
基于TF-IDF的防网页篡改监测系统
2021-06-11 02:01麦欣彦郑棉炜张占英
锦绣·下旬刊 2021年2期
麦欣彦 郑棉炜 张占英


摘要:在信息技术飞速发展的现代,网络安全越加重要已是未来的趋势所向。随着越来越多的人登录网站、浏览网站,判断网站内容是否真实、是否被篡改成为一大难题。于是网站防篡改监测系统的构建变得极其重要,本文构建了一种基于TF-IDF的防网页篡改监测系统,用于解决网页内容被篡改而导致获得信息不真实的情况。基于TF-IDF的防网页篡改监测系统通过使用爬虫技术获得网页信息,并对爬虫获得的网页信息进行预处理,接着使用TF-IDF算法将网页信息量化,计算网页间的余弦相似度,当相似度低于报警阈值时,系统将对网站管理者发出警报。本系统解决了由于网站管理人员水平的参差不齐以及不同网站管理的难度差异大所造成的网站安全隐患,建立了有效的监测机制,适用于绝大多数网站。在成本和效率上大大的改进了传统的人工监测网站的方法,有很大的应用前景。
关键词:爬虫技术;TF-IDF算法;余弦相似度;防网页篡改监测系统
Abstract:In the modern era of rapid development of information technology, the increasing importance of network security is the future trend. As more and more people log on and browse the website, judging whether the content of the website is authentic and whether it has been tampered with has become a major problem. Therefore, the construction of an anti-tampering monitoring system for websites has become extremely important. This article constructs a TF-IDF-based anti-tampering monitoring system for web pages to solve the problem of untrue information obtained due to tampering of web content. The TF-IDF-based anti-tampering monitoring system for web pages obtains web page information by using crawler technology, and preprocesses the web page information obtained by the crawler, and then uses the TF-IDF algorithm to quantify the web page information and calculate the cosine similarity between web pages. When the degree is lower than the alarm threshold, the system will issue an alarm to the site manager. This system solves the hidden dangers of website security caused by the unevenness of the level of website management personnel and the large differences in the difficulty of different website management, and establishes an effective monitoring mechanism, which is suitable for most websites. It has greatly improved the traditional website monitoring method in terms of cost and efficiency, and has great application prospects.
Keywords: crawler technology, TF-IDF algorithm, cosine similarity, anti-tampering monitoring system.
一、引言
近年来,随着互联网行业的高速发展,越来越多的人已经习惯通过访问一个学校或者公司的官网来了解相关信息。但是由于网站管理人员水平的参差不齐,缺乏有效监测机制,导致网站存在着不同程度的安全隐患。2017年我国开始施行《中华人民共和国网络安全法》,其中第二十一条明确规定了“国家实行网络安全等级保护制度,要求网络运营者应当按照网络安全等级保护制度要求,履行安全保护义务”,体现了国家对网络安全这一领域的重视。
对于一个网站来说,最大的风险可能不是服务器宕机或者网站瘫痪,更严重的是被黑客非法入侵后篡改網站内容,使其链接到广告、游戏甚至是国外政治敏感站点。对于网站管理者来说,他们迫切需要一个能够有效监测网页内容是否被篡改的系统,能够在占用服务器资源较少的情况下对网页历史信息进行比对,并在发现网页被篡改时进行报警。
目前国内已有不少学者在相关领域进行了研究,储久良[1]等人采用虚拟化技术,使用开源软件SNM实现高校网站群监控系统[2],其缺点是在部署的时候相对复杂,需要一定的技术基础。高新成[3]等人提出了基于.NET的校园站群内容更新监测系统,但是该系统只能运行于Windows平台,缺少一定的适用性。为了解决上述的问题,不仅需要考虑部署的简便性,还需要考虑系统能否在各主流平台上适用,本文提出了一种基于Python Django框架的防网页篡改监测系统,采用词袋模型和TF-IDF算法对词向量进行加权处理,通过计算不同时间段文本向量的相似度,当相似度低于报警阈值时,可通过多种形式对网站管理者发出警告。
二、相关理论
2.1 词袋模型(Bag of Words)
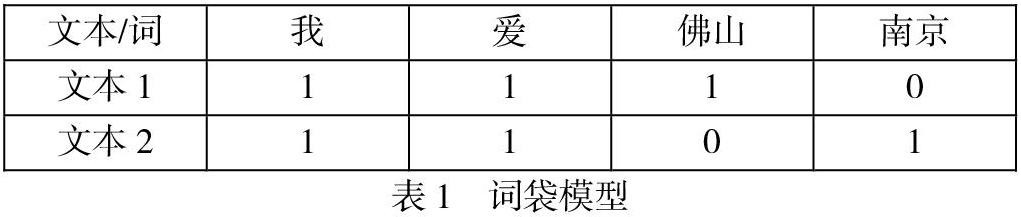
词袋模型是一种基础的特征提取方式,基本原理就是将目标文本看作无数个词的集合,文本集中所有的词在目标文本中是否出现可以作为文本的特征,若出现则为1,否则为0。词袋模型对于一个目标文本可以忽略文本中词的次序和句子的语法,文本中任意一个词出现在文本中的任意一个位置,都不会受到其他因素的干扰。利用词袋模型可以实现从文本中提取特征项形成特征项矩阵被用于文本分类[4]
以“我爱佛山”和“我爱南京”为例,构建的词袋模型如下:
文本1:我、爱、佛山 文本2:我、爱、南京
对文本1、文本2构造向量如下表1词袋模型所示:
2.2 TF-IDF算法(Term Frequency–Inverse Document Frequency)
TF-IDF是一种用于信息检索与数据挖掘的常用加权技术,用于评估字词对于一个文本集或者一个语料库中的其中一份文本的重要程度。TF是词频(Term Frequent)指的是某个给定词语的在该文本中出现的频率,再将其归一化,防止偏向长的文本。IDF是逆文本频率指数(Inverse Document Frequency)可以理解为一个词语普遍重要性的度量[5]。
算法的核心思想:如果特征在文本集中出现的频率的低,但是在某一类的文本中出现的频率较高,即也能说明该特征具有较好的类别区分能力,可以赋予较高的权重[6]。
TF表示關键词在整个文本中出现的频率,计算方式如下:
其中表示该词在文档中出现的次数,表示文档中所有词汇出现次数的总和。
某一个词的IDF可以由总文档数除以包含该词语的文档数再取商对数获得,计算公式为:
TF-IDF的计算方式为:
2.3 余弦相似度
在维空间中,任何向量都可以看成从原点出发指向不同方向的有限线段,任意两条有向线段之间存在着一个确定的夹角以及夹角的余弦值。余弦相似度就是利用线段间余弦相似度大小来衡量向量差异度的方法[7]。若其夹角余弦值为1,则两向量差异度最小,若其夹角余弦值为-1,则说明两向量反向。所以可以通过计算两个向量之间的夹角余弦值,来评估他们之间的相似度,其计算公式为:
三、防网页篡改监测系统的构建
防网页篡改监测系统主要由以下几个部分构成。
3.1 网页文本信息获取
通过调用Python的Requests库,获取指定网页的文本信息,作为下一步骤的文本输入。
3.2 提取文本特征
该过程主要由2个步骤组成:
1、文本预处理:使用正则表达式,对原始输入文本中的无意义的符号进行去除。
2、分词,构建词库:使用Python中的Jieba分词库,对预处理后的文本进行分词,取分词后出现次数前20的的关键词作为这个输入文本的语料库。
3.3 计算相似度
1、将两个不同时间提取文本特征得到的语料库,合并成一个新的语料库,基于得到的语料库,通过TF-IDF算法生成两段文本的词频向量。
2、计算两个词频向量之间的余弦相似度,相似度越接近1,说明网页文本内容越接近,没有被恶意篡改。
3.4 敏感词监测系统
中文互联网上有许多敏感词,为此我们收集了部分敏感词绘制为表2部分敏感词表,当原始文本输入文本中出现该敏感词,将触发报警机制。
3.5 报警机制
该系统具有多种报警机制,可以本系统可通过微信、短信、邮箱、电话等多种方式进行报警,确保网站管理员第一时间收到报警信息。
四、实验验证
4.1 实验平台
本文实现的防网页篡改监测脚本在以下平台进行实验,CPU:Intel Core i5 8300H,内存:DDR4 16G,硬盘:固态硬盘240G,操作系统:Windows10,开发环境:Python3.8.3、Django2.2。
4.2 实验流程
按照图1监测系统流程图中的步骤进行实现验证,将输入的文本信息进行实时监测达到网页防篡改监测的目的。
4.3 实验方法
本文以佛山科学技术学院官网(https://www.fosu.edu.cn/)作为测试对象,通过手动篡改的方式,对网站的文本内容进行不同程度的篡改,下表3篡改内容表是对内容进行篡改的详情。
实验时,开启脚本监测,然后爬取佛山科学技术学院官网网页源码,统计出出现次数前20的文本信息,绘制词频图如上图2 未篡改的佛山科学技术学院官网词频图所示。接着,将导航栏文字内容中的“学校”篡改为“学院”,绘制词频图如下图3篡改内容后的佛山科学技术学院官网词频图所示。之后,将所得词使用TF-IDF算法向量化,进行余弦相似度计算。结果发现当篡改导航栏文字内容后,原网页与篡改的网页之间的余弦相似度产生变化,脚本能敏锐监测到这种变化,从而发出警报。
设定软件监测的间隔为3分钟,脚本启动后每3分钟会对网页进行一次监测,计算与3分钟前网页的余弦相似度。当相似度低于0.98(按照经验设置)或监测到敏感词时,会触发报警系统,通过多种方式对网站管理员进行报警。
4.3 实验结果
按照实验结果,可以将相似度阈值定为0.98,当两文本计算得到的余弦相似度低于该阈值时,可以判定为网页发生了篡改行为,对管理员及时进行示警。同时,实验结果表面对页面部分微小变化还是比较灵敏的,在不占据大量系统资源的前提下,具备不错的实用性。
五、结语
国家《网络安全法》的推出,体现了国家对网络安全这一领域的重视程度。近年来,门户网站成为了人民群众了解党政部门的重要途径之一,而党政部门网站频繁遭受篡改,信息泄露等风险。本文通过网站被篡改的特征,构建了一种基于TF-IDF的防网页篡改监测系统,能够有效监测网页文本内容被篡改。当检测到网站内容被篡改或者出现敏感词时,能够及时通过多种方式提醒网站管理员,确保网站的正常使用。
参考文献
[1]储久良,李玲.虚拟化技术在高校数据中心的应用[J]. 实验室研究与探索,2012.
[2]王宁邦,徐博.基于爬虫和网页防篡改的高校门户网站群预警监控系统构建[J].云南民族大学学报(自然科学版),2019.
[3]高新成,王燕,王蔚龙.基于.NET和MVC的校园网络管理协作办公系统[J].齐齐哈尔大学学报(自然科学版),2012.
[4]黄春梅.王松磊.基于词袋模型和TF-IDF的短文本分类研究[J] .软件工程师, 2020.
[5]任世超.基于机器学习的文本分类算法研究[D].成都信息工程大学,2019.
[6] 但唐朋,许天成,张姝涵.基于改进TF-IDF特征的中文文本分类系统[J].计算机与数字工程,2020.
[7]李虹,王子文.基于余弦相似度的多能互补园区供能分区规划[J].电力科学与工程,2020
作者简介:张占英,男,佛山科学技术学院数学与大数据学院,讲师,主要从事自然语言处理与人工智能的相关研究
麦欣彦, 男,佛山科学技术学院数学与大数据学院,学生
郑棉炜,男,佛山科学技术学院数学与大数据学院,学生
(佛山科学技术学院 数学与大数据学院 广东 佛山 528000)
