
基于CGRA的神经网络高效数据流设计
2021-06-28 08:50李泽豪程利甫蒋仁兴柳宜川王琴
电子测试 2021年1期
李泽豪,程利甫,蒋仁兴,柳宜川,王琴
(1.上海交通大学电子信息与电气工程学院,上海,200240;2.上海航天电子技术研究所,上海,201109)
0 引言
近年来,人工智能已经深入到人们生活中的每一个角落,现有的各类神经网络架构的计算量级达到了GB级别,网络中权重个数也在百万数量级,这导致对神经网络运算的硬件载体的算力和存储带宽要求更加严格。传统的基于冯诺依曼结构的CPU已难以满足要求,GPU和专用集成电路虽然可以大幅度提升运算速度,但分别由于功耗问题和灵活性问题导致其适用范围比较局限,因此兼具灵活性和低功耗的粗粒度可重构架构[1][2]逐渐成为了研究热点。
本文结合了脉动阵列的思想,设计了神经网络核心算法各个尺寸卷积操作的高效数据流,在保证PE利用率和运算吞吐率的同时保证了配置的可重用特性。
1 通用CGRA阵列架构
粗粒度可重构架构的核心计算资源是通过可重配置的互连网络连接而成功能单元阵列,如图1所示,可以将应用中的计算密集型任务、控制密集型任务或是数据密集型任务放置与阵列中进行硬件加速。

图1 通用CGRA架构
本文搭建的CGRA架构中有4个相同的PEA阵列,每个PEA阵列由64个异构PE组成,处理单元包括ALU、LSU、MUL、MAC等功能,如图2所示。可以看到,每个PE有四根输入线,分别是32bits位宽的IN1、IN2、IN3,以及1bit位宽的单比特控制信号IN4,输出有三根数据线,分别是32bits位宽的OUT1和OUT2,以及1bits位宽的输出控制信号线。Opcode输入控制PE功能与外部线连接。其中具有LSU功能,能够访问片上存储的PE单元分布在阵列四周。

图2 卷积窗口3*3数据流(a)权重参数(b)输入特征图数据(c)卷积部分和
1.1 阵列路由层次结构
目前的CGRA架构设计中,往往会在mesh结构的基础上,扩展PE的互连能力[4][5],使得PE能够与不相邻的PE进行数据传输,从而使PE阵列更适合流式处理以达到更高的吞吐率。
本文所搭建的粗粒度可重构架构中,处理单元阵列尺寸为8*8,阵列由64个异构处理单元组成。阵列边沿的PE可以与之横向或者纵向距离为3以内的PE进行单周期的数据传输,并能够与其距离为7的PE进行单周期数据传输。
1.2 阵列存储层次结构
目前针对神经网络这类数据密集型和计算密集型的应用,往往会给每个PE配备一个单独的存储块[3]用于存储频繁使用的操作数或者存储临时数据,以降低花费在访问外部存储中的时间。通用目的架构为了在各个应用场景达到最高的平均能效,往往不会单独为每个PE配置较大的存储空间,替代的则是小型用于少量局部数据存储的LR(local register),本文所用架构的局部寄存器为每个PE提供了深度为16,位宽为32bits的可利用空间。
8*8的阵列结构被分为了四块,每一块配备了深度为8的,可供16个PE同时访问的区域寄存器,以实现区域性的数据传输。另外,所搭建的架构提供了可供阵列上所有PE访问的8个全局寄存器。
2 数据流设计
2.1 阵列卷积设计
卷积所实现的功能类似于滤波操作,通过Nout个大小为w* h * Nin的三维卷积核W,在输入特征图I上以固定步长的滑窗操作遍历整个输入特征图,每次滑窗操作会将卷积核各个位置的权重与其在特征图中的数据相乘,再将所有乘数相加得到输出特征图A中的一个数据,过程可表示为:

公式中⊗代表一次二维卷积操作,B为偏置。目前主要的卷积窗口尺寸分别为3*3、5*5以及7*7,因此主要针对这三种卷积窗进行映射数据流设计。
对于3*3尺寸的卷积操作,每次计算实际上需要18个独立的操作数,主要使用到的计算为乘加运算,完成一个卷积结果的输出需要9次乘法和8次加法。在映射方案中,考虑到18个操作数中的权重所占的9个操作数可以重复利用,这部分操作数则预先通过配置放到了每个PE独有的Local Register中,待遍历完输入特征图之后再更新,这使得每次运算需要的新操作数从18个降低为9个。图2(a)为更新各个PE的Local register的更新路径,由绿色线条表示。模拟卷积操作的滑动窗口的滑动状态,可以发现相邻两次滑动窗口中有6个数可重复利用,应用到PE阵列中,设计方案使用脉动阵列的方式来模拟滑动窗口的滑动过程,在传递单次乘法计算结果的同时通过OUT2输出接口传递IN1的输入数据,这种数据传输方式,只需要逐周期传入输入特征图的3行数据,将前几个周期传入的输入数据继续保留在阵列中传输,待流水线填充完成则可以将单个卷积结果所需要的新数据降低到3个。计算模式如图2所示,计算结果从左至右传递,原始计算操作数从上至下传递,红色线条为计算结果输出路径,蓝色线条为原始操作数通过脉动阵列传输的路径。
输出的3个部分和使用额外的两个PE做加法完成整个二维卷积窗口的计算结果,但脉动阵列的处理方式下,这3个结果之间相隔5个周期,无法通过简单的路由完成周期对齐。为解决这个问题,设计了通过LR加上一个简单路由功能PE可以完成5周期的缓冲PE。
这种计算模式下,数据的初始填充间隔周期为56个周期,流水线填充完毕后,每个周期可输出一个卷积计算结果。并且将访存带宽需求缩小为原有需求的1/6,可以大幅度降低访存功耗,PE利用率达98.4%,有效计算PE占比达70%。5*5和7*7卷积窗口的数据流设计思路与上述类似。
2.2 阵列池化设计
池化层实质为一个下采样层,目的是降低特征图的尺寸以实现特征图的主要特征提取,并同时简化网络计算复杂度。常用的池化算子包括最大值池化和均值池化,池化操作将输入特征图分为多个K*K大小的区域,将其中的最大值或者区域内数据均值作为输出。
阵列数据流设计如图3所示为2*2池化,图中黑色线条表示传入的数据流,红色线条表示通过减法PE得到的单比特控制信号,用于select功能PE选择数据输出。通过使用可供片上协处理器控制的全局寄存器控制功能单元每个功能的迭代次数可以完成同一配置在不同尺度输入特征图上的共用,可大幅度减少读取配置所需的访存时间和功耗。

图3 阵列池化数据流
2.3 多阵列协同工作
由于片外存储数据的读写为数据密集型应用的瓶颈所在,CGRA的计算资源和片上存储大小及数据带宽的不匹配问题往往是限制架构性能的关键,数据带宽并不能像计算资源一样通过堆叠提高,而片上存储的增大会提高芯片功耗。通过多阵列协同工作,利用合理的片上数据复用,平衡片外存储访问与计算时间,可以最大化释放阵列处理单元的计算能力。
如图4所示,相邻的两个PEA之间可以共用一个片上存储块,将初始计算操作数依次写入各个片上存储的同时,依次启动各个阵列进行计算,使各个阵列之间形成一个广义的流水线,计算结果通过SM1输出。各个存储块分别有16个bank可同时被阵列上的访存单元读写,通过地址增加方式的改变,可将片上存储以8个bank分为两组,两个PEA阵列在同一时刻分别访问一组,以乒乓模式对两组存储进行读写,可保证在两个阵列同时运行时阵列之间不发生访存冲突。

图4 多阵列协同工作
3 实验结果与分析
为了验证所设计数据流的性能,本文在VCS上搭建了上述通用粗粒度可重构架构的RTL仿真环境。
通过将64*64尺寸的特征图分别进行3*3卷积、5*5卷积、7*7卷积以及池化窗口2*2的最大值池化,比较在CGRA平台和使用Intel Core i5-8500型号CPU平台的运行时间,具体运行结果如表1,发现针对各个尺寸的卷积,CGRA架构相对于CPU架构的平均加速比可达732倍,其中3*3卷积窗口使用了4个不同的卷积核,因此CPU时间为单个卷积核的4倍。对于2*2池化窗口的最大值池化操作,加速比也可达412倍。
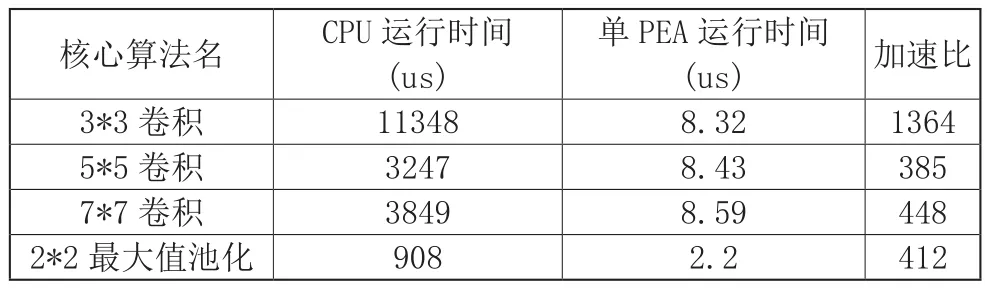
表1 核心算法在单PEA和CPU的运行性能比较
在Pytorch平台载入AlexNet模型预训练权重后,通过量化将浮点数转为32bits定点数据,将AlexNet各个尺寸的卷积层通过上一节描述的方式映射到整个CGRA中,由于神经网络类应用对片上存储需求较高,为了验证阵列数据流的极限性能,仿真过程中将片上存储限制放宽,预设了足够放置所有权重和中间数据的存储空间。在500MHz的时钟频率下,峰值计算性能可达379.11GOP/s,平均计算性能可达238.37GOP/s。
将此峰值性能与现有的卷积神经网络FPGA加速器做比较,其中FPGA[6]工作时钟为100MHz,FPGA型号为Virtex-7 VX485T,FPGA[7]的工作时钟评论为156MHz,型号为Virtex-7 VX690T,FPGA[8]工作频率为150MHz。可以看到针对AlexNet网络模型,CGRA的计算性能相比于FPGA加速器处于劣势,这是由于CGRA在计算过程中需要更换配置达到重构以切换数据地址以及权重,这个过程需要消耗额外的时间,并且重新提取权重进入阵列之后,流水线需要重新填充。
计算性能上的劣势除了重构时间造成,还由片上计算资源决定,若将FPGA的DSP个数与CGRA的PE个数做等效处理,那么从单个计算单元的执行效率来看,CGRA比FPGA更高,并且CGRA拥有动态可重构的特性。因此,在CGRA的片上存储资源足够大的情况下,相比于FPGA实现,本文的数据流映射方式使CGRA的计算单元能够得到更有效的利用。
4 结语
本文针对神经网络类应用核心算法特点,结合脉动阵列的思想在通用粗粒度可重构架构的处理单元互连特性下,设计了一套高效的映射数据流,设计方案在配置文件层提供了处理器参数控制接口,在不更换配置文件的情况下适用于不同输入特征尺寸图像,并可作为映射模板嵌入到大型网络应用映射流程中。本文搭建了通用粗粒度可重构架构的RTL仿真环境,在该环境下针对神经网络核心算法进行仿真和性能评估,验证了数据流方案的高效性,通过比较相同算法在CPU平台和仿真平台的运行时间,结果显示所设计的数据流可以达到平均652倍的应用加速比。在片上存储资源足够的情况下,本文的数据流设计使得计算单元的执行效率高于FPGA实现方式。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
哈尔滨工业大学学报(2022年5期)2022-04-19
软件导刊(2022年3期)2022-03-25
摄影世界(2022年1期)2022-01-21
新一代信息技术(2021年22期)2021-12-29
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2019年1期)2019-01-21
知识经济·中国直销(2018年12期)2018-12-29
商周刊(2017年6期)2017-08-22
