
基于相似度计算方法的人脸图分割
2021-07-06 02:14杨思渊蒋锐鹏海仁古丽阿不力提甫姑丽加玛丽麦麦提艾力
计算机技术与发展 2021年6期
杨思渊,蒋锐鹏,海仁古丽·阿不力提甫,姑丽加玛丽·麦麦提艾力
(新疆师范大学 数学科学学院,新疆 乌鲁木齐 830017)
0 引 言
图像分割是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。图像分割广泛应用在医学影像处理、卫星图像中物体定位、人脸识别、指纹识别、交通控制、机器视觉等。图像分割的方法多种多样,较为成熟的方法有:阈值法、区域法、边缘检测法、聚类法等。文献[1]在阈值法中提出了一种改进的二维Otsu算法;文献[2]提出一种改进区域生长法的遥感影像道路提取方法,先对遥感影像进行k均值聚类(K-means),再利用改进区域生长方法提取道路,这种方法精确度高,时间复杂度低;文献[3]提出一种将二进小波变换与形态学算子融合的边缘检测算法,在噪声浓度相同的情况下,具有很好地抑制噪声的能力,且检测的边缘图像轮廓清晰,含有丰富的细节信息。
图像分割的本质是对图像中的每个像素加标签(分类),这一过程使得具有相同标签的像素具有某种共同的视觉特性。如在人脸图像的分割中,可以将一张图的所有像素点进行聚类,使得人脸部分的图像划分为一类,非人脸部分划分为另一类,常用的方法有K-means[4],它是一种非监督学习模型,该算法原理简单、收敛速度快,效率高;也可以用监督学习模型如SVM[5]来对图像进行分类,该方法需要自己寻找不同类别的支持向量进行标记。
这两种方法在图像分割中都存在一定的缺陷,对K-means来说,它对像素特点的依赖性较大,像素相近的图像不能做出很好的分类;而SVM需要人为地选取支持向量,效率不高,易出错,且支持向量的选取也受到不同人群主观因素的影响。
在监督学习模型SVM的支持向量选取上,该文提出了相似度计算方法,代替人为选取可能出现的误差,并且对赋予的支持向量进行优化,去除无效数据,减少近似和重复数据。实验表明,该方法得到的SVM模型分类效果优于直接使用K-means方法。
1 监督学习SVM模型的图像分割
支持向量机(support vector machine,SVM)是Vapnik等人[6]根据统计学习理论提出的一种机器学习方法[7]。通过学习算法,SVM可以自动找出那些对分类有较好区分能力的支持向量,由此构造出的分类器可以最大化类与类的间隔,因而有较好的适应能力和较高的分辨率。该方法只需有各类域的边界样本的类别来决定最后的分类结果[8]。
对于人脸图像分割,用到的是一个二分类支持向量机,其具体形式如下[7]:
①设已知训练集:
T={(x1,y1),(x2,y2),…,(xl,yl)}∈(X×Y)l
(1)
其中,xi∈X=Rn,yi∈{1,-1}(i=1,2,…,l),xi为特征向量。
②使用线性核函数[9](式2)和适当的参数C,构造并求解最优化问题:
K(x,x')=x·x'
(2)
(3)
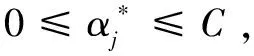
(4)
④构造决策函数[10]:
(5)
当f(x)=1时,目标属于第一类;f(x)=-1时,目标属于第二类。
利用支持向量机进行图像分割,本质上就是进行分类。所以必须要找出能区分不同像素点的特征,由于采用了彩色RGB图,因此可以直接用像素点的RGB值作为特征。在选取支持向量时,一定要选取与特征相关的点,不同的特征点要尽可能多地选取。如在人脸图像分割时,第一类支持向量应选取更多的是五官和皮肤附近的像素点,第二类支持向量应避免选择第一类选取过的点,选取更多的人脸范围以外的像素点。两个支持向量选取的像素各自应当是相似或相近的,这样充分保证两个支持向量差异最大化,使得SVM的分类效果更好。
SVM模型训练输入两组数据,其中一组为需要的数据,用label=1来标记,另一组数据为不需要的数据,用label=0来标记。实验中的图像数据转化为像素点所对应的RGB值,用[a,b,c]来表示,a,b,c分别表示选取点的三个颜色通道的数值。
将两组选取点与label值分别作为SVM的两组输入值,训练后得到一组训练(model)值,将该值重新作用于整张图像,预测得出整张图的分类结果。MATLAB中调用的fitcsvm函数做训练,predict函数做预测。将fitcsvm训练好得到的model值和测试数据用predict函数得到预测的前景和背景标签,再从标签分类中得到分割图像。
2 基于相似度计算方法的图像分割
2.1 图像颜色模型的转换
日常生活中最常见的颜色空间就是RGB颜色空间了,然而K-means运用其模型进行聚类分割彩色图像时发现效果并不理想,而1976年国际照明委员(international commission on illumination,CIE)制定的Lab颜色空间和人类视觉感知相关,并且具有均匀性以及欧氏距离不变的特性[11],实验中Lab颜色空间在K-means中拥有良好的实验效果。
从RGB颜色空间转换到Lab颜色空间时,需要借助XYZ颜色空间[12],RGB颜色空间与XYZ颜色空间的转换关系如式(6)所示:

(6)
再从XYZ颜色空间转换到Lab颜色空间,公式如下:
(7)

(8)
式(7)中L、a、b分别是Lab颜色空间的三个通道,式(8)中Xn、Yn、Zn默认是95.047、100.0、108.883。
2.2 K-means图像分割
K-means图像分割算法包括以下几个步骤[13]:
(1)从n个数据对象中任意选择K(K>1)个对象作为初始聚类中心。
(2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分。
(3)重新计算每个聚类的均值(中心对象),直到聚类中心不再变化。这种划分使得下式最小:
(9)
其中,xi为第i样本点的位置;mj为第j个聚类中心的位置。
(4)循环第②、③步,直到每个聚类不再发生变化为止。
K-means图像分割的具体实现步骤如下:
首先将彩色图像从RGB转成Lab彩色空间,然后选取适当的K值作为聚类个数,K值根据实际情况调整大小,使用MATLAB自带的K-means函数进行运算,得到聚类图像的K个分类标签值,最后还原得到K个聚类的结果。
2.3 相似度计算方法

该方法是将K-means聚类方法得出的结果分为前景和背景,前景为所需要的人脸图,背景为不需要的部分,分别作为SVM的两个支持向量,组成一个数据集,与label值0(背景)和1(前景)一一对应,得到的数据集和label赋予MATLAB的fitcsvm函数进行训练得到一个模型(model)值,该model值就是用来预测整张图片分类情况的模型。
图1是K-means图像分割实验结果,该实验将图像分割为K=2个聚类,效果良好。图1(b)为人脸部分,即前景,(c)为非人脸部分,即背景。

图1 K-means图像分割结果
然而直接将K-means的聚类结果不做任何改动赋予SVM训练时,其训练效果并不令人满意,甚至会出现全黑的情况,原因是在图1(b)和(c)中都存在黑色部分,这是K-means算法在聚类分割时产生的问题,不难发现,将(b)和(c)重合就得到了原图(a)。这些黑色部分的RGB值均为[0,0,0]。在第一节中提到过,对SVM选取支持向量时要尽量与目标类目一致,且要使两个类目的差异性最大,这些黑色的像素值对SVM训练存在干扰,故将其去除,保留剩余部分。
f(xi,yj)≠[0,0,0]
(10)
其中,xi,yj表示图像像素点坐标。
经过式(10)运算后,有效像素点得以保留,但通过查看数据,发现数据中有很多相同或相似的值,而选取支持向量的原则是选取丰富且不同的特征点,这些值会对结果产生不好的影响,故也将其去除。
|f(xi,yj)-f(uk,vl)|≤ε
(11)
其中,uk,vl为图像像素点坐标,ε为趋于0的无穷小量。
完成式(10)和(11)的运算后,SVM的训练效率大大提升,且效果相比于不做任何改动要好。
增加训练集,即把多张人脸图的K-means聚类结果经过优化拼接成一个大的训练集,再赋予SVM进行分类训练,得到多张图的训练模型,流程如图2所示。

图2 增加训练集数据拼接的流程
因SVM数据增多后训练速度明显下降,当发现测试图片不再发生明显增强效果后便停止增加数据集,故该文训练的图像个数最大为6张,但其耗时已经达到数小时之久。下面将给出详细的实验过程。
3 实验与讨论
实验所用软件为MATLAB R2016a,运行环境为CPU I5-8300,内存16 GB,操作系统为Windows10,所用图像均为218*178 RGB图。
3.1 SVM图像分割实验(手动选取支持向量)
传统方法所得到的图像分割效果如图3所示。

图3 SVM传统方法图像分割
图3(a)中*为背景选点,○为前景选点。
可以看出非监督学习模型人为选取前景点和背景点的SVM分类效果并不理想。原因是人工选取的点并不能分别将各类所需的样本点全部选取,始终会有部分样本点漏选或错选,且人工选取存在差异性和不确定性,特别是对于相对复杂的图像,人工选取就会变得非常困难。
3.2 K-means图像分割实验
颜色分布规律不明显的图像经K-means聚类分割效果如图4所示。

图4 K-means图像分割结果
图4的K-means图像分割效果明显不如图1的效果,原因是人脸区域与背景区域有颜色相近的地方,这就使得K-means对此类图像聚类效果不好。
3.3 文中方法的实验与结果
现将图1做SVM训练的模型用于图4(a)进行SVM分类,并与K-means作对比,效果如图5所示。

图5 文中方法与K-means方法的比较结果
对比图5(a)和(b)可以看出,文中方法在SVM人脸分类结果中明显优于K-means。
使用其他图片对文中方法作验证,图6中左侧为原图,中间为文中方法效果图,右侧为K-means效果图。

图6 其他图像使用文中方法和K-means方法的比较结果
以上实验表明,将K-means的聚类结果赋予SVM分类器训练的方法是可行的,在图像分割实验中可以取得较为满意的结果。
增加训练集后,新的模型和一张图像的模型对图4(a)做SVM分类的效果如图7所示。

图7 增加训练集与一张图训练模型实验结果
实验表明,增加训练集后训练的模型相比于单张图像,在面部有更多细节得以显现,部分黑色部分没有了,左上角的背景区域也有所减少,可见增加训练集可以改善SVM的测试效果,显示了文中方法的有效性。
3.4 评价指标
实验使用图像分割误差指标[14]来评价分割效果,该指标包括过度分割率(OR)、欠分割率(UR)和图像整体错误分割率(ER),公式分别如下:
(12)
(13)
(14)
其中,Op是前景中分割错误的像素数;Up是背景中错误分割到前景的像素数;Dp是手动分割得到的前景的像素数。表1详细展示了图4(a)的三种不同方法的评价指标,OR对分割结果影响较大,值越小越好,UR对分割效果影响较小,值不要太大即可,ER为整体错误率,值越小越好[15]。

表1 图4(a)评价指标结果
从表1中可以看出,文中方法在OR和ER中要优于其他两种方法,UR值略高于SVM,影响不大,这在主观视觉上也是一致的。
表2展示了图6中两组图像的K-means和文中方法的评价指标,因传统SVM的分割会受不同人的主观因素影响,每次分割结果不一致,故在此不作比较。

表2 图6评价指标结果
同样在表2中,文中方法在OR和ER上也优于K-means方法,与主观视觉一致。
4 结束语
在结合监督和非监督学习模型的基础上,提出了一种基于相似度计算的图像分割方法,对基于监督、非监督和文中提出的图像分割方法进行了对比实验,并给出了客观和主观评价结果。从图像分割的结果和客观评价指标可以看出,文中方法有效地提高了图像分割的性能和效率。
因为文中实验方法根据图像的颜色进行分类,当图像不同类别之间的数据相关性很大时,分割结果会出现不明显的情况,虽然提出了相似度计算方法有效地结合K-means的输出类别和SVM的输入支持向量,但是最终的图像分割结果还是会受K-means分类性能的影响,因此进一步优化算法是下一步深入研究并改进的地方。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
汽车实用技术(2022年4期)2022-03-07
奥秘(2021年5期)2021-06-15
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小雪花·初中高分作文(2017年9期)2018-05-21
米娜·女性大世界(2016年8期)2016-08-17
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
奇闻怪事(2014年5期)2014-05-13
