
支持多属性泛化的个性化(α,l,k)匿名模型
2021-07-06 02:15苏林萍董子娴吴克河崔文超
计算机技术与发展 2021年6期
苏林萍,董子娴,李 为,吴克河,崔文超
(华北电力大学 控制与计算机工程学院,北京 102200)
0 引 言
在信息高度共享的今天,每天都有大量的数据被收录和发布。对信息的挖掘和分析,可以有效促进科学事业的发展,从而为人们营造更加便捷畅通的生活环境。但与此同时,不得不面临隐私数据的泄露问题。因此需要重点保护个体的隐私数据。
在数据匿名化的思想下,隐私数据保护模型的基本做法是:在满足信息安全发布的要求下,隐匿特定个体和敏感信息之间的联系,并提高数据的可用性[1]。但是传统的匿名方式并未考虑不同个体对敏感数据的个性化隐匿需求[2]。不同的隐私信息其敏感等级必然不同,同一敏感信息对不同个体的敏感程度也会不同[3]。
Xiao等在文献[4]中第一次提出了个性化匿名的思想,之后出现了很多增强型的改进算法。其中,文献[5-6]为数据集中的每一个元组都设置了不同的隐匿需求,尽管极大程度地满足了不同个体的个性化需求, 但是工作量巨大, 也造成了不必要的数据冗余。 文献[7]提出个性化(α,l)-多样化k-匿名模型,归纳个性化隐匿方式包括两种机制,一种是面向个人的,一种是面向敏感值的。因为一般来说,仅仅面向个人的隐私保护模型容易由于个体的喜好造成信息的不必要损失和隐私泄露,而单纯面向敏感值的方式往往会欠缺特定个体的特定需求[8]。但是这种方法因为层层的限制条件而造成了属性值的过度泛化。文献[9]则提出了个性化(p,α,k)-匿名模型,改善了匿名后数据损失较大和高敏信息泄露的缺陷,将敏感值划分不同的敏感级别,并且各等级应用不相同的匿名方式,但是其对个性化的需求体现不足[10]。
针对上述文献中所提方法存在的不足,该文基于个性化(α,l)-多样化k-匿名模型和个性化(p,α,k)-匿名模型,提出针对属性过度泛化的改进的个性化匿名模型:应用文献[11]中敏感度评分的概念给不同的敏感值定义不同的等级,再根据少量特定个体对自己敏感属性的评级为每条记录确定最终的敏感值等级,按照敏感属性泛化树将高敏值直接泛化到下一级,然后使此时等价组里中低级敏感值满足l和α约束。
1 匿名模型
数据匿名化,指对要发布数据集的各属性进行合理的脱敏操作,要求数据在对应运维、实施或者数据挖掘等场景下不影响使用的同时,不能反识别出对应的个体。
可将原始集中属性划分为以下四种[12]:标识符属性(ID),是可以唯一标识到特定个体的属性,例如表1的“Name”。这部分属性在匿名处理中一般会被直接移除;准标识符属性(QI),是可通过和外部数据链接或背景知识的手段唯一确定出特定个体的属性[13]。例如表1中的“Gender”、“Age”和“Zip code”属性;敏感属性(S),是指个体的敏感信息,指攻击者最想明确和关联的属性[14],如表1中的属性“Disease”;非敏感属性(N),也就是其他属性,在脱敏时这部分属性不做处理。

表1 原始数据
定义1:等价组。给定数据集T={A1,A2,…,An},n为T中属性的个数。则其中的准标识符属性集QI={q1,q2,…,qi}里,i为准标识符属性个数,值一致的记录则属于同一等价组。
定义2:k-匿名。给定数据集T和等价组Q,若对于∀Q⊂T,Q中的记录条数都至少为k(k≥2),则T满足k-匿名。
由此可知,当数据集满足k-匿名时,攻击者确定特定个体和元组数据之间关联关系的概率不超过1/k,有效防止了链接攻击,不过因为并未破坏特定个体与敏感信息间的关系,所以还是会有背景知识攻击以及同质攻击的可能[15]。例如,表2就是对原始表表1的2-匿名化实例,当知道Tom的性别、年龄和邮编信息时,因为表中记录6和7的疾病属性都是Cancer,所以由此可以确定Tom的所患疾病,很显然,这是Tom不想公开的属性信息。

表2 2-匿名表
基于k-匿名模型中存在的风险,需要破坏特定个体与敏感信息之间的关联关系,这就需要引入l-多样性模型。
定义3:l-多样性。给定数据集T和等价组Q,若对于∀Q⊂T,其敏感属性值的种类数都不小于l(l≥2),则该数据集满足l-多样性模型。
表3即对表2中的敏感属性按2-多样性模型泛化后的示例,此时,对于每一个等价类,其敏感属性的种类个数都至少为2。但是该模型无法避免相似性攻击和偏斜攻击,以表3为例,当只能确定Amy为最后两条记录时,由于其疾病种类都是很严重的属性值,所以还是可以得知Amy得了绝症,这可能是Amy极度不想公开的隐私信息。

表3 2-多样性表
定义4:个性化(α,l)-多样化k-匿名模型。给定数据集T={A1,A2,…,An},将敏感值按敏感度的不同划分不同的等级Sid,此时若有特定个体对自己记录的敏感值等级指定了等级Ppl,且Ppl>Sid,则按照Ppl的等级替换Sid。匿名后数据集T*,若T*符合k匿名,且各等价组里不同敏感值的个数不低于l,每个等价组里相同敏感等级的敏感值出现的频率不大于α,就可以称T*符合个性化(α,l)-多样化k-匿名模型。
定义5:个性化(p,α,k)-匿名模型。给定数据集T={A1,A2,…,An},将敏感值按敏感程度不同分为高中低三级,将高等级敏感值直接泛化。匿名后数据集T*,若此时T*符合k匿名,且此时各等价组里不同敏感值的个数不低于p,每个等价组中相同敏感值出现的频率不大于α,就可以称T*符合个性化(p,α,k)-匿名模型。
2 个性化(α,l,k)匿名模型相关概念
为了给特定个体提供有效的个性化服务,同时要降低信息损失量来提高数据的可用性,该文结合个性化(α,l)-多样化k-匿名和个性化(p,α,k)-匿名两种模型,提出了一种个性化(α,l,k)匿名模型。在个性化(α,l)-多样化k-匿名模型中,虽然同时考虑了面向个人和面向敏感值两种个性化隐匿机制,但是通过实验也可以看出,由于过度泛化造成了大量的信息损失,极大地影响了数据的分析和挖掘。个性化(p,α,k)-匿名模型则提出针对敏感度较高值泛化的思想,将高等级敏感值直接泛化,在让其余中低敏感等级的值满足p,α约束时,也是优先泛化较高敏感级的属性,由此不仅有效降低了数据集的敏感度,还降低了信息损失量,但是个性化的思想体现不足。由此,该文提出一种个性化(α,l,k)匿名模型。
2.1 敏感属性的敏感度划分与频率约束α
下面将引入文献[11]里敏感度评分的思想,以其结果作为敏感值的敏感等级,这样较个性化(α,l)-多样化k-匿名模型更加体现个性化需求。
定义6:敏感度评分。统计个体对每个敏感值敏感程度的评分结果,并以统计结果的有效区间划分等级,作为敏感值敏感等级的预设参数。用这种方式设定的参数能更加满足大众用户对敏感度的要求。
例如散点图1所示,该图为对敏感属性疾病的调查结果,横坐标依次代表Flu、Indigestion、Heart disease、Asthma、Phthisis、Hepatitis、HIV和Cancer这八种疾病,将评分满分设置为80分,每个个体根据自己对疾病的重视程度对各个疾病进行打分,得分越高表示重视程度越高。去掉离群点,可以看到数据依次集中在区间[0,20)、[0,20)、[20,40)、[20,40)、[40,60)、[40,60)、[60,80)、[60,80)中,所以疾病的敏感属性可划分为4个等级,分别为1、2、3和4,并将这个值作为敏感属性的预设参数C。划分结果如表4所示。

图1 敏感度评分结果

表4 敏感属性预设参数
定义7:频率约束α。给定数据集T、等价组Q,指定的敏感属性S中各个敏感值的出现频率α(0≤α≤1)。若在任意等价组Q中,任意属性值都满足|(Q,S)|/|Q|≤α,那么数据集T满足出现频率约束α。其中,|(Q,S)|指等价组Q中敏感属性为S的记录个数,|Q|是等价组Q的大小。
2.2 敏感属性泛化树
构建敏感属性泛化树,如图2所示。各个原始敏感值作为泛化树的叶节点,树的高度至少是敏感属性的总等级数,要求被泛化的每个父节点均满足各敏感值的行业规范。

图2 敏感属性泛化树
2.3 个性化隐私保护规则
在通过应用敏感度评分的方法,达到了面向敏感值的个性化需求基础上,本模型还支持面向个人的个性化需求,允许用户给自己记录的敏感值认定敏感等级。需要注意的是,自定义的敏感等级值p不得超过泛化树的高度H。仅当p>C时,需用p值替换C的值。
如表5所示,在ID为3的记录中p=2≥C=1,所以会对该记录执行进一步脱敏操作,用对应等级父节点“呼吸道感染”属性值代替“Flu”。其中,用户指定的敏感等级p列中,“-”代表用户未指定等级。

表5 隐私保护级别
2.4 信息损失度量
不管是准标识符属性还是隐私属性的泛化操作都会带来信息的损失[16]。信息的损失反映了信息的可用性,但在一定程度上也反映了敏感信息的保护程度。
定义8:信息损失量。给定数据集T,规定T里属性A的阈值是size(A),那么A被泛化成A*的信息损失量为:
(1)
其中,|A*|为属性A被泛化后的值。|size(A)|是A的可能取值,若该属性是连续性数据,取区间长度,若是分类型数据,取值域的基数。
所以T中记录ti(1≤i≤n)的信息损失量如下,其中Wi是A的信息损失量权重:
(2)
则T中所有属性的信息损失量为:
(3)
3 算法设计
该文提出了个性化(α,l,k)匿名算法,本算法结合了个性化匿名的两种机制,在极大程度满足个性化的前提下,有效降低了数据损失量。
算法步骤如下:
(1)引用文献[17]中提出的多属性泛化的方法得到符合k匿名的数据集;
(2)比较自定义的敏感等级p和敏感属性的预设参数C,若p>C,则修改对应记录的等级,用F代表敏感属性的最终级别,再将敏感值泛化到相应的级别;
(3)将每个等价组中的记录按敏感值的敏感等级由高到低进行排序,将F最高的属性信息直接泛化到下一级;
(4)统计各等价类里不一致的敏感值个数,若小于l则将F相对较高的值进行泛化,并使其满足出现频率α的约束,直到满足个数值大于等于l;
(5)计算各等价类中各敏感值出现的频率,若大于α则将敏感度相对较高的属性进行泛化,直到满足频率值小于等于α。
如表6所示,是对表2中隐私属性Disease的进一步泛化,使其满足个性化(0.5,2,2)匿名模型的要求。最后一列是敏感属性的最终敏感等级,在满足个性化隐私保护规则的同时,满足对α、l和k值的要求。其中共三个等价组,分别为记录1~2、3~4和5~7,各等价组均包括两条及以上记录,等价组里不同种类的敏感值最少为两种,且符合出现频率α为0.5。
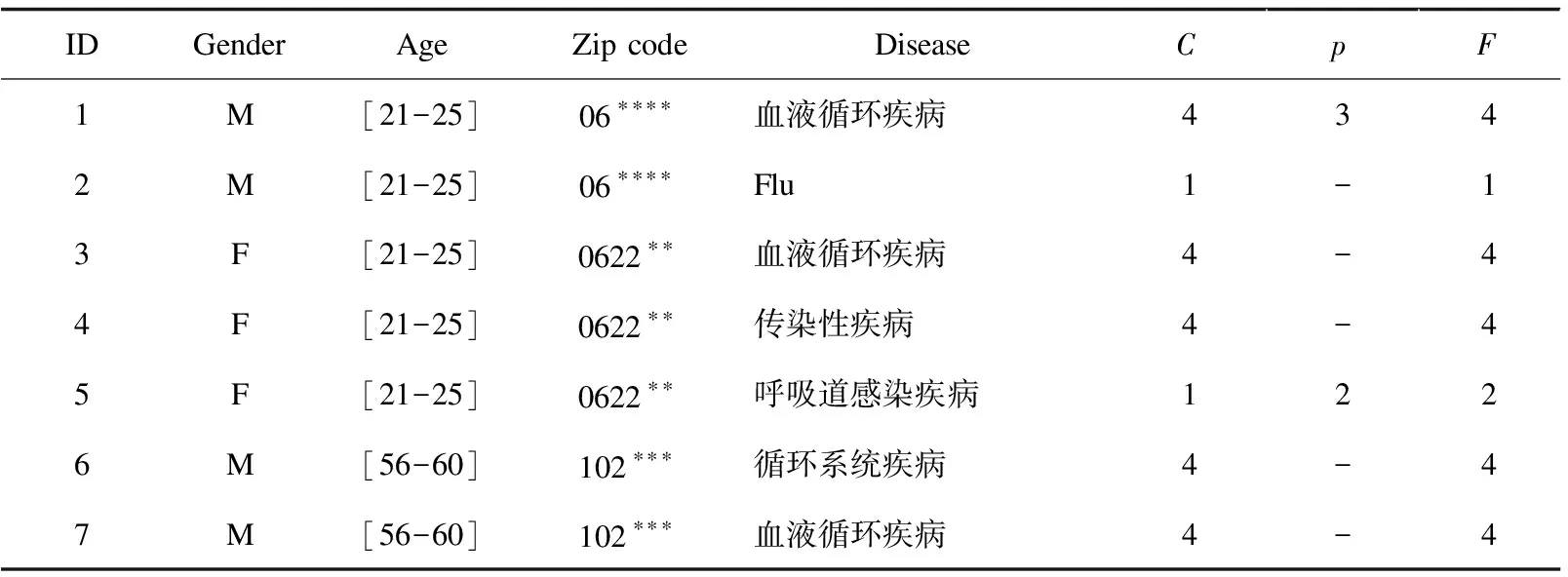
表6 个性化(0.5,2,2)匿名模型
生成个性化(α,l,k)匿名算法:(以上文中疾病这一敏感属性为例)
输入:数据集T,参数α、l、k,敏感等级C与p
输出:满足发布条件的数据集T*
(1)对T中的所有属性构建泛化树;
(2)计算T中记录的总条数count,if(count==0),则执行(7);else,则继续执行(3);
(3)引用文献[11]中提出的多属性泛化方法得到符合k匿名的数据集T1;
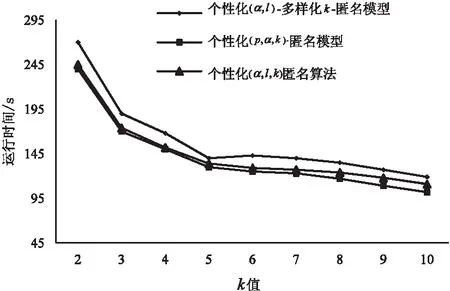
(4)用C列值给F列赋初值,对于每一条记录,if(C (5)依次在T2中取出k条记录,并将其存放到ti中; (6)i从1~n遍历t={t1,t2,…,tn}: ①若ti.length()不为0,则j从1~m遍历tj,将tj中的记录按敏感值的F由高到低进行排序,将F为最高级的敏感值泛化一级并替换原值; ②若ti.length()不为0,则k从1~m遍历tk,若tk中不同敏感值个数小于l,则泛化较高F的敏感值,且保证该敏感值满足α约束,直到tk中的敏感值均满足l和α约束; ③合并t作为T*。 (7)返回T*。 本实验采用UCI机器学习仓库中Adult数据集,此数据集被广泛应用于脱敏领域的研究实验。其中有48 842条记录,可筛选出30 162条有效数据作为原始数据集T。选取T中的6个属性为QI,并添加一列Disease为S列,属性的基本情况如表7所示。其中敏感属性列的敏感等级C值依旧应用上文的用户评分结果,随机选取2/5的数据记录添加用户自定义的疾病敏感属性值,并为表7中所有属性构建泛化树。 表7 各属性基本情况 实验环境:硬件环境为Intel Core i7-6700 3.40 GHz CPU,8 GB RAM;操作系统为Windows10;编程语言为Java。为了验证分析该算法的实用性,将个性化(α,l)-多样化k-匿名模型和个性化(p,α,k)-匿名模型在运行时间和信息损失量上作比较。固定l和α的值分别为4和0.7,每组实验反复运行10次,剔除离群数据,并取剩余值的平均数作为最后的取值。 在相同实验条件下,比较三种算法在k值大小的变化下,运行时间的变化。由图3可知,随k值变大,三种模型的运行时间都会减少,是由于等价组数量变少了,要处理的次数就也变少了。由于该文所提算法较个性化(p,α,k)-匿名算法增加了很多个性化的处理,所以运行时间上会稍多。随着k值的增大,对于多样性的要求越容易满足,所以折线的斜率会小一些。 图3 运行时间与k值的关系 采用上文所给信息损失量公式(3),在相同实验条件下,比较三种算法在k值大小的变化下,信息损失量的变化。如图4所示,随k值变大,三种模型的损失量也在变大,是由于等价组里记录数变多造成的。该文所提算法不仅应用了个性化(p,α,k)-匿名算法中对不同敏感等级的敏感值采取不同匿名方式的思想,还引入了文献[11]中的多属性泛化方法来使数据集满足k匿名,该方法针对属性过度泛化进行了深入研究,因此所提模型信息损失量要低。 图4 信息损失量与k值的关系 提出一种个性化(α,l,k)匿名模型。该模型在应用多属性泛化算法得到符合k-匿名模型的基础上,将敏感属性在面向个人和面向敏感值这两方面进行匿名操作,且针对不同敏感等级的敏感值执行不一样的操作,同时使其满足各等价组里敏感值的多样性和频率。实验表明,该模型在有限的运行时间内,达到了较好的个性化隐私保护效果。但是该模型是面向单敏感值的匿名操作,在实际生活中会经常面临多敏感值的情况,所以提出可以应用于任意敏感属性个数的个性化匿名模型是后续研究工作的主要内容。4 实验结果与分析

4.1 运行时间分析比较
4.2 信息损失量分析比较

5 结束语
猜你喜欢
心理学报(2022年8期)2022-08-09
新高考·高三数学(2022年3期)2022-04-28
教学研究与管理(2022年3期)2022-04-25
福建基础教育研究(2019年11期)2019-05-28
中文信息(2017年12期)2018-01-27
高中生·天天向上(2015年11期)2015-10-21
小天使·四年级语数英综合(2015年7期)2015-07-06
中学科技(2015年1期)2015-04-28
中学教学参考·理科版(2014年4期)2014-08-21
中学生物学(2008年2期)2008-07-07
