
一种高性能计算集群登录节点资源限制方法
2021-05-29 11:56池成悦韦建文周子豪
实验室研究与探索 2021年4期
唐 金,池成悦,韦建文,周子豪
(上海交通大学网络信息中心,上海 200240)
0 引言
近年来,随着高等教育经费投入的增加以及计算资源需求的不断增长,国内外很多高校和科研机构纷纷建设了高性能计算集群[1-3]。上海交通大学于2013年建成并投入使用高性能计算集群。经过多年的发展,目前集群算力已达到2.1PFLOPS,科研用户数逐渐增多,日均服务机时直线上升,科研成果不断创新高[4-7]。
集群和用户规模的不断扩大增加了集群登录节点的负载以及管理上的难度[8]。集群登录节点属于共享资源,允许用户进行一些简单不耗资源的操作。但是,不同用户对集群的使用操作以及相关规章制度的了解存在着一定的差异。有些用户由于刚刚接触高性能计算,对集群认知比较有限,经常会直接在登录节点运行耗费资源的任务,导致登录节点长时间负载过高[9]。随着高性能计算集群的用户数量逐渐增加,对集群自动化需求越来越高。因此上海交通大学高性能计算集群急需一种自动、实时的监测技术来调节登录节点资源使用[10]。
国外几个HPC中心曾尝试使用cgroup 对共享资源进行限制。由印第安纳大学编写的“cgroup_py”脚本,可以起到限制用户资源的作用,但该脚本与CentOS 7 系统或基于Systemd 的系统不兼容;由美国普渡大学Maves和John 编写的“cgroups_py”脚本,可以对给定用户的Systemd user-$ UID.slice 资源进行限制,该方法基于简单的阈值法,只能起到静态的限制作用,可扩展性不强。犹他大学Dylan、Robben 等在基于Cgroups和Systemd理论基础上,提出了一种可以对共享资源进行监测的方法Arbiter2,该方法不仅可以监视用户CPU和内存使用率,还可以强制执行默认资源限制、惩罚消耗共享资源过多的用户。
本文结合上海交通大学高性能计算集群的实际运行情况,在基于Arbiter2 的实现原理上,从资源和时间两个维度限制超出阈值的用户,并设计了多层惩罚机制,动态调整用户可用资源。实际应用结果表明,登录节点上用户违规次数大幅降低,资源利用率始终处于正常水平。
1 关键技术及实现原理
1.1 关键技术Cgroups和Systemd
Cgroups 全称是Control Groups,早在2006 年由Google工程师(主要是Paul Menage 和Rohit Seth)发起,并于2007 年嵌入在linux内核中,成为一种可以限制、记录任务组所使用的物理资源的机制,如限制CPU、内存、I/O 等资源的使用。Cgroups 将系统中的进程(任务)进行分组化管理,每组进程为一个控制族群(control group)。控制族群以层级(hierarchy)的形式组织成一颗控制族群树,子族群继承父族群的特性。对CPU、内存等资源进行控制的子系统称之为资源控制器,必须要附加到某个层级上才能起作用,从而对层级上的控制族群进行管理[11]。
Systemd通过提供内在机制、默认设置和相关的操作命令,降低了Cgroups的使用难度,提供了一种便捷的方式。在系统的初始化阶段,Systemd会把资源控制器即子系挂载到默认的/sys/fs/cgroup/目录下面,并自动创建进程组(slice)、外部进程(scope)和系统服务(service unit)来为Cgroups 树提供统一的层级结构。在层级顶端Systemd 会自动创建4 个slice(-.slice,system.slice,user.slice,machine.slice)来监测并限制用户行为,在用户登录时自动创建,在会话结束后自动销毁。默认情况下,内存和CPU 的控制器都未启用,可以通过systemctl set-property user-# UID.slice 来启用,并设置:slice CPU Accounting=true,Memory Accounting=true[12]。
1.2 实现原理
(1)监测资源使用率。为了收集登录节点用户资源使用信息,需要从Cgroups 层次结构/sys/fs/cgroup中提取用户CPU 和内存的使用率。当用户登录集群时,会在每个用户的控制器下创建一个slice 文件,用于记录用户资源使用信息,CPU 控制器下的slice 位于/sys/fs/cgroup/cpu/user.slice/user-#UID.slice,内存控制器的slice 位于在/sys/fs/cgroup/mem/user.slice/user-#UID.slice。cpu.usage_percpu 用于记录CPU 资源使用率,但是该使用率是指用户自建立cgroups以来的CPU使用率,可通过提取时钟频率的差异来表示当前CPU使用率。memory.usage_in_bytes 用于内存使用率,为了准确判断当前内存使用率,一般是多次测量取平均值[13-14]。

(2)不良评分。设置参数badness 用于计算每个用户的不良评分,最高分为100,最低分为0,根据不良评分大小来选择相应的惩罚措施。不良评分的计算公式:式中:ur是用户使用的资源;Qr是每位用户可使用的资源配额;Cr是设置的资源阈值。当用户使用的资源大于阈值,即ur≥Cr时,不良评分ΔBr会随着时间的增加而增加,当增加到某一值时,则启动惩罚措施;当用户使用的资源在阈值以下时,即ur<Cr时,不良评分ΔBr会逐渐减少,受到的限制也会逐步减少。α 和β为系数,通过调节这两个系数,可以调节badness 变化快慢。最终的结果是,用户可以在短暂时间内运行资源消耗超过其阈值的程序,而不会受到惩罚。但是,长时间超过限定的阈值时,不良评分会逐渐增大,当达到一定的数值后就会启动惩罚措施来限制用户可使用的资源。
(3)用户状态。状态包含用户所处的状态、特殊性质的状态(如白名单)以及属性状态组。每个用户在同一时间只能处于一种状态,称之为“当前状态”。用户的另一种状态是默认状态,该状态主要用于用户从处罚状态返回时,系统通过默认状态对用户限制资源。本文设计方法通过将用户的uid或gid与order变量中遇到的第一个状态进行匹配,来确定用户的默认状态,若与order变量中定义的任何状态都不匹配,则将用户组设置为默认状态组即fallback_status。
(4)资源限制。当用户的不良评分达到惩罚值时,就会启动相应的惩罚措施来限制用户可用资源。对CPU资源的限制是通过CPU层次结构中的cpu.cfs_quota_us 文件来限制,当用户使用超过阈值(cpu_badness_threshold)时,短时间内将会被限制使用资源。对用户内存资源的限制是通过内存层次结构中的memory.limit_in_bytes 文件,当用户使用量超过阈值(mem_badness_threshold)时,内核会首先尝试收回内存,若无法实现,则会清理掉Cgroups 中最大的任务[15]。
2 高性能计算集群上的实践过程
系统总体工作流程如图1 所示。用户登录集群后,系统首先判断用户的cpu.usage _ percpu 和memory.usage_in_bytes是否超过阈值,如果超过阈值,则根据用户违规严重程度采取惩罚措施,一段时间未违规,则相应降低惩罚,逐步回归正常状态。接下来将详细介绍用户身份和状态分类、CPU 和内存相关设置、惩罚级别分类。
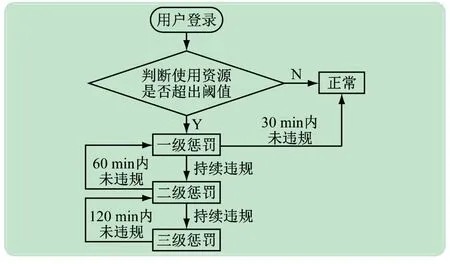
图1 系统总体工作流程示意图
首先,设置用户身份和状态。将用户设置为管理员用户和普通用户两种身份,管理员用户加入白名单,可以任意使用登录节点资源,不受限制。管理员名单目前只设置两位,更多的账号是普通用户。将用户状态设置为正常状态和惩罚状态,正常状态即默认状态,用户在登录节点上可以使用的资源是默认值的百分百,并且允许短时间内高负载运行;当用户有违规行为时,则进入惩罚状态。
其次,分类设置系统资源。将正常用户可使用的资源设置为1 核CPU,4 GB内存,CPU阈值设置为cpu_badness_threshold=80%,内存阈值mem_badness_threshild=50%,time_to_max_bad=5 min,time_to_min_bad=30 min,即当用户使用CPU超过80%或者内存使用量超过50%,且持续时间超过5 min,则不良评分开始增加,当用户的CPU和内存使用率持续30 min均在阈值以下,不良评分则会逐步减少。以内存使用率为例,随机统计了某位用户一段时间内资源使用率与不良评分的变化,如图2 所示。
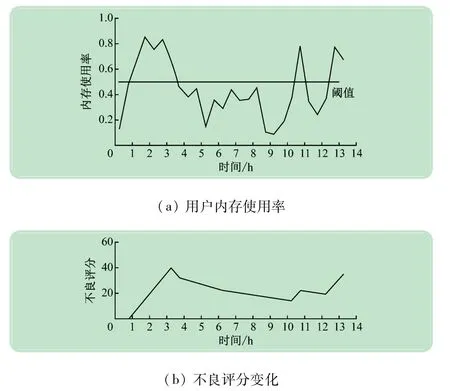
图2 登录节点上用户资源使用率与不良评分变化
最后,设置惩罚措施。对于违规用户,采取3 层惩罚机制动态限制用户可用资源。不同级别的惩罚措施对应的资源可用率和资源限制时间不同,如表1 所示。

表1 用户状态与其对应的资源限制
3 结果分析
上海交通大学高性能计算集群登录节点有3 台主机,操作系统均是CentOS 7.7,且操作系统带有cgroups v1 的Systemd版本,依赖的软件主要有Python 3、toml和matplotlib。研究人员在T2、T3 两台登录节点主机上进行了软件部署和相关参数设置,T1 主机上保持原有状态。
经过6 个月的试运行,登录节点的T2、T3 主机资源平均使用率显著下降,因用户不合理行为导致节点挂机的情况减少至零。随机统计了一段时间内3 台登录节点资源使用率,如图3 所示,T2、T3 主机上的内存和CPU资源使用率始终在50%以下,T1 主机上的内存和CPU资源使用率较高,平均在80%左右。
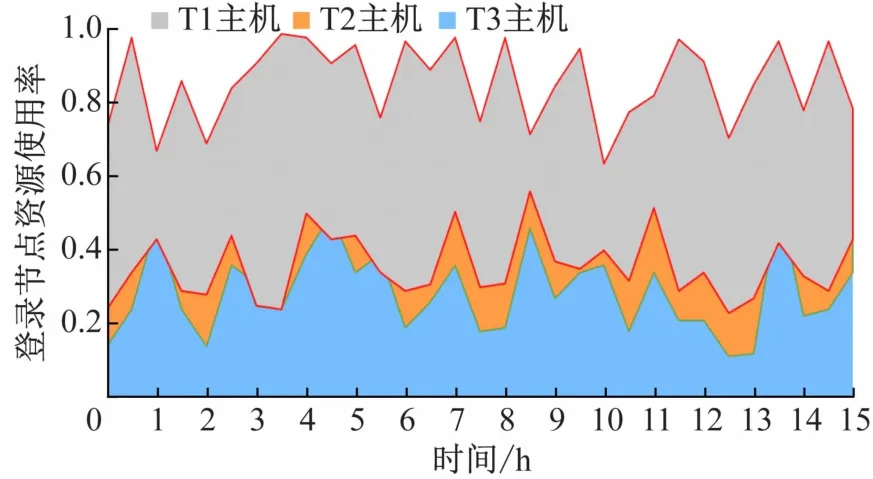
图3 登录节点上用户可用资源限制前后使用率对比
4 结语
本文分析了登录节点的意义及重要性,讨论了上海交通大学高性能计算集群登录节点存在的问题。针对登录节点负载过高的情况,在研究了其他HPC机构的管理方式后,提出了一种基于Cgroups 控制组策略的可以动态限制资源的方法。实际应用结果表明,CPU和内存使用率始终处于正常水平,登录节点的稳定性和可靠性得到了提高。同时,本文提出的方法对其他机构高性能计算集群的登录节点管理也有一定的参考价值。
猜你喜欢
网络安全和信息化(2020年11期)2020-11-13
小读者(2020年2期)2020-03-12
阅读(快乐英语高年级)(2019年11期)2019-09-10
综艺报(2019年5期)2019-03-18
趣味(语文)(2018年1期)2018-05-25
电子制作(2017年19期)2017-02-02
山东工业技术(2016年15期)2016-12-01
汽车文摘(2015年11期)2015-12-14
学苑创造·A版(2015年6期)2015-07-01
汽车维护与修理(2015年1期)2015-02-28
