
基于深度残差长短记忆网络交通流量预测算法
2021-07-02 08:54刘世泽秦艳君王晨星柯其学罗海勇王宝会
计算机应用 2021年6期
刘世泽,秦艳君,王晨星,苏 琳,柯其学,罗海勇,孙 艺,王宝会
(1.北京航空航天大学软件学院,北京 100191;2.北京邮电大学计算机学院,北京 100876;3.首都师范大学信息工程学院,北京 100048;4.中国科学院计算技术研究所,北京 100190)
(∗通信作者电子邮箱hbliusz@126.com)
0 引言
近年来,随着城市化的不断发展,城市交通拥堵问题日益严重。对交通流量进行准确预测,有助于优化城市交通资源规划和调度,缓解交通压力。交通流量数据具有规模大、维数高和随时间动态变化等特性,且容易受到外部复杂、多样和动态因素影响,实现长期和准确的交通流量预测具有很大的挑战性。
传统交通流量预测方法大多使用数学建模或仿真方法描述交通流量时间序列数据的变化规律,例如统计模型、传统机器学习模型、差分整合移动平均自回归(Autoregressive Integrated Moving Average,ARIMA)模型[1]、向量机回归模型[2]和马尔可夫随机场[3]等,这些方法要求数据平稳且持续,并不能很好地预测复杂动态变化的交通流量。传统机器学习方法存在过于依赖特征工程提取、先验知识等问题,对于维度高、时空相关性复杂的交通流量预测往往难以给出准确的预测性能。
深度学习方法可以在无需大量先验知识的情况下表示和自主学习交通流量数据特征。卷积神经网络(CNN)[4-7]和递归神经网络(Recurrent Neural Network,RNN)[8-10]对时空数据具有较好的处理能力。文献[11-12]基于卷积神经网络提出了一种时空残差网络(Spatio-Temporal Residual Network,STResNet)模型,该模型对交通流量数据的三种特性——时间特性、空间特性和外部特性进行建模。将残差网络和卷积神经网络相结合以学习空间特征,并通过对内部数据按照不同周期性进行采样来模拟时间特征。该模型未考虑交通流量连续性问题。文献[13]认为,容量大、参数多的模型尽管具有较好的预测性能,但较难优化,且容易过度学习,与奥卡姆的剃刀理论相悖。
现有交通流量预测大多考虑单步预测,但在实际应用中,交通流量多步预测存在一定的必要性[14-16]。近年来,基于编解码器模型的深度学习方法在自然语言理解任务中取得了较大的成功[17-18]。这种模型采用端到端的通用框架,编码器模型将输入序列编码为固定维数的向量,解码器再将历史数据的矢量表示映射回目标序列。
为了解决上述问题,本文的主要工作如下:
1)提出了一种编解码器交通流量预测模型。该模型融合长短时记忆神经网络和残差神经网络网络,构成编码器,学习交通流量数据的时间相关性和空间相关性,提取时空数据的特征。将提取的特征映射成为固定长度矢量,输入到长短时记忆网络和全连接层组成的解码器中,实现交通流量的多步预测。
2)在编码器模块中,本文使用多步预测模型,可以大幅提升网络学习效率,降低时间复杂度。本文通过对比多步训练耗时和单步预测训练耗时可知,前者比后者降低了55.5%到65.5%,体现了多步预测模型的优越性。
3)使用北京市真实出租车客流数据集和纽约真实自行车客流数据集对所提算法进行了大量测试,实验结果表明,本文中所提的交通流量预测模型优于扩散卷积循环神经网络(Diffusion Convolutional RNN,DCRNN)和时空图卷积(Spatio-Temporal Graph Convolutional Network,STGCN)等交通流量预测算法。
1 相关工作
近年来,随着城市化的发展,人口增长和移动通信技术在交通中的应用带来交通数据快速增长。现有的统计模型、传统机器学习模型、差分整合移动平均自回归模型、向量机回归模型和马尔可夫随机场方法在数据处理方面存在不能学习复杂的时空数据相关性,例如数据的时空特征提取不够充分。在发生异常事件的情况下,例如拥堵或事故,存在对交通流量多步预测不准的问题。
交通流量预测传统方法,包括使用经典统计模型或传统机器学习模型[19]。Okutani 等[20]基于线性回归方法的卡尔曼滤波模型基于这种模型提出一种动态交通流量预测模型。van der Voort 等[21]提出了差分整合移动平均自回归模型。近年来,Kim 等[22]使用三维马尔可夫随机场(Markov Random Field,MRF)来模拟由车辆检测站(Vehicle Detector Station,VDS)传感器网络所测得的交通流量的时间动态性。
随着人工智能技术的发展和日益成熟,深度学习也被广泛应用于交通流量预测。Yao 等[23]提出了一个深度多视图时空网络(Deep Multi-View Spatial-Temporal Network,DMVSTNet)框架来对时空关系进行建模,突破了传统关于交通流量预测的深度学习方法仅独立考虑空间关系或时间关系的局限,使用三个视图:时间视图(未来需求的时间相关性建模)、空间视图(局部空间相关性建模)和语义视图(对共享相似时间模式的区域之间的相关性进行建模)。
2 SECLI交通流量预测模型
本文设计的集成挤压激励卷积长短时记忆(Squeeze-and-Excitation Convolution Long-short term memory Integrated,SECLI)网络框架如图1 所示。从图1 中可以看出,该网络主要由编码器和解码器构成。其中,编码器主要由残差神经网络和一个长短时记忆(Long Short-Term Memory,LSTM)神经网络构成,解码器主要由LSTM 神经网络和全连接神经网络构成。SECLI 模型不仅使用LSTM 神经网络对不同时间段交通流量数据的时间依赖性和周期性进行学习,而且使用残差神经网络对交通流量数据的空间依赖关系进行学习。
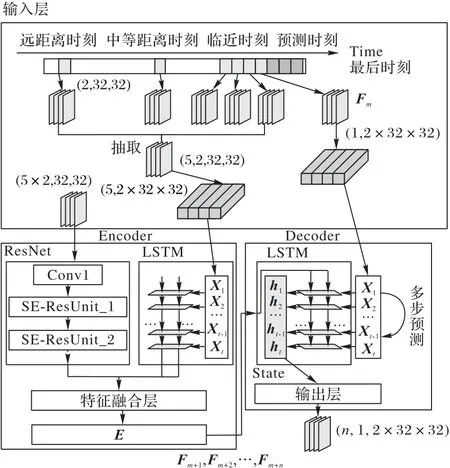
图1 SECLI交通流量预测模型编码解码框架Fig.1 Encoder-decoder framework of SECLI model for traffic flow prediction
针对时间依赖性,模型根据当下预测时刻对应的三种时间间隔的数据进行抽取,分别为当前时刻的c个连续时刻片的数据,当前时刻一天前p个连续时间片数据和当前时刻一周前t个连续时间片的数据。其中,三种时间间隔数据使用抽取时间片比例控制三种时间特性的学习权重,这三个时间片数量c、p、t是模型的超参。因为交通流量数据的不确定性和实时变化的特点,相较远距离时刻的交通情况,当下的交通流量分布总是与最近时刻更相似,所以通常总是加大对临近时刻流量数据学习的权重。
将数据进行分片操作之后,本文将三种时间数据拼接成一个4D 张量集合进行学习。将这个张量变换成3D 传入深度卷积残差网络,同时把变换成一维序列的交通流量数据送入LSTM 神经网络,对数据的时间依赖性和空间依赖性进行学习。
ResNet模块是模型编码器对交通流量数据进行地理特征抽取的核心模块。在ResNet 对数据进行空间特征提取后,将空间特征向量分别与两个时间特性向量通过加法的方式进行融合,对融合后的两个向量进行拼接。拼接后的向量E作为编码器的输出,已经包含了从所有抽取数据中学习的时空特性。
解码阶段,历史数据集最后一个时刻的数据作为LSTM的数据变换格式后输入,将向量E拆分为LSTM的两个状态输入,经过学习后得到单步预测值,再经过全连接层进行归纳,对输出的格式进行修正,最终得到单步预测结果。
多步预测将最后一个历史时刻的真实流量值作为输入,前文介绍的解码器输出作为状态初始值,再重新输入解码器进行预测,即得到多步预测结果。
2.1 输入层
本文将交通流量数据视为时间序列数据,模型根据预测时刻对应的三种时间间隔的数据进行抽取,分别为当前时刻之前的3 个时刻片的数据、当前时刻一天前一个时间片数据和当前时刻一周前一个连续时间片的数据。
输入层是模型的数据入口。如图2 所示,在这一层将预处理后的交通流量数据每个时间片进行不同时间特性数据的抽取,得到(None,5,2,32,32)大小数据张量。其中None 是batch_size的大小,5是3种历史特性数据片个数之和,2维保持原始数据的维度。将抽取后的张量大小转换为(None,5×2,32,32)输入ResNet 进行特征提取,同时转化成大小为(None,5,2×32×32)的张量输入对应的LSTM 网络进行深度时间特征提取。
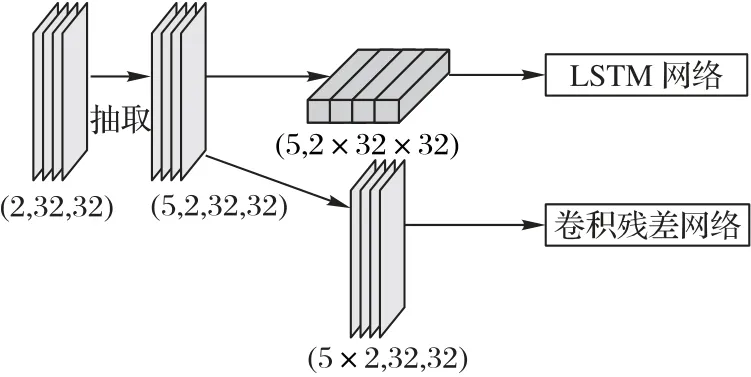
图2 SECLI输入层结构Fig.2 Input layer structure of SECLI
2.2 ResNet层
ResNet是模型编码器对交通流量数据进行特征抽取的核心模块。ResNet包含了2个残差单元,残差单元结构如图3所示,在每个残差单元中,大小为(None,5×2,32,32)的数据张量,经过残差层得到形状为(None,64,32,32)的特征张量,此处卷积层起到形状变换的作用,从而便于之后两个张量进行相加融合。每个张量需经过两个卷积层和一层挤压-激励(Squeeze-and-Excitation,SE)层,得到数据空间注意力和特征张量。其中每个卷积层前添加批归一化(Batch Normalization,BN)层与线性整流函数(Rectified Linear Unit,ReLU)激活函数。历史特征向量通过shortcut 路径与特征张量进行融合,得到大小为(None,64,32,32)的张量作为ResNet的最终输出。

图3 SECLI的残差单元结构Fig.3 Residual unit structure of SECLI
ResNet 可以有效避免卷积神经网络(Convolutional Neural Network,CNN)存在的过拟合以及网络退化等问题。ResNet能够在加快训练速度的同时保持较高的准确率。本文采用的ResNet 模块如图4 所示,残差单元之后都增加了SE 层作为空间注意力模块。

图4 SECLI的ResNet模块结构Fig.4 ResNet module structure of SECLI
2.3 SE层
SE 层这种网络易于封装,封装后的模块被称为SEBlock。SE-Block 为数据“特征通道”这个维度加入注意力机制,通过损失函数在全局范围内学习每个特征的重要性并对其进行重新标定。SE-Block 通过“挤压”和“激励”两个关键操作,实现这种策略。
SE 首先进行“挤压”操作:顺着空间维度对输入向量进行特征压缩,将每个二维的特征通道u变成一个实数,并且输出的维度和输入的特征通道数是一一对应的。这个实数表现了特征通道上的全局分布。在代码实现中,本文使用keras库中的全局平均池化函数(GlobalAveragePooling2D),它在每个数据通道上进行求平均值操作,得到一个长度为特征通道长度的一维向量,因此数据由传入的(None,64,32,32)变成(None,64)。为保证数据维度不变,再使用Reshape 函数恢复数据维度,使数据大小为(None,1,1,64),实现的效果如图5所示。

图5 SECLI的SE层“挤压”操作示意图Fig.5 “Squeeze”operation of SE layer of SECLI
其次是“激励”操作,它类似循环神经网络中门的机制,通过自学习参数w来为每个特征通道生成权重。之后使用生成的权重对特征进行“重标定”:“激励”模块输出的权重可以看作为特征选择后的每个特征通道的重要性,然后通过乘法给每个通道增加权重,完成在通道维度上的对原始特征的重标定。SE层整体计算简化公式如式(1)、(2)所示:

其中:u为原特征通道;p为压缩函数;w为u的权重。
“激励”操作增加了有用的特征权重,并减小了对当前任务用处不大的特征权重,可以显式地建模特征通道之间的相互依赖关系。
2.4 LSTM网络模块
LSTM 网络模块是模型编码器对交通流量数据进行时间特征抽取的核心模块。经过大量实验,本文的LSTM 单元数设置为64,时间步数为5,输入维度为batch_size。其中,LSTM单元数即为LSTM 中遗忘门、输入门、输出门和tanh 层四个前馈网络中隐藏神经元的个数,LSTM中隐藏神经元的个数决定了LSTM 层输出特征的维度,时间步数据经过LSTM 单元的次数,即通过记忆机制对数据进行学习和筛选的次数。图6 表示LSTM 的输入过程,将历史数据输入到LSTM 模块中,输出两个隐状态。隐状态值在预测阶段使用。

图6 SECLI的LSTM模块结构Fig.6 LSTM module structure of SECLI
LSTM 网络单元如图7 所示。输入层将(None,5,2×32×32)送入LSTM 网络,依次经过LSTM 单元完成学习和遗忘过程。本文使用保留状态LSTM,最终输出最后一个学习单元的隐藏状态和记忆单元状态,大小均为(None,64)。
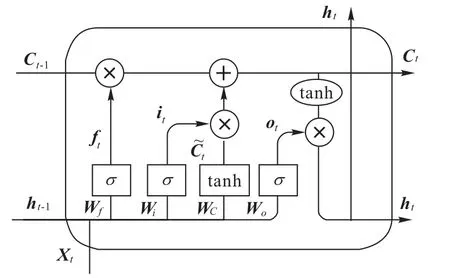
图7 LSTM单元结构Fig.7 LSTM unit structure
LSTM 第一步是从单元状态中丢弃什么信息,ht-1表示上一节点状态的输出,xt为当前状态下数据的输入,ft表示遗忘门,W和b均为可学习权重矩阵。以交通流量预测为例,当使用历史交通数据进行预测时,神经网络需要遗忘一部分以前的突发交通状况和时间久远、与当前时刻时间关系较弱的数据,从而更好地进行预测。

计算的第二步是输入门决定在单元状态中存储什么新信息,比如交通时间序列之间新的关系、规律等。具体操作分为两部分。首先筛选需要更新的数据并将值映射到(0,1),同时利用tanh层创建一个新向量来表示当前计算的值更新到记忆单元的比重大小。

计算的第三步是将旧的记忆状态Ct-1更新为新的记忆状态Ct。

最后一步计算是输出门对单元实际输出进行最终限制。首先,创建一个有tanh层压缩的记忆状态向量tanh(Ct)。然后使用ht-1、xt和sigmoid 层创建一个滤波器,与上述向量相乘,得到隐状态ht。

其中,门控结构动态调整LSTM 单元自循环权重参数,这是网络自我学习的关键。网络适时对知识进行记忆和遗忘,以实现较为长期的记忆,从而解决对输入序列与时间的长期依赖问题。
2.5 特征融合层
经过ResNet 模块和LSTM 网络模块对时空特征的提取,得到了大小为(None,2,32,32)的地理特征向量和两个大小为(None,64)的时间特征向量,按照编解码器的架构,需要融合为一个向量。代码实现中,特征融合层具体结构如图8 所示,使用LSTM 单元数作为CNN 层卷积核个数,卷积核大小为3×3,使地理特征向量的特征通道大小与LSTM 单元数相等,再使用Reshape 和Dense 层进行形状转换,最终使地理特征向量大小为(None,64),分别与LSTM 网络模块输出的两个状态相加融合,得到编码向量。

图8 SECLI的特征融合层结构Fig.8 Feature fusion layer structure of SECLI
2.6 解码器模块
解码器模块主要由一个LSTM 网络和输出层组成,组成结构和预测过程,如图9 所示。与之前LSTM 不同的是,将解码LSTM 设计为返回全部隐藏状态序列作为预测值,同时输出两个状态向量。

图9 SECLI解码器多步预测示意图Fig.9 Multi-step prediction schematic diagram of SECLI decoder
解码LSTM 输入编码器输出的编码向量,使用这两个(None,64)大小的向量作为状态输入对LSTM 的两个状态进行初始化,再使用最后历史时刻数据,即预测时刻上一时刻的数据作为LSTM 的数据输入进行预测,得到LSTM 计算过程中每个隐层输出向量的序列,向量大小均为(None,64),最后将利用Dense 层变换向量形状,使其形状与解码阶段输入的历史数据一致,最终得到向量大小为(None,2×32×32)的序列,即为最终预测结果。至此单步预测过程完成,而图片整体表示多步预测过程,通过不断获取单步预测的预测结果、隐藏状态和记忆单元状态,迭代利用LSTM 进行解码,最终得到多步预测结果。
3 实验与结果分析
在本章中通过实验评估所提出的模型SECLI。首先,介绍使用的两个不同的交通客流数据集,包括出租车和自行车,以及用于比较的最新基准。然后,给出了实验参数,包括默认模型参数和仿真环境。接下来,将对四个数据集的各种模型进行仿真评估,并得到实验结果。同时,还给出了时间开销数据表明本文所提出模型可以短时精准预测交通流量数据。
3.1 实验数据
本文选择以下两个数据集进行评估:
1)北京出租车(TaxiBJ)。北京出租车数据是按四个时间间隔从北京出租车的全球定位系统(Global Positioning System,GPS)数据中收集的:2015 年3 月1 日—6 月30 日,此数据的交通客流量反映在2 个通道中,网格区域大小为32×32。最后10 d的数据是测试数据,其他数据是训练数据。
2)纽约自行车(BikeNYC)。该数据由纽约自行车系统在2014年4月1日—9月30日发布。每个行程数据包括:行程持续时间、开始和结束站台ID,以及开始和结束时间。此数据的交通客流量反映在2个通道中,网格区域大小为16×8。使用最后10 d的数据进行测试,其余数据用于训练。
在经过数据预处理后,本文将对预测每个时间片所需的历史数据进行抽取,合成历史信息向量与预测数据一一对应,但以对数据集中的第一个时间片的数据进行预测为例,数据集中并不存在它的历史数据。在取得历史向量集合和标签数据集后,数据集均取最后10 d的数据作测试数据,其他数据作训练数据。抽取和训练集划分后的数据集含数据条数如表1所示。

表1 交通流量预测实验中的数据集划分Tab.1 Dataset division in traffic flow prediction experiments
3.2 性能评价指标
为了充分评估算法性能,本文联合使用均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)两个指标评估算法预测性能,其定义如式(9)和式(10)所示。
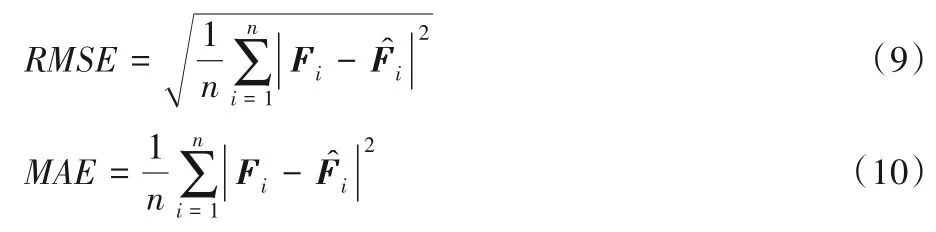
其中:Fi、分别为第i个时间步预测的真实值和预测值;n为样本总数。
3.3 实验方法
使用Min-Max 归一化方法缩放输入数据在[0,1]范围内。在评估中,将预测值重新缩放回正常值。使用激活函数为比例指数线性单元(Scaled Exponential Linear Unit,SELU),在卷积层前使用数据归一化过程。在实验中,批次大小设置为32。首先选择训练样本的90%来训练每个模型,其余10%在验证集中进行参数调整。所有实验中都使用了Early stopping机制。
3.4 实验环境
本文所提出的SECLI 模型在拥有CentOS Linux Release 7.4.1708(Core)操作系统与128 GB 内存的服务器上进行实验。服务器的CPU 与GPU 型号分别是Intel Xeon Gold 6132 CPU @2.62 GHz 与Nvidia Tesla-V100。同时本文基于Keras深度学习框架实现了SECLI交通流量预测模型。
3.5 对比分析
1)自对比实验。
为了评价不同分量对模型的影响,本文基于BikeNYC 数据集进行了自对比实验,比较了:1)单独使用CNN;2)单独使用ResNet;3)单独使用LSTM;4)编码器只使用CNN,解码器使用LSTM;5)编码器只使用ResNet,解码器使用LSTM;6)编解码器均使用LSTM;7)本文模型去除注意力模块SE层;8)本文模型将2D-CNN 换成1D-CNN。各变异体的实验结果如表2所示。从表2 中得到了两个观察结果。首先,没有短期编码器,模型退化为单步预测模型。其次,模型内各模块都提高了预测精度,表明了模型各部分的重要性和本文设计的有效性。

表2 不同算法在BikeNYC数据集上的交通流量预测结果对比Tab.2 Traffic flow prediction result comparison of different algorithms on BikeNYC dataset
2)单步预测。
本节通过展示实验的结果趋势从直观上来对比预测值和真实值。在对模型进行训练之后,分别对北京和纽约两个城市内某区域进行预测,预测结果和实际结果对比分别如图10~11所示,预测的趋势和真实值非常吻合,表明取得了较好的短时交通流量预测效果。且在交通流量值较大位置预测效果要优于交通流量值较小的位置;将北京出租车数据集和纽约自行车数据集对比,北京出租车数据集较大,预测效果要优于后者。
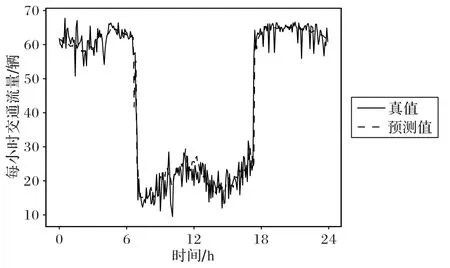
图10 TaxiBJ流量预测值与实际值对比Fig.10 Comparison of prediction values and real values of TaxiBJ flow
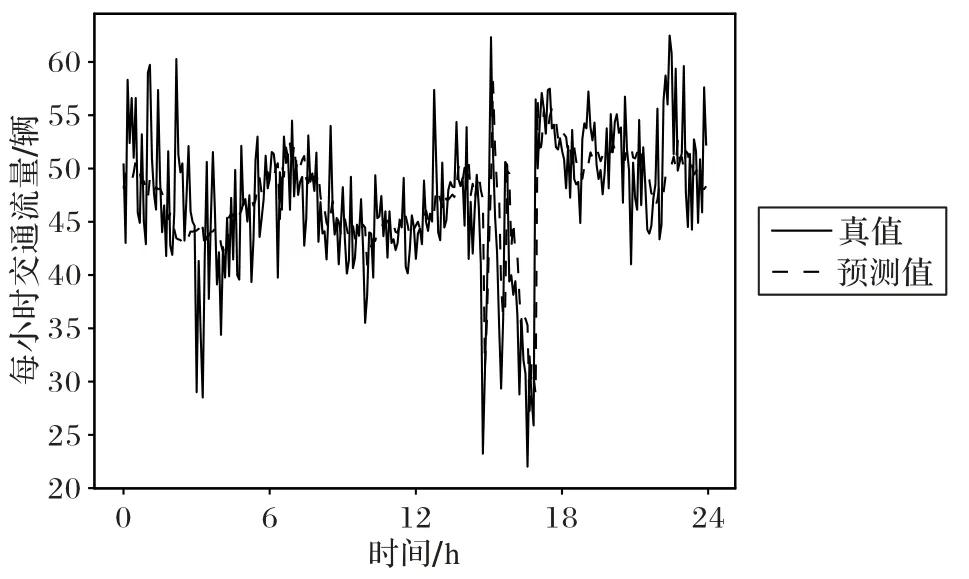
图11 BikeNYC流量预测值与实际值对比Fig.11 Comparison of prediction values and real values of BikeNYC flow
首先将本文模型与以下模型进行比较:三个具有代表性的传统基线包括历史平均值(Historical Average,HA)、普通线性回归(Ordinary Linear Regression)和梯度集成(Extreme Gradient Boosting,XGBoost);基于深度神经网络的时空数据分析模型(DNN-based prediction model for Spatio-Temporal data,DeepST);ST-ResNet;DMVST-Net;卷积长短时记忆(Convolutional Long-Short Term Memory,ConvLSTM);混合卷积长短时记忆网络(Fusion Convolutional Long-Short Term Memory Network,FCL-Net);整合区域人群流并应用于灵活的区域划分(Integrates Regional Crowd Flow and Applies to Flexible Region Partition,FlowFlexDP);DCRNN;STGCN。
表3 给出了综合比较结果,从表3 可以看出:1)深度学习方法总是优于HA、OLR 和XGBoost 等非深度学习方法,这表明了深度学习方法在捕捉非线性时空相关性方面的优越性。2)本文所提出基于深度残差长短记忆网络(SECLI)模型始终保持最佳性能,并在两个数据集中都优于其他方法。结果表明,所提模型能够捕捉到更准确的时空相关性。
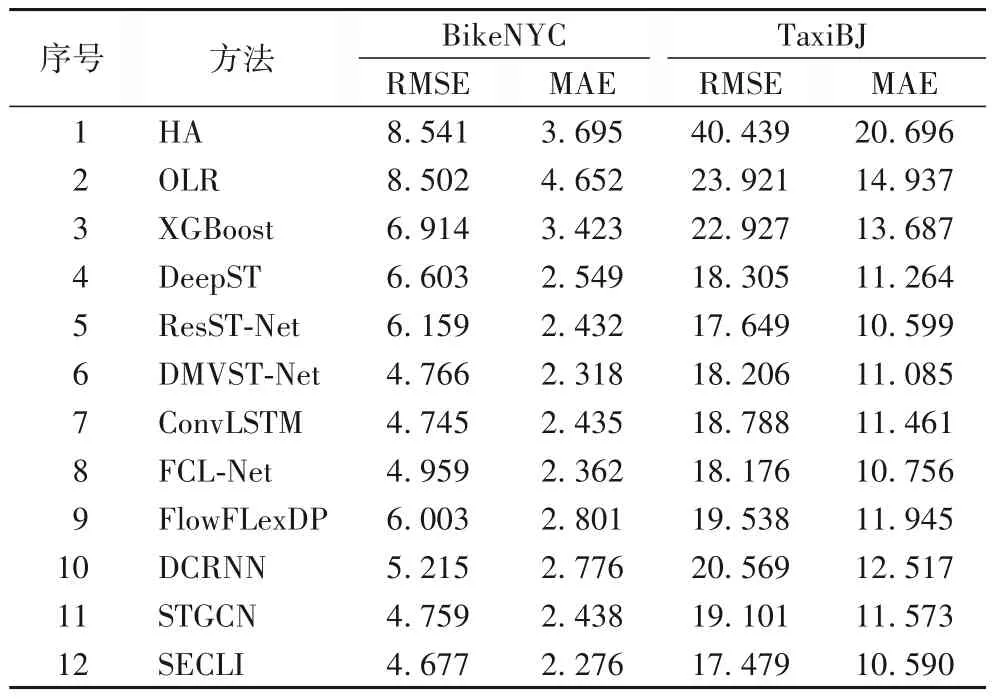
表3 不同深度学习方法流量预测结果对比Tab.3 Traffic flow prediction result comparison of different deep learning methods
3)多步预测。
目前交通流量预测模型大多依赖于数据驱动,数据量也是决定预测精度的因素之一,但学习的数据量越大,预测精度越高。因此为提升预测精度,预测模型都耗时较长,充分利用单次数据学习过程进行多步预测十分有意义,这意味着可以更快、更早地对未来进行长时交通流量预测。BikeNYC 和TaxiBJ 上基于本文模型进行多步预测实验的重复单步实验和单次多步的时间开销实验对比结果如表4 和表5。与单步预测相比较,单次多步训练只需要对模型进行单次学习,训练耗时极大减小;在2 步和3 步预测中,单次多步训练耗时比重复进行单步预测分别最多提高了55.5%和65.5%,体现了多步预测模型的优越性。在实际应用中,可以在相对较短时间内进行多步细粒度的交通流量预测。
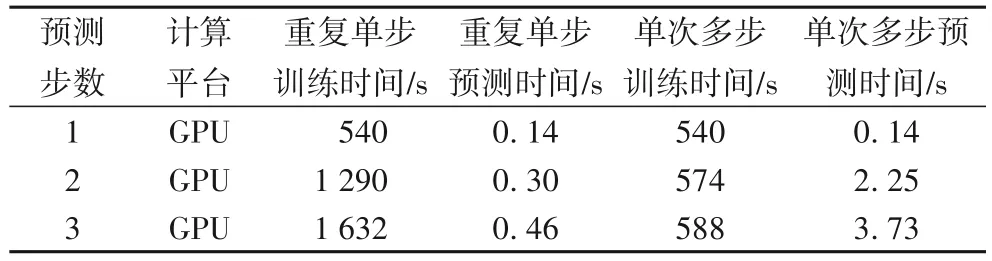
表4 BikeNYC上重复单步预测和多步预测的时间开销比较Tab.4 Time consumption comparison of repeated single-step and multi-step prediction on BikeNYC
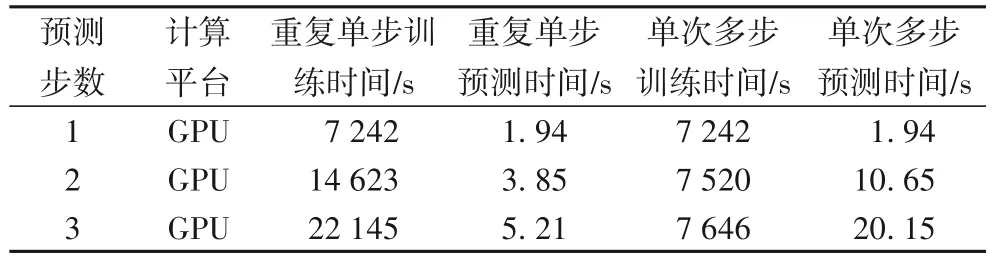
表5 TaxiBJ上重复单步预测和多步预测的时间开销比较Tab.5 Time consumption comparison of repeated single-step and multi-step on TaxiBJ
4 结语
本文所提的融合残差神经网络、LSTM和空间注意力的交通流量预测模型SECLI,能有效学习时空轨迹数据的深度时空特征和时空依赖性,提高了交通流量多步预测性能。在两个大规模公开数据集上的测试结果验证了,本文所提的SECLI 模型在单步和多步预测中都明显优于传统机器学习模型和基线深度学习模型。未来将致力于把本文模型算法应用于非结构化时空数据的挖掘与处理。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
科技资讯(2017年19期)2017-08-08
科技创新与应用(2017年16期)2017-06-10
中国市场(2016年36期)2016-10-19
高中生学习·高三版(2016年9期)2016-05-14
