
塔河油田碳酸盐岩缝洞型油藏单储系数概率分布模型
2021-06-02 10:24吕海涛虎北辰郑见超
油气地质与采收率 2021年3期
李 斌,吕海涛,耿 峰,虎北辰,郑见超,梁 宇
(1.西南石油大学地球科学与技术学院,四川成都 610500;2.西南石油大学油气藏地质及开发工程国家重点实验室,四川成都 610500;3.中国石化西北油田分公司勘探开发研究院,新疆乌鲁木齐 830011;4.中国矿业大学地球科学与测绘工程学院,北京 100083)
塔河油田奥陶系油藏是中国目前发现的最大规模的碳酸盐岩缝洞型油藏,储层非均质性强,油藏资源量计算参数取值不确定因素多[1-4]。在油田勘探和开发初期阶段,主要采用静态容积法计算地质储量,储量计算结果与后期油田开发认识偏差较大[5-9]。塔河油田开发实践显示,碳酸盐岩缝洞型油藏储集体是多期岩溶改造作用的结果,储集空间主要有溶洞、孔洞、裂缝等,由这些特征明显不同的储集空间组合形成的洞穴型、裂缝-孔洞型和裂缝型储集体在三维空间分布的边界形态极不规则[10-13],简单地套用碎屑岩油藏的储量计算参数方法来确定该类油藏的储量存在明显的不适应[8,12,14-15],而目前中外还没有针对该类型油藏的成熟储量计算方法[16-19]。不同勘探区以及不同岩溶作用条件下,断裂发育情况以及原油性质存在明显差异。通过统计523 口井碳酸盐岩缝洞型油藏储量计算参数,采用概率法分析储量计算的单储系数概率取值方法,并探索建立重点区带和不同地质类型及影响因素的单储系数取值依据,以期为缝洞型油藏单储系数准确计算提供依据。
1 单储系数概率模型的建立
单储系数又称储量密集度,是指含油面积为1 km2,厚度为1 m 的油层中所充填的地面原油的万吨数[20]。单储系数是单位体积内的油气储量,受储层发育程度、油气聚集程度和流体性质影响较大[21-22]。目前,单储系数计算方法有直接法、类比法和经验法,采用概率法开展单储系数研究较为少见[23-25]。
1.1 数学意义和地质意义检验
数学意义检验也称为参数模型数学假设检验方法,是以统计学中的拟合优度检验为基础。所谓拟合优度检验,是指统计学中用来检验来自总体中的一类数据,其分布是否与某种理论分布相一致的统计方法[20]。相对于基于样本统计直方图的粗略判断,利用拟合优度检验等数学假设的检验方法具有较为可靠的数学理论基础。将拟合优度检验应用到圈闭资源量参数的概率分布模型检验中,可以获得更加客观、准确和定量化的参数分布。统计学中的拟合优度检验方法有很多种,不同检验方法的检验侧重点各有不同,适用于不同的应用领域。本次数学意义检验主要采用卡方检验和K-S 检验两种方法,两者都是通过实际分布与理论分布的差异来判断是否近似于假设分布,不同之处在于卡方检验基于大样本条件,对样本分组频数进行检验,而K-S 检验则是针对每个样本值进行检验,没有样本数量的要求。K-S 检验不受样本数量的限制,直接针对原始的n个观测值进行检验,数据利用较为完整。
地质意义检验是利用圈闭资源量参数的地质含义,对参数模型的有效性进行评判的一类方法。端值检验法、类比检验法和P(10)/P(90)检验法是3种常用的地质意义检验手段。其中P(10)/P(90)检验法通常用P(10)与P(90)的比值来反映资源量参数或结果的不确定性。P(10)/P(90)值越高,不确定性越大。有效孔隙度、含油(气)饱和度等参数的P(10)/P(90)值一般应低于10,否则应考虑样本是来自不同的地质相或样本数量过少。不确定性较小的圈闭,其P(10)/P(90)值一般为2~5,预探井等风险较高的其P(10)/P(90)值可能会达25左右。
1.2 参数概率分布模型检测
在明确数学意义检验和地质意义检验判断标准的基础上,建立数学模型拟合的具体流程和标准(图1),采用K-S 检验和卡方检验两种数学检验方法,结合端值检验、P(10)/P(90)检验两种地质检验手段,确定单储系数概率模型。圈闭资源量计算中常用的概率分布模型包括正态分布、对数正态分布、Beta分布和三角分布等[20]。
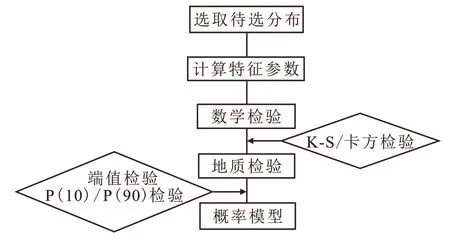
图1 概率法数学模型拟合流程Fig.1 Flow chart of mathematical model fitting by probability method
以艾丁北地区为例,进行单储系数数学模型拟合和结果分析。艾丁北地区位于沙雅隆起阿克库勒凸起西北斜坡带上,处于桑塔木尖灭线以北,断裂规模较小,以逆断裂为主,奥陶系储层非均质性较强,局部含油连片。开发井为130口,其孔洞型储层有效孔隙度为2%~14%,裂缝型储层有效孔隙度为0.01%~0.5%,孔洞型储层含油饱和度为59%~77%,原油密度为0.95~1.05 g/cm3,为重质油和超重质油。
首先对样本进行数据分组统计,根据本区油藏单储系数Pmean 小于1×104t/(km2·m)的特点,本次待选分布定位为正态分布、对数正态分布和Beta 分布;然后对上述分布模型进行K-S检验,从表1可以看出,单储系数小于正态检测和对数正态检测渐进显著性均大于0.05×104t/(km2·m),表明不具有正态分布特征,而Beta 分布的显著性水平小于0.05×104t/(km2·m),符合度较高,从图2 也可以看出,艾丁北地区储层孔隙度和含油饱和度参数分布对称性差,呈偏正态分布。因此,可以利用偏正态的Beta 分布检测数据形态,得到Beta函数分布的特征参数值。
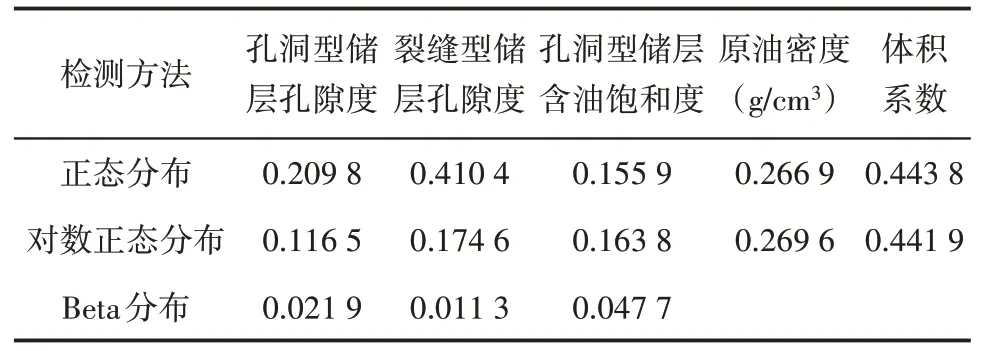
表1 艾丁北地区单储系数概率分布模型K-S检验结果Table1 K-S mathematical detection of probability distribution model of parameters regarding reserves per unit volume in northern Aiding area
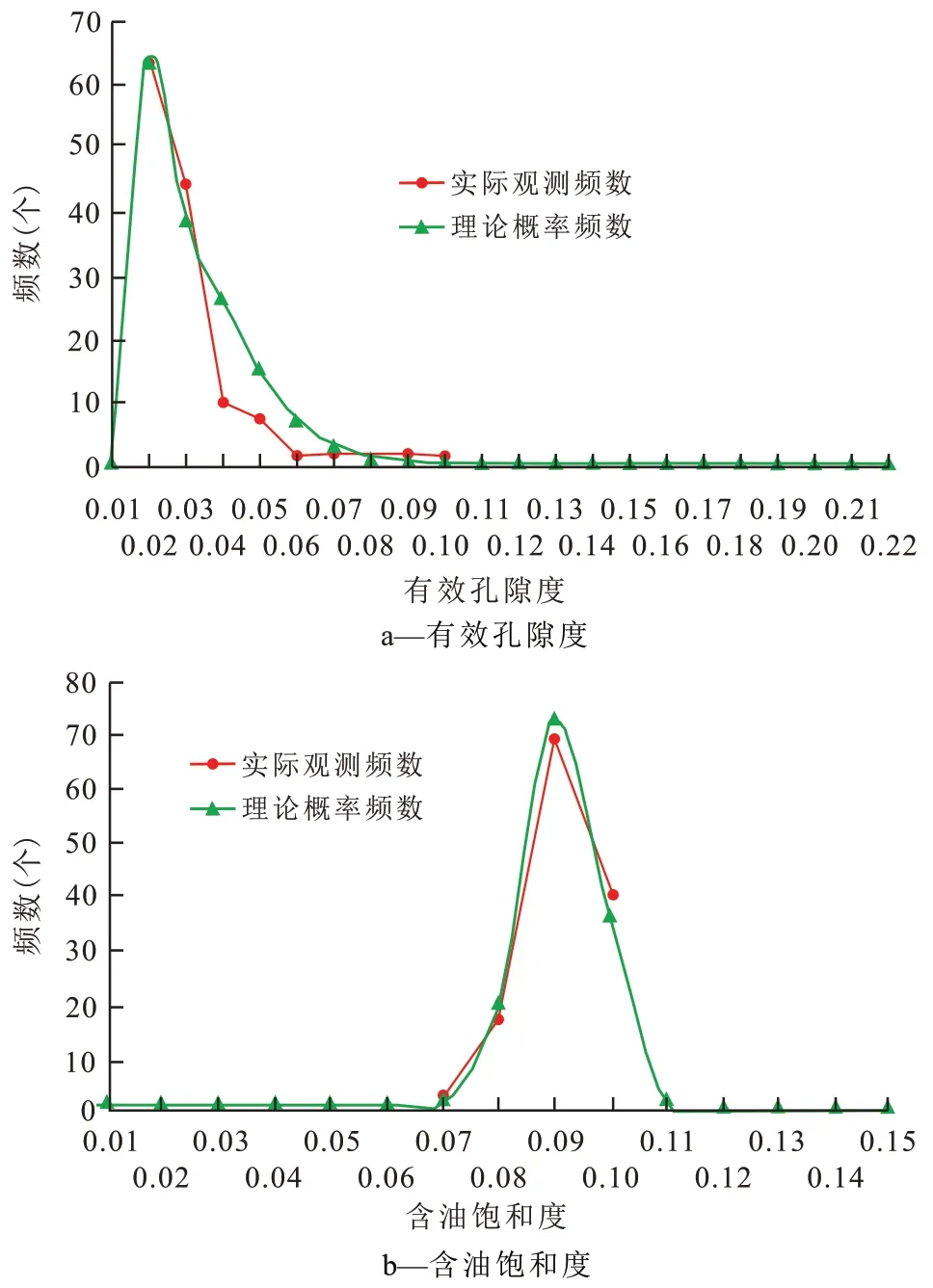
图2 艾丁北地区孔洞型储层实际观测频数与理论概率频数分布Fig.2 Beta distribution of actual observed frequency and theoretical frequency distribution of vuggy reservoirs in northern Aiding area
1.3 单储系数模板
运用蒙特卡洛计算方法[26-27],通过定义参数分布模型和输出结果,建立油藏参数的概率密度分布模型(图3),从有效孔隙度概率密度分布来看,有效孔隙度主要为0~0.1。从有效孔隙度逆累积概率密度分布来看,有效孔隙度为0~0.1 时,累积概率密度为0~1.0。从含油饱和度概率密度分布来看,含油饱和度主要为0.15~0.2。从含油饱和度逆累积概率密度分布来看,累积概率密度为0~1.0。从裂缝有效孔隙度概率密度分布来看,裂缝有效孔隙度为0~0.005。从裂缝有效孔隙度逆累积概率密度分布来看,累积概率密度为0~1.0。从原油密度概率密度分布来看,原油密度主要为0.949~1.055 g/cm3。从原油密度逆累积概率密度分布来看,累积概率密度主要为0~1.0。最后检验置信区间(一般大于95%),使其符合地质意义。为验证概率法计算单储系数的准确性[28-29],与样本值法计算的单储系数进行对比,从图4可见,概率法受参数分布模型约束,均值变化大、端值变化小,概率参数Pmean,P(10)和P(90)值较为接近,单储系数结果相对稳定保守。
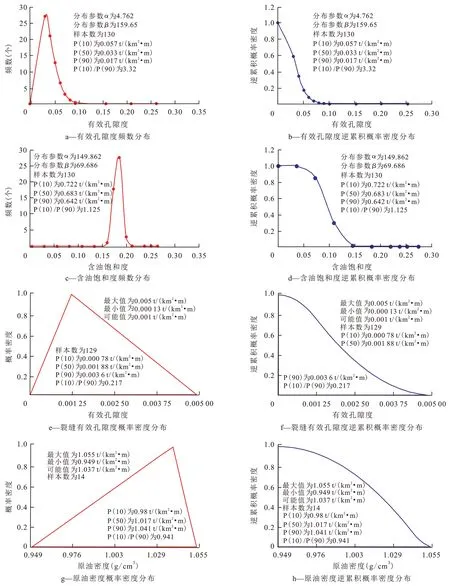
图3 艾丁北地区孔洞型储层油藏参数概率密度分布模型Fig.3 Probability distribution model of reservoir parameters for vuggy reservoirs in northern Aiding area

图4 艾丁北地区孔洞型储层概率法和样本值法单储系数分布模型Fig.4 Distribution of reserves per unit volume based on probability method and sample values for vuggy reservoirs in northern Aiding area
2 不同区块单储系数分布特征
按照上述方法,对塔河油田及相关区块开展缝洞型油藏单储系数建模研究,首先统计不同刻度区样本数据,建立参数分布模型,然后采用概率法建立孔洞型和裂缝型油藏单储系数的模型,读取模型的概率参数P(10),P(50),P(90),Pmean 值。从评价区概率法和样本值法单储系数对比(图5)可以看出,概率法单储系数波动小,较为可靠。艾丁北、于奇和玉北地区孔洞型油藏概率法计算的单储系数Pmean 值大于2×104t/(km2·m),艾丁北、主体区和盐下地区裂缝型油藏概率法计算的单储系数Pmean值为0.16×104~0.19×104t/(km2·m)。
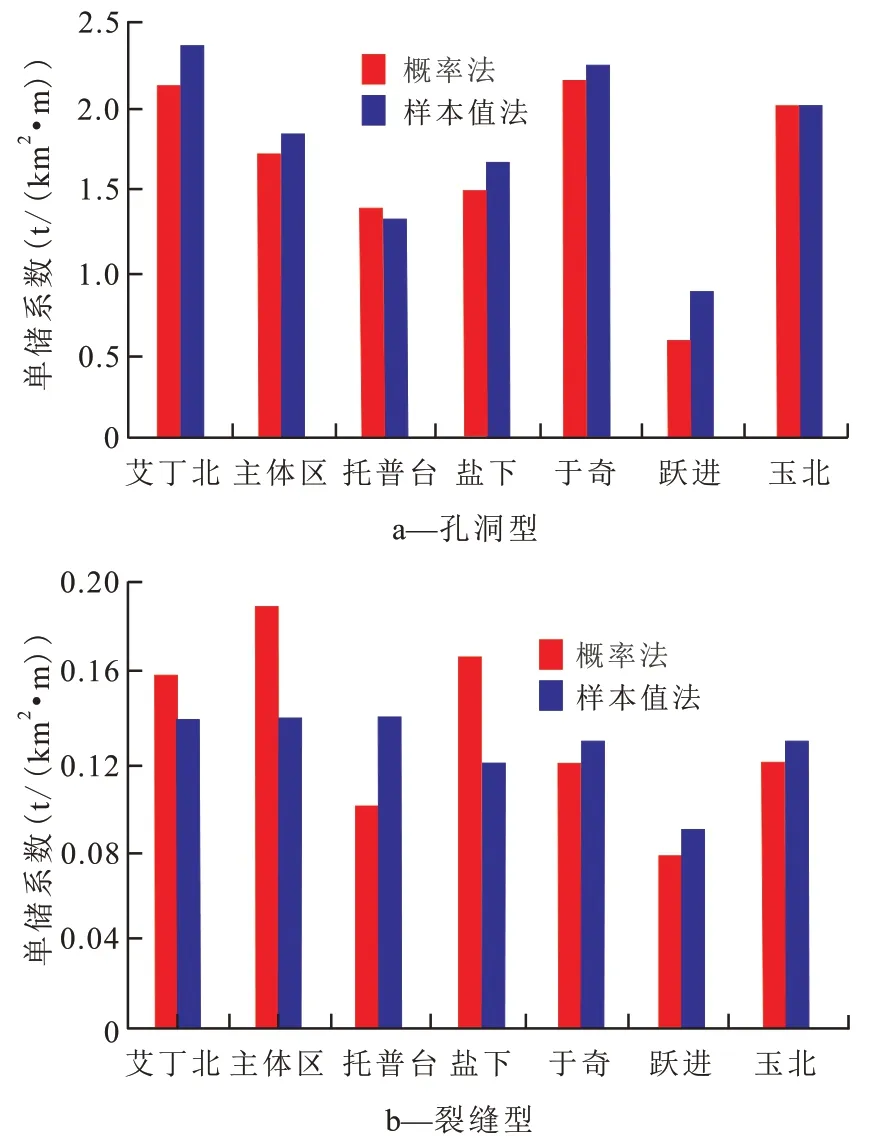
图5 评价区孔洞型和裂缝型油藏单储系数直方图Fig.5 Histogram of reserves per unit volume in vuggy and fractured reservoirs of area under evaluation
3 油藏单储系数影响因素
3.1 地质背景
为研究油藏发育的地质背景对缝洞型油藏单储系数的影响[30-32],参考现场地质研究成果将塔河地区及顺北地区奥陶系油藏170个样本划分为受风化壳控制(AD16—AD8)、尖灭线附近(S72)、断裂控制(TP29-TP19X)以及断溶体控制(顺北)4 种不同地质背景,分别求取概率法、样本值法和容积法单储系数,受断溶体控制的洞穴型储层单储系数最高,概率法计算的单储系数Pmean 值达10.7×104t/(km2·m),受风化壳控制的孔洞型和裂缝型储层单储系数较高,尖灭线附近储集体次之。从单储系数计算方法可以看出(图6),概率法计算结果与样本值法的计算结果差距较小,容积法计算结果略高。
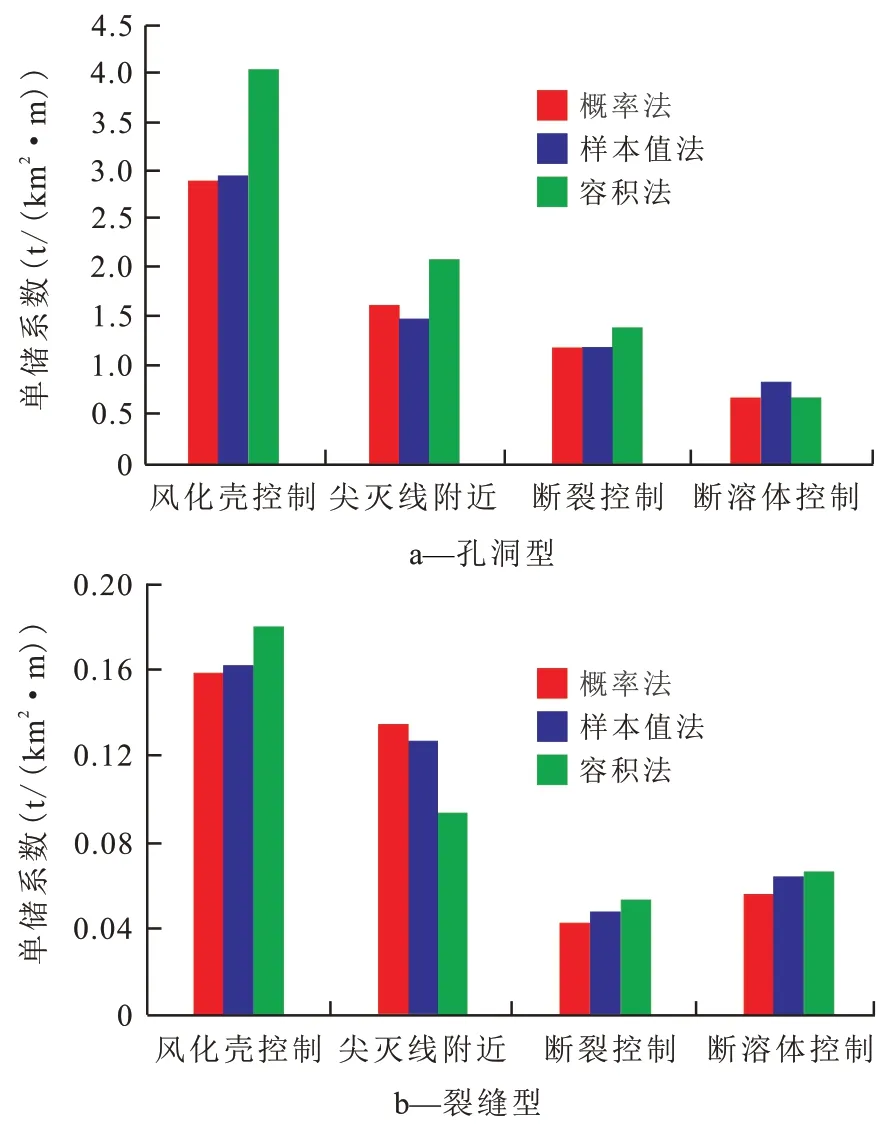
图6 不同地质背景下孔洞型和裂缝型储层单储系数对比Fig.6 Comparison between reserves per unit volume in vuggy and fractured reservoirs against different geological backgrounds
3.2 原油密度
为研究不同原油密度对油藏单储系数的影响,将塔河地区及顺北跃进地区奥陶系523个原油样本划分为超重质油、重质油、中质油、轻质油和挥发油类型,开展单储系数研究,建立单储系数分布模板10 个(图7)。超重质油概率法计算的单储系数Pmean 值大于2×104t/(km2·m);超重质油与重质油概率法计算的Pmean 值为0.1×104~0.16×104t/(km2·m)。超重质油和重质油孔洞型储层单储系数较高,大于2×104t/(km2·m);超重质油和重质油裂缝型储层单储系数较高,大于0.1×104t/(km2·m);原油密度对单储系数影响较大,与单储系数呈一定相关性。
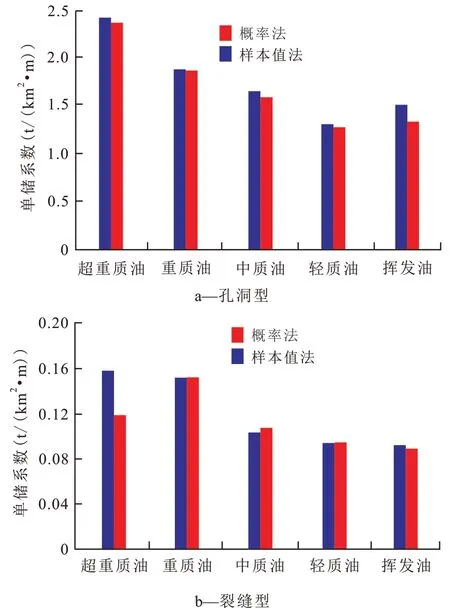
图7 不同原油性质下孔洞型和裂缝型储层单储系数对比Fig.7 Comparison between reserves per unit volume in vuggy and fractured reservoirs with different crude oil properties
3.3 勘探进度
为分析勘探进度对单储系数的影响,以托普台地区为例,将该区158 个样本点分别按1/4,1/2 数据比例随机抽取数据建立不同的单储系数概率模板,分别代表勘探早期、中期和现今阶段的勘探现状,并读取单储系数(表2)。从表2可以大致看出,概率法计算的Pmean值略低于样本值法计算结果。

表2 托普台地区样本值法和概率法计算的单储系数结果对比Table2 Comparison between reserves per unit volume based on sample values and probability method in Tuoputai area
不同勘探阶段的单储系数对比表明,原始数据受异常值影响,波动较大,平均值高于概率法计算的Pmean 值。在流体性质和储层类型相似情况下,样本值法跟概率法单储系数较为接近,略呈正相关,表明随着勘探进展,资源量计算结果会呈现增加的趋势,建议在概率法参数统计中应尽可能多增加样本点数。
4 结论
在单储系数概率模型选取上,Beta 分布适用性更强,表现也更为客观准确。对于裂缝孔隙度和原油密度参数,由于样本数量较少、集中度高、个别离散,则应使用模型相对简单、精度较差的三角分布作为待选分布。
缝洞型油藏单储系数概率法取值显示:孔洞型油藏单储系数为0.61×104~2.2×104t/(km2·m),均值为1.67×104t/(km2·m),裂缝型油藏单储系数为0.08×104~0.19×104t/(km2·m),均值为0.13×104t/(km2·m),其中艾丁北、于奇和玉北地区孔洞型油藏单储系数较高,概率法计算的Pmean 值高于2×104t/(km2·m);艾丁北、主体区和盐下地区裂缝型油藏单储系数较高,概率法计算的Pmean值高于0.16×104t/(km2·m)。缝洞型油藏超重质油和重质油孔洞型储层单储系数较高,平均大于2×104t/(km2·m),原油密度对单储系数影响较大,和单储系数呈一定相关性。
传统容积法计算的单储系数略高于概率法和样本值法。受断溶体控制的洞穴型储层单储系数最高,概率法计算的Pmean 值达10.7×104t/(km2·m),受风化壳控制的孔洞型和裂缝型储层单储系数较高,尖灭线附近储集体次之。
在流体性质和储层类型相似情况下,勘探进度与资源量计算参数呈现一定正相关性,建议在概率法参数统计中应尽可能多增加样本个数。
猜你喜欢
科海故事博览·上旬刊(2022年5期)2022-05-17
长江大学学报(自科版)(2022年2期)2022-03-21
非常规油气(2021年4期)2021-09-16
工业加热(2021年8期)2021-09-11
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
新传奇(2018年16期)2018-05-14
