
基于多任务的多标签文本分类
2021-07-09 17:19覃杰
现代计算机 2021年14期
覃杰
(四川大学计算机学院,成都 610065)
0 引言
随着时代的飞速发展,人机对话技术变得愈发重要。对话意图的识别是通过文本分类任务实现的,而普通的文本多分类任务不能满足人机对话中复杂意图的识别功能,取而代之的是多标签文本分类任务。与传统的文本多分类不同的是,现实生活中存在的大量数据其实是对应多个类别的。例如一篇文章可能涵盖了文化、科技、教育相关多个类别。多标签文本分类任务较传统的文本分类任务的计算更为复杂,主要表现在一个样本的文本特征需要与多个标签产生关联,这就要求更精细化的特征抽取并且正确地映射到对应的标签上。此外,标签附带的额外信息应该被充分的利用起来,而不能仅仅简单的作为一个分类ID 处理。
早期的多标签文本分类任务一般将多标签问题转化为各个标签的二分类问题[1],然而这种方法忽略了标签之间的关联关系并且当标签数量过大的时候,模型的数量呈线性增加。后来Read et al.(2011)提出了链式二分类模型来建模标签之间的高阶关联关系[2],但是计算复杂度依然十分庞大。随着神经网络的兴起,深度学习模型如CNN、LSTM 凭借其强大的特征抽取能力,在自然语言处理的众多任务中成为主流模型。CNN[3](Kim,2014)采用多核卷积抽取文本特征,多个卷积核可以抽取不同窗口大小的文本特征,丰富了句子特征的表达。CNN-RNN[4](Chen et al.,2017)使用CNN和RNN 捕获了局部和全局语义特征建模标签的内在关联关系。近期,SGM[5]模型,通过生成式seq2seq 结构,来建模标签间的依赖关系得到了很好的效果,但是标签之间的关系是复杂的,线性的标签解码存在一定的不足。LSAN[6]模型,利用标签语义信息确定标签与文档之间的语义联系,构造特定于标签的文档特征表示,通过自注意力机制,捕获属于特定标签的文本信息,在多个数据集上获得了优异的成绩。
本文基于LSAN 模型,引入多任务机制,通过计算文本与标签的相似度分数作为辅助任务,联合相似度计算loss 和多标签分类loss 优化模型,相关指标得到进一步提升。
1 算法实现
1.1 LSAN模型
LSAN 模型由三个主要部分构成,第一部分是由Bi-LSTM 构成的特征提取层,第二部分是由文本自注意力机制提取文本特征的嵌入表示和标签注意力机制提取标签特征嵌入表示组成。第三部分是融合文本和标签的嵌入特征进行预测的全连接网络。具体模型结构如图1 所示。
模型结构不同层的相关定义和功能表达如下:
(1)Bi-LSTM
双向LSTM 模型在LSAN 模型中主要用于提取文本的词特征嵌入表示。为了解决传统的RNN 的长期以来问题和梯度消失问题,Hochreiter 和Schmid huber提出了LSTM 模型。该模型引入了自适应门控机制来决定LSTM 的状态单元在某时刻保存多少上一个时刻的状态信息,以及提取当前输入特征的程度。Bi-LSTM 在LSTM 的基础上增加了反向的LSTM 单元,使得在正向提取特征的情况下,又能进行逆序特征提取,从而获得了更好的特征抽取能力。LSTM 由三部分组成:输入门、忘记门、输出门。所有门控单元使用当前输入和上一时刻的隐层状态hi及当前细胞单元状态活值ci来计算下一时刻的细胞单元状态。具体公式如下:

其中it,ft,ot分别对应t时刻的输入门、忘记门、输出门的信息,Ct为t 时刻的细胞状态,W为对应权重参数,b为对应的偏置项。
(2)Self-Attention[7]和Label-Attention
自注意力机制主要用于抽取文本的高阶特征。自注意力机制是由(Lin et al.,2017)提出的,成功地在各种文本任务上取得了很好的表现。注意力机制的计算过程由信息输入,计算注意力分布,根据注意力分布来计算输入信息的加权平均组成。具体的公式如下:

A(s)是文本的自注意力得分矩阵,M(s)j是由注意力得分加权到文本隐层表征对应的j类标签的结果。其中,W2∈Rc×da,k为embedding 维数,c为标签数目,da为超参数可以调整。H∈R2k×n为Bi-LSTM 输出的隐层张量,M(s)∈Rc×2k是通过自注意力机制进行文本特征抽取的所有标签的具体化表示。
标签注意力机制主要是通过Bi-LSTM 的隐层张量与标签嵌入计算注意力得分然后将得分与Bi-LSTM输出的隐层张量加权计算得到具有标签注意力分数的文本特征的隐层表示。具体公式如下:
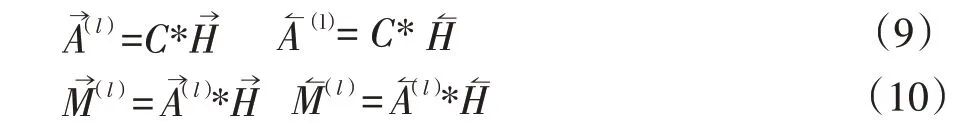
其中C是标签嵌入向量,A→为C与H→计算出的注意力分数,M↼(l)为最终文本在标签注意力下的嵌入表示。
(3)基于注意力的适应性融合策略
M(S)侧重于文档内容,M(l)侧重于文档内容与标签文本之间的语义关联。通过一个全连接层经过sig⁃moid 函数计算各自的分数,进行适应性加权得到最终的特定于标签的文档特征表示。具体公式如下:


1.2 多任务实现
多任务机制是同时考虑多个相关任务的学习过程,目的是利用任务间的内在关系来提高单个任务为学习的泛化性能。在多标签文本分类中,建模标签和文本的关系不仅可以通过上述注意力机制来实现,也可以通过计算标签嵌入表示和文档句向量表示的相似度来实现。假设某一训练样本属于A标签,那么A标签的嵌入表示和该样本的句子表示就应该比较接近。具体的公式如下:

训练文本对应分类的标签嵌入向量与该文本嵌入向量的相似度较高,所以通过公式(15)计算得到的loss值相对较低,而不属于该训练样本的其他标签计算得到的相似度较低,则得到的loss值较高。
2 算法实现
2.1 实验环境与数据
为了验证加入多任务相似度计算的有效性,本文在Ubuntu18 操作系统,配备显卡(NVIDIA GTX1660 6GB),以及深度学习框架PyTorch 的环境下进行仿真实验。数据部分本文采用了Arxiv Academic Paper Da⁃taset 数据集,该数据是由Yan 论文中[5]提供,该数据集从包含了55840 每篇学术论文摘要以及对应54 个不同的学科标签主题。一篇学术论文摘要可能对应多个学科名称。通过将该数据集划分为训练集、验证集以及测试集。模型训练结束采用在验证集上模型效果最好的模型作为测试集的预测模型。其中训练集、验证集、测试集的大小分别设置为:53840、1000、1000。
2.2 数据预处理
对AAPD 数据集进行简要的数据分析,其中训练集和测试集的句子长度分别为163 和171。为了覆盖大部分数据集,我们将句子长度设定为500,不足部分进行不全,超过的部分进行截断。为了实现相似度计算任务,需要对句子真实长度进行标记,以便在实验的过程中,实现补全token 的掩码,从而提取到句子真实长度的隐层向量特征的平均表达。
2.3 模型训练
数据经过预处理后,使用Google Word2Vec 预训练词向量(300 维),构成文本的嵌入矩阵,得到Bi-LSTM的输入embedding 特征。标签的嵌入向量维数也取300 维,通过随机初始化生成。Bi-LSTM 中的隐层单元设置为500,批处理大小(batchsize)设置为64,每个样本长度通过截断和补齐固定为500,激活函数采用ReLU,学习率设定为0.001,da 参数设置为200,b 设置为256。模型训练损失函数采用BCE(Binary Cross En⁃tropy)loss。使用Adam 优化器。模型训练过程中损失函数值以及P@1,P@2,P@3 指标变化情如图2 所示。
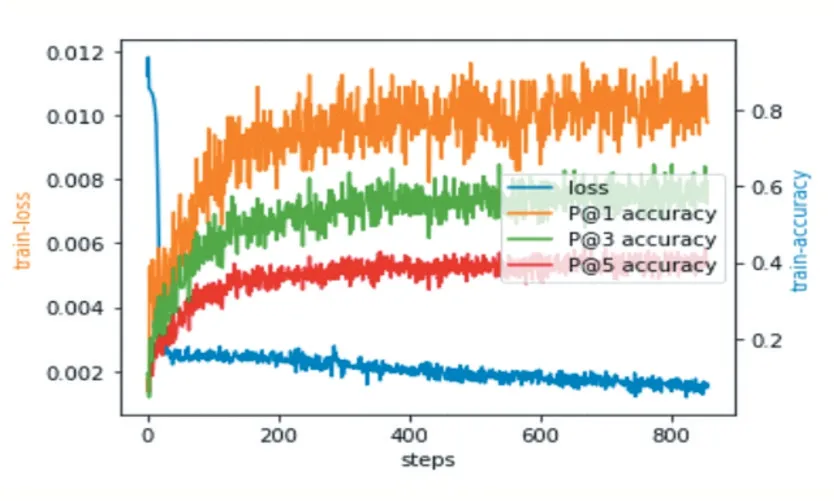
图2 Loss及指标变化
2.4 仿真实验结果
实验对比了对比加入了多任务相似度计算的LSAN 模型与未修改的模型训练结果。相关结果如表1 所示。定义改进的方法名字为MT-LSAN。评估指标采用Top-K 中的精确度。公式定义如下:
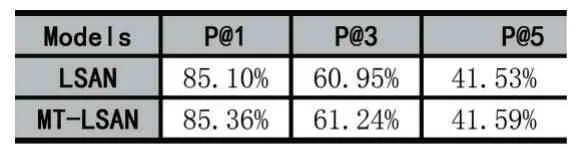
表1 对比实验结果

其中k表示取排名从高到底的前k个标签的预测值进行精度计算,l表示对应的标签类别。
通过对比实验可以发现,加入多任务机制的模型,其精度得到了一定的提升,其中P@1 提高了0.26%,P@3 提高了0.29%。仿真实验结果表明,加入了多任务机制的模型试验结果得到了一定的提升。
3 结语
本文在LSAN 模型的基础上通过引入标签与文本相似度计算的多任务机制,丰富了标签自身的隐含信息,使得文本内容与标签的关联关系变得更加紧密,在现有的实验结果上获得了一定的提升。在现有的对话系统意图识别中,多标签文本分类可以解决多意图识别问题,该模型具有一定的应用指导意义。
猜你喜欢
应用心理学(2022年5期)2022-11-05
小雪花·成长指南(2022年1期)2022-04-09
现代信息科技(2021年21期)2021-05-07
海峡姐妹(2018年3期)2018-05-09
中国新技术新产品(2016年23期)2016-12-26
第二课堂(课外活动版)(2016年2期)2016-10-21
电脑知识与技术(2016年2期)2016-03-22
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
