
基因组功能注释分析米曲霉ZA189优势酿造性能的遗传基础
2021-06-30 15:42侯莎吴昌正潘力王斌
现代食品科技 2021年6期
侯莎,吴昌正,潘力,王斌
(1.华南理工大学生物科学与工程学院,广东广州 510006)(2.广东海天创新技术有限公司,广东佛山 528000)
目前我国酱油生产绝大多数采用的是上海市酿造科学研究所1958年研发获得的米曲霉沪酿3.042,其初始菌株来源于福建省永春县酱园,中科院编号为AS3.863。米曲霉沪酿3.042是以AS3.863为出发菌经过紫外诱变获得的。该菌具有分子孢子量大、繁殖速度快、抗杂菌生长能力强、易制曲、培养粗放、蛋白酶活力较高及综合酶系分泌丰富等特点。根据统计结果显示,目前我国90%的酱油企业仍然沿用此菌种。第一株完成全基因组测序的米曲霉菌株是RIB40,由日本学者于2005年完成,基因组大小为37 Mb,共8条染色体,包含12074个基因[1]。截至目前共有10株米曲霉的基因组被测序[2]。沪酿3.042的基因组测序工作,由天津科技大学曹小红课题组在2012年完成,基因组全长36.6 Mb,注释基因11639个,与RIB40比较发现沪酿3.042基因组中参与转运系统、酯类形成和氨基酸代谢等功能的数百个基因存在差异,这些差异是两种菌株发酵风味差异的遗传基础[3]。
Oxford Nanopore Technologies技术(ONT测序)是新一代基于纳米孔的单分子实时电信号测序技术[4],目前主要包括三种平台(MinION、GridIONx5、PromethION),其测序原理是相同的:DNA/RNA链在马达蛋白的带领下与镶嵌在生物膜上的纳米孔蛋白结合并解螺旋,在生物膜两侧电压差的作用下DNA/RNA链以一定的速率通过纳米孔通道蛋白,由于DNA/RNA碱基化学性质的差异,当其通过纳米孔通道时将引起电化学信号的变化[5],通过对电信号的检测及转换,可获得相应碱基类型的信息,从而完成测序[6]。其特点是测序读长长(超过150 kb),测序速度快,测序数据实时监控。基于该方法已实现多种微生物基因组的测序工作,发表相关文章300余篇。
米曲霉ZA189菌株是以沪酿3.042为出发菌株,采用常压室温等离子体(Atmospheric Room Temperature Plasma,ARTP)诱变获得的突变菌株。与出发菌株相比,ZA189制曲获得的成曲中,中性蛋白酶、淀粉酶及谷氨酰胺酶活力均有所提高,发酵原油中氨基酸态氮、全氮、还原糖和谷氨酸均有所提高,而且更适用于酱油现代化圆盘工艺和大罐生产,所得原油味道更浓郁,色泽更鲜明,具备酱香浓郁,鲜甜突出,滋味醇厚持久。
本研究利用ONT测序技术对米曲霉ZA189进行全基因组测序,对其基因组序列进行组装、注释,并进行功能注释和分析,在此基础上分析该菌的胞外水解活力、安全性等特征,为指导其在酱油酿造中的应用提供数据支持。
1 材料与方法
1.1 菌株及培养基
菌株:ZA189,由沪酿3.042经诱变获得。
培养基DPY:2%(W/V)葡萄糖,1%(W/V)蛋白胨,酵母粉和KH2PO4各0.50%(W/V),0.05%(W/V)MgSO4·7H2O,2%琼脂(W/V)、pH 5.0。
1.2 试剂及仪器设备
1.2.1 试剂
苯酚:氯仿:异戊醇(25:24:1)(索莱宝);Tris-base(sigma);SDS(sigma);琼脂糖(sigma);EDTA(国药试剂);SQK-LSK109连接试剂盒(Oxford Nanopore Technologies)。
溶菌缓冲液:Tris-HCl 50 mM,EDTA 50 mM,SDS 3%(W/V),pH=8.0,高温高压灭菌后保存使用。
1.2.2 主要仪器设备
生化培养箱,上海一恒科学仪器有限公司;超净工作台,苏州净化设备有限公司;小型离心机,德国Eppendorf 公司;低温冷冻离心机,德国Eppendorf公司;水平电泳系统,美国BIO-RAD公司;凝胶成像系统,美国BIO-RAD公司等。
1.3 实验方法
1.3.1 米曲霉培养
取冰箱冻存的ZA189孢子(约107/mL)500 μL到加有玻璃纸隔离的DPY平板上,30 ℃恒温培养24 h至长出丰富菌丝。
1.3.2 基因组DNA的提取
用灭菌的药匙刮取菌丝,将菌丝转移至研钵(提前液氮预冷)中,液氮研磨成粉末(需研磨充分)。称取适量粉末(3 g)加入到65 ℃预热的溶菌缓冲液(1.5 g/10 mL)中。65 ℃孵育0.5 h,每隔5 min用5 mL去尖枪头轻轻混匀。加入等体积的DNA提取液,轻轻颠倒混匀,12000×g,4 ℃离心10 min。取上清(切勿吸到中间层白色沉淀),加入等体积氯仿,轻轻颠倒混匀,4 ℃ 12000×g离心10 min。取上清,加入2.5倍体积预冷的无水乙醇,-20 ℃沉淀DNA 2 h左右。12000×g,4 ℃离心15 min,去除上清,用70%(V/V)无水乙醇洗涤沉淀2次。适量水溶解DNA,加入1%体积的RNA酶处理30 min,通过凝胶电泳检测提取的基因组质量。
1.3.3 基因组DNA质量检测、文库构建及测序
实验流程按照Oxford Nanopore Technologies(ONT)公司提供的标准 protocol执行(https://nanoporetech.com/),包括样品质量检测、文库构建、文库质量检测和文库测序等流程,文库构建包括如下步骤:(1)提取高质量基因组DNA,利用Nanodrop、0.35%琼脂糖凝胶电泳进行纯度、浓度和完整性质检;(2)BluePippin全自动核酸回收系统回收大片段DNA;(3)文库构建及测序(SQK-LSK109连接试剂盒):①大片段DNA的获得:提取高质量的DNA,样本质检合格后,对基因组DNA进行随机打断;利用磁珠富集、纯化大片段DNA,将大片段进行切胶回收;②片段修复:对筛选好的大片段DNA进行损伤修复、末端修复及3'末端加A,并对反应产物进行纯化;③连接反应:片段修复产物进行测序相关接头的连接及纯化,得到最终的上机测序文库;④定量检测:用Qubit精确地对建好的DNA文库进行定量检测;⑤文库上机:取一定量的DNA文库,与上机相关试剂混合后加入Flow cell中,利用PromethION测序仪进行实时单分子测序,获得原始测序数据。
1.3.4 基因组测序数据的组装
测序获得的原始序列,需要进行质控、组装、注释等,才能获得生物学相关信息,分析生物学功能。
(1)原始数据质控:测序原始数据格式为包含所有原始测序信号的二进制fast5格式,通过MinKNOW软件包中的Albacore软件进行base calling后会将fast5格式数据转换为fastq格式,经进一步过滤接头、低质量及短片段(长度<2000 bp)的reads后,得到总的数据集。
(2)基因组组装:使用Canu v1.5[7]软件对过滤后subreads进行纠错,然后使用NECAT软件对纠错后的subreads进行组装,最后采用Pilon v1.22[8]软件利用二代数据进一步对组装基因组进行纠错,得到最终准确度更高的基因组。
1.3.5 数据处理
1.3.5.1 基因预测及功能注释
(1)基因预测:蛋白编码基因预测主要采用从头预测、基于同源蛋白预测,然后对2种预测结果进行整合。使用Genscan v1.0、Augustus v2.4、GlimmerHMM v3.0.4、GeneID v1.4、SNAP (version2006-07-28)进行从头预测;使用GeMoMa v1.3.1进行基于同源蛋白的预测。最后利用EVM v1.1.1整合上述2种方法得到的预测结果,并用PASA v2.0.2进行修饰。使用软件tRNAscan-SE v1.3.1预测基因组中的tRNA,使用软件Infernal v1.1基于Rfam v12.0数据库预测基因组中的rRNA。
(2)基因功能注释:利用预测得到的基因序列与KOG、KEGG、Swiss-Prot (2015_01)、TrEMBL、Nr等功能数据库做BLAST(v2.2.29)比对,得到基因功能注释结果并进行功能富集分析。利用软件hmmer v3.0基于Pfam(27.0)数据库进行Pfam功能注释。利用软件hmmer基于碳水化合物相关酶数据库(CAZy[9])(http://www.cazy.org/)进行碳水化合物酶类基因的功能注释。
1.3.5.2 胞外分泌蛋白及蛋白酶分析
(1)信号肽预测:使用软件SignalP 4.0对所有的预测到的基因的蛋白序列进行分析,找出含有信号肽的蛋白。
(2)跨膜蛋白预测:使用软件tmhmm v2.0对所有预测基因的蛋白序列进行分析,找出含有跨膜螺旋的蛋白,即为跨膜蛋白。
(3)分泌蛋白预测:在上述预测的含有信号肽的蛋白中去除含有跨膜螺旋的蛋白,剩余的蛋白即为分泌蛋白。
(4)蛋白酶分析:根据基因功能注释的结果,从分泌蛋白中筛选出蛋白酶基因,对其进行功能聚类分析。
2 结果与讨论
2.1 米曲霉ZA189测序数据质控与基因组组装
Nanopore测序的下机数据的原始数据经格式转换、过滤接头、过滤低质量及短片段后,得到4,872,627,875 bp高质量测序数据集,测序深度为132.05×。将reads按照不同梯度长度分布统计(图1),其中10 kb~20 kb和20 kb~30 kb之间分布的reads最多,分别为39.43%和25.12%。

图1 米曲霉ZA189基因组测序reads长度分布统计Fig.1 Length distribution of sequencing reads in the genome of A. oryzae ZA189
利用过滤后的高质量测序数据,使用NECAT软件进行基因组组装,最后采用Pilon软件利用二代数据进一步对组装基因组进行纠错,得到高准确度的基因组,组装得到完整基因组总长36.89 Mb,Scaffold数目为16条(米曲霉为8条染色体),scaffold N50长度为2.37 Mb。而出发菌株沪酿3.042测序全长36.6 Mb[3],米曲霉ZA189基因组相比出发菌株增加的序列(0.29 Mb)可能是序列插入或者片段重复导致的。
2.2 米曲霉ZA189基因组中的基因注释
蛋白编码基因预测主要采用从头预测和基于同源蛋白预测,然后对2种预测结果进行整合,共预测得到12,468个米曲霉基因(表1)。ZA189基因组中编码蛋白基因的长度为24,760,823 bp,平均长度为1,986 bp,占基因组长度67.10%,其中外显子区总长度占60.54%,内含子区长度占6.57%(表2)。出发菌株沪酿3.042则预测到11379个基因,外显子区总长度为44%[3],基因数量和外显子长度比例的差异,一方面是测序技术和分析手段的进步引起的,另一方面也体现了ZA189优势酿造性能的分子基础。
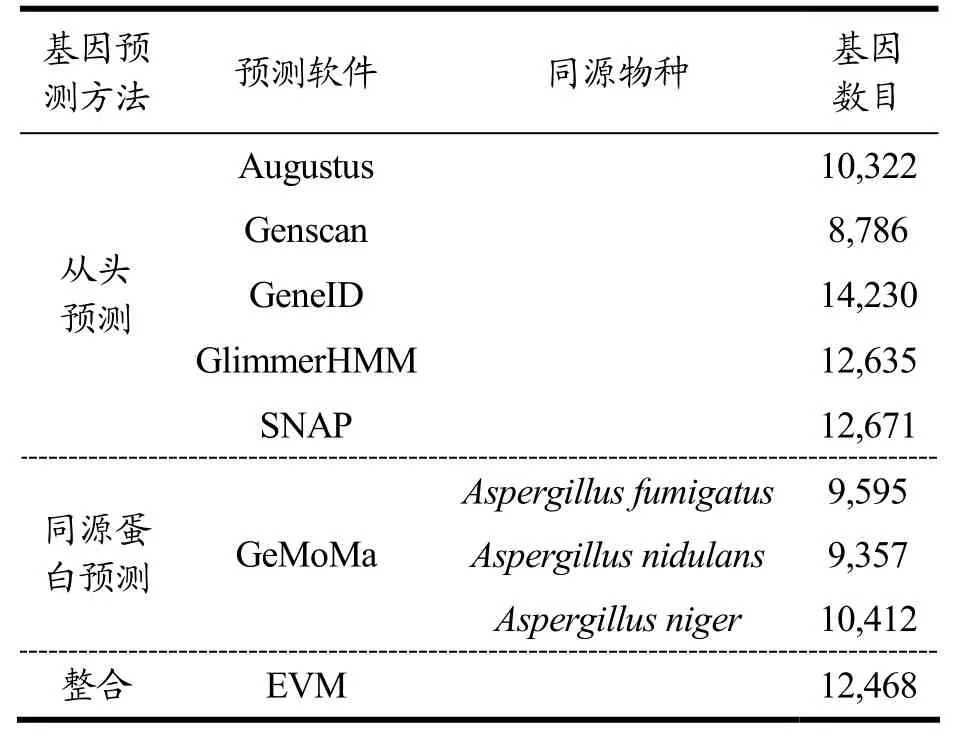
表1 米曲霉ZA189蛋白编码基因的预测Table 1 Prediction of protein-coding genes in A. oryzae ZA189

表2 基因信息统计Table 2 Statistics of gene information
非编码RNA即不编码蛋白质的RNA,包括microRNA、rRNA和tRNA等多种已知功能的RNA,针对非编码RNA的结构特点,采用不同的策略预测不同的非编码RNA。在米曲霉ZA189基因组中,共预测得到263个tRNA、72个rRNA。而出发菌株沪酿3.042则预测到243个tRNA[3],丰富的蛋白质翻译相关RNA基因的存在,表明ZA189具有大量表达蛋白质的遗传基础。
2.3 米曲霉ZA189基因组的功能注释
ZA189相比出发菌株沪酿3.042酶活力更高,根据项目组前期研究,ZA189应用于酱油发酵中(表3所示),制曲阶段孢子数和原料消耗率显著低于出发菌株沪酿3.042(p<0.05),中性蛋白酶活力和淀粉酶活力分别达到3 210.21 U/g和480.29 U/g,谷氨酰胺酶活力达到3.48 U/g,较出发菌株提高38%;发酵原油的氨基酸态氮含量为1.16 g/100 mL、全氮含量为1.94 g/100 mL、还原糖含量为11.05 g/100 mL、谷氨酸含量为13.69 g/kg,均高于出发菌株沪酿3.042[10]。
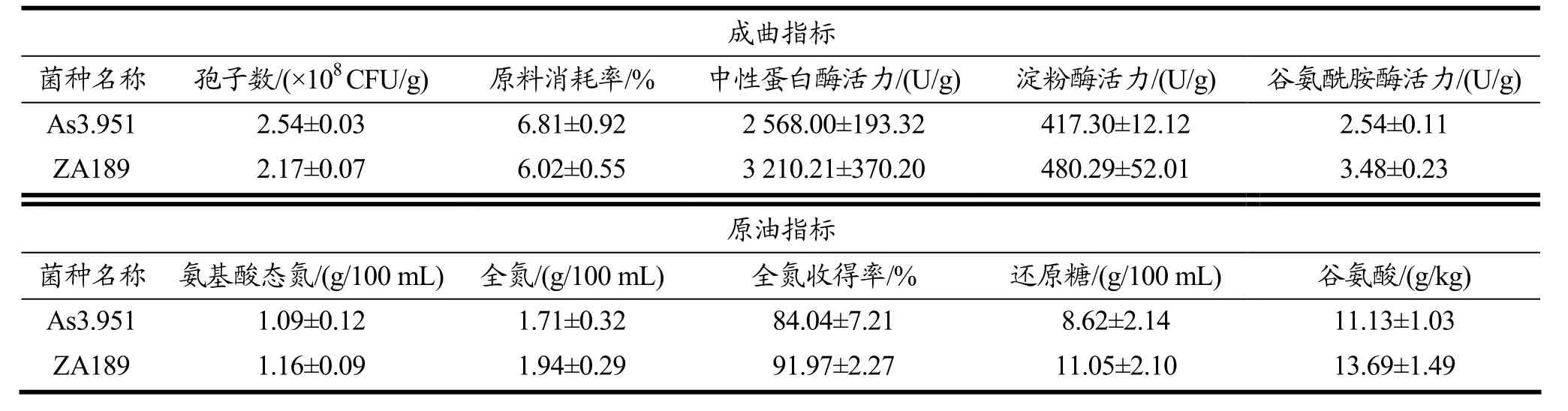
表3 ZA189发酵性能分析[10]Table 3 Fermentation feature analysis of ZA189
对米曲霉ZA189基因组注释的基因进行KOG功能注释(图2),其中以下功能类群富集了大量功能基因:C-能量生产与转换(Energy production and conversion)、E-氨基酸的运输与代谢(Amino acid transport and metabolism)、G-糖运输与代谢(Carbohydrate transport and metabolism)、I-脂肪运输与代谢(Lipid transport and metabolism)、O-翻译后修饰(Posttranslational modification,protein turnover,chaperones)、Q-次级代谢(Secondary metabolisms biosynthesis,transport and catabolism)、T-信号传导(Signal transduction mechanisms)、U-胞内囊泡转运及分泌(Intracellular trafficking,secretion,and vesicular transport)。类群C、E、G、I、O、U富集大量的功能基因,表明米曲霉具有强大的能量合成能力、蛋白质合成及转运的能力,这是其在发酵工业广泛应用的遗传基础[11]。类群Q富集大量基因,表明米曲霉具有较强的次级代谢产物合成能力,这为米曲霉产生多种多样的风味功能物质提供了可能。
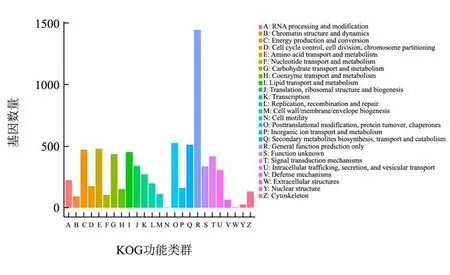
图2 米曲霉ZA189基因的KOG功能注释分析Fig.2 KOG functional annotation of genes in A. oryzae ZA189 genome
对米曲霉ZA189基因组注释的基因进行KEGG途径分析(图3),以下途径富集了大量功能基因:内质网中的蛋白处理(Protein processing in endoplasmic reticulum)、剪接体(spliceosome)、RNA转运(RNA transport)、核糖体(Ribosome)、氧化磷酸化(Oxidative phosphorylation)、氨基酸生物合成(Biosynthesis of amino acids)、碳代谢(Carbon metabolism)、嘌呤代谢(Purine metabolism)。图4、图5反映了氧化磷酸化、核糖体上的基因富集情况。这与KOG功能富集分析的结果是一致的,说明米曲霉在能量代谢、蛋白质合成、碳代谢(与生长相关)方面具有遗传优势。此前关于米曲霉酿造模式菌株RIB40转录组研究的结果表明,与能量代谢、蛋白质合成等相关的基因在固体发酵条件下具有高的转录表达水平[12],也说明米曲霉在基因组上与能量代谢、蛋白质合成相关优势也体现在了实际的发酵应用中。
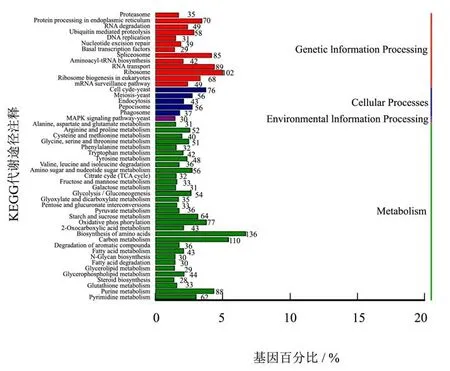
图3 米曲霉ZA189基因的KEGG代谢途径注释Fig.3 KEGG pathway analysis of annotated genes in the genome of A. oryzae ZA189

图4 氧化磷酸化途径上富集的米曲霉ZA189基因Fig.4 Annotated genes of A. oryzaeZA189 enriched in oxidative phosphorylation
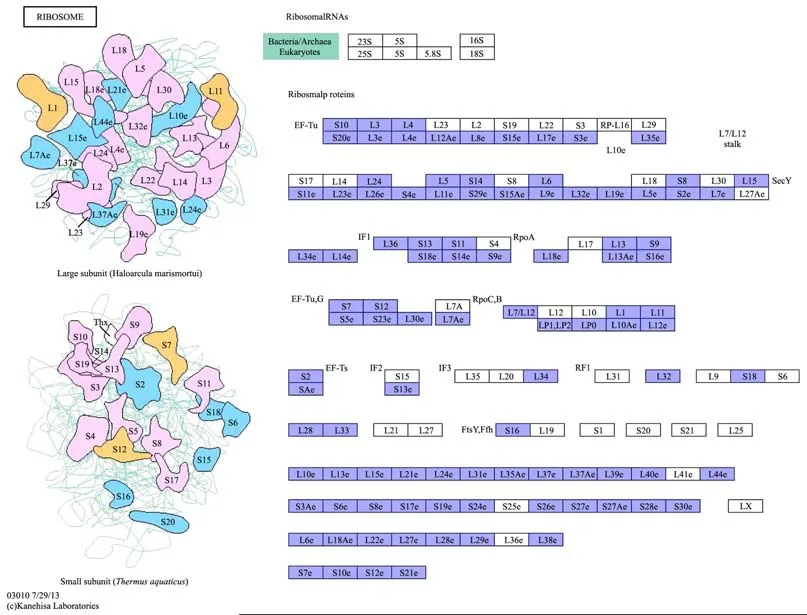
图5 核糖体上富集的米曲霉ZA189基因Fig.5 Annotated genes of A. oryzaeZA189 enriched in ribosome
2.4 米曲霉ZA189的碳水化合物活性酶
碳水化合物活性酶(Carbohydrate-Active enZYmes,CAZy),主要包含与糖苷键降解、修饰及生成相关的酶类家族。碳水化合物活性酶数据库,主要包含5大分类:糖苷水解酶(Glycoside Hydrolases,GHs)、糖基转移酶(Glycosyl Transferases,GTs)、多糖裂解酶(Polysaccharide Lyases,PLs)、碳水化合物酯酶(Carbohydrate Esterases,CEs)、辅助活性酶(Auxiliary Activities,AAs)。此外,该数据库还包含与碳水化合物结合相关的酶(Carbohydrate-Binding Modules,CBMs)。将米曲霉ZA189基因组预测基因的蛋白序列,利用软件hmmer基于碳水化合物相关酶数据库(CAZy)进行碳水化合物酶类基因的功能注释(图6),结果显示米曲霉ZA189基因组中包含多达330个糖苷水解酶(GH)基因,占CAZy酶总数的42.69%,这为米曲霉糖苷水解酶的开发利用提供了基础数据,这也与ZA189在酱油成曲阶段高淀粉酶活的特性密切相关。例如,Gomi K等从米曲霉中制备了分泌表达的糖苷水解酶GH3,并对其进行了酶学性质研究[13],Tang,C.D.等人的研究表明米曲霉的糖苷水解酶可以用于魔芋粉的水解以及作为饲料添加剂[14]。
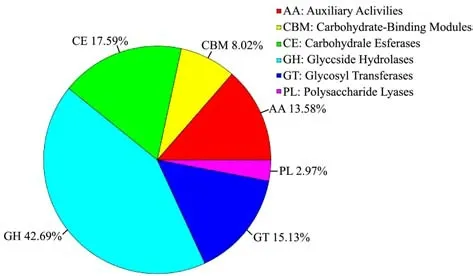
图6 米曲霉ZA189基因组的碳水化合物活性酶(CAZys)Fig.6 Carbohydrate-Active enZYmes (CAZys) annotated in A.oryzaeZA189 genome
2.5 米曲霉ZA189基因组中的蛋白酶的功能分析
利用SignalP 4.0软件预测米曲霉ZA189基因组注释的基因,共获得1224个具有信号肽的基因,利用tmhmm v2.0软件预测跨膜蛋白,在米曲霉ZA189基因组中共找到2668个跨膜蛋白基因。从具有信号肽的1224个基因中去掉包含的跨膜蛋白基因,剩余的基因基因即为分泌蛋白基因,共888个。根据Nr基因功能注释的结果,确定了分泌蛋白中的30个蛋白酶基因(表4),包括2个中性蛋白酶、2个碱性蛋白酶,还有氨肽酶、羧肽酶、内肽酶等。若以活性中心来划分,包括2个金属蛋白酶、4个丝氨酸蛋白酶、5个天门冬蛋白酶氨酸酶四大类。在沪酿3.042和采用N+离子注入方式诱变获得的菌株100-8中,分析到25种蛋白酶基因[15]。因此,可看出ZA189菌株具有更多蛋白酶基因,使其具有高水平分泌表达大量蛋白酶的潜力,这是由其制备的成曲中蛋白酶活力提升的原因,也是其作为酱油酿造菌株降解大豆蛋白的关键性能指标[16]。

表4 米曲霉ZA189基因组中的蛋白酶Table 4 The proteases annotated in the genome of A. oryzae ZA189
3 结论
本研究利用新一代纳米孔测序技术完成了米曲霉ZA189基因组的测序、组装和功能注释。获得的基因组全长36.89 Mb,包含16条Scaffold,测序深度达到132.05×,所得基因组在完整性和质量上达到米曲霉模式菌株RIB40的基因组质量水平。基因注释表明,米曲霉ZA189基因组包含丰富的tRNA和rRNA基因,这是米曲霉高效表达蛋白的遗传基础。KOG和KEGG注释表明米曲霉ZA189具有强大的能量合成、蛋白质合成及次级代谢产物合成能力,这是其在发酵工业广泛应用并产生多种风味功能物质的遗传基础。碳水化合物活性酶CAZy注释和蛋白酶注释表明,米曲霉ZA189基因组中包含多达330个糖苷水解酶(GH)和30个蛋白酶基因,这是米曲霉ZA189作为酱油酿造菌株高蛋白酶活、淀粉酶活和谷氨酰胺酶活的分子基础。通过本研究对酱油酿造菌株米曲霉ZA189的基因组及其功能有了更加深入的理解,为指导其在酱油酿造中的应用提供了理论支持。
猜你喜欢
今日农业(2021年11期)2021-08-13
猪业科学(2021年3期)2021-05-21
幽默大师(2020年10期)2020-11-10
中西医结合肝病杂志(2020年2期)2020-10-27
中华诗词(2019年1期)2019-11-14
文苑(2018年22期)2018-11-19
中成药(2018年7期)2018-08-04
猪业科学(2018年4期)2018-05-19
新农业(2016年18期)2016-08-16
西南军医(2016年6期)2016-01-23
