
中小河流洪水预报智能调度平台关键技术
2021-06-09 07:31万定生朱跃龙朱海南朱青松
河海大学学报(自然科学版) 2021年3期
万定生,王 坤,朱跃龙,姚 成,朱海南,朱青松
(1.河海大学计算机与信息学院,江苏 南京 210098; 2.河海大学水文与水资源学院,江苏 南京 210098)
我国河流众多,气候类型较为复杂,由于受台风、暴雨等恶劣天气的影响,发生在中小流域的洪水越发频繁。中小流域降雨具有雨量大且集中、洪水起伏较大的特点[1],目前国家对于大江大河的洪水治理已具备经验,而对于中小流域的洪水治理经验相对缺乏。中小河流洪水防控与应急管理要求实现准确预报、及时预警、科学调度和有效处置[2],水文预报是防洪减灾的重要非工程措施,开展中小河流洪水预警预报平台的建设,将有效提高中小河流的洪水预报水平与防洪减灾能力。
洪水预警预报平台始于20世纪70年代,美国、意大利等发达国家先后建立了洪水预报系统,如美国3S洪水预警系统、意大利DAMSAFE决策支持系统和欧盟洪水预报及报警响应系统等[3]。国内洪水预报软件研发起步较晚,得益于计算机技术迅速发展,大量的洪水预报系统应运而生,如三峡水库入库站洪水预报系统、黄河防洪调度决策支持系统和长江流域防洪调度系统等,初步构建了的防汛抗旱水文监测预报预警服务体系[4]。
长期以来,洪水预警预报平台多基于客户机/服务器(C/S)模式构建,随着洪水预报需求不断拓展以及水文模型研究[5-6]的迅速发展,此类系统在服务管理、安全性和模型通用性等方面存在明显不足[7]。随着Web2.0的兴起,浏览器/服务器(B/S)模式与微服务架构[8-9]的洪水预警预报智能平台在水文模型集成与共享、服务管理和平台安全性等方面有着明显的优势[10]。
洪水预警预报平台以大量水文数据为支撑。目前,中小河流水文数据资料的获取途径主要来源于全国各地水文站。这些数据必须具有准确性、有效性和代表性,因此,对中小河流水文数据质量控制,提高水文数据适合使用的程度,是水文数据应用于预报平台的关键。
在洪水预警预报过程中,准确预报及展示出洪水演进轨迹、影响范围,为水利部门提供决策支持成为亟须解决的问题。随着地理信息系统(GIS)和数字高程模型(DEM)技术的快速发展,如何利用这种计算机技术实现快速、准确地预测和模拟出洪水淹没情况,降低了防洪的成本,对于防洪减灾具有十分重要的意义。
针对中小流域水文数据特点进行质量控制,基于微服务架构进行水文模型集成与共享,开发洪水预警多重情景仿真技术,并将其应用在中小流域洪水预警平台,为相关工作提供决策支持。
1 平台结构设计
中小河流洪水预警预报智能调度平台基于“网格化-虚拟化-可视化”的设计理念,围绕数据传输、运行环境和功能业务等关键点,进行平台框架设计。
a. 数据网格化。对不同类型、不同格式的数据,建立了水文、气象和土壤等信息一张网的数据交换规范。在示范流域建立1 km×1 km网格平面,从而实现数据网格化处理,提高了数据读取、交换的效率,为平台架构提供数据支持。
b. 运行环境虚拟化。基于微服务构建的水文模型在Docker容器中运行。容器与虚拟机类似,是一个相对独立的运行环境。容器对其内部的水文模型服务及其关联性进行隔离,从而构建起一套能够随处运行的自容纳单元。相比于虚拟机,容器并不需要为每个应用分配单独的操作系统,因此其拥有更高的资源使用效率、更小的实例规模和更快的创建迁移速度。
c. 业务可视化。平台基于ArcGIS和Unreal Engine 4引擎,结合洪水淹没算法,对预报业务的结果进行二维和三维的展示,准确预报及展示洪水演进轨迹和影响范围,直观再现洪涝灾害的发生范围及程度。
平台基于上述平台框架,结合动态反射机制,设计高可配置和可扩展的3层云平台结构,集成水文气象数据、模型以及其他各功能模块以及预警预报和风险评估模型。平台整体结构如图1所示。

图1 平台整体结构Fig.1 Overall structure of platform
d. 平台整体架构。包括:基础资源层、支撑平台层和应用层。基础资源层作为IaaS层(Infrastructure as a Service)包括:水文部门实时监测气象数据、通过数据共享接入的气象数据、计算资源与网络资源;基础资源层为整个平台构建提供底层支持。支撑平台层作为PaaS层(Platform as a Service)包括数据质量控制模块与模型模块,数据质量控制模块对数据资源层提供的水文数据进行质量控制,包括对缺失数据进行预测插补以及异常数据检测,对处理好的数据向上提供数据统一服务接口;模型模块提供基于微服务的预报模型,包括精细化网格模型、智能预报模型等,并将上述模型进行整合,形成模型多层次按需服务,提高模型共享效率。应用层为SaaS层(Software as a Service),基于多情景仿真技术,提供面向洪水预报和风险分析的业务服务,包括基础数据查询、水雨情监视、数据分析、集成洪水预报、风险分析以及智能调度等。
2 平台关键技术
2.1 水文数据质量控制方法
通过对中小河流水文数据中主要质量问题的分析,中小河流水文数据质量控制主要分为:缺失数据插补、冗余数据检测与处理、异常数据检测等。本文主要分析对于中小河流水文数据缺失值插补方法与异常数据处理。针对缺失数据插补,提出从单向和多向2个方面对缺失数据进行预测插补;针对异常数据,提出若干异常点检测与异常模式检测方法。
2.1.1 水文数据插补方法
2.1.1.1 基于ARIMA与SVM组合预测单向插补模型
差分整合移动平均自回归模型(autoregressive integrated moving average model,ARIMA)[11]广泛应用于时间序列的分析与预测中。对于中小河流水文时间序列数据,如果缺失数据点前存在长度为N的完整序列,则可以利用这n个数据来对第n个数据以后的数据进行预测,构造单向插补模型。理论上利用ARIMA模型可以预测多个数据记录的缺失值。但是随着预测数值个数的增加,会造成预测精度下降。而且原始观测数据集中数值缺失情况不确定,因此设置固定宽度的滑动窗口,结合ARIMA模型(ARIMA model based on sliding window,SW_ARIMA)对水文时间序列进行预测。SW_ARIMA模型构建步骤如下:(a)获取观测数据集x(n),选取其中一段比较完整的数据序列x(k)作为预测模型输入数据集;(b)为了滑动窗口内的预测数据不随着时间的推移而增加,设置固定滑动窗口宽度等于预测数据x(k)的长度k。避免对数据集X(n)中的缺失值进行插补时造成遗漏,设置滑动窗口步长与预测值个数相等。假设预测值的个数l(l≥1)。为了保障精度,l取值不宜过大;(c)构建ARIMA预测模型,得到预测值;(d)更新x(k),滑动窗口前移一步,直到观测数据集X(n)处理完毕。图2表示起始数据状态;图3表示x(k)更新一次,滑动窗口前移动一步状态。
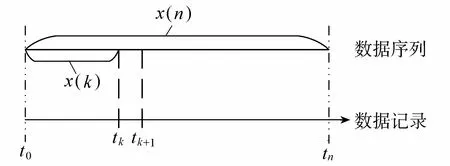
图2 起始数据状态Fig.2 Starting data state

图3 x(k)更新状态Fig.3 x(k)’s update status diagram
支持向量机(support vector machine,SVM)中的主要参数有惩罚系数c、核函数参数g以及不敏感损失函数参数q。其中惩罚系数c控制超出误差样本数据的惩罚程度,与核函数参数g一起决定了支持向量机的泛化能力。通过粒子群优化
算法(PSO)对SVM进行参数优化,并采用均方误差(MSE)最小作为最佳适应度。
对于SW_ARIMA与PSO_SVM这2种单一的预测模型,预测结果存在较大误差。本文将2种单一预测模型进行并联加权组合,减少模型的预测误差。组合预测模型结构如图4所示,试验结果见表1。

图4 组合模型结构Fig.4 Composite model structure

表1 基于SW_ARIMA与PSO_SVM模型预测结果
试验发现,在单一模型环境下,SW_ARIMA模型效果略好于PSO_SVM模型效果。而组合模型得到结果优于前两种单一模型。因此对于中小河流水文数据中的缺失情况,将组合模型预测值作为参考值,能够有效地减少插值误差。
2.1.1.2 基于Adaboost组合预测的多向插值模型
中小河流水位流量等水文数据,在一定的时间内具有时间序列的特征,即表现出一定的连续性和周期性。因此,对中小河流连续性缺失的数据,利用存在记录中的观测数据和历史相同时刻的观测数据对未来相同时刻缺失的数据进行预测,构造多向插补模型,将预测值当作参考值。
在Adaboost算法中,弱预测器是一种不稳定的预测模型或者是各种不同预测模型。其中循环神经网络(resurrent neural networks,RNNs)属于组合预测插值模型中的弱预测模型,因为每次训练会产生不同的网络权重。SVM相比神经网络有着更强的泛化能力,在相同的样本情况下训练结果更加稳定。选择单个SVM和多个RNNs作为Adaboost的弱预测因子,通过弱预测因子的加权组合弥补算法的不足。因为SVM最初主要用于分类,而应用于预测领域的支持向量机为支持向量回归(support vector regress,SVR) ,因此实际应用SVR,采用Adaboost组合算法,建立组合预测插值模型。图5表示对某一时刻的数据进行预测的模型示意图,其中Tyd表示第y年的d时刻。

图5 Tyd时刻组合预测插值模型Fig.5 Combination prediction interpolation model of Tyd time
2.1.2 水文数据异常检测方法
2.1.2.1 基于ReMess-iForest算法的异常点检测
基于孤立森林算法的检测模型[12]是两阶段构造过程,首先对森林中的子树iTree进行构造;其次将已构造的iTree组合成孤立森林,对预测数据进行异常分数的计算。iForest算法在检测包含多个正常点群的数据集时,局部异常点被密度相似的正常集群所掩盖,导致iForest算法对局部异常程度的判定不准确。
改进iForest算法—ReMess-iForest算法模型构建时,第一步iTree子树的构建,使用与iForest算法中完全相同的实现步骤,第二步计算异常分数时,使用基于相对质量的局部排名度量方法,计算数据x落入1棵子树的相对质量。

(1)
式中:Ti(x)——数据x落入子树Ti中的叶子节点;i(x)——Ti(x)的直接父节点;m(·)——树节点的数据质量即数值大小;ε——归一化项,用于生成子树后的训练数据大小,此处使用默认值256;si(·)——处于0~1之间,其值越大,越可能是异常。
对于一个训练数据x,令其遍历每一棵iTree,然后计算x最终落在每棵iTree,计算其相对质量大小,最后得出x在每棵iTree的平均相对质量大小:

(2)
因此使用iForest算法检测模型得到了适用当前测站的最优参数,使用ReMess-iForest算法检测模型有效解决iForest算法的局限性。
2.1.2.2 基于层次聚类的符号化水文时间序列异常模式检测
基于聚类的异常检测的步骤是:先对扩展符号聚集近似(extended symbolic aggregate approximation,ESAX)方法表示得到的特征向量进行聚类并得到所有类的聚类中心,再找到与待检测对象距离最近的聚类,如果其与聚类中心之间的距离没有超过阈值,则该对象是正常数据;如果其与聚类中心的距离超过了阈值,则被判断是异常数据[13]。基于聚类的异常检测方法中,目前常用的两阶段异常检测方法[14],该方法分为2个阶段:第一步阶段对时间序列进行聚类,将数据分为多个类,每个类中的对象都具有强烈的关联关系;第二阶段是找出待验证对象所属的聚类,再度量该对象与聚类中心的距离,并通过该距离来判断异常数据。
2.1.2.3 基于相似性度量的异常模式检测
从时间复杂度、理论优度和实用优度进行综合评估,基于关键点的分段压缩法(KPRA)效果较好[15]。原始时间序列通过关键点进行分割,得到的每一段子序列用分段线性(piecewise linear representation,PLR)进行模式表示[16-17]。对于水文时间序列中异常模式的检测,首先使用KPRA-PLR算法对水文时间序列进行降维处理,通过关键点对时间序列进行分割得到各个子序列,用线性表示方法得到元模式,相邻元模式两两之间组成序列模式t;其次使用STDW算法对序列模式进行相似性度量,计算实时水文数据得到的序列模式t和历史水文数据T上每个序列模式的相似性度量;序列模式t的异常分数为序列模式t与T上每个序列模式间的平均距离的倒数,使用k-近邻原理算出局部异常因子,Top-k最大的异常因子对应的序列模式即为异常模式。
2.2 水文模型多层次按需服务
水文模型作为水文过程成熟的模拟手段,一直是水文学研究的热点。水文模型在洪水预报中应用有着十分重要的作用。目前,水文数据及水文模型资料大多分散在不同机构和研究人员手中,缺乏水文模型的集成与共享平台将分散的资源进行整合,所以当前水文模型共享率并不高[18]。在开放网络环境下,模型服务化是当前实现模型封装与共享的主流方式[19]。
2.2.1 水文模型多层面服务化封装策略
为了满足未来水文模型动态配置的业务发展需求和实现水文模型资源的集成与共享的目标,水文模型服务化封装策略需要考虑以下内容:(a) 服务中数据描述格式需要统一,便于服务间的数据交互;(b) 水文模型需要进行多层面拆分,形成各自独立的服务,从而降低程序耦合,提高模型资源的复用率;(c) 各个独立的服务不对外暴露实现细节,只提供统一的对外调用接口。
结合栅格新安江模型[20]、经验模型等典型的水文模型进行分析,在模型实际研发过程中,模型的输入数据主要分为3种类型:数据库数据、文件数据和用户输入数据,并且水文模型在设计时通常会产生模块化的概念,每个模块的实现又包含了不同的数学算法或物理规律,如蒸散发能力计算、槽面降雨量计算、地表径流量计算等。综合以上因素,需从水文模型的计算机实现中抽象出数据、算法、模块和模型4个层面来进行水文模型的服务化封装方法研究。
水文模型数据种类多样,相应的数据表示方式也多种多样。常见的水文模型数据类型包括:基本信息、实时信息、下垫面信息和模型参数信息等,总的来说,水文模型主要有3种数据来源:数据库、文件和用户界面输入。
水文模型在实现时会运用到多种多样的算法,如数学公式、物理规律等。通过分析多种算法的特征,水文模型算法服务化封装的组成要素主要包括:算法服务标识、算法服务描述、算法服务输入、算法计算流程和算法服务输出几部分。
模块服务化封装思路大致与算法服务化封装保持一致,两者的区别之处主要在于模块封装时新增的外部调用流程。水文模块除了实现自身特有的计算逻辑外,有时还需要组合已定义的算法或模块,从而需要实现外部接口调用的定义。模型服务化封装的主要工作便是模块的组合。根据流域特征及适用条件等动态组合模块形成不同的模型,可以极大地增强模型的灵活性,最终形成模型库实现模型的集成与共享。模型服务化封装分为两种情况:有源程序的模型封装和无源程序的模型封装。
2.2.2 水文模型服务集成方法
水文模型服务集成就是指水文模型业务流程定义的过程。业务流程由一系列服务节点组成,通过设计流程控制引擎来处理服务节点之间的调用逻辑。业务流程的执行就是各个服务节点依次按逻辑被调用的过程,它将原子业务功能按需串接在一起,最终形成完整的水文模型服务,对外提供模型服务调用接口。
水文模型服务集成框架主要由数据服务、业务功能和业务流程3部分组成。业务功能指的是算法服务层、模块服务层和模型服务层所包含的独立的服务节点。业务流程指的就是服务节点之间的调用逻辑。数据服务为所有的功能服务节点提供了数据支持。水文模型服务集成框架如图6所示,图中的正方形、三角形和圆形分别代表了不同层面的服务节点,箭头方向则代表了服务的调用方向。模型服务会调用模块服务,模块服务会调用算法服务。一个模型服务可以调用多个模块服务,一个模块服务可以调用多个算法服务,一个算法服务可以被多个模块来调用,一个模块也可以被多个模型调用。

图6 水文模型服务的集成框架Fig.6 Integrated framework for hydrological model services
在分析水文模型组成时,往往采用自上而下的模型分析方法。首先,从模型整体出发研究可以分成的模块数以及每个模块所能提供的功能,然后分析模块中所包含的水文过程,从每种水文过程中挑选出合适的算法或方程进行模拟。水文模型服务集成过程是一个与之相反、自下而上的过程,需要先定义算法服务,再组装模块服务,最终生成模型服务。
2.3 中小河流洪水预警多重情景仿真技术
为准确预报及展示洪水演进轨迹和影响范围,提出一种中小河流垂直河道淹没算法,从宏观角度为水利部门提供决策支持;为直观有效再现洪涝灾害的发生范围及程度,提出一种基于UE4引擎的淹没仿真设计流程,从微观角度模拟洪水淹没的动态过程。
2.3.1 中小河流垂直河道淹没算法
中小流域具有地形较复杂、洪水来水快以及洪水漫延范围广等特点。结合无源淹没的优点及有源淹没的思想,同时考虑大范围淹没情况下无源淹没未考虑连通性所造成的准确性差以及有源淹没需要选取种子点而中小流域在发生大范围淹没的情况下无法选取种子点,提出一种以河道为考虑对象的中小流域垂直河道淹没算法。
垂直河道淹没算法以流域内河道为处理对象,在每段河流汇流处将河道进行分段,形成多个河段。具体算法实现步骤如下:
a. 输入水位数据PwaterLevel,输入流域ASCII格式的DEM数据以及河道折点数据。
b. 初始化河段类RiverLine,其中包括河段的基本属性以及河段各折点坐标数组。
c. 读取流域内所有河段数据并以RiverLine对象的形式存储到集合list中。
d. 取出集合中的一个河段对象,从河段端点开始,取出顺序的2个折点Pa(Plng1,Plat1)以及下一折点Pb(Plng2,Plat2),用式(3)计算线段PaPb长度d,用式(4)计算线段长度为DEM数据像元大小的倍数。

(3)

(4)
式中:PcellSize——像元大小,即步长。
e. 判断Pa点与Pb点的相对关系,即判断Pb点在Pa点的什么方向。判断方法如下:通过式(5)和式(6)计算2点的经度差PdifferLng和纬度差PdifferLat,并计算线段PaPb与纬线的夹角α。
PdifferLng=Plng1-Plng2
(5)
PdifferLat=Plat1-Plat2
(6)
f. 将线段按等分成t段,得到多个等分点坐标。
g. 在各处等分点(Plng,Plat)做与线段垂直方向上的探测线,沿水流方向在河道左右两侧进行探测,PcountLeft为左侧探测次数;PcountRight为右侧探测次数;通过夹角α获取到每次探测点的坐标(PtempLng,PtempLat)。
h. 获取到坐标点对应的高程值PcellValue,如果PcellValue为-9 999则停止操作,否则计算水深PwaterDepth的公式如下:
PwaterDepth=PwaterLevel-PcellValue
(7)
i. 判断PwaterDepth与0的关系,若PwaterDepth大于0,则将淹没区域的水深值赋值给对应的栅格,其余未淹没区域值用-9 999填充。
j. 判断所有河段是否已被计算完毕,若还未计算完毕,则重复步骤(4)至步骤(9)继续对剩余河段操作,求出剩余河段的淹没情况,直至所有河段计算完毕。
k. 最后将淹没结果以ASCII文件的形式写出到硬盘。
试验主要是以安徽省屯溪流域为研究对象,所有实际水位数据均由屯溪水文站监测计算得到;DEM数据来自地理空间数据云;根据获取到的DEM数据并结合河道特点,提取该流域的所有河道栅格数据。
当水位在180 m、200 m时,由于屯溪流域最低高程值为115 m,且流域内高程值低于180 m、200 m的分布于河道两侧的区域明显较多,故在屯溪流域发生大范围的淹没情况,在高程较高的黟县站附近也发生小区域的淹没情况,且与大淹没区域连通,其30 mDEM分辨率淹没范围示意图如图7(a)和图7(b)所示。

图7 30 m DEM分辨率淹没情况Fig.7 Flood inundation situation of 30 m DEM resolution
2.3.2 基于UE4引擎的淹没可视化
在UE4平台的应用基础之上,提出了一种用于模拟洪水淹没实时研究过程的设计流程。结合DEM数据,3DM按模型及系列UE4组件,进行洪水淹没的可视化[21]。
总体设计流程如下:首先以精细化DEM数据为基础,制作指定流域地貌地形,同时结合贴图材质、模型实例、光照系统等相关组件搭建流域模拟场景并进行优化处理。随后使用蓝图编辑器设计多重触发事件及过场动画,从而获得高拟真度且切合实际的实时淹没仿真效果。
本文以屯溪流域出口区域地形地貌和精细化DEM数据为基础,通过UE4引擎处理形成屯溪流域洪水淹没仿真基础场景,高度还原了屯溪水文站附近1.588 km2的流域场景。接入实时水文数据库,依据blueprint中断机制对JSON格式水文数据进行解析,借助Lerp插值方式控制河道水位,为淹没过程仿真作数据准备。使用基于TimeLine时间轴线的帧动画渲染,模拟洪水淹没的动态过程,并在水位超出警戒范围后发出模拟预警预报,如图8所示。

图8 洪水淹没与预警预报效果Fig.8 Effect of flood inundation and warning
3 平台集成与应用
基于上述的系统结构,集成数据质量控制、多层次的按需智能服务体系和多情景仿真等关键技术,采用Java、Spring Cloud和Docker等技术栈,构建了中小河流洪水预警预报智能调度平台。中小河流洪水预警预报智能调度平台主要功能包括作业预报模块、预报结果可视化模块和方案智能调度模块。
a. 洪水预报模块实现了人工预报和自动预报的功能。人工预报利用选择的预报方案和经过数据质量控制的实时/历史降雨数据,根据预报参数配置水文模型,并调取相关微服务进行组合为预报模型进行预报,并展示预报结果。自动预报通过定时服务,通过指定方案和实时信息进行预报。
b. 预报结果可视化模块根据洪水预报模块的结果,在多重情景下对结果进行可视化展示,包括淹没仿真、UE4动态渲染等。
c. 方案智能调度模块基于作业预报结果,结合地形资料等前置数据,根据调度方案库智能生成具体调度方案,供防汛部门参考。
d. 试验选取2016年6月的一场洪水进行作业预报,作业预报计算结果过程统计与上游网格汇水面积如图9所示。图9(a)利用折线图、柱状图直观展示了流量、水位以及面雨量在洪水演进过程中的变化;图9(b)展示了当前网格的流量过程线与上游网格汇水面积及其汇流方向。

图9 作业预报计算结果及其可视化Fig.9 Calculation result of operation forecast and its visualization
目前,中小河流洪水预警预报智能调度平台已在示范流域安徽屯溪得到应用,同时在南京秦淮河、福建漳州平和、龙山和马口等中小流域得到推广应用。
4 结 语
针对中小河流水文气象数据缺失、异常以及资料系列短等问题,提出多源水文气象数据质量控制技术和方法;分析中小河流洪水防控与应急管理多业务协同关系,提出针对“情景-仿真-应对”模式的可视化技术,为实现预报预警和应急处置的快速动态展示提供技术保障;研发云环境下具有状态和交互特征的模型封装服务技术,实现不同时空尺度中小河流预报预警、风险评估、智能调度等模型耦合集成,提供数据、算法和模型多层次按需服务。基于上述关键技术与算法,结合云平台构建技术,研制中小河流洪水预警预报智能调度决策支持平台,开发数据交换接口,接入省和国家防汛指挥系统,在示范流域开展应用,进行成效评估,有效提高中小河流的洪水预报水平与防洪减灾能力。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
现代经济信息(2021年3期)2021-11-23
陕西档案(2021年2期)2021-05-21
天津诗人(2017年2期)2017-11-29
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
少儿科学周刊·儿童版(2015年7期)2015-11-24
少儿科学周刊·儿童版(2015年7期)2015-11-24
