成土母质(Strata,ST)。
(1)数字高程模型(DEM)数据来源于中国科学院计算机网络信息中心地理空间数据云平台(http://www.gscloud.cn),空间分辨率为30 m。DEM数据通过SAGA GIS v.6.4提取4个地形因子:相对坡度位置(RSP),沟谷深度(VD),地形湿度指数(TWI)和垂直到沟谷距离(VDCN)。
(2)归一化植被指数(NDVI)数据从http://ladsweb.nascom.nasa.gov下载获得,空间分辨率为250 m。下载的遥感影像经过大气校正、辐射校正和几何校正,通过Savitzky-Golay滤波去除时间序列中的噪声,并通过最邻近法重采样获得分辨率30 m的NDVI数据。
(3)年均温(ANTP)和年降水量(ANPR)数据来源于世界气象数据库(http://www.worldclim),空间分辨率为1000 m。
(4)成土母质(ST)数据来源于全国第二次土壤普查,比例尺为1∶50 000。
1.3 预测模型
1.3.1 分类与回归树 分类与回归树(Classification and Regression Tree,CART)是一种监督分类方法,它假设决策树为二叉树,利用训练样本来构造二叉树并进行决策分类。CART可以用于分类或连续变量预测,可以处理非线性、非正态分布的数据,包容数据的缺失和错误,具有结构清楚、计算简单和适用性广等优点[21]。构造CART树分为树生长和树剪枝两个步骤:首先基于总样本生成一个多层次、多叶节点的决策树,当所有叶节点中的样本数为1或决策树高度到达用户设置的阈值时停止建树,生成的决策树足够大,能充分反映数据之间的联系;然后对决策树进行剪枝,从产生的一系列子树中选择适当大小的树,对未知数据进行准确预测[22-23]。
1.3.2 随机森林 随机森林(Random Forest,RF)是由多个决策树形成的组合预测模型,是CART模型的扩展。RF克服了CART模型过度拟合的问题,能够估计影响变量的重要性[24],但对样本数据集的大小较为敏感。RF的计算步骤为:从总样本中有放回的随机选出N个样本构建回归树,不进行剪枝操作,余下的样本作为袋外数据,袋外数据用来评价模型性能和自变量的重要性,通过投票或取平均值的方法,得到回归树最终预测结果。RF方法中的两个重要参数是树的数量和每个非叶子节点上可供选择的变量数。
1.3.3 随机森林残差克里格 随机森林残差克里格(Random Forest with Residual Kriging,RFRK)是一种结合了RF与OK的混合地统计方法,它考虑了变量间的非线性关系及目标变量的空间自相关性,提高了预测精度。通过RF算法得到的预测值与观测值之间存在残差,如果这些残差存在空间自相关性,可以将残差当作随机变量,通过克里格提高对未知点的预测精度。RFRK的计算步骤为:首先使用RF得到研究区有机质的预测值,计算RF预测残差,然后对预测残差进行OK插值,最后将RF预测值和OK插值误差相加得到预测结果。
1.3.4 普通克里格 普通克里格(Ordinary Kriging,OK)是一种随机性局部插值法,用已知点的样本估计未知点的值,考虑变量的随机性。OK着重于空间自相关因素,用拟合的半变异直接进行插值,通用方程式为:
(1)
式中,z为未知点的估计值,zx为x点的已知值,wx为x点的权重,n为用于估算的已知点数。权重不仅与估算点和已知点之间的半变异有关,还与已知点之间的半变异有关。
1.4 预测模型精度评价
根据模型构建的原则和相关研究,随机选取总样点的80 %作为训练集,余下20 %作为验证集,训练集用于构建预测模型,验证集用于评估模型的预测精度。统计指标包括平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和决定系数(Coefficient of Determination,R2),当MAE和RMSE值越小、R2值越接近1时,模型精度越高。使用多个统计指标很难对预测模型精度进行排序,因此,本文使用能够代表所有选定统计指标(MAE,RMSE,R2)的整体评价指标(Global Performance Indicator,GPI)对模型精度进行排序,结果显示GPI值越大,预测模型总体效果越好[25-26]。计算公式分别为:
(2)
(3)
(4)
(5)
2 结果与分析
2.1 土壤有机质含量描述性统计
土壤有机质含量的描述性统计列于表1,可见总样本均值为17.46 g·kg-1,取值范围为5.10~78.80 g·kg-1,土壤有机质含量整体上属于中等水平。土壤有机质含量的变异系数为33.73 %,属于中等变异程度,表明研究区内土壤有机质具有一定的变异性,适合空间局部估计[27]。
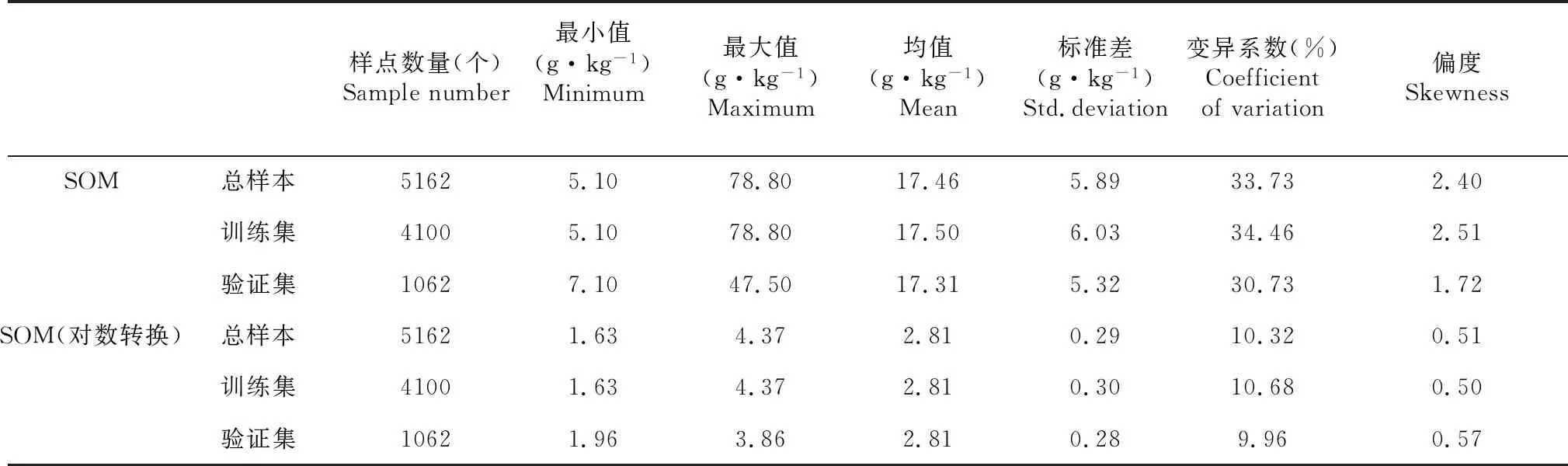
表1 研究区采样点土壤有机质含量描述性统计Table 1 Descriptive statistics of soil organic matter content in the study area
从5162个总样本点中随机选取4100个样本点构建预测模型,剩余1062个样本点用于评价不同预测模型的精度。普通克里格法要求输入数据呈正态分布,但研究区土壤有机质含量的偏度大于1,不符合正态分布,因此对研究区SOM数据进行对数转换,数据经转换后符合要求。
2.2 土壤有机质含量与环境变量的相关性分析
2.2.1 土壤有机质含量与气候、地形和植被的相关性分析 土壤有机质含量与年均温(ANTP)、归一化植被指数(NDVI)、相对坡度位置(RSP)、年降水量(ANPR)和垂直到沟谷距离(VDCN)呈极显著负相关,相关系数分别为-0.25、-0.13、-0.10、-0.06、-0.06。土壤有机质含量与高程(ELE)、沟谷深度(VD)、地形湿度指数(TWI)呈极显著正相关,相关系数分别为0.18、0.18、0.11。
通过SOM与ELE、VD、TWI、RSP、NDVI、ANTP、ANPR和VDCN的相关性分析,证实所选的环境变量对研究区SOM有显著影响,应参与CART、RF和RFRK的模型构建(表2)。

表2 土壤有机质含量与环境变量的相关性Table 2 Pearson’s correlations between soil organic matter content and environmental variable
2.2.2 成土母质对土壤有机质含量的影响 土壤有机质含量在不同成土母质中存在显著差异(P<0.05),二叠系和三叠系灰岩发育的土壤有机质含量最高,为27.34 g·kg-1,而下侏罗统自流井组粉砂岩发育的土壤有机质含量最低,为15.17 g·kg-1。说明成土母质对土壤有机质含量的空间分布有显著影响,应参与CART、RF和RFRK的模型构建,这与Guo等学者的研究结果一致[28](表3)。

表3 成土母质对土壤有机质含量的影响Table 3 The influence of strata on soil organic matter content
2.3 土壤有机质含量的半方差分析
通过半方差分析可以得到变量的空间自相关性和最优拟合模型,用于OK预测模型构建。研究中除了土壤有机质直接使用OK预测模型进行插值外,在RFRK预测模型插值过程中也用到OK预测模型,因此SOM(对数转换)和RF预测残差都需要进行半方差分析。
采用GS+软件计算半方差,结果(表4)表明,SOM(对数转换)和RF预测残差的最优拟合模型为指数模型,块金效应分别为12 %和9 %。块金效应表示空间相关性强弱,如果块金效应小于25 %,表示强空间自相关性,说明变量具有很好的空间结构性[29-30],研究中的块金效应均小于25 %,属于强空间自相关性,空间变异主要受结构性因素(例如成土母质、地形和气候)的影响。
OK预测模型着重考虑空间自相关因素,用拟合的半变异模型直接进行插值,研究中的SOM(对数转换)和RF预测残差属于强空间自相关性,满足OK预测模型的使用要求,有条件取到较好的插值结果。
2.4 土壤有机质含量预测模型构建及模型精度
构建CART、RF预测模型时,通过网格搜索与交叉验证确定预测模型的最优参数组,最后确定CART预测模型中最小子节点、最小父节点和最大树深度分别为10、20、20,RF预测模型中树的数量和每个非叶子节点上可供选择的变量数量分别为500个和3个,CART、RF预测模型在MatLab软件中构建。OK预测模型在ArcGIS软件中构建,需要的拟合模型及参数通过半方差分析得到(表4)。基于RF预测模型得到变量的预测值,计算预测残差,然后对预测残差进行OK插值,最后将RF预测值和OK插值误差相加构建RFRK预测模型。

表4 土壤有机质含量的最优半方差函数模型及参数Table 4 The semi-variance model and parameters for soil organic matter content
不同预测模型的精度见表5和图3。CART、RF、RFRK、OK的GPI值分别为-2.25、-0.80、0、0.71,预测模型整体精度由低到高排序为CART 表5 不同土壤有机质含量预测模型精度Table 5 The accuracy of different prediction models on soil organic matter content 在使用不同预测模型绘制的空间分布图(图4)中,土壤有机质分布的总体趋势一致,土壤有机质含量整体上属于中等水平,高值主要集中在西部的明月山地区,而东部地区的有机质含量偏低,中部地区的有机质含量分布不均、高低错落。模型精度最低的CART预测模型绘制的空间分布图,出现边界明显的块状区域。OK预测模型与RF、RFRK预测模型相比,OK预测模型绘制的空间分布图更平滑,RF和RFRK预测模型绘制的空间分布图对局部细节刻画更精细。 本研究中的地统计学预测模型OK整体精度高于机器学习预测模型CART、RF 和RFRK。研究区样点密度较高、分布较均匀,半方差模型的随机性会随着采样间隔的减小而减小,变量的空间相关性增强,在半方差分析中研究区土壤有机质含量呈现强烈的空间自相关性,空间自相关性极大地提高了模型的性能[31],因此依赖于空间自相关性的OK预测模型精度高。Pouladi等[12]的研究结果同样表明对于采样密度较大的区域,克立格法可以不需要辅助变量而直接预测土壤有机质含量;而在观测点数量有限的地区,结合辅助因子的方法表现更好[32]。机器学习模型通过模拟环境变量与土壤有机质含量的非线性关系,预测未知位置的土壤有机质含量,在土壤属性受多种环境因素共同作用时,参与构建模型的指标越多,机器学习的预测能力可以得到越好的挖掘,而对于成土环境相对单一的区域,使用易于操作的地统计方法可以获得理想的制图效果[33]。谢恩泽等[19]在研究中提出:寻找与土壤有机质含量相关性强的、容易获取且廉价的辅助因子具有一定挑战性,这增加了机器学习预测模型的复杂性。分析表明采样密度、空间自相关性和环境变量对研究结果有影响,所以当研究区已有土壤数据库,且数据库中土壤采样点密度较高、分布较均匀,同时研究区位于坡度较缓、起伏不大的低山丘陵区,可以考虑采用操作简单的OK预测模型绘制土壤有机质含量空间分布图,有效降低工作量和工作难度。 机器学习预测模型整体精度由低到高排序为CART 通过对比分析4种不同预测模型绘制的空间分布图,发现不同预测模型的土壤有机质空间分布总体趋势一致,但局部细节存在差异,这与姜赛平等[35]研究结果一致。RF和RFRK预测模型绘制的空间分布图不是光滑的连续曲面,而且CART预测模型绘制的空间分布图出现边界明显的块状区域,这是因为在采用回归树方法绘制的土壤有机质空间分布图过程中,每一个节点处土壤有机质含量值都是不连续的,因此导致生成的土壤有机质空间分布图不是一个平滑的连续面,并且在节点较少的情况下,会导致与现实不符的土壤突变现象[36]。克里格插值是基于已知的空间数据对未知空间数据进行估算,利用拟合模型将离散数据插值为连续的曲面数据,因此OK预测模型比机器学习模型绘制的空间分布图更平滑。 在不同预测模型绘制的空间分布图中,土壤有机质分布的总体趋势一致,高值主要集中在西部的明月山地区,而东部地区的有机质含量偏低,中部地区的有机质含量分布不均、高低错落。不同空间分布图在局部细节中存在差异,RF和RFRK预测模型绘制的分布图对局部细节刻画更精细,OK预测模型绘制的空间分布图更平滑。 预测模型整体精度由低到高排序为CART
2.5 使用不同预测模型绘制空间分布图
3 讨 论
4 结 论
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14网络安全与数据管理(2022年3期)2022-05-23疯狂英语·读写版(2022年3期)2022-03-31中国火炬(2021年9期)2021-09-22北京航空航天大学学报(2020年10期)2020-11-14北京航空航天大学学报(2019年9期)2019-10-26风流一代·经典文摘(2019年12期)2019-09-10读者(2018年24期)2018-12-04瞭望东方周刊(2017年36期)2017-09-28知识窗(2017年3期)2017-03-09
