
基于Faster R-CNN的多任务增强裂缝图像检测方法
2021-07-05 10:57毛莺池唐江红王静平萍王龙宝
智能系统学报 2021年2期
毛莺池,唐江红,王静,平萍,王龙宝
(河海大学 计算机与信息学院,江苏 南京 211100)
我国是世界上拥有水库大坝最多的国家[1],但随着时间的推移和坝龄的增长,大坝表面和内部发生形变,出险几率增加,威胁人民生命财产安全。裂缝是大坝的主要危害之一。
近年来,图像处理、模式识别和深度学习等技术的发展,为大坝裂缝图像检测提供技术支持。但由于大坝环境复杂等一系列因素的限制,导致裂缝图像收集和标记成本过高,因此难以获得大坝裂缝图像检测的分类模型。迁移学习主要是针对规模不大,样本数量有限的特定领域数据集使用机器学习容易产生过拟合而导致无法训练与学习的问题,通过利用具有一定相似性的领域中已训练好的较好优秀模型和样本构建满足任务需求的模型,从而实现小数据集下构建良好模型的效果。
Faster R-CNN[2]是目前基于区域卷积神经网络系列的目标检测算法中综合性能最好的方法之一,但其对多目标、小目标情况检测精度不高。本文提出了一种基于Faster R-CNN的多任务增强裂缝图像检测方法,以适应大坝在不同光照环境,不同长度裂缝情况下的检测。同时提出了一种基于K-means多源自适应平衡TrAdaBoost迁移学习方法辅助网络训练,解决样本不足问题。
1 相关工作
根据卷积神经网络的使用方式,将基于CNN目标检测算法[3-4]分为两大类:基于区域建议的深度学习目标检测算法和基于回归思想的深度学习目标检测算法。前者的主流算法有:RCNN算法[5]、Fast R-CNN算法[6]和Faster RCNN算法。R-CNN首次将神经网络应用在目标检测算法上,在 Pascal VOC 2012 的数据集上将平均精度mAP提升了30%。Fast R-CNN将候选框识别分类和位置回归合成到一个网络中,不再对网络进行分步训练,提高了训练速度。Faster RCNN与Fast R-CNN最大的区别就是提出了区域建议网络(region proposal networks, RPN)网络,极大地提升了检测框的生成速度。基于回归思想的深度学习目标检测的主流算法有:SSD算法[7]和YOLO V2算法[8]。SSD算法和YOLO算法均没有区域建议过程,极大地提高了检测速度,但识别精度和位置回归精度不足。
从20世纪90年代起迁移学习开始逐渐进入机器学习领域,受到研究者们的关注。常用的迁移学习方法有AdaBoost[9]和TrAdaBoost[10]算法等。AdaBoost算法基本思想:当一个训练样本被错误分类时候,对此样本增加样本权重,再次训练时该样本分错的概率就会大大降低。TrAda-Boost算法是由AdaBoost算法演变而来的,该算法通过降低误分类的源域训练数据权重,增加误分类的目标域训练数据权重,使得分类面朝正确的方向移动并训练出强分类模型。Al-Stouhi等[11]总结TrAdaBoost算法存在的问题,在此基础上进行改进,提出一种动态TrAdaboost (dynamic TrAdaboost, DtrA)方法,DtrA方法能够在迭代过程中动态调整样本权重;郭勇[12]在DtrA方法基础上进一步改进,提出一种自适应TrAdaBoost (adaptive TrAdaBoost, AtrA) 方法,AtrA方法能够反映出源领域训练数据集与目标领域训练数据集之间是否具有相似性关系。
2 ME-Faster R-CNN与K-MABtrA方法
本文提出了一种基于Faster R-CNN的多任务增强裂缝图像检测的网络模型,以适应大坝在不同光照环境、不同长度裂缝情况下的检测。同时,提出了一种基于K-means多源自适应平衡TrAdaBoost迁移学习方法解决样本不足问题。本文采用基于K-MABtrA迁移学习方法训练MEFaster R-CNN网络模型,该方法通过已准备的多源裂缝图像数据集对卷积神经网络的参数进行预训练,然后使用预训练得到的网络权重作为初始权值,迁移到目标数据集上进行微调,得到适用于大坝裂缝检测的模型。
2.1 ME-Faster R-CNN模型
ME-Faster R-CNN在Faster R-CNN模型基础上进行改进,改进之处如图1所示。其中,特征提取部分:选取轻量级的ResNet-50作为卷积神经网络;特征融合部分以及候选区域生成部分:改进使用多任务增强RPN模型,改善锚盒尺寸大小提高Faster R-CNN搜索能力,提高检测识别精度;检测处理部分:特征图和选择区域建议经过感兴趣区域(ROI)池、全连接(FC)层分别发送给边界回归器和SVM分类器得到分类与回归结果。

图 1 ME-Faster R-CNN模型改进之处Fig. 1 Improvements of ME-Faster R-CNN
ME-Faster R-CNN检测流程主要分为3个部分,分别是特征提取、特征融合以及候选区域生成、检测处理。
1)特征提取:本文选用ResNet-50深度残差网络[13]作为大坝裂缝图像特征提取器,通过5级ResNet-50将图片转换成特征图。
2)特征融合以及候选区域生成:将所得特征图输入多任务增强RPN模型,并改善RPN模型的锚盒尺寸和大小以提高检测识别精度,最后生成候选框。具体方法如下:
①多任务增强RPN方法:最初Faster RCNN模型结构中只有一个RPN,RPN使用最后一个卷积层获得特征图[2]。称之为原始RPN,其结构如图2(a)所示,输入图像大小为 224×224,原始RPN在网络中感受野要远远大于 2 24×224,仅能获得少量典型裂缝特征。然而,图像中裂缝存在不同大小和比例。如果检测到裂缝大小对于检测区域太大,则检测区域周围多余裂缝形状可能会被视为噪音。如果检测到裂缝大小对于检测区域太小,RPN将无法生成ROI。因此,原始RPN的功能不足以检测不同大小和比例的完整裂缝对象。

图 2 原始RPN模型与多任务增强RPN模型Fig. 2 Primitive RPN module &multi-task enhanced RPN module
针对以上问题,ME-Faster R-CNN方法提出一种多任务增强RPN方法,其结构如图2(b)所示。该方法在ResNet-50的基础上引入多个RPN来产生ROI,提取不同大小特征图。具体是在ResNet-50的第3卷积层Conv3_x后加入一个RPN模块,其感受野大小为 146×146,用来检测较小目标;同时在ResNet-50的第4卷积层Conv4_x后加入一个RPN模块,其感受野大小为 229×229,用来检测较大目标;在ResNet-50的第5卷积层Conv5_x之后利用多RPN任务可以输出图像总体信息。
由于每个RPN输出独立的ROI数组,为聚集和选择有效的区域,多任务增强RPN方法提供ROI-Merge Layer用于接受独立ROI数组,ROIMerge Layer仅输出一个数组。为了避免重复的ROI和低的ROI裂缝似然分数,本文使用非极大值抑制方法,不同卷积层后RPN输出的候选区域中,在对应位置两ROI的交并比大于0.7的ROI为同一ROI。具体方法为,3个卷积层后RPN输出的候选区域均带有建议得分,该分数对应的是目标的可能性,在对应位置选取分数最高的一个ROI区域,另外两层对应位置的ROI与所选ROI交并比IoU若大于0.7,则认为是同一ROI,ROI-Merge Layer的输出数组中对应位置仅输出该得分最高的数组。在使用非极大值抑制方法之后,选择前100个值较高的ROI。因此,ROIMerge Layer只需要调整超参数即可控制ROI的数量。
②改善RPN模型的锚盒尺寸和大小:FasterR-CNN模型经过卷积层提取特征图,然后特征图输入RPN区域进行特征融合以及生成候选区域,此时特征图上每个像素点映射不同比例宽度锚点,每个锚点放置若干个不同大小的锚,为解决不同尺度间隔的锚盒搜索能力不平衡的问题,本文设计了一种新型锚盒,新型锚盒尺度为:50×50 、 2 00×200 、 3 50×350 和 5 00×500,其中,50×50 和 2 00×200 适用于较小的裂缝检测,350×350 和 5 00×500 适用于较大的裂缝检测。这4种尺度每种尺寸按1∶1,1∶2,2∶1 的长宽比例缩放,共12种尺度作为RPN需要评估的候选框,在预测时候选框的顺序是固定的。RPN的目标就是对原图中的每个锚点对应的12个框,预测其是否是一个存在目标的框。框与真值框的 IoU>0.7就 认为这个框是一个候选框,反之,则不是。
2.2 K-MABtrA方法
针对大坝裂缝图像较少,训练样本分布不均衡,以及TrAdaBoost算法在训练过程中易削弱辅助数据集作用的问题,本节提出一种基于Kmeans的多源自适应平衡TrAdaBoost的迁移学习方法K-MABtrA,使用迁移学习充分利用多个领域的大量相关训练集,动态调整样本权值,训练出网络的强分类器,提高大坝裂缝检测的准确率。如图3所示为基于K-means的多源自适应平衡TrAdaBoost迁移学习方法的过程,主要分为两个阶段:K-means图像聚类方法[14]和多源自适应平衡TrAdaBoost迁移学习。
1) K-means图像聚类方法:通过K-means图像聚类方法,利用欧式距离将图像进行聚类排序。将聚类距离远的图片从裂缝图像库中删除,有利于后续分类器的训练,提高训练效率。K代表聚类质心数目,means表示簇内数据的均值。K-means图像聚类方法具体步骤如下:
①首先将图像库中图像Xi(i=1,2,···,n) 进行灰度化,依次存储到一维矩阵DX中;
②接着以10像素长度,3像素移动步长依次进行分块存储,记录每小块的首位置,得到n个像素块数据集,从中任意选择30个图像小块的灰度均值作为初始聚类中心;
③根据每个图像矩阵小块的灰度均值,利用欧几里得距离,如式(1)所示,计算这些对象与30个图像样本聚类中心的距离;并根据最小距离重新对相应图像小块灰度均值进行划分,将每个图像矩阵小块赋给最相近的类;

式中:dis(xi,yj) 为数据对象xi和yj之间的距离。该值越大,说明xi和?yj越相似;反之xi和yj差距越大。
④重新计算每个有变化的图像小块像素灰度均值的质心;
⑤重复上述步骤3)、4)直至各个数据类的集合 中心不再发生变化为止。
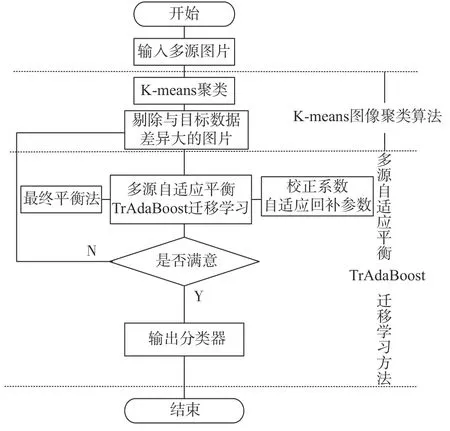
图 3 K-MABtrA方法流程图Fig. 3 Flow chart of K-MABtrA method
2)多源自适应平衡TrAdaBoost迁移学习:利用不同领域裂缝图像和真实大坝裂缝图像一一组合进行训练,生成基分类器;在TrAdaBoost基础上引入校正系数[12],避免由于迭代次数的增加,导致源领域权重下降过快,与目标源领域权重之间差距过大的问题;在校正系数中引入自适应回补参数[13],反映源领域训练数据集与目标领域训练数据集之间是否具有相似性关系,提高方法检测性能;最后,使用最终平衡权重法,使最终得到的目标源数据集与各领域裂缝数据集重要度一致。
① 增加校正系数更新源领域样本的权值
迁移学习在训练过程在,各领域辅助训练集随着迭代次数增加得到的权值不断减小以至于与目标数据集不相关,无法起到辅助目标数据集学习的作用。为了更好地利用各领域辅助训练集和目标数据集训练,在TrAdaBoost基础上增加校正系数更新源领域样本的权值。当迭代次数m不断增大,各个领域辅助训练集都能被正确回归,当 m 次迭代结束后,各个辅助领域样本权值之和为

式中:na为辅助训练集 a 中样本个数;wma为 a 中各训练样本权重。
目标数据集 b 中预测样本正确的样本权值不变,nb为目标数据集 b 中样本个数, wmb为 b 中训练样本权重,εmb为弱分类器在 b 上的错误率,正确样本的权值之和为

目标数据集 b 中预测错误样本需要更新 φm,则 b 中错误样本的权值之和 Sb2为

所有目标域样本权值之和,即正确样本和错误样本权值之和:

当 m+1 次迭代的辅助数据集样本权值分布为
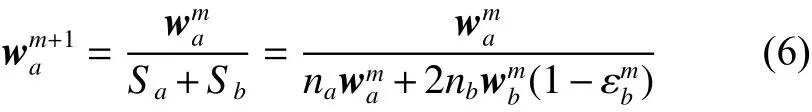
当迭代次数足够大时,各领域辅助训练集都能被正确回归,迭代结束后,wma+1=wma,联系式(6)可得:
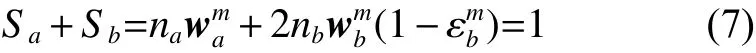
设辅助数据集样本增加校正系数为 Cm,其权值变为


从式(9)可以看出,校正系数 Cm与弱分类器在目标数据集 b 上的错误率 εmb负相关,辅助数据集样本权值增加,对下一次迭代训练弱分类器的影响增加;反之对下一次迭代训练弱分类器的影响减小。因此,在TrAdaBoost算法基础上加入校正系数 Cm能够同时保持目标数据集和辅助数据集样本权值得到收敛。
② 引入自适应回补参数
然而,即使 εb较低时,弱分类器对源领域训练集的分类效果也会存在差异,这种差异同样可以反映出源领域训练集与目标领域训练集之间的相关性。为了反映这种相似性关系,在校正系数中引入自适应回补参数,自适应回补参数为基分类器在辅助数据集和目标数据集上的分类正确率之和,即

③ 最终平衡权重法
最后,循环达到设定迭代次数 M ,得到强学习器。但在迭代后,目标数据集与源数据集的权重已经严重偏离,所以,造成最终分类器也过于偏向目标小数据集的问题。针对上述问题,在最终分类器生成方式中引入最终平衡权重法。最终平衡权重法的基本概念是:在迭代过程中,源数据权重不断下降,目标数据权重不断增加,迭代结束后,源数据权重与目标数据权重之间差距较大,但在最终分类器生成形式上,将目标数据集最终权重重置为最后一次迭代中各领域辅助训练集权重的平均值,使最终得到的目标源数据集与各领域辅助训练集要度一致,提高算法的检测准确 率。
3 实验与结果
3.1 数据集介绍
目前公开的大坝裂缝图像数据库较少,为了实现对大坝裂缝图像检测与识别,从大坝日常监测过程以及Google图像搜索引擎中收集并整理已标记好的裂缝图像组建成数据库。该数据库包含大坝、公路、混凝土墙壁和桥梁4个领域裂缝图像,其中大坝裂缝图像635张,其他领域裂缝图片 每个领域各2 500张,总计8 135张裂缝图片。
3.2 实验结果与分析
本次实验根据选取数据集的特点,选取mAP[15](mean average precision)和检测评价函数交并比[16](intersection over union,IoU)作为目标检测算法的评价指标。mAP作为目标检测中用于衡量识别精度指标;IoU 表示感兴趣区域和标定区域的重叠率。
本实验主要从以下4个方面对基于Faster RCNN参数迁移的裂缝图像检测训练方法的优劣进行对比分析:
1)视觉对比分析
在裂缝检测过程中,对裂缝图像提取感兴趣区域,并对感兴趣区域进行裂缝特征提取,通过训练好的分类器进行裂缝检测识别后,每个感兴趣区域边框都会得到一个分数,即置信度。随机选取3组实验结果进行视觉对比分析如图4所示。以图4(a)为例,其中,原图中央有一条长度和开合度明显的裂缝痕迹,其下方有一条短且开合度不明显的裂缝痕迹。Faster R-CNN能够检测出长度和开合度明显的裂缝,在其下方的裂缝并未准确检测出来。而ME-Faster R-CNN模型不仅提高 I oU 重叠度,更为准确地检测出长裂缝,同时能够准确检测出下方小裂缝痕迹,做到不误检也不漏检。实验结果表明,在相同的实验条件下,ME-Faster R-CNN方法不仅能提高检测精度,而且在应对目标小、多目标情况时,能获得很好的 检测效果。
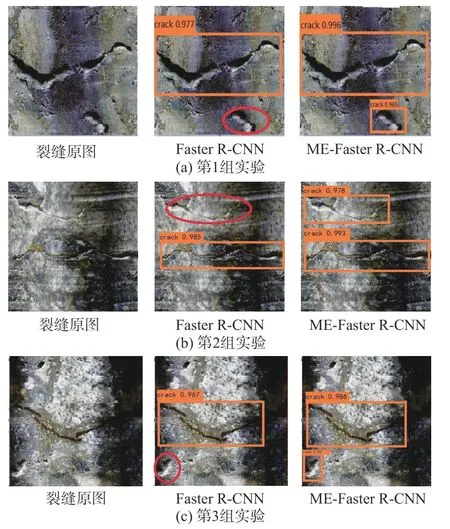
图 4 视觉对比分析Fig. 4 Visual contrast analysis
2)与不同基准网络模型之间对比分析
该部分采用ZF网络[17]、VGG-16[18]网络、Res-Net-50和ResNet-101网络作为特征提取基准网络,Faster R-CNN作为目标检测模型进行实验。
由表1可得,在同样数据集的训练测试下,ZF-Net可以达到66.51%的mAP值,VGG-16网络可以达到71.90%的mAP值,而ResNet网络的mAP值可以超过78%,提高了6个百分点,网络的检测准确度得到提高,由表1可以看出ResNet-50比ResNet-101的检测精度略低,但是ResNet-50的参数量为ResNet-101参数量的 1 /2,能够有效减少网络权重数量,加速模型训练[14],综合训练速度与检测精度本文选取ResNet-50为基准模型。

表 1 不同基准网络模型的准确度Table 1 Accuracy of different baseline network models
3)与不同目标检测算法对比分析
该部分以ResNet-50网络为基准网络,以SSD算法、YOLO V2算法、Faster R-CNN算法和ME-Faster R-CNN算法作目标检测模型进行实验。
表2给出不同目标检测算法获得的平均IoU、召回率、准确度以及平均精度。其中,MEFaster R-CNN算法的平均 IoU 是最高的,表明ME-Faster R-CNN算法在裂缝位置检测的准确性方面更优异一些,且其mAP值也是最大的,达到80.02%,表明ME-Faster R-CNN检测模型的综合性能很好。

表 2 不同目标检测算法对比分析Table 2 Comparison of different target detection algorithms
此外,注意到裂缝尺寸大小对准确度也会存在一定影响。因此,将采集到的真实大坝裂缝图像根据其尺寸大小分为3组。第1组包含100个样本,其尺寸大小在[0,50]范围内,第2组包含100个样本,其尺寸大小在[50,200]范围内,第3组包含100个样本,其尺寸大小超过200像素。各目标检测算法在不同尺寸裂缝图像的准确度如图5所示。

图 5 不同尺寸裂缝图像的准确度Fig. 5 Accuracy of crack images with different sizes
从图5可以看出,Faster R-CNN系列模型检测的准确度要整体优于SSD算法和YOLO V2算法,所有的检测算法在较大裂缝图像上都能表现得最好,而在小裂缝图像的检测上,准确度却不是很高。Faster R-CNN算法和ME-Faster RCNN算法在较大裂缝图像检测性能上实力相当,而在小裂缝图像的检测上,ME-Faster R-CNN算法要更优于Faster R-CNN算法。综上所述,MEFaster R-CNN算法在保持一定准确度的基础上,在面对小目标检测难度较大的情况,也能获得很好的效果。
4)迁移学习对比实验
该部分以ResNet-50作为基准网络,ME-Faster R-CNN作为目标检测模型,目标数据集样本占源训练集样本的比例为r,r取2%、5%和10%,分别用K-MABtrA方法、ATrA方法、DTrA方法、TrAdaBoost迁移学习方法进行分类器训练。
由表3可得出,同一方法,不同比例r下训练得到的分类器,在一定的范围内随着比例r不断增加,分类器的各评价指标都有所提升,说明在一定范围内目标源数据占总数据比例越大,分类器的各评价指标越高,检测效果越好。在目标源数据所占比例r相同情况下:ATrA和DTrA方法各评价指标均高于TrAdaBoost,证明了引入校正系数和自适应回补参数的有效性。本文提出的K-MABtrA方法各指标均高于ATrA方法。说明K-MABtrA方法引入最终平衡权重法,使最终得到的目标源数据集与各领域裂缝数据集重要度一致,提高算法的检测准确率。综上所述,K-MAB-trA方法能够更多地利用其他领域的共享信息,得到更好的迁移学习效果,训练出强分类器,高效 地完成大坝裂缝图片的检测任务。

表 3 不同迁移学习方法对比分析 Table 3 Comparison of different transfer learning methods
4 结束语
经实验验证,本文提出的ME-Faster RCNN方法在多目标、小目标检测准确性方面更优异;且本文提出的迁移学习方法更有效地解决了样本不足的问题。本文所提出方法的局限性在于ME-Faster R-CNN相比于Faster R-CNN只在特定检测任务中准确度较高,比如本文的应用场景:大坝裂缝检测,或类似的检测任务。而对于目标大小相似、亮度相同的目标检测其结果与FasterR-CNN所差无几。
猜你喜欢
石油与天然气地质(2021年3期)2021-06-29
中学生数理化·高一版(2021年2期)2021-03-19
少儿美术(快乐历史地理)(2020年5期)2020-09-11
知识经济·中国直销(2018年8期)2018-08-23
意林·全彩Color(2018年7期)2018-08-13
数学学习与研究(2017年3期)2017-03-09
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国老区建设(2016年1期)2016-02-28
电测与仪表(2014年15期)2014-04-04
