
基于朴素贝叶斯的敏感信息识别方法研究
2021-07-16 06:45陆向艳苏崇刘峻
网络安全技术与应用 2021年7期
◆陆向艳 苏崇 刘峻
(1.广西大学计算机与电子信息学院 广西 530004;2.广西师范大学广西多源信息挖掘与安全重点实验室 广西 54100)
互联网经过20 多年的发展,已经深入渗透到社会生产、生活和学习等领域的各个方面,互联网各种平台上每天产生大量的文本信息,其中有些信息不加以辨别和控制会对政治、经济和道德等领域造成损害或影响。这些信息主要包括政治敏感信息、恐怖信息、色情信息、侮辱谩骂信息、恶意广告信息等[1],被统称为敏感信息。如果不及时识别和处理这些敏感信息,互联网环境将不断地遭受破坏,给社会稳定、安全和文明等方面造成不利影响,识别并过滤敏感信息成为当前净化网络环境的重要手段。由于互联网信息量巨大,当前主要采取自动化方法来识别敏感信息。自动识别敏感信息方法主要为基于机器学习的分类方法,当前研究主要有基于SVM、决策树、K 近邻等[2-5]方法,本文提出一种基于朴素贝叶斯的敏感信息识别方法,旨在为敏感信息识别提供方法参考。
2 基于朴素贝叶斯的敏感信息识别方法
2.1 方法模型
基于朴素贝叶斯的敏感信息识别方法包括敏感信息标记、文本分词、朴素贝叶敏感词训练、朴素贝叶斯敏感信息分类4 个步骤,方法模型如图1 所示。
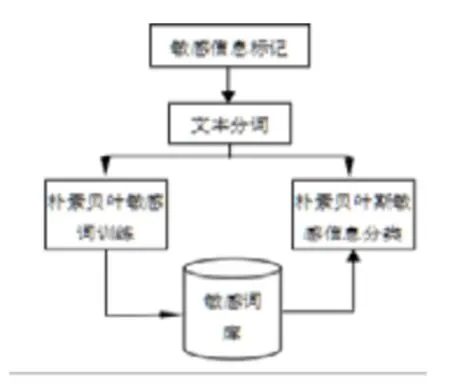
图1 模型图
2.2 敏感信息标记
用爬虫软件收集文本数据集,取其中一部分进行文本敏感属性标记,将包含和不包含敏感信息的文本分开存放。将敏感数据集分成涉黄、涉政、涉恐、广告、谩骂五个类别进行分类标记。
2.3 文本分词
用Word 分词器的最大Ngram 分值算法对文本数据集进行分词、去除停用词后,将敏感信息与非敏感信息的分词分开保存。
2.4 朴素贝叶敏感词训练
对于训练集文本的每一个分词,首先进行词频统计并计算分词先验概率,然后查看敏感词库是否已记录该分词,是则修正该词语的概率,否则写入敏感词库。敏感词库最后保留词频排序在前15%的词汇。朴素贝叶敏感词训练过程如图2 所示。
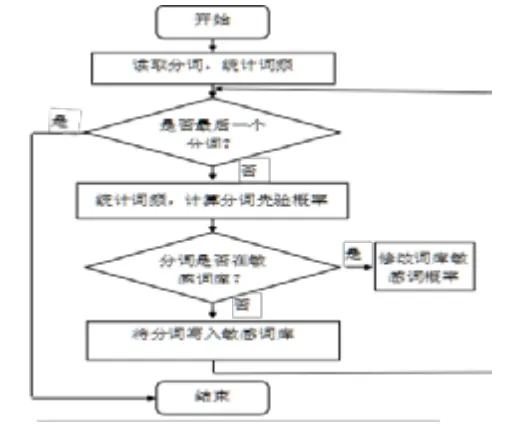
图2 训练过程
3 实验和结果分析
实验收集涉黄、涉政、涉恐、广告、谩骂五个类别文本数据各500 个,每个类别分别取100 个文本进行标记,300 个文本进行训练,100 个文本进行测试,验证本文提出的基于朴素贝叶斯的敏感信息方法的有效性,实验结果如表1 所示。
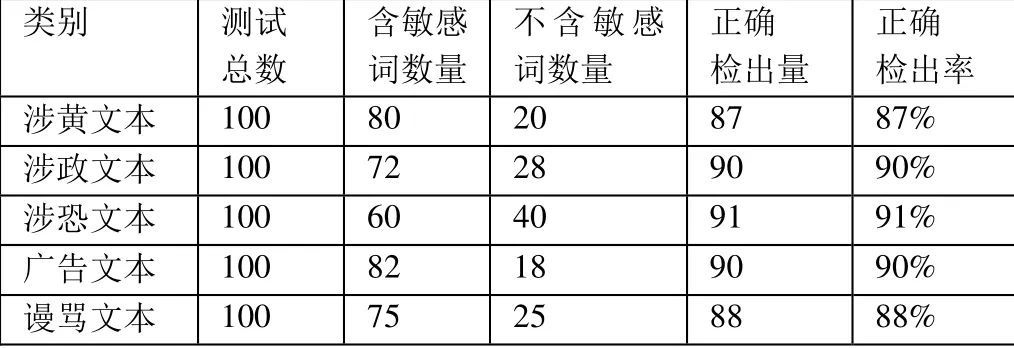
表1 实验结果
对于实验的五个类别数据,算法正确检出率都在87%以上,其中涉恐、涉黄和广告文本正确检出率在90%以上,相对较高,涉黄和谩骂文本正确检出率相对较低,原因主要是因为朴素贝叶斯在计算各分词概率时独立计算,而涉黄和谩骂文本相对涉政、涉恐和广告文本这三类文本其词汇的上下文关联更强。
4 结束语
识别网络敏感信息,对净化网络环境具有重要意义。本文提出一种基于朴素贝叶斯的敏感信息识别方法。实验结果表明本文方法能有效识别敏感文本信息。
猜你喜欢
小资CHIC!ELEGANCE(2021年36期)2021-10-15
校园英语·月末(2021年13期)2021-03-15
动漫界·幼教365(大班)(2020年7期)2020-06-26
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
现代计算机(2019年30期)2019-12-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
当代陕西(2019年9期)2019-05-20
电脑爱好者(2017年5期)2017-05-04
