
基于遗传-贪心混合搜索的人造板下料算法
2021-07-27 09:59刘诚孙远升花军姚嘉明
林业工程学报 2021年4期
刘诚,孙远升,花军,姚嘉明
(东北林业大学机电工程学院,哈尔滨 150040)
定制家具发展快速,数字化制造成了家具企业发展核心竞争力所在,如何利用数字化信息技术提供高效率、低成本的定制化产品已成为其面临的主要问题[1],因此探讨人造板数字化智能下料具有重要意义。人造板下料问题为可旋转和满足“一刀切”的二维矩形板排样(two-dimensional rectangular bin packing of rotate and guillotine,简称2RBPRG),即在工件可90°旋转,且排样满足“一刀切”条件下获得最优下料方案,该问题变量较多,包括每个工件的下料顺序、尺寸、位置及摆放方向,极具复杂性,属于多项式复杂种树度的非确定性(non-deterministic polynomial,NP)完全问题,目前仅能通过穷举法精确求解,当问题规模倍数扩大时计算机也无法计算。对此大量学者采取启发式算法近似求解,常见算法为二叉树排样[2-5]、分块填充排样[6-7]和二阶段排样[8-9]等。其中树形搜索与分块填充排样算法时间复杂度接近O(nlgn),速度较快,但其采取先“一刀切”划分后排样策略可能增大余料碎化程度,降低排样利用率,对此,通过对排样空位进行整合[4],以及通过选择最佳排样分解方式[5],在一定程度上降低余料碎化,提高利用率。二阶段排样算法则简化排样问题,采用“条带排样”策略,如通过在原料板上逐次剪切下矩形带后在其上排样[9],工件规格不整齐程度较大时,余料碎化较为严重。
智能算法也大量应用在矩形排样问题求解中,其中遗传算法应用最为广泛,如Aurelio、赵新芳等[10-11]均在无“一刀切”约束的矩形排样中使用遗传算法,获得较高排样利用率,但这类算法求解具有随机性,收敛速度及求解效果较为依赖遗传策略的选择。
针对上述算法存在问题,笔者采取对排样择优后进行“一刀切”检测的排样策略,降低余料碎化程度,通过改进遗传算法进行全局搜索,之后利用贪心算法对其进行二次优化,使解的质量接近全局最优,提高排样利用率,为人造板优选下料提供一种新的解决方案。
1 遗传-贪心混合算法描述分析
遗传算法是高度随机、自适应的全局搜索算法,其按评估策略评价每个个体,通过选择、交叉、变异将种群迭代进化,最终收敛到最适应群体求得最优解,但易过早陷入局部最优而早熟,对此采取贪心策略构建适应度函数,对个体解进一步寻优,即出现早熟后,仍可通过贪心搜索再次提高解的质量,从而提高遗传算法全局寻优能力。笔者基于遗传算法及贪心算法的原理和方法,研究2RBPRG的求解过程,在种群初始化、编码和贪心策略3个方面进行改进。
1.1 2RBPRG的求解目标
将一组矩形工件{P1,P2,…,Pn},排样在给定宽度、高度不限的原料板Y上,其中Pi为第i块工件,n为工件个数,求解目标为使Y使用高度h最小,即Y利用率最大,并且满足:
1)Pi不超出Y边界,1≤i≤n;
2)Pi、Pj互不重叠,1≤i,j≤n;
3)满足“一刀切”要求,即每次对Y切割时均可以将其分为两个独立矩形板材。
1.2 有序种群初始方式
赵新芳等[11]通过对全部矩形工件编号,随后根据面积降序排列,面积相等时根据最大边长降序排列,工件编号排列构成有序集{P1,P2,…,Pn},1≤Pi≤n,对每个Pi赋予正负号,分别表示工件横放与竖放,以此表示个体,重复m次随机赋予正负号后得到初始种群。上述有序种群初始方式中,每个体工件排样顺序相同,仅摆放方式改变,解的搜索空间较小,不利于得到高质量个体,但其根据面积降序排列方法生成工件初始序列,可显著提高排样空位的有效利用,因此对其进行改进优化。
首先由面积降序排列方法将工件排序为初始序列,对工件按顺序编号,工件编号构成有序集{P1,P2,…,Pn},1≤Pi≤Pi+1≤n,作为初始种群的个体;之后对该有序集中每个编号随机调整位置,生成新序列,作为初始种群的个体,重复m-1次随机调序,生成m-1个个体,共m个个体构成初始种群。与文献[11]相比,有序种群初始时不考虑工件摆放顺序,在后续贪心搜索时加以考虑。
初始种群选取对遗传算法收敛速度和求解效果影响甚大。对于2RBP|R|G初始种群选取存在2个问题:1)工件数量较多时解空间巨大,n个工件时解有n!种,盲目构造初始种群,不易获得高质量个体;2)排样过程复杂,仅以面积降序排列初始种群,会忽略形状差异对排样的影响,不易获得满意求解效果。
为解决上述问题本文随机调序为局部调序。首先将工件初始序列局部分组,每组v个,工件组的排列构成有序集{Q1,Q2,…,Qn′},n′=n/v,Qi= {P(i-1)×v+1,P(i-1)×v +2,…,P(i-1)×v+v},之后对Qi内编号随机调序。局部随机调序优点:在全局序列上保持面积降序排列特性,即优先排样大工件,小工件在后面排样,大工件排样时产生的空位较大,随后小工件排样可以更好进行空位填补,易获得满意的求解效果;同时可以缩小解空间规模,易获得高质量个体。
1.3 编码方式
本研究在个体序列与工件初始序列之间建立映射,以工件初始序列作为个体序列中工件位置参考,从个体序列中首个工件开始,记录其在工件初始序列中位置作为基因首个编码,然后将其在工件初始序列中删除,以此往复编码,组成有序集{q1,q2,…,q′n},表示基因,n′=n/v,qi= {p(i-1)×v+1,p(i-1)×v+2,…,p(i-1)×v+v},p(i-1)×v+j表示基因位置,编码如下:
1)工件初始序列为{Q′1,Q′2,…,Q′n′},n′=n/v,Q′i= {(i-1)×v+1,(i-1)×v+2,…,(i-1)×v+v};
2)个体序列为(Q′i)′= {P(i-1)×v+1,P(i-1)×v +2,…,P(i-1)×v+v};
3)编码至p(i-1)×v+ j时,在Q′i中删除{P(i-1)×v +1,P(i-1)×v+2,…,P(i-1)×v+j -1}的相同元素,之后将P(i-1)×v+j在Q′i中的当前序列号作为p(i-1)×v+j,1≤p(i-1)×v+j≤v-j+1,1≤j≤v。如图1所示,其中首先由P(i-1)×v +1=(i-1)×v+j,得到p(i-1)×v+1=j;之后将(i-1)×v+j在Q′i中删除,其后序列号全部减1,由P(i-1)×v+2=i×v+k,得到p(i-1)×v+2=k-1,往复进行编码。
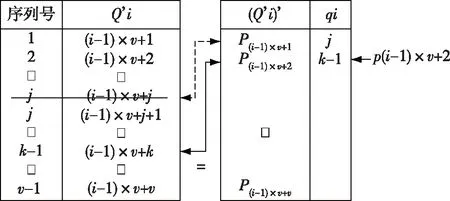
图1 基因编码映射示意图
基因编码方式对交叉、变异有较大影响。本研究编码的两个基因在交叉时,相同序列号元素可任意交换生成新基因,变异时基因某个序列号元素可在域内任意改变,均不会出现工件重复。
1.4 基于贪心算法的后检测排样
贪心算法总以当前情况为基础,根据优化测度作最优选择,直至求得最优解,不考虑整体情况,效率较高。笔者针对每个个体的工件序列,先利用贪心策略对排样择优,优化测度为排样利用率,之后对其进行“一刀切”检测,扩大局部解搜索空间,求出对应最优排样方案,计算适应度对其进行评价。
1.4.1 排样择优的贪心策略
排样择优通过操作矩阵实现,遵循“右下角占优”原则,通过迭代求解,时间复杂度为O(n)。
为便于“一刀切”约束检测,将全部板材尺寸增大2个刀路宽度DL,建立排样运算矩阵W及矩阵坐标系,以W右下角为原点,向上为X正向,向左为Y正向,W中每个元素fw(x,y)=wxy代表一个板材最小单元,以W内元素行、列数表示原料X向尺寸r+ 2DL、Y向尺寸c+ 2DL,如图2a所示。通过W的局部矩阵U描述工件,以U内元素行、列数表示工件X向尺寸ru+2DL,Y向尺寸cu+2DL,如图2b所示。通过改变U内元素fw(xu+x,yu+y)数值,记录工件信息,如图2c所示。记录工件尺寸为ru=7,cu=5,DL=1,仅改变其轮廓处元素:1)下边界元素记录尺寸ru,得fw(xu+DL,yu+DL+y)=ru,0≤y≤ru- 1;3)右边界元素分别记录本身与上边界元素的X向距离,fw(xu+DL+x,yu+DL)=ru-x,1 ≤x≤ru-1;4)上边界元素分别记录本身与左边界元素的Y向距离,fw(xu+DL+ru,yu+DL+y)=cu-y,1≤y≤cu-1。排样择优的贪心策略如下:

图2 初始矩阵及局部矩阵
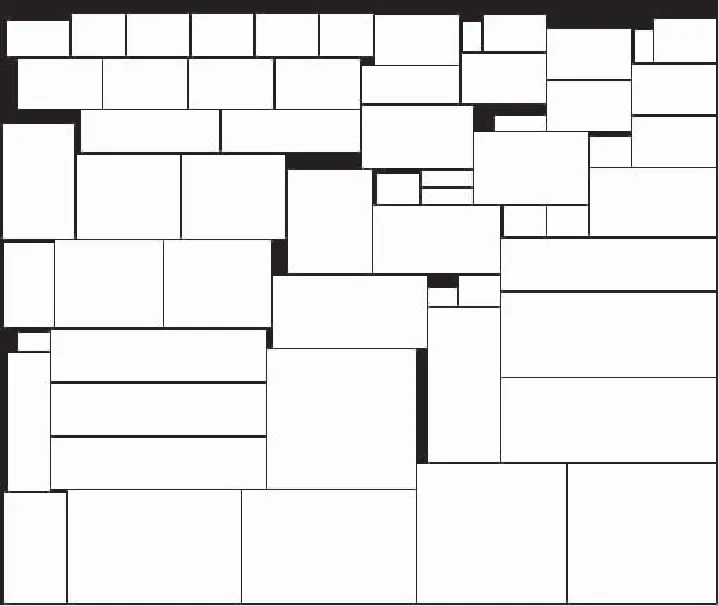
Step 1:从W原点开始,沿X正向搜索零矩阵U,以其右下角坐标(xu,yu)为搜索位置,当xu+ru Step 2:搜索到零矩阵U时,将工件记录到U内,检测W内排样是否满足“一刀切”,若不满足则重新索搜; Step 3:将工件旋转90°,重新搜索后与旋转前比较,取利用率高者,排样下个工件,直至排样完毕,如图3所示,为10块工件的简单排样。 图3 在W上搜索U 1.4.2 后检测策略 在W中以DL行或列零元素表示刀路占位,检测排样是否满足“一刀切”,可通过递归检测,时间复杂度为O(n),具体如下: Step 1:检测矩阵(首次为W)是否被刀路占位贯穿,如果贯穿则按刀路占位对其分割,对分割后的两个矩阵分别检测,直至分割后的矩阵全部为最小矩阵,即矩阵不被刀路占位贯穿,且内部存在非零元素; Step 2:最小矩阵与已排样工件数量相等时,排样满足“一刀切”约束,分割过程如图4所示。 图4 后检测中的矩阵分割 以排样利用率作为适应度,函数为: f(O)=Sw/Sm 其中:Sw为工件总面积;Sm=r·max(yu+cu),Sm为原料用于排样的最小矩形面积,max(yu+cu)为工件排样最大高度;适应度值范围为[0,1]。 给定n个工件,采用前述种群初始方式生成m个个体,将其编码为基因,用排样算法计算其最优排样,用适应度函数计算其适应度。 1)选择算子:采取比例选择方式,每个个体被选择概率与其适应度成正相关,同时采取最优保存策略,防止交叉、变异破坏种群中适应度最高的个体。将父辈个体按适应度进行降序排序{O1,O2,…,Om},每个个体死亡率函数为F(Oi)=(i-1)/m,没有死亡的父辈个体直接进化为下代个体,数量记为m′。 2)交叉算子:父辈种群中随机选择2个个体配对,进行多点交叉,生成1个新个体,重复次交叉至下代个体为m个。设随机选择的2个个体基因为Oi1={pi1,pi2,…,pin}和Oj1={pj1,pj2,…,pjn},取基因Oi1序列奇数位,基因Oj1序列偶数位,生成新的基因{pi1,pj2,pi3,pj4,…,pi(j)n}。 3)变异算子:对于选择和交叉生成的子代个体,根据最优保存策略,除适应度最高的父代个体外,其余个体均需变异。对个体基因内每个pi×v+j进行变异,变异概率为Pvariation,变异后的pi×v+j在区间[1,v-j+1]内随机选择。 本研究交叉算子和变异算子均在Qi内独立进行,求解大规模排样问题时,解空间维持在(v!)n/v大小,运算效率高;多次迭代后大工件依旧在个体序列靠前位置,利于得到高质量解。 重复执行第2.2节,直至满足预定的迭代次数或最优解的适应度达到要求(最优适应度3次迭代不发生改变),终止计算。 本研究在CORE i7 2.40 GHz CPU,8GB内存的PC机上进行下面的测试。 测试1:采用Hopper等[12]所采用的7类测试算例,每类分为3组矩形工件,排样在定宽无限高的矩形原料中,计算占用的最小高度,具体数据参阅文献[12]。该测试算例中没有考虑刀路损耗及“一刀切”约束,本研究算法将不进行刀路检测及刀路占位操作。 分别采用Hopper等[12]所采用的GA+BLF算法和SA+BLF算法、Zhang等[13]的FH算法、Leung 等[14]的PH算法和赵新芳等[11]的改进遗传算法以及本研究所采用的算法,计算每组算例。定义算法最优解H*到准确最优解H的绝对差值G=(H*-H) /H作为评价准则,每类算例的平均差值G平均=(G1+G1+G1) / 3。本研究算法选取种群规模m=20,变异概率Pv=0.05,各算法计算G平均值如表1所示,平均计算时间T平均如表2所示。 表1 每组例题的平均相对距离 表2 每组例题的平均计算时间 从表1可以看出,本研究算法平均差值G平均为0.883%,比GA+BLF降低3.687%,比SA+BLF降低3.117%,比FH降低0.797%,比PH降低2.067%,比文献[11]算法降低0.267%,说明本研究算法的解最接近H。由表2可以看出,本研究算法计算时间相对其他算法较少,说明本算法时间效率较高。 测试2:采用龚志辉等[15]的测试算例,其中给出20种矩形工件共59个,在宽度400 mm,高度不限的矩形原料板上排样,具体数据参阅文献。该测试算例同样不考虑刀路损耗及“一刀切”约束。分别采用龚志辉等[15]的算法、赵新芳等[11]的改进遗传算法、许华杰等[16]的AAGA算法,以及本研究算法计算该组算例。本研究算法选取种群规模m=50,变异概率Pvariation=0.1,各算法在不同迭代次数下排样利用率情况如表3所示。 由表3可以看出:本研究算法与文献[11]和[15]的算法比较,最优利用率均提高了10%;与许华杰等[16]的算法相比最优利用率十分接近且接近1,说明本研究算法具有较高的求解质量。同时,本研究算法相对于以上3种算法收敛速度较快,迭代40次时便获得最优解,仅为文献算法0.5倍,本研究算法的遗传策略具有明显优势。本研究算法迭代40次后排样如图5所示。 表3 不同迭代次数下最优利用率对比 图5 迭代40次的最优排样图 测试3:采用王华昌等[17]的 “一刀切”排样测试算例,其中给定26种矩形工件共49个,在1 850 mm×1 240 mm原料板上排样,具体数据参阅文献。该测试算例不考虑刀路损耗。分别采用王华昌等[17]的模拟退火算法、陈仕军等[18]的混合算法及本研究算法计算该组算例。本研究算法选取种群规模m=20,变异概率Pvariation= 0.05。各算法排样利用率如表4所示。 表4 3种算法的最优利用率对比 由表4可以看出,本研究算法与文献[17]和[18]的算法比较,最优利用率均有所提高,说明本研究算法在“一刀切”的约束下具有较高的求解质量。 测试4:采用Vassiliadis[2]和彭碧涛等[3]算法分别对7种工件进行“一刀切”下料,其原料上高度为200,宽度不限,刀路宽度为2,并给出最优排样如图6a、b所示,具体数据参阅文献。本研究算法选取种群规模m=20,变异概率Pvariation= 0.05,排样如图6c所示。表5给出3种算法的使用尺寸、最优利用率、余料数量。 图6 3种算法的排样图 表5 3种算法的排样结果对比 由表5可以看出,本研究算法余料数量相比文献[2]减少72.7%,相比文献[4]减少30.8%,说明本算法在降低余料碎化具有一定效果。同时,本研究算法最优利用率相比文献[2]提高4.5%,相比文献[4]提高1.3%,说明本算法在考虑“一刀切”约束及刀路损耗下具有较高的求解质量。 对于人造板下料问题,笔者提出基于遗传-贪心混合算法的板材排样策略,在初始种群选取、基因编码及贪心策略三方面予以改进,降低了问题解空间范围,进而提高了算法效率。在贪心排样时采取先排样择优、后对其“一刀切”检测的策略,扩大了局部解搜索空间,进而提高了算法求解质量。实验计算表明: 1)在测试1中,本研究的算法在无“一刀切”约束排样中,相比文献算法得到较高的时间效率及求解质量; 2)在测试2中,本研究算法在迭代求解时具有较快收敛速度,相比文献算法通过少量迭代便获得满意解; 3)在测试3中,本研究算法在有“一刀切”约束排样中,相比文献算法可以获得较高的最优利用率; 4)在测试4中,本研究算法在有“一刀切”约束排样中明显降低余料碎化,使原料利用率进一步提升。 由以上结论可见,本研究中的人造板下料算法在定制板式家具生产中具有一定应用价值。

1.5 适应度函数
2 遗传算法求解过程
2.1 初始种群
2.2 遗传算子
2.3 终止准则
3 试验计算






4 结 论
猜你喜欢
矿山安全信息(2022年11期)2022-11-26
计算机仿真(2022年8期)2022-09-28
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
矿山安全信息(2021年3期)2021-11-30
智能制造(2021年4期)2021-11-04
杭州电子科技大学学报(自然科学版)(2020年3期)2020-06-08
中学生数理化(高中版.高考理化)(2019年6期)2019-06-22
当代旅游(2016年10期)2017-04-17
汽车维修与保养(2015年2期)2015-04-17
