
基于MogoDB数据库的临床医疗大数据挖掘案例分析
2021-07-28 05:30胡皓皓胡昌盛
科技创新导报 2021年3期
胡皓皓 胡昌盛


DOI:10.16660/j.cnki.1674-098X.2011-5640-8970
摘 要:隨着医疗大数据时代的到来,从大量原始数据中挖掘出相关有用的信息,对治病防病及医疗决策进行有效辅助,起到非常好的作用。本文基于MongoDB数据库,利用Python编程语言,编写数据处理程序,通过将原始的多个数据表入库转换,找出已治愈患者,在此基础上找出复燃、复发患者并筛选出没有重复的数据;通过多进程提高处理速度。最后结果达到了预期,为相关医务人员提供了诊断及决策依据。
关键词:Python MongoDB数据库 大数据 数据挖掘
中图分类号:TP311 文献标识码:A 文章编号:1674-098X(2021)01(c)-0108-03
A Case Study of Clinical Medical Big Data Mining Based on MongoDB Database
HU Haohao1 HU Changsheng2*
(1.South China Institute of Software Engineering, Guangzhou University, Guangzhou, Guangdong Province, 510990 China; 2.Guangzhou University of Chinese Medicine, Guangzhou, Guangdong Province, 510006 China)
Abstract: With the advent of the era of medical big data, mining relevant useful information from a large number of original data plays a very good role in effectively assisting the treatment and prevention of diseases and medical decision-making. In this paper, based on MongoDB database, using Python programming language, we write a data processing program. Through putting the original data tables into the database and transforming, we find out the cured patients. On this basis, we find out the recurrent patients, and screen out the data without duplication. We improve the processing speed through multi-processing. Finally, the results achieved the expected results, and provided the basis for diagnosis and decision-making for relevant medical staff.
Key Words: Python; MongoDB database; Big data; Data mining
医疗机构作为医疗行业的重要载体,保存大量的患者的原始数据。早期,大部分医院原始数据的记录大都保存在Excel电子表格中,表格多,数据量大,少则十多万条,多则几百万条。单独通过电子表格进行数据统计功能非常有限,而且处理速度慢,对深度数据挖掘没有什么作用。本文笔者通过Python编写语言,结合MongoDB数据库编写程序,把原始数据中的多表进行关联并进行条件筛选,通过多次优化进程,挖掘出相应结果。具体编程处理流程分多步进行。
1 设计具体流程
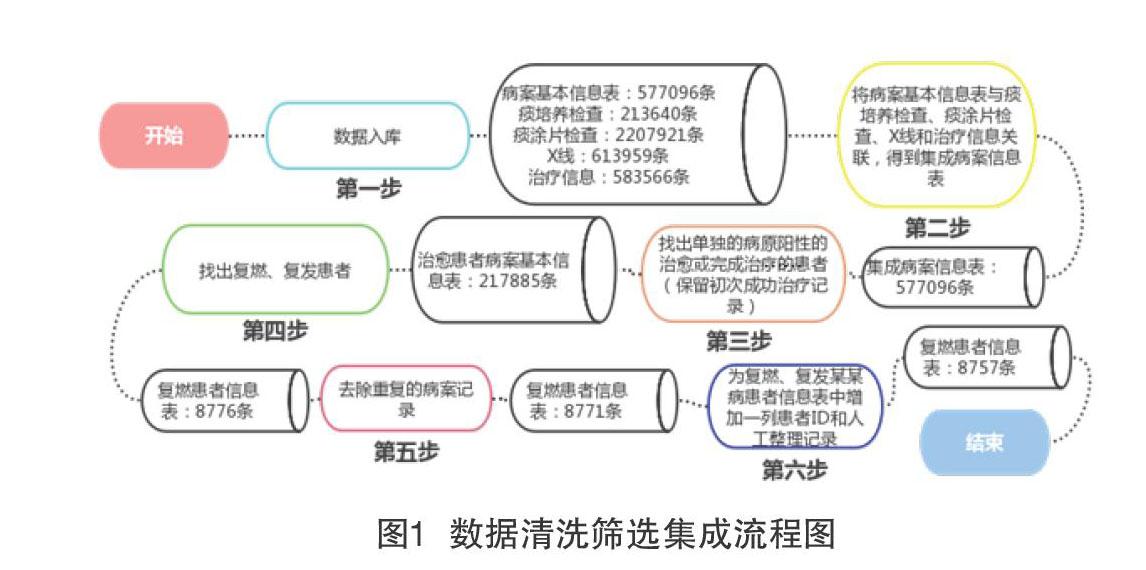
设计具体流程如图1所示。
2 数据转换及导入
MongoDB是一种NoSQL数据库,MongoDB可以实现多类数据的一体化存储、统一规则访问及多样性查询、关联检索等功能。将xls格式的2011~2019年某省某某病患者数据文件全部导入到MongoDB中。通过将病案基本信息表关联其他四个表(痰涂片检查、痰培养检查、X线和治疗信息)的信息,匹配的条件是病案ID和登记号,得到集成病案信息表。
这一步获得五个大表和一个总表,如表1。
3 找出已治愈的患者
从第一步得到的病案基本信息表里面筛选出已治愈的患者记录(包含221357条记录)并导入治愈患者信息表,其中主要伪代码如下:
输入:病案基本信息表
输出:治愈患者信息表
对病案基本信息表的每条记录R:{
如果 (R[“诊断结果”]∈[“涂片阳性”,“仅陪阳”,“仅分子生物学阳性”] 或
R[“分子检出结果”]==“检出”) 且 R[“停止原因”]∈[“完成疗程”,“治愈”]:{
将R加入治愈患者信息表}}
筛选条件是:“诊断结果”是“涂片阳性”、“仅陪阳”或者是“仅分子生物学阳性”,或者“分子检出结果”是“检出”。除此之外,“停止原因”是“完成疗程”或“治愈”。
然后再进行去重(即找出不重复的患者)并输出一个csv格式的文件。去重的条件是有相同的患者姓名、出生日期和性别,或者有相同的身份证号,或者有相同的患者姓名、出生日期和患者联系电话。去重去掉的是治愈患者第一次治愈记录之后的全部治愈记录。去重之后治愈患者信息表中还有217885条记录。
4 找出复燃、得发患者
遍历上一步得到的治愈患者信息表csv文件,在病案基本信息表中找出复燃、复发患者的所有初次治愈(包含初次治愈记录)后的记录:
对csv中的每一条记录:果身份证号不为空,用身份证号查询病案,看看是否有出现在该记录“停止时间”相同或之后的病原学阳性发病记录:
输入:治愈患者信息表csv
对治愈患者信息表csv的每条记录R:{
独特病案ID序列:=[]
独特病案记录序列:=[]
如果 R[“身份证号”] ≠ ””:{
身份证号查询结果 := 查询集成病案信息表 ((记录[“诊断结果”]∈[“涂片阳性”,“仅陪阳”,“仅分子生物学阳性”] 或 记录[“分子检出结果”]==“检出”) 且 (记录[“停止时间”] ≥R[“停止时间”] 且 记录[“停止原因”] ≠“诊断变更” 且 记录[“身份证号”] ==R[“身份证号”])
如果 身份证号查询结果记录的数目>1:{
对身份证号查询结果的每条记录D:{
如果 D[“病案ID”]独特病案ID序列:{
往 独特病案ID序列 加入D[“病案ID”]
往 独特病案记录序列 加入D
往 复发患者信息表-身份证号匹配 加入D }} }}
姓名出生日期查询结果 := 查询集成病案信息表 ((记录[“诊断结果”]∈[“涂片阳性”,“仅陪阳”,“仅分子生物学阳性”] 或 记录[“分子检出结果”]==“检出”) 且 (記录[“停止时间”] ≥R[“停止时间”] 且 记录[“停止原因”]≠“诊断变更” 且 记录[“患者姓名”] ==R[“患者姓名”]且 记录[“出生日期”] ==R[“出生日期”])
如果 姓名出生日期查询结果记录的数目>1:{
对姓名出生日期查询结果的每条记录D:{
如果 D[“病案ID”]独特病案ID序列:{
往 独特病案ID序列 加入D[“病案ID”]
往 独特病案记录序列 加入D }} }}
“停止原因”不能是“诊断变更”,因为“诊断变更”意味着并没有发病,诊断有误。
如果查询出来的记录数大于一,再对查询到的记录根据“病案ID”去重(每个病案ID对应一次发病记录),再将去重后的记录加入临时独特的记录序列和用身份证号匹配的复发患者信息表(中间结果),其“病案ID”加入临时独特的病案ID序列。
用姓名、出生日期查询病案,看看是否有出现在该记录“停止时间”相同或之后的发病记录:
如果查询出来的记录数大于1,再对查询到的记录根据“病案ID”去重,再将去重后的记录加入临时独特的记录序列,其“病案ID”加入临时独特的病案ID序列。去重后的记录如果不符合其他匹配条件就加入用患者姓名和出生日期匹配的复发患者信息表(中间结果),如果性别相同就加入用患者姓名、性别和出生日期匹配的复发患者信息表(中间结果),如果性别相同、户籍地址相同就加入用患者姓名、性别、出生日期和户籍地址匹配的复发患者信息表(中间结果),如果性别相同、现地址相同就加入用患者姓名、性别、出生日期和现地址匹配的复发患者信息表(中间结果),代码如图2所示。
如果上一步得到的临时独特的病案ID序列的元素个数大于1,将临时独特的记录序列中的记录按停止时间排序(升序)。然后对序列中的记录增加一个“第几次发病”字段值,再存入复发患者信息表。
5 去除复燃、复发某某病患者信息表中含有重复的病案ID的记录
由于第二步得到的去重之后的治愈患者信息表中仍然有可能有重复的患者,最后根据病案ID把重复的记录删去。患者ID是每个患者唯一的,可以通过患者ID找到某患者的全部发病记录。经过整理(包括合并同一个患者的两个患者ID的记录和删除不合适的数据),表中还剩下8757条记录。部分代码片段如图3。
图3 部分代码片段
第四步完成后,删去的重复记录是5条,得到的复发患者信息表有8757条记录。
6 结语
医疗系统包括各种各样的医疗信息,其中早期使用最广泛的数据表格主要是电子表格Excel,如何把相关表格导入到结构化数据库中,表之间的关系如何,在用户调研过程中要清楚,编程人员要找出表之间的关系,根据用户需求,通过选择不同的编程语言及数据库,同时优化数据库服务器,提高数据运行处理速度。还要注意算法的优化,比如在这个项目中同时用到了多个数据库查询,利用查询之间的关系优化算法,使得多条查询可以简化为一条查询。
参考文献
[1] 周羿阳. 基于Hadoop的医疗辅助诊断系统的设计与实现[D].上海:东华大学,2016.
[2] 梁晓杰. 基于Hana的医疗大数据多维度挖掘[D].上海:东华大学,2016.
[3] 王培勋,李冲,刘晓欢.基于医院信息数据挖掘的信息化临床路径在临床医疗费用监控中的应用[J].中国医学装备,2019,16(4):110-113.
[4] 梁小玲.探讨医疗大数据环境背景下健康信息的分析方法[J].信息技术与信息化,2018(6):87-88,91.
[5] 李伟,刘光明,张真发.基于MongoDB数据库的临床医疗大数据存储方案设计与优化[J].工业控制计算机,2016,29(1):121-123.
[6] 阮彤,高炬,冯东雷,等.基于电子病历的临床医疗大数据挖掘流程与方法[J].大数据,2017,3(5):83-98.
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
