
视觉里程计研究综述
2021-06-28 06:59胡凯吴佳胜郑翡张彦雯陈雪超鹿奔
南京信息工程大学学报 2021年3期
胡凯 吴佳胜 郑翡 张彦雯 陈雪超 鹿奔
1 南京信息工程大学 自动化学院,南京,210044 2 南京信息工程大学 江苏省大气环境与装备技术协同创新中心,南京,210044
0 引言
为了使得计算机能够和人一样通过感觉器官观察世界、理解世界和探索未知区域,视觉里程计(Visual Odometry,VO)技术应运而生.作为同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)[1-3]的前端,它能够估计出机器人的位姿.一个优秀的视觉里程计技术能为SLAM的后端、全局地图构建提供优质的初始值,从而让机器人在复杂的未知环境中实现精准自主化来执行各种任务.传统的里程计,如轮式里程计因为轮子打滑空转而容易导致漂移,精确的激光传感器价格昂贵,惯性传感器虽然可以测量传感器瞬时精确的角速度和线速度,但是随着时间的推移,测量值有着明显的漂移,使得计算得到的位姿信息不可靠.而视觉里程计由于视觉传感器低廉的成本和长距离较为精准的定位在众多传统里程计中脱颖而出.
所谓视觉里程计就是从一系列图像流中恢复出相机的运动位姿,这一思想最早是由Moravec[4]提出的,他们不仅在论文中第一次提出了单独利用视觉输入的方法估计运动,而且提出了一种最早期的角点检测算法,并将其使用在行星探测车上,体现了现阶段视觉里程计的雏形,包括特征点检测及匹配、外点排除、位姿估计三大块,使得视觉里程计从提出问题阶段过渡到了构建算法阶段,Nister等[5]在CVPR上发表的论文中提出了一种利用单目或者立体视觉相机来获取图像的视觉里程计系统,宣告VO技术进入了优化算法阶段.随着ORB-SLAM[6]的问世,VO作为SLAM的前端成为了研究热潮,也代表着主流基于特征点法VO的一个高峰.Engle等[7]提出的LSD-SLAM则成功地把直接法的视觉里程计应用在了半稠密单目SLAM中.近年来涌现了各类的新颖视觉里程计系统,比如2019年Zheng等[8]提出了一种基于RGB-D传感器的自适应视觉里程计,可以根据是否有足够的纹理信息来自动地选择最合适的视觉里程计算法即间接法或者直接法来估计运动姿态.
本文重点对视觉里程计的已有研究工作进行综述,主要选取了近年来有代表性的或取得比较显著效果的方法进行详细的原理介绍和优缺点分析.根据是否需要提取特征点大致分为特征点法和直接法.也可以根据是否脱离经典的位姿估计模块方法分为经典视觉里程计和新颖视觉里程计.最后总结并提出未来的发展前景.
本文第1节介绍传统视觉里程计框架的算法.其中包括特征点法VO的关键技术和直接法视觉里程计中的相关算法.第2、第3节综述最新的视觉里程计研究方法,包括第2节中惯性视觉传感器融合的易于工程实现轻量型的VO,以及第3节中基于深度学习的视觉里程计可以通过高性能计算机实现精密建图等功能.第4节简要概括视觉里程计的各类标志性算法.第5节结合视觉里程计面临的挑战,展望了未来的发展方向.
1 传统视觉里程计
传统视觉里程计沿用了Nister等[5]的VO框架,即依据相邻帧之间特定像素几何关系估计出相机的位姿信息,包括位置(x,y,z)和滚转角(roll)、俯仰角(pitch)以及偏航角(yaw)三个方向信息.根据是否需要提取特征,分为特征点法和以灰度不变假设为前提的直接法.
1.1 特征点法
特征点法首先从图像中提取出关键特征点,然后通过匹配特征点的手段估计出相机运动.大致分为了两个部分,即特征点的提取匹配和相机运动的位姿估计.特征点法在视觉里程计中占据了主要地位,是因为其运行稳定,而且近年来研究者们设计了许多具有更好鲁棒性的图像特征,这些特征对于光照敏感性低,而且大多拥有旋转不变性和尺度不变性.线面特征的提出更是使得特征点法适应了纹理信息少的场景.特征点法示意如图1所示.

图1 特征点法示意图Fig.1 Schematic diagram of feature-based method
1.1.1 特征提取及匹配
经典的特征算子有SUSAN[9]、Harris[10]、FAST[11]、Shi-Tomasi[12]、SIFT[13]、SURF[14]、PCA-SIFT[15]、ORB[16],其中最为基础也是最为经典的是Harris和SIFT(尺度不变特征变换)算法,现有的算法基本都是基于这两者,可以看作是Harris和SIFT的简化和改进.Harris角点检测算法运用了微分运算和角点邻域的灰度二阶矩阵,而微分运算对图像密度和对亮度的变化不敏感性和二阶矩阵特征值不变性使得Harris角点检测算子拥有了光照变化不敏感、旋转不变性.后来出现了SUSAN算子,它的原理和步骤和Harris较为相似,但是SUSAN算子不仅拥有较好的边缘检测性能,在角点检测方面也有较好的效果,能够应用在需要轮廓提取的环境下.
但是Harris算子和SUSAN算子都不具备尺度不变性,这是一个很大的缺陷.因为视觉传感器获得的图像除了旋转和光照变化之外,往往尺度都不具有一致性.
而SIFT算子充分考虑了在图像变换过程中出现的光照、尺度、旋转等变化.SIFT算法在所有尺寸空间上通过高斯微分函数来识别出可能存在的尺度和旋转不变的特征点,使得SIFT具有尺度不变性.然后对DoG空间进行拟合处理,找到稳定的关键点的精确位置和尺寸.基于图像局部的梯度方向,分配给每个关键点位置方向信息,使得SFIT算子具有旋转不变性.此时关键点的位置、尺度和方向信息已确定,接下来需要描述符来描述关键点.其描述符根据图像局部梯度变换而来,这种表示允许比较大的局部形状的变形和光照变化.虽然SIFT有很多优点,但计算量极大,一般SIFT算法运用在不考虑计算成本的场景中.
SURF(Speeded Up Robust Features,加速稳健特征)在SIFT基础上进行改进,大大提升了运行速度.它采用了盒式滤波器来近似高斯滤波,对图像进行滤波之后,计算像素的黑塞(Hessian)矩阵行列式近似值,而盒式滤波器对图像的滤波转化成计算图像上不同区域间像素和的加减运算问题,只需要简单几次查找积分图就可以完成.SURF节省了大量时间,兼顾了效果和精度.
Ke等[15]通过对SIFT的描述子数据进行主成分分析,对数据进行了降维,最终也达到了加快算法的运行速度的目的.PCA-SIFT构建了一个包含所有特征点和其描述子信息的特征矩阵,然后计算矩阵的协方差矩阵的特征向量,并选择前n个较大的特征向量构成投影矩阵,再把描述子向量与投影矩阵相乘即可降维.PCA-SIFT对于旋转和光照有较好的不敏感性,但是由于PCA-SIFT不完全的仿射不变性,投影矩阵需要在特征比较明显的场景下才能起作用.
现阶段能够较为快速、稳定且准确地运用在视觉里程计上的是ORB算法,它充分考虑了SLAM系统需要的实时性、鲁棒性和准确性,为后端提供了较好的初始值.它采用了改进的Fast关键点检测,构建了图像金字塔,在每一个尺度层检测关键点,从而实现尺度不变性;特征的旋转不变性由灰度质心法实现.ORB使用BRIEF描述子,它是一个二进制向量,是在提取关键点之后,在其邻域内选择N个点对比较像素大小,例如假设pn(xi,yi),qn(xj,yj)是某关键点邻域内的第N个点对.(xi,yi)和(xj,yj)分别是pn,qn的坐标,若pn(xi,yi)的像素值小于qn(xj,yj)的像素值则取0,否则为1.经过N次比较后得到一个N维的描述子向量.
以上所述的都是传统的特征点法,它们由于环境因素导致的特征分布不均匀、纹理信息单一甚至是相机模糊等问题而提取不到足够的关键点,这种情况是普遍存在的,使得特征点法无法很好地运行,间接影响了后续位姿估计的精度.而线特征对于光照有着不敏感的特性,所以能够使得VO系统很好地适应弱纹理环境的场景.
Lu等[17]提出了使用点线特征的视觉里程计,该算法吸收了直接法与特征点匹配法的优点,在纹理较少的环境中有不错的效果.通过增大算法的收敛域,该算法对于光照变化和快速运动的场景有更好的鲁棒性.在跟踪部分,同时处理点特征和线特征,点特征根据实际情况选用特征提取算法,比如SURF;线特征跟踪部分,由于在针孔相机模型中,从世界坐标系中点或者线投影到相机成像平面的投影线始终保持直线,为了检测世界坐标系中的三维线,需要在对应的相机图像中检测它们的投影.所以使用LSD[18]算法来提取线特征,效果如图2所示.

图2 LSD算法提取线特征效果Fig.2 Line feature extraction by LSD
与点特征会有外点一样,线特征也会有离群点.RANSAC算法在滤除离群点的同时检测三维线段的存在,对提取到的线特征的MSLD描述符[19]进行最近邻匹配,如图3所示.

图3 采样点选择示意图[19]Fig.3 Schematic diagram of sampling point selection[19]
虽然结合了线特征使得VO系统在复杂恶劣的环境中更加稳定、准确,但是同时也增加了计算量,会降低实时性.比如Pumarola等[20]提出了一种基于单目相机的融合点线特征的实时PL-SLAM系统,通过引入线特征提升了ORB-SLAM算法的精度,同时也增大了计算复杂度,尤其是在特征匹配阶段.PL-SLAM在单目ORB-SLAM的基础进行改进,把LSD线段提取算法与ORB特征点提取算法融合,使得ORB-SLAM拥有了适应低纹理环境的能力,还提出了新的初始化策略,即在连续三帧图像中只能检测到线特征的情况下,估计出一个近似的初始化地图.
Gomez-Ojeda等[21]则是通过点线特征的组合把PL-SLAM系统运用到立体视觉上,让线特征在视觉里程计系统上的使用更加泛化,再利用(Pseudo-Huber)损失函数来剔除误匹配的特征.最近文献[22]引入了与强角点即某些属性特别高的点相结合的边缘,提高具有很少或高频纹理的环境中的稳健性.Zhao等[23]提出了一种由两个反投影平面的法线来表示线特征的参数化,从而使得线特征的重投影误差达到最小值,这种方法可以降低PL-SLAM系统对线特征的端点进行参数化造成计算冗余的负面影响.表1中列举了当前特征检测算法在旋转不变性、尺度不变性、光照不变性、可重复性、抗干扰性和计算效率几个方面的性能比较.

表1 特征检测算法性能比较
1.1.2 位姿估计
位姿估计是视觉里程计系统中的核心,也是其重要目标.位姿估计也就是通过分析相机与空间点的几何关系,从而计算出把K-1时刻的相机位姿变换到K时刻相机位姿的变换矩阵Tk,k-1.根据时间序列把相邻时刻的运动串联起来,这样就构成了机器人或者相机的运动轨迹.无监督学习VO、VISO2-Mono和VISO2-Stereo在KITTI数据集上的运动轨迹如图4所示.

图4 运动轨迹效果Fig.4 Motion track rendering
根据不同视觉传感器获得不同的图像信息而分成三种基本的运动估计计算方法.
1) ICP方法.若相机能够通过某种方式获得深度信息如使用双目相机或者RGB-D相机,此时通常使用ICP算法(迭代最近点算法)[24]来解决.假设在相邻帧有一组匹配好的3D点P={p1,p2,…,pn}和P′={p′1,p′2,…,p′n},位姿估计也就是想要找到一个旋转矩阵R和平移向量t使得∀i,pi=Rp′i+t.由此3D-3D(3D即三维图像的3D点)之间的位姿估计可以转换为求解最小化三维点之间误差的数学模型,即ei=pi-(Rp′i+t).
现有的ICP求解方式分为两种,一种是线性代数的求解法比如奇异值分解法(SVD)[25],它可以分为三步:


③计算平移向量t*,t*=q-Rq′.
另一种是非线性优化方法,通过迭代的方式找到最优值.它类似Bundle Adjustment方法,构建目标函数即式(1)之后,把相机位姿作为一个变量,不断迭代、更新、优化,得出一个最优的位姿:
(1)
其中在ξ右上角的倒三角符号∧表示把ξ六维向量(前三维是平移向量,后三维是旋转向量)转换为一个四维矩阵.
2) 对极几何方法.若能获得的图像只有2D图像,如机器人使用单目相机而无法获得深度信息,此时使用对极几何方法解决.对极几何用在只知道匹配点的2D像素坐标的情况下,一般是机器人使用的相机传感器为单目相机.3D-3D或者3D-2D问题都至少需要获得一组特征点是三维的,所以需要用至少两个单目相机或者能够获得深度的RGB-D相机,而解决2D-2D问题只需要一个单目相机,它以其低廉的价格在众多里程计方案中脱颖而出.为了探索2D点之间的几何关系,一般引入对极几何约束.如图5所示,pi-1,pi分别是图像Ii-1,Ii中的由上述的特征匹配方法所得一个特征点,它们都是世界坐标系中空间点P的投影.假设这是一次正确的匹配,其中Oi-1,Oi是两个相机的光心,li-1,li分别是Ii-1,Ii中的极线.
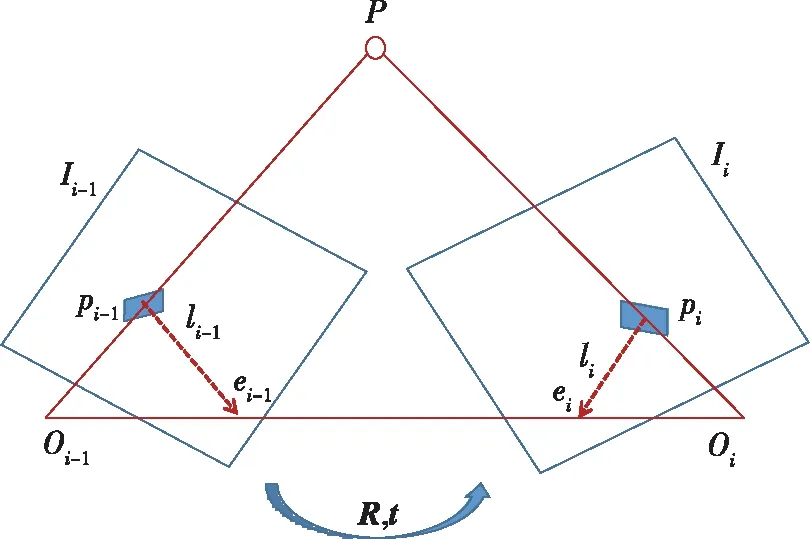
图5 对极几何约束示意图Fig.5 Schematic diagram of polar geometric constraints
为了求解出它们之间的运动,即求解旋转矩阵R、平移向量t,引入对极几何约束,可以得出式(2),(3).其中t∧表示向量t的反对称矩阵,上标T表示转置,K为相机的内参矩阵.
(2)
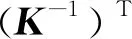
(3)
从而可以从式(3)中的本质矩阵E、基础矩阵F解出R和t,常用八点法[26]或者复杂一点的五点法[27]来求解.如果相机画面中的特征点都落在同一平面上则需要单应矩阵来估计运动.
3) PnP方法.PnP方法用来解决相邻时刻仅有一个时刻的图像能获得深度信息的情况.PnP(Perspective-n-Point)是求解相邻两帧图像中特征点一帧是二维特征点而另一个是三维特征点的运动估计方法.PnP求解的方式有很多种,其中Moreno-Noguer等[28]对此有很大的贡献.常用的解决方法有至少需要6对匹配点的直接线性变换(DLT),有只需要3对匹配点的P3P,也有后续更为复杂的EPnP和UPnP,还可以转化为非线性优化的方式,利用迭代法求解构建的最小二乘问题.其中DLT把旋转矩阵R和平移向量t定义成一个增广矩阵[R|t],根据空间点与其投影到相机成像平面对应的特征点之间的关系而求解位姿估计问题;P3P则是利用给定的3个点之间形成的三角形相似性质来解决3D-2D位姿估计问题,把2D点转换成相机坐标系下的3D坐标,然后就变成了3D-3D的位姿估计问题,如图6所示.其中O为相机光心,A,B,C分别为3个3D点,a,b,c分别为3个2D点,L为3D点的投影平面.

图6 P3P问题示意图Fig.6 Schematic diagram of P3P problem
1.2 直接法
虽然特征点法是主流方法,但是相比于直接法仍然有着很多缺点.比如特征点法需要十分耗时地提取特征,计算描述子的操作丢失了除了特征点以外的很多信息,而且更加适应低纹理信息场景.直接法不同于特征点法最小化重投影误差,而是通过最小化相邻帧之间的灰度误差估计相机运动,但是基于灰度不变假设:
I(x,y,z)=I(x+Δx,y+Δy,z+Δz).
(4)
例如假设空间有点P投影到相邻两帧图像上有p1,p2两点.它们的亮度分别为I1(p1,i)和I2(p2,i),其中i表示当前图像中第i个点.则优化目标就是这两点的亮度误差ei的二范数.此法可以应用在纹理信息较少、无法提取到足够的特征点的场景下,直接估计相机的运动.直接法示意如图7所示.

图7 直接法示意图Fig.7 Schematic diagram of direct visual odometry
其中T和ξ分别是p1,p2之间的转换矩阵及其李代数.式(8)ξ∧右上角的∧表示把ξ转为一个四维矩阵,从而通过指数映射成为变换矩阵.
Ma等[29]已经成功地把直接法用于RGB-D视觉传感器上.为了让计算量颇大的直接法能够实时地运行在单个CPU上,文献[30]提出了一种半稠密型深度滤波器公式,它能够大大降低计算复杂度,甚至还可以在智能手机上使用AR技术.LSD-SLAM[7]改进了传统直接法,将深度噪声加入到最小化光度误差的公式中得到较好的效果,它是单目直接法的标志性算法,是一种半稠密直接法.
直接法应用到完整的V-SLAM系统时,如果有恰当特征点的辅助,将会使得系统变得更加鲁棒和精准.如Forster等[31]提出一种半直接法SVO(Semi direct monocular Visual Odometry),它结合了特征点和直接法,在追踪部分使用稀疏直接法对稀疏关键点获得粗略的位姿信息,并利用光流法来找到当前帧和地图点对应帧的像素块,优化后把关键帧地图点投影到当前帧.
2018年,Zhang等[32]提出的DOVO根据ORB特征获取的关键点数量和一个阈值K来评估使用ORB特征进行姿态估计的可靠性.如果关键点的数量小于阈值K,则采用直接法保持摄像机的跟踪,并根据场景的光度优化光度误差来估计摄像机的姿态,否则通过优化重投影误差来计算姿态估计.实验结果表明,该方法保证了姿态的准确性和实时性.
Engel等[33]提出一种纯使用直接法的视觉里程计DSO(Direct Sparse Odometry).不同于传统的直接法,它将数据关联与位姿估计转换成一个统一的非线性优化问题.其第一创新点是通过光度标定改善由于相机参数改变引起的图像亮度变化问题,第二个创新点则是滑动窗口优化有效地控制了优化的计算量,又有良好的优化效果.实验结果表明,无论在跟踪精度还是鲁棒性方面,该方法在各种真实环境下都显著优于最先进的直接和间接方法.DSO的出现将直接法的视觉里程计推上了一个新的高度.但是由于直接法相比于特征点法具有的非凸性,限制了DSO在处理视频时的效果.2019年,Sun等[34]提出的FSMO(Fully Scaled Monocular direct sparse Odometry)基于DSO在原有的能量函数中增加了距离测量值,减少了直接法能量函数的非凸性带来的影响.这可以理解为式(5)的一种变形,即:
Etotal=Eframe+λ·Edis,
(9)
其中Eframe表示光度误差,Edis是距离误差,λ用来保持Eframe和Edis在一个数量级上.
2 惯性视觉融合
不管特征点法还是直接法要准确地估计出图像之间的变换都需要消耗很大的计算量,所以实际应用中,为了易于工程的实现,一个机器人往往携带多种传感器.由于惯性传感器(IMU)能够在短时间内精确测量传感器的角速度和加速度,但是如果长时间应用累积误差严重.IMU与相机传感器结合,称为视觉惯性里程计VIO (Visual-Inertial Odometry),可以分为基于滤波和基于优化的两大类VIO,也可以根据两个传感器数据应用的方法不同分为松耦合和紧耦合.松耦合是指IMU和相机分别进行位姿估计,紧耦合是指相机数据和IMU数据融合,共同构建运动方程和观测方程进行位姿估计.
现阶段基于非线性优化的方案有VINS-Mono、OKVIS等,还有基于滤波的紧耦合算法,它需要把相机图像特征向量加入到系统的状态向量中,使得状态向量的维度非常高,从而也会消耗更大的计算资源,MSCKF(Multi-State Constraint Kalman Filter)[35]和ROVIO(RObust Visual Inertial Odometery)[36]是其中具有代表性的算法.传统的基于EKF(扩展卡尔曼滤波)的视觉里程计与IMU数据融合时,EKF的更新是基于单帧观测的,每个时刻的状态向量保存的是当前帧的位姿信息、速度、变换矩阵和IMU的误差等,使用IMU做预测步骤,视觉信息作为更新步骤.而MSCKF以类似滑动窗口(sliding window)的形式,使一个特征点在几个位姿都被观察到,从而建立约束,再进行滤波更新,它避免了仅依赖两帧相对的运动估计带来的计算负担和信息损失,大大提高了收敛性和鲁棒性.图8为MSCKF的滑动窗口原理图.
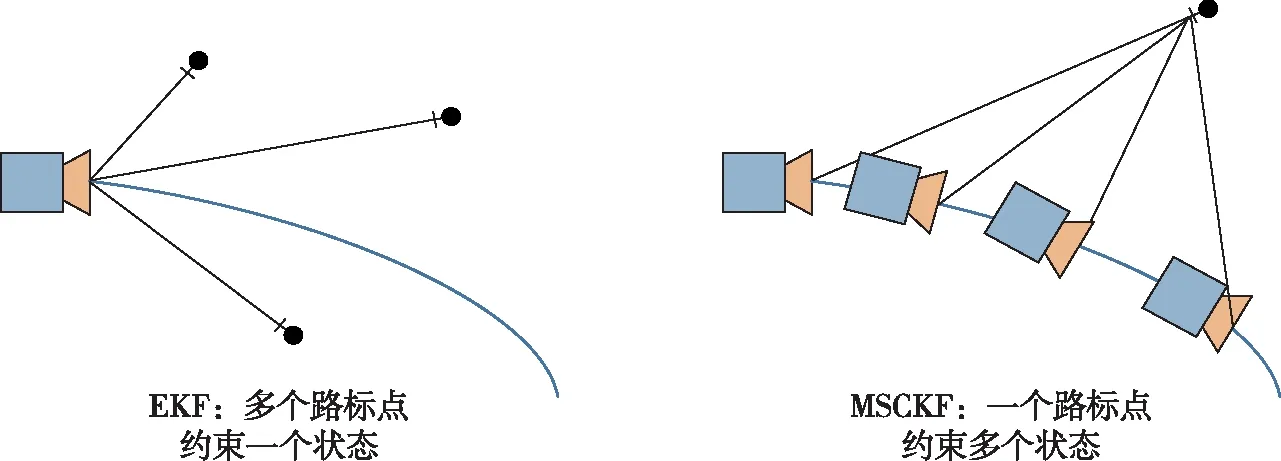
图8 EKF点约束状态与MSCKF点约束状态对比Fig.8 Comparison in point constraining between EKF and MSCKF
ROVIO是一种基于单目相机的EKF滤波VIO,它直接优点是计算量小,但是需要根据设备型号调整到适合的参数,参数也是影响精度的重要因素.ROVIO应用在SLAM系统中时没有闭环,也没有建图的线程,所以误差会有漂移.
针对基于滤波的松耦合,为了降低计算量,通过把图像信息当作一个黑盒,将VO的位姿估计结果与IMU数据进行融合,来减小状态向量维度.是一个很好的思路.
Weiss[37]在他的博士论文中详细介绍了视觉和IMU基于EKF的融合过程以及多传感器下构建的融合框架.其中,Ethzasl_SSF和Ethzasl_MSF都是基于滤波的松耦合中优秀的开源算法.Ethzasl_SSF主要是处理视觉与单个惯性传感器的融合问题,而Ethzasl_MSF 提出了与多传感器融合框架,会使用深度相机、激光、IMU等一系列传感器的数据来最终输出一个稳定的姿态.滤波器的状态向量是24维,如式(10),相比于紧耦合的方法精简很多.
(10)
其中除了不同坐标系变换的位置和四元数之外,还加入了陀螺仪bw和加速度计ba的偏差和,以及单目视觉尺度缩放的视觉比例因子λ.
OKVIS(Open Key-frame-based Visual-Inertial SLAM)[38]和香港科技大学沈邵劼课题组的VINS[39]是基于优化方法的VIO现阶段效果最好的算法.OKVIS是基于关键帧优化的VIO,它将视觉和IMU的误差项和状态量放在一起进行优化.在VO和SLAM中,通过最小化相机帧中观察到的地标的重投影误差来进行非线性优化以找到相机位姿和地标位置.图9上部为纯视觉VO示意图,下部为加上IMU后VO的示意图.IMU对相邻两帧的位姿之间添加约束,而且对每一帧添加了状态量(陀螺仪和加速度计的偏差及速度).对于这样的新结构,文献[38]建立了一个包含重投影误差和IMU误差项的统一损失函数进行联合优化:

图9 OKVIS视觉与IMU的融合结构示意图Fig.9 Structure of OKVIS vision fused with IMU
(11)
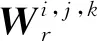
IMU误差项的实现和文献[40]一致,OKVIS优化也是预积分的思路.OKVIS 将前后帧IMU测量值做积分,因为积分会用到 IMU 的偏差,而偏差是状态量,每次迭代时是变化的.所以每次迭代时会根据状态量相对于偏差的雅可比重新计算预积分值,当偏差变化太大时,不能再用雅可比近似计算预积分值,这时会根据IMU测量值重新进行积分.
VINS也是类似的思路.VINS-Mono[39]是VINS开源的单目视觉惯性SLAM方案,是基于滑动窗口优化实现的VIO,使用IMU预积分构建紧耦合框架,是具备自动初始化、在线外参标定、重定位、闭环检测,以及全局位姿图优化功能的一套完整的SLAM系统.该算法的前端(VO)是Harris角点加LK光流跟踪,闭环检测添加了BoW词袋算法.VINS-Mono主要设计用于状态估计和自主无人机的反馈控制,但它也能够为AR应用提供精确定位,与ROS完全集成.此外,团队还开源了IOS版本VINS-Mobile[41],致力于部分AR的APP的研究.
3 基于深度学习的视觉里程计
除了与别的传感器进行融合这一思路之外,由于视觉里程计获得的都是图像信息,而深度学习在对图像识别、检测、分割方面的发展尤为迅速,从而为两者结合提供了良好的基础.深度学习与视觉里程计的多方面都有所结合,相比传统视觉里程计的人工特征,深度学习有着较为优秀的自动特征表征能力,且和直接法一样不需要计算描述子,也不需要传统视觉里程计复杂的工程,比如相机参数标定,各种传统的人工特征或者角点在面临光照变化、动态场景或者是图像纹理较为单一的情况时都有一定的敏感性,对于这些问题,基于深度学习的特征提取技术使得视觉里程计的性能有了一定的改善.用来解决位姿估计问题的深度学习技术大致分为监督学习和无监督学习两种.
监督学习网络中,最开始Kendall等[42]提出PoseNet,他们使用CNN粗略地预测出相机运动的速度和方向,使用SFM自动生成训练样本的标注,在没有大量数据标签情况下,通过迁移学习实现了输出较为精准的位姿信息.Costante等[43]用稠密光流代替RGB图像作为CNN的输入.该系统设计了三种不同的CNN架构用于VO的特征学习,实现了算法在图像模糊和曝光不足等条件下的鲁棒性.然而,同PoseNet一样,实验结果表明训练数据对于算法影响很大.当图像序列帧间运动较大时,算法误差很大,这主要是由于训练数据缺少高速训练样本.
目前效果较好的DeepVO[44],网络结构如图10所示.它能够从序列原始图像直接映射出其对应的位姿,是基于RCNN(递归卷积神经网络)的,它分为两个部分:首先通过卷积神经网络(CNN)学习图像的特征,然后通过深度递归神经网络学习(RNN)隐式地学习图像间的动力学关系及内在联系,运用各种大小的卷积核来更好地提取感兴趣特征使网络能够更好地提取各种特征.通过这种CNN网络学习得到的特征描述不仅将原始的高维RGB图像压缩成一个紧凑的描述,而且提高了后续的连续图像序列的训练效果.将CNN的最后一个卷积层(Conv6)提取到的特征传递给下一部分的RNN,第二部分的RNN为了能够发现和利用图像之间的相关性,使用了一种LSTM(Long Short-Term Memory)在较长的运动轨迹上实现这个目的.它能够随着时间的推移仍然保持隐藏状态的记忆,并且在隐藏状态之间存在反馈回路,使得当前的隐藏状态与之前状态存在的函数关系.因此它能够找出输入图像和姿态之间的联系.RNN在k时刻的状态更新公式如下:

图10 DeepVO结构示意图[44]Fig.10 DeepVO structure[44]
hk=H(WxhXk+Whhhk-1+bh),
(12)
yk=Whyhk+by,
(13)
其中hk和yk为k时刻的隐藏状态和输出,W项表示相应的权矩阵,b项表示偏置向量,H为非线性激活函数(如sigmoid).RNN根据CNN生成的视觉特征,随着相机的移动和图像的获取在每一步输出一个6维姿态估计,包括位置信息和姿态信息.
还有一种不需要数据标签的无监督学习方法,一定程度上解决了监督学习由于缺少训练样本带来的问题.文献[45]通过无监学习的方式进行单一图像的深度估计,该方法采用双目数据集,通过多重目标损失训练网络产生视差图.通过模型的训练,该网络对单个图像深度估计达到高精度,超过了最先进的监督学习方法.Zhou等[46]提出了一种用于深度和相机运动估计的无监督深度学习框架,其深度预测和姿态估计结果较好.
2019年,Liu等[47]创建了一种单目视觉里程计的无监督训练框架,每次位姿估计时无需根据实际值计算尺度因子,而是通过把单目图像和深度信息输入到训练网络来获得绝对尺度.他们的框架不需要相机真实的姿态来训练网络,实际姿态只用来评估系统的性能.该网络基于RCNN的框架,图像通过卷积层提取特征后,把特征输入到LSTM网络中分别输出旋转矩阵和平移向量.为了寻到最优参数,需要最小化损失函数,其描述了RCNN生成的姿态与预期结果之间的距离.利用RCNN得出的变换矩阵和对应的点云值计算二维空间损失函数和三维空间损失函数.对于二维损失函数,首先通过变换矩阵和深度值把当前帧It的点投影到下一帧It+1,于是得到一个新帧I′t,二维损失函数如式(14)所示.三维损失函数是把当前帧的点云Ct变换到相邻帧后得到C′t,计算变换前后点云图的差距,如式(15)所示.最终通过加权系数λ2D和λ3D融合两个损失函数,如式(16)所示.
(14)
(15)
L=λ2DL2D+λ3DL3D.
(16)
现阶段基于深度学习的VO并不能取代传统的基于几何方法的VO,而是一种可行的补充.因为深度学习提取得到的都是表象特征,但几何特征对VO是至关重要的.
4 标志性视觉里程计系统归纳
目前的基于传统视觉里程计框架的算法中,ORB-SLAM2[48]应对各种场景已经有了较好的鲁棒性和实时性,但是面对光照变化大、图像纹理信息较少的情况或者在动态场景中,传统VO框架无法很好地发挥作用.使用点线特征结合的PL-SLAM使得ORB-SLAM2不管是否缺少纹理特征信息都能精确地估计位姿.而当面对动态环境时本文综述了两个思路.一是不考虑计算成本只求精度的时候,可以使用DeepVO、SFM-Net等基于深度学习的高性能的视觉里程计,而有些问题,误差由于VO只用相机获取信息的途径而无法消除避免,多传感器融合可以很好的减小此类问题对定位带来的影响,例如MSCKF.表2中分析了现有的VO算法的贡献和特点,包括视觉惯性传感器融合和基于深度学习的视觉里程计算法.表3中收集各类VO算法的开源代码.

表2 优秀VO算法的贡献和特点

表3 各类开源VO系统实现代码地址表
5 总结与展望
本文对视觉里程计的三个模块即像素跟踪模块、外点排除模块和位姿估计模块进行了综述,介绍了近几年的视觉里程计算法.其中着重介绍了像素跟踪模块,包括传统的基于点特征法和直接法的视觉里程计(VO),还对比较新颖的线特征和线特征运用在VO系统中的优势进行了介绍.在外点排除和运动估计模块简略地介绍了相关理论知识.最后结合最新的算法详细介绍了当前较为火热的两个VO发展趋势,即以视觉惯性传感器融合为例的多传感器融合的SLAM前端算法,以及基于深度学习的视觉里程计.
挑战和机遇是一对“双胞胎”,VO技术也是如此,面临挑战时往往会带来机遇.未来视觉里程计可能的发展趋势如下:
1)结合地图语义信息.由于环境中普遍存在动态场景造成的实际样本和检测样本之间误差降低了目前大部分的算法模型的位姿估计和轨迹的精度,通过结合语义地图的方式将从几何和语义两个方面来感知场景,使得应用对象对环境内容有抽象理解,获取更多的信息,从而来减小动态场景带来的误差,还可以为SLAM中的回环检测带来更多信息从而提高精度,但是计算成本会增加很多.适合通过高性能的计算设备用于实现精密地图构建、场景理解等功能的场合.
2)多机器人协同的视觉里程计系统.单个机器人可能无法快速熟悉环境特征及其相对于环境特征的位置,也可能在执行任务的过程中损坏.为了稳定的精准导航,开发分布式系统来实现视觉里程计将是一个发展方向.使用多个机器人可以有很多优点,例如可以减少探索一个环境所需的时间、不同的信息来源将提供更多的信息、分布式系统对故障更健壮等.但是多个机器人VO的缺点就是必须将每个机器人生成的地图合并成一张全局地图,同时还需要自我定位与其他机器人协作.由于单个地图以及机器人之间的相对姿态的不确定性,使得地图合并变得更加困难.
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
福建基础教育研究(2019年6期)2019-05-28
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
