
组合动作空间深度强化学习的人群疏散引导方法
2021-08-11 01:03薛怡然刘家锋
哈尔滨工业大学学报 2021年8期
薛怡然,吴 锐,刘家锋
(模式识别与智能系统研究中心(哈尔滨工业大学),哈尔滨 150001)
大型商场、写字楼等多功能建筑在满足人们多种需求的同时,建筑复杂程度逐渐提高。在发生地震、火灾等灾害时,建筑内复杂的结构对人群疏散逃生形成阻碍,对生命安全形成新的威胁。灾害发生时,人群由于对建筑物环境不了解、视野受限、心理恐慌等因素,难以准确找到最优逃生路线[1]。在从众心理的影响下,逃生者容易形成拥堵甚至踩踏,造成更大损失[2]。如何引导人群以最有效的路径疏散,对灾害中保护生命安全,减少人员财产损失具有重要意义。
为了在灾害发生时引导人群有效疏散,研究者开发了多种基于动态引导标志的人群疏散引导系统[3-6]。此类系统可以对建筑场景建模,收集灾害位置和人群分布等实时信息,用路径规划算法找出最优逃生路径,通过动态引导标志诱导人群的运动状态,有效地提高了紧急情况下人群逃生效率。但是,现有的人群疏散引导系统都离不开人工设计基于拓扑图或者网格形式的场景模型、根据场景特征手动输入模型参数等工作,人工工作量较大并且容易引入人为因素造成的误差,对后续路径规划等计算步骤造成干扰。
针对此问题,本文提出了基于深度强化学习算法的端对端的人群疏散引导方法。即训练一种仅以建筑平面图为输入,在与环境的交互和反馈中自动探索学习场景模型和路径规划方法,发现最优动作策略,直接输出动态引导标志信息的疏散引导智能体。为实现此方法,设计了基于社会力模型人群动力学仿真的强化学习智能体仿真交互环境,并针对深度强化学习中典型深度Q网络(DQN)[7]方法应用于人群疏散引导时出现的“维度灾难”问题,提出了组合动作空间的DQN方法,降低了网络结构复杂度,提高了算法在复杂建筑场景中的实用性。
1 相关工作
1.1 人群仿真与疏散引导
人群运动仿真是人群疏散研究中分析人群行为特征、自组织等现象的重要基础。人群仿真研究可分为宏观模型与微观模型。宏观模型主要考察人群整体的运动状态,一般采用元胞自动机等栅格模型[8]。例如用流体力学方法计算速度场,再作用于个体的高密度人群仿真方法[9],和基于格子玻尔兹曼模型的人群异常检测方法等[10]。微观模型用动力学方法仿真每个个体的运动特征,典型方法有引入人的主观因素的社会力模型[11-12]。
在仿真研究中,研究者希望提高疏散效率,使人群运动更贴近现实,因此人群疏散中的路径规划问题受到研究者的关注。有研究者分别利用群体智能的布谷鸟算法[13]和结合心理因素的A*算法[14]改进路径搜索方法。也有研究者结合多种传感器信息,例如构建威胁态势信息场的路径优化方法[15]、感知灾害位置的路径选择方法[16]、根据路径和出口容量优化的路径选择模型[17]等。仿真环境的路径规划方法可以综合环境信息,计算使全局疏散效率最高的逃生路径。在实际场景中,逃生者由于视野和经验受限,只能掌握自身周边信息,建筑物监测系统即使可以掌握优化的逃生路径,也需要专门途径告知逃生者。
为了指示逃生路线,大型建筑内一般设置有应急逃生标志。应急标志可分为静态引导标志和动态引导标志两类[18]。在真实场景实验[19]和基于社会力模型的仿真实验[20]中,静态引导标志都对疏散效率起到了重要的正面作用。不同于静态引导标志仅能指示一种预设的疏散路线,动态引导标志可根据灾害场景中人群分布等实时条件显示不同的引导信息。研究表明在某个出口不可用时,动态引导标志可以有效诱导人群从其他出口疏散[21],在路径中发生危险时,动态标志也能引导人群避开不安全的路线[22]。
将上述人群仿真环境、路径规划算法和动态引导标志相结合,研究者开发出了多种人群疏散引导系统。此类系统以建筑物环境模型为基础,实现了从场景信息感知、疏散路径规划到人群运动诱导的闭环反馈,具备一定的实用价值[3]。例如在拓扑图模型上基于网络流路径规划的动态引导方法[4]、使用仿真摄像机采集人群密度信息,应用实时最短路算法的动态疏散系统[5]。还有研究与现实建筑系统相结合,建立平行应急疏散系统框架,取得了更大现实意义[6]。
此类系统基本流程包含输入场景平面图、人工构建拓扑图或网格模型、根据通道容量等因素输入模型参数、应用路径规划算法和设置动态引导标志信息等几个步骤。其中构建模型和填写参数几个步骤的人工参与度高,工作量大,容易由于人为失误造成误差并在后续步骤中放大,使系统疏散效率受到影响。针对此问题,本文利用深度强化学习方法,提出端到端的动态人群疏散引导系统。
近年来,强化学习方法在人群疏散研究中得到了一些应用。研究者开发了数据驱动的强化学习人群仿真方法,用智能体模拟和预测个体的运动[23]。在路径选择问题上,有研究利用逆向强化学习方法使机器人模仿人类行动轨迹[24]。这些仿真研究目标是接近真实场景,而非优化疏散效率。对于疏散引导问题,一些研究者开发出多种使用强化学习智能体输出机器人运动方向,控制机器人在人群中运动,从而干涉人群运动状态,提高疏散效率的方法[25-27]。此类方法在单个路口的仿真实验中取得了一定效果,但在实际应用中存在加剧人群拥挤、引发踩踏事故等隐患。现有基于强化学习的研究将逃生者个体或机器人个体定义为智能体。与此不同的是,本文将疏散引导系统定义为强化学习智能体,其以场景图像为观测输入,输出遍布场景的多组动态引导标志信号,从而诱导人群运动,提高疏散效率。
1.2 深度强化学习
强化学习[28]是人工智能领域的重要组成部分之一,是一种通过与环境的交互和试错,学习从环境状态到动作的映射,发现最优行为策略,以使从环境获得的积累奖赏最大的学习方法。结合深度神经网络,深度强化学习智能体能直接以图像作为输入,将特征提取和值函数估计等过程内化在网络结构中,显著拓展了智能体的感知和决策能力。深度强化学习的标志性成果包括在Atari视频游戏中超越人类玩家水平的DQN方法[7]、在围棋中战胜人类顶级选手的AlphaGo[29]和在星际争霸2游戏在线对战中打入大师级排行的AlphaStar[30]等。
强化学习模型[28]基于马尔可夫决策过程(MDP),可描述为四元组(S,A,Pa,Ra),其中S为所有状态的集合,即状态空间,A为动作空间,状态转移函数Pa(s,s′)=P(st+1=s′|st=s,at=a)表示在状态s时智能体执行动作a,环境进入状态s′的概率,奖励函数Ra(s,s′)表示在状态s执行动作a进入状态s′时所获得的即时奖励。智能体在每个离散的时间步t,观测环境状态st,根据策略π∶S→A选择动作at=π(st)作用于环境,环境反馈给智能体奖励rt,并转移到下一个状态st+1。智能体与环境的交互过程见图1。
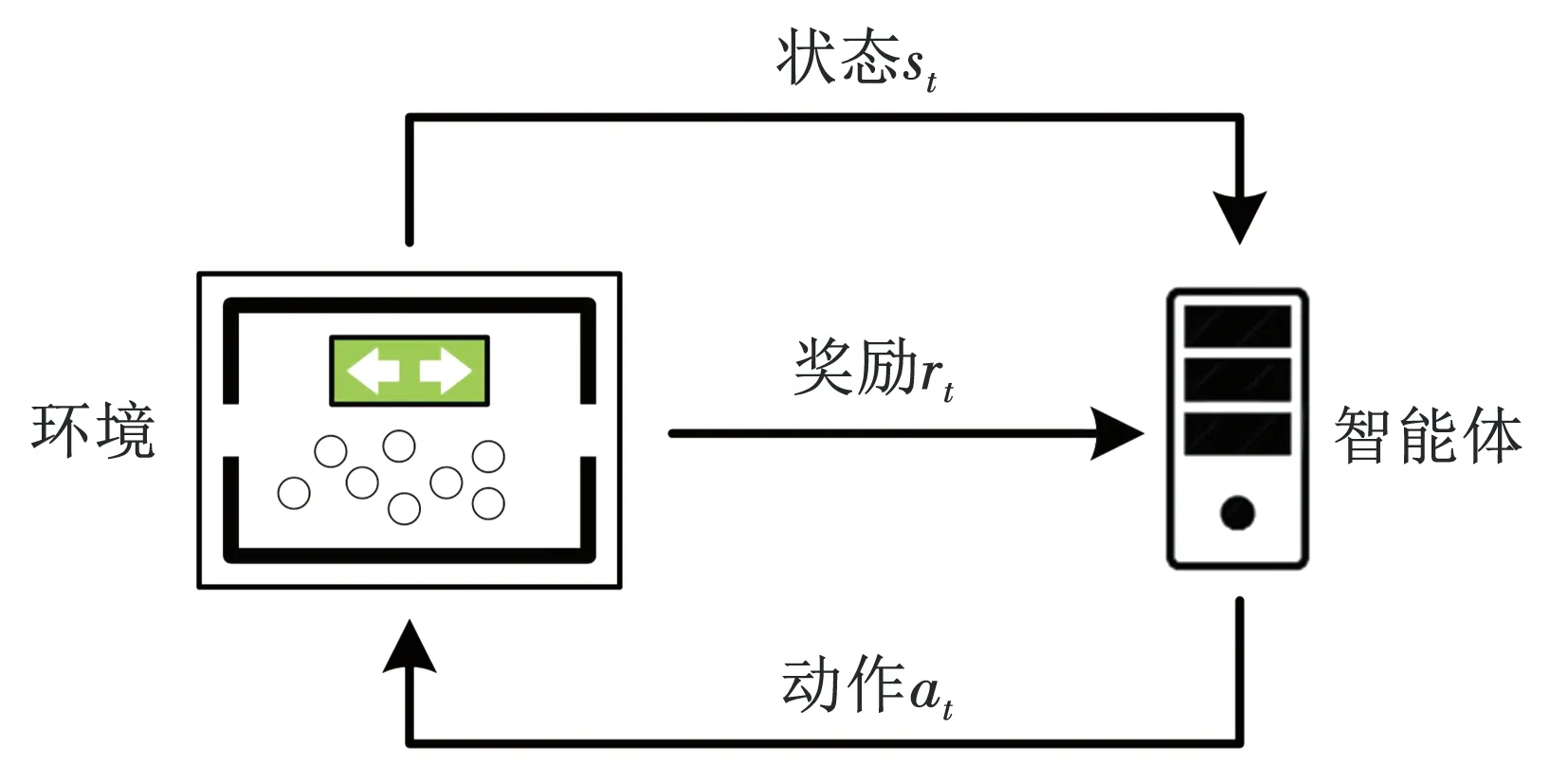
图1 强化学习模型示意Fig.1 Schematic of reinforcement learning model
在强化学习的MDP模型基础上,定义状态-动作值函数,也可称作动作值函数
Qπ(st,at)=Eπ[rt+γrt+1+γ2rt+2+…]
(1)
表示按策略π,在状态st时执行动作at之后获得的期望累积奖励,其中γ为奖励衰减系数。谷歌DeepMind团队开发的DQN方法[7]用深度神经网络表示动作值函数,且分为参数为θ的当前Q网络和参数为θ-的目标Q网络,每隔一定时间将当前Q网络参数复制到目标Q网络中。DQN的策略π为贪婪策略,总是选择当前状态下Q值最大的动作,训练时加入一定概率选择随机动作作为探索过程。DQN使用经验池存储和管理样本,对于一个时间步的样本et=(st,at,rt,st+1),计算时序差分(temporal difference,TD)误差
(2)
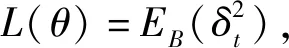
DQN在以图像为输入的Atari视频游戏等任务上取得突破。研究者在DQN的基础上,提出了用当前Q网络进行目标动作选取的Double DQN(DDQN)方法[31]、用TD误差区分经验池中样本优先级的优先经验回放[32]等改进方法。
然而,DQN输出的动作空间是离散的,并且对每一种可能的动作组合使用一个输出层节点进行评价,因此当动作维数增加时,网络复杂度将以指数方式增长。在人群疏散引导问题中,智能体以动态引导标志的显示状态作为输出动作,每个标志的离散动作形成独立的动作维度。在复杂建筑场景中动态引导标志数目较多时,DQN的输出层规模将变得过于庞大而使算法无法实现。
2 基于组合动作空间DQN的疏散引导
2.1 人群疏散引导的强化学习模型
人群疏散引导问题涉及3类对象,包括建筑场景、逃生者和智能疏散引导系统。现有研究常将每个逃生者个体定义为一个智能体,研究个体的行动策略和运动状态,或添加可动机器人个体作为智能体。与此不同的是,本文将疏散引导系统看作一个智能体,如图2所示,则智能体所处的环境包括实际建筑场景和其中运动的人群。建筑场景由平面图表示,摄像机等多种传感器收集人群运动状态,绘制进场景平面图,此图像即包含了当前环境中所需的信息,连续多帧图像的灰度位图组合成(width×height×depth)三维张量,定义为MDP的环境状态st∈S。对于多层建筑,可以将不同楼层平面图拼接成整体场景图像输入系统,从而实现多层建筑中的疏散引导。疏散引导系统通过动态引导标志显示信号,诱导、干涉人群运动,因此智能体动作at∈A对应引导标志信号,at是离散向量,每个维度对应一个引导标志,取值为此标志显示状态(向左、向右等)之一。由于环境和人群运动较为复杂,状态转移函数Pa(s,s′)是未知的,需要智能体在交互过程中学习和适应。奖励函数的设计决定了智能体的优化方向和学习目的,在人群疏散问题中,应根据成功撤离的人数或疏散所用时间等因素设计奖励函数。本文定义Ra(s,s′)=-1,即每个时间步固定给予惩罚,智能体的学习目标是使累积惩罚最小,即全体人群疏散时间最短。
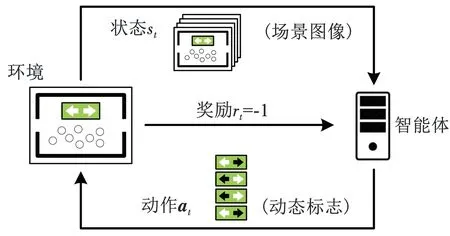
图2 人群疏散引导的强化学习模型Fig.2 Reinforcement learning model for evacuation guidance
强化学习智能体的训练过程需要与环境不断交互,在探索和试错中学习。其所需的交互规模十分庞大,一般在数万个周期、百万个时间步以上。并且训练初期智能体知识不足,可能造成更多潜在危险。
因此用于智能疏散引导系统的强化学习智能体必须在仿真环境中进行训练,训练完成后再部署到实际建筑内。
疏散引导系统智能体通过与仿真环境的大量交互进行探索与学习,最终得到神经网络形式的优化策略π(s)。学习过程中不需要人工设计建筑通道拓扑图或网格模型,智能体能自主发现和优化引导策略,不需要另外设计路径规划等中间算法。实际应用中,每个时刻t传感器收集人群运动信息,将人群位置分布、当前引导标志显示状态等信息绘制进场景平面图。利用卷积神经网络对图像的感知能力,多帧场景灰度位图组成三维张量传入神经网络,作为智能体输入的观测状态st,智能体根据训练完成后包含优化策略的神经网络计算动作向量at=π(st),由动态引导标志显示对应信号,实现对人群疏散的有效引导。
2.2 组合动作空间DQN
在网络结构上,DQN采用多层卷积神经网络处理图像输入,然后连接多层全连接神经网络,输出层每一个神经元对应一种可能的离散动作组合。对于动作中相互独立的成分,总的动作空间是各个独立动作空间的笛卡尔积。当动作空间有n个相互独立的维度,每个维度有m个离散动作时,DQN网络需要mn个输出层节点,以对应输入状态s时不同动作Q(s,a)的值。因此,随着独立动作数目的增长,DQN的网络结构复杂度以指数速度增长,从而使算法不可实现。同时输出层过多也会导致样本利用率降低和网络参数更新困难。这个现象被称为DQN的“维度灾难”问题。
在人群疏散引导的应用当中,智能体动作定义为引导标志的显示状态。即使每个引导标志只有向左和向右两个状态,对于n个引导标志,总的动作空间容量也会达到2n之多,引发“维度灾难”。本文针对此问题,提出组合动作空间的DQN方法(CA-DQN)。如图3所示,对于相互独立的动作维度,每个维度对应Q函数网络输出层一组节点,每组包含这个维度上的所有离散动作。这个改变可看作对每个动作维度d设置了各自的值函数Qd(s,a(d);θ),并且共用一套网络参数。此时网络输出层节点数目是各个维度上离散动作数之和,随独立动作数目的增长速度从指数增长降为线性增长,例如n个引导标志所需输出层节点为2n。

图3 CA-DQN神经网络结构Fig.3 Network structure of CA-DQN
(3)
对于一个样本et=(st,at,rt,st+1)定义每个维度上的TD误差
(4)
结合研究者提出用当前Q网络选择t+1时间动作,以避免过高估计的DDQN算法[31],TD误差进一步定义为
(5)
则从经验池中采样所得一组样本B={e1,…,et},神经网络的损失函数定义为平方误差损失的算术平均值
(6)
神经网络按式(6)定义的损失函数用误差反向传播算法进行训练。此时,对于每个样本,动作的每个维度都有一个输出层节点被选择并参与TD误差的计算和网络误差的反向传播,则共有D个输出层节点可以得到更新。相比DQN中每个样本只能更新一个输出层节点,CA-DQN方法提高了样本的利用效率。
2.3 组合动作空间DQN的优先经验回放
DQN以随机方式从经验池中采样,不考虑样本差异,样本利用效率较低。采用优先经验回放方法[32],用式(2)定义的样本TD误差,将样本采样优先级定义为pt=(|δt|+ε)α,其中ε和α为常数。TD误差绝对值越大的样本意味着所包含的有效信息越多,对其赋予更高采样优先级,可提高样本利用率和训练效率。
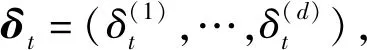
(7)
样本优先级定义为平均值可能使样本重要性被其他动作维度稀释,但有助于保持训练过程的稳定性。
结合以上优先经验回放方法,CA-DQN的训练过程如下:

算法1:智能体训练过程
输入:仿真环境 env
输出:神经网络参数θ*
1随机初始化神经网络参数θ,θ-
2初始化经验池 pool
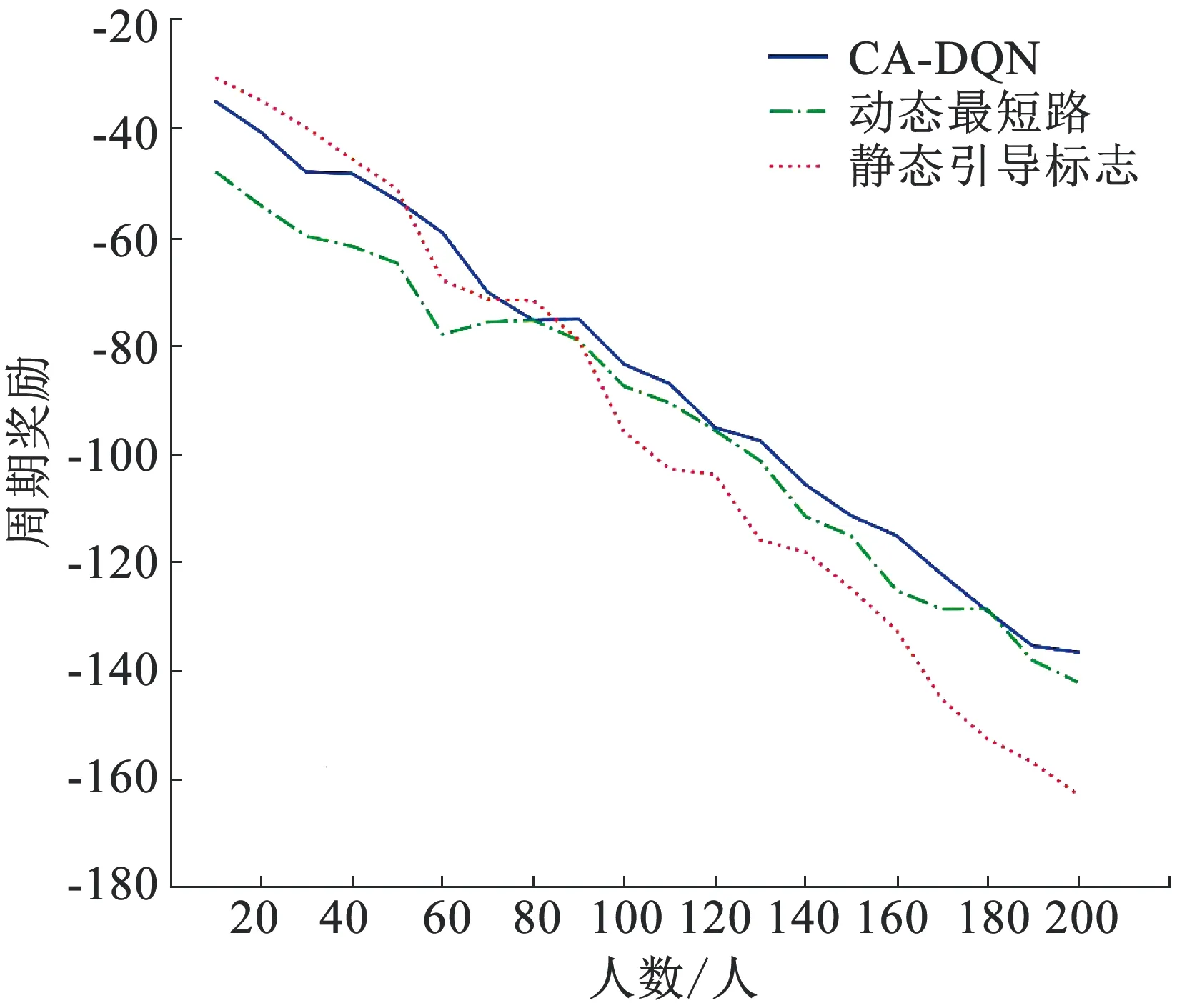
3whilesteps 4state,reward,terminate ← env.RandomInit()//随机初始化仿真环境 5whilenot terminatethen 6action ← AgentPolicy(state,θ)//按式(3)选择动作 7state_new,reward,terminate ← env.Step(action) 8td_error ← CalcTDError(state,action,reward,state_new,θ,θ-)//按式(5)计算TD误差 9priority ← CalcPriority(td_error)//按式(7)计算样本优先级 10pool.Append(state,action,reward,state_new,priority) 11state ← state_new 12steps ← steps + 1 13s,a,r,s' ← pool.RandomSample(batch_size)//按优先级随机采样 14td_error ← CalcTDError(s,a,r,s',θ,θ-)//按式(5)计算TD误差 15loss ← CalcLoss(td_error)//按式(6)计算损失函数 16θ← BackPropagation(θ,loss)//更新网络参数 17每隔一定步数θ-←θ 18end 19每隔一定周期数计算平均周期回报,若性能提升θ*←θ 20end 本文采用基于社会力模型的人群动力学仿真系统[5]作为智能体交互环境,构造了典型的多房间、双出口室内场景,以下称为“场景1”。多层建筑场景可通过拼接各层平面图输入疏散引导系统,本文为直观起见,采用单层仿真场景。仿真系统计算每个个体的运动状态,并加入个体心理因素对运动造成的影响。仿真系统基于C++语言和Qt库编写。 如图4所示,仿真场景大小为29.2 m×19.7 m,平面图像素为499×337,场景内包含左右2个出口和6个房间,上下2个通道连接房间和出口,每个通道设置5个动态引导标志,标志可显示相对两个方向之一。人群数量为200人,初始位置以圆形范围随机分布,分布中心和半径取值范围为x∈(100,140),y∈(60,280),r∈(100,200)。场景图像中,蓝色直线表示墙壁,绿色矩形表示出口位置,绿色箭头表示动态引导标志,每个标志有相反两个方向的显示状态,蓝色圆点表示逃生者个体,灰色部分为不可到达区域。个体最大运动速度为5 m/s。仿真个体在没有看到疏散引导标志时,选择距离最近的出口,按照静态最短路线逃生,看到疏散引导标志时,按照引导标志指示的方向逃生。仿真系统动力学计算的每个时间步为40 ms,仿真时间上限为100 s。 图4 仿真场景1Fig.4 Simulation scene 1 同时,本文也采用原交互环境中基于实际建筑平面图的仿真场景[5]进行实验,如图5所示,以下称为“场景2”。场景图像中符号含义与场景1相同。场景大小为47.0 m×28.8 m,图像像素为805×494,人群数量为200人,分布中心和半径取值范围为x∈(100,700),y∈(60,440),r∈(300,500),场景内共有2个出口和6个动态引导标志。不同仿真场景的强化学习智能体由于输入输出定义不同,疏散策略不同,需要分别进行训练。 图5 仿真场景2Fig.5 Simulation scene 2 CA-DQN方法基于Python语言、TensorFlow平台和OpenAI/baseline库实现。实现过程与超参数的选择参考了baseline库中用于Atari视频游戏的DQN方法,并针对本文方法进行适当调整。强化学习智能体的每个时间步中,首先由仿真系统进行5步计算,即仿真200 ms内人群的运动状态,将获得的最后4帧图像下采样为1/2大小的灰度图,以场景1为例,组合成像素为249×168的4通道图像,作为智能体的状态st输入值函数Q网络。Q网络结构如图3所示,由三层卷积神经网络和三层全连接神经网络组成。第一层由32组8×8卷积核组成,输入为249×168×4的三维张量,第二层由64组4×4卷积核组成,第三层由64组3×3卷积核组成。卷积神经网络的激活函数为ReLU。三层全连接层神经元数目分别为128、64、32,激活函数为ReLU。输出层激活函数为恒等函数,20个神经元分为10组,每组2个中取输出值较大的作为一个动态引导标志的显示信号,共同组成10维离散输出向量作为智能体动作at。at作用于仿真系统,改变10个引导标志显示的方向,从而指引人群运动方向,此时智能体与仿真环境的交互完成一个循环。智能体每步的奖励固定为-1,即每秒获得-5的奖励,智能体训练目标为减少总体疏散时间。 训练超参数中,批量大小为64,学习率为10-5,总时间步为107,经验池样本容量为105,每2×104步将当前Q网络参数复制到目标Q网络。实验硬件平台为AMD Threadripper 2990WX CPU、NVIDIA RTX 2080Ti GPU、128 GB内存。 由于原DQN方法用于本文实验时,以场景1为例,需设置210=1 024个输出层节点,相比CA-DQN的20个节点,DQN网络规模过大,在现有条件下难以实现。因此本文选择基于静态引导标志的方法和基于拓扑图建模和动态Dijkstra最短路方法的疏散引导算法[5]作为对比。静态引导标志方法中,用自动或人工的最短路方法计算,每个标志指向距离最近的出口,每个场景仅计算一次,不考虑人群实时分布,模拟过程中标志不发生变化。动态Dijkstra最短路方法需要专家人员根据地图内通道结构人工建立拓扑图模型,并且设置多个虚拟摄像头节点,统计通道不同位置的人群密度,实时调整拓扑图各边权值,用Dijkstra算法进行路径规划,实现人群的有效疏散。实验结果中,每1 s疏散时间对应-5的周期奖励。 由图6的训练曲线看出,对于场景1,智能体在约3×104个训练周期后达到最优策略,此时智能体与仿真环境交互次数约为6.4×106个时间步。图7中,对于场景2,智能体在约4.5×104个训练周期后达到最优策略。如表1所示,对不同疏散方法使用新的随机人群分布参数进行100个周期的疏散仿真,场景1中智能体训练所得最优策略的平均周期奖励为-158.25,即平均疏散时间为31.65 s,优于使用静态引导标志的41.35 s和动态Dijkstra最短路方法的32.18 s。场景2中智能体训练所得最优策略平均疏散时间为27.33 s,优于静态引导标志和动态最短路方法。说明本文基于CA-DQN的智能疏散引导智能体可以有效引导人群疏散。 图6 场景1智能体训练曲线Fig.6 Training curve of agent in scene 1 图7 场景2智能体训练曲线Fig.7 Training curve of agent in scene 2 表1 不同方法疏散时间Tab.1 Evacuation time under different methods s 图8展示了场景1中一个典型的疏散过程(图中符号含义请参考3.1节):图8(a)是人群的初始分布,人群主要分布于左侧4个房间,若没有动态指引,人群按到出口距离最短的静态标志疏散策略,将造成左侧出口拥堵,右侧出口得不到有效利用。在图8(b)到图8(d)时刻,智能体感知到人群分布,将左上方房间人群引向左侧出口,其余人群引向右侧出口。图8(e)时刻,左侧出口拥堵已得到缓解,右侧出口预期撤离人数较多,因此智能体将左下区域剩余人群引向左侧出口。最终在图8(f)时刻,人群基本同时从两侧出口完成疏散,表明人群疏散引导智能体实现了人群疏散效率的最大化。 图8 场景1一个周期的疏散过程Fig.8 Typical evacuation process in scene 1 类似地,图9展示了场景2中典型的一个疏散过程。图9(a)中,人群初始化分布主要集中在场景上方。图9(b)时刻,智能体感知人群分布,将左上方房间以外的大部分区域人群向右下方出口诱导。图9(c)到图9(d)时刻,一部分人群有效地转移至右侧通道,避免了左上方出口进一步拥堵。最终,在图9(e)到图9(f)时刻,人群基本同时从两个出口完成疏散,说明智能体的引导实现了人群疏散效率最大化。 图9 场景2一个周期的疏散过程Fig.9 Typical evacuation process in scene 2 改变仿真场景初始化人数,分别进行100个周期的疏散仿真,不同方法的疏散效果对比见图10。场景1中,在人数较少时,各个通道都能保持通畅,静态引导方法效果较好。人群数量增加时,静态引导方法受影响较大,CA-DQN和动态最短路方法可以避免人群拥堵。人群数量增加到80人以上时,两种动态方法疏散效果优于静态方法,其中本文CA-DQN方法实现了最优疏散引导效率。场景2的实验也显示出类似结果,由图11看出,本文方法在不同人群数量下均能取得较好效果。 图10 场景1中不同人数的周期奖励Fig.10 Period reward with varying number of persons in scene 1 图11 场景2中不同人数的周期奖励Fig.11 Period reward with varying number of persons in scene 2 实验结果显示,相比静态标志不能感知人群分布信息,本文基于CA-DQN的强化学习人群疏散引导方法能动态地调整引导标志的显示信号,有效提高人群疏散效率。与基于拓扑图建模的动态Dijkstra最短路方法相比,本文方法取得了更好的疏散引导效率,同时避免人工构造拓扑图的工作量和潜在的人工误差。 本文分析了使用动态引导标志的人群疏散引导问题,针对现有方法需要人工设计拓扑图模型或网格模型,配合独立的路径规划算法,导致人工工作量大、容易引入人为误差等不足之处,提出了基于组合动作空间深度强化学习的人群疏散引导方法。通过端对端的深度学习,由智能体在训练过程中自行探索学习建筑结构和路径规划方法,通过环境反馈自动修正认知误差,从而找到最优的疏散引导策略。 针对深度强化学习中典型的DQN方法应用于人群疏散问题时因输出的动态引导标志数量较多而出现的“维度灾难”问题,本文提出CA-DQN网络结构,将关于输出动作维度的网络结构复杂度从指数级增长降低为线性增长,提高了强化学习方法在复杂场景和大规模人群疏散问题中的可用性。在基于社会力模型的人群动力学仿真系统中的实验表明,本文方法相对静态引导标志有效提升了人群疏散效率,减少疏散时间,达到与基于人工建模的动态最短路方法相同水平。 未来工作将进一步提升强化学习智能体在复杂场景中的训练效率,对输出信号变更频率等加以更多限制,使其在真实场景中更易理解。3 实验与分析
3.1 实验设计与实现
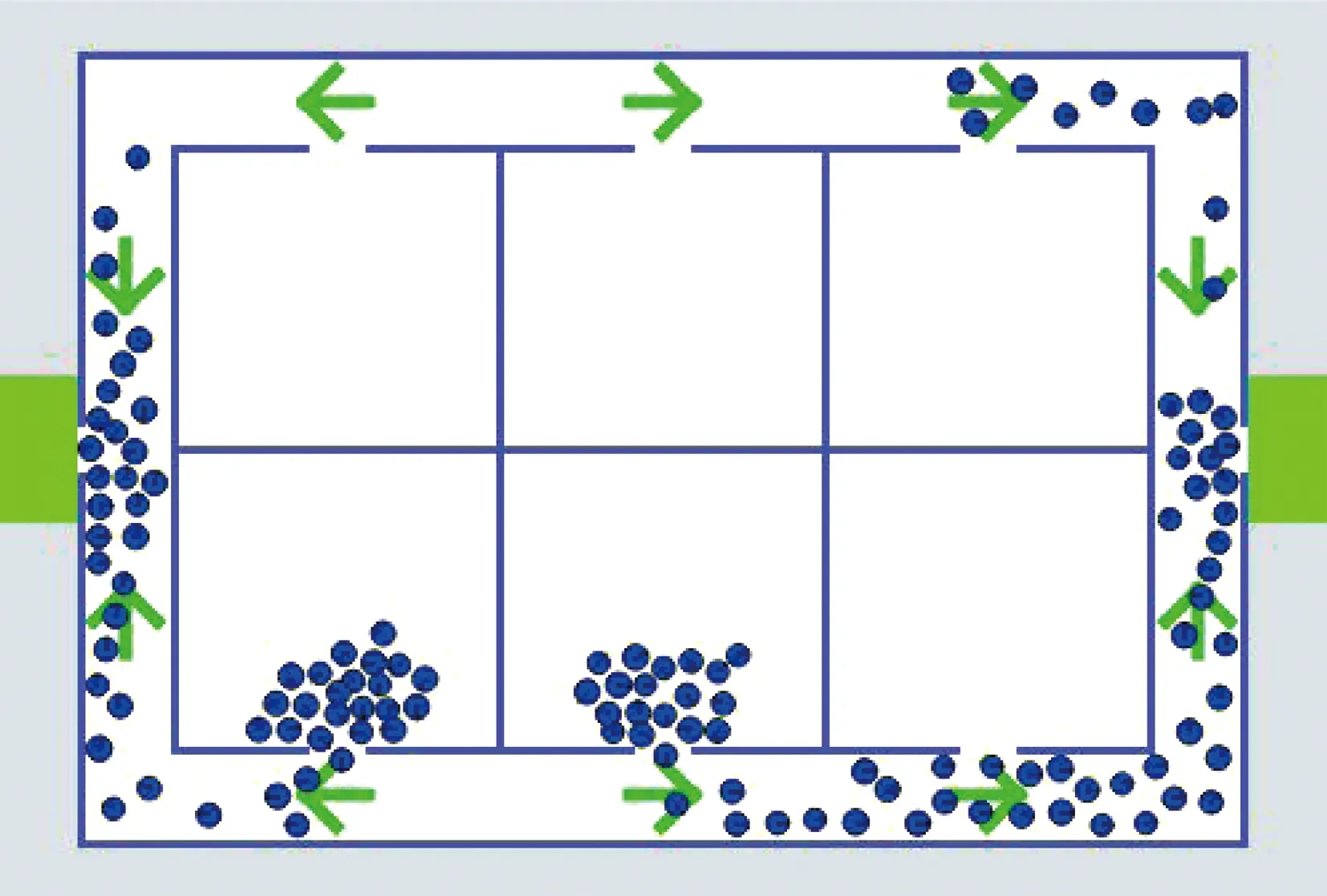

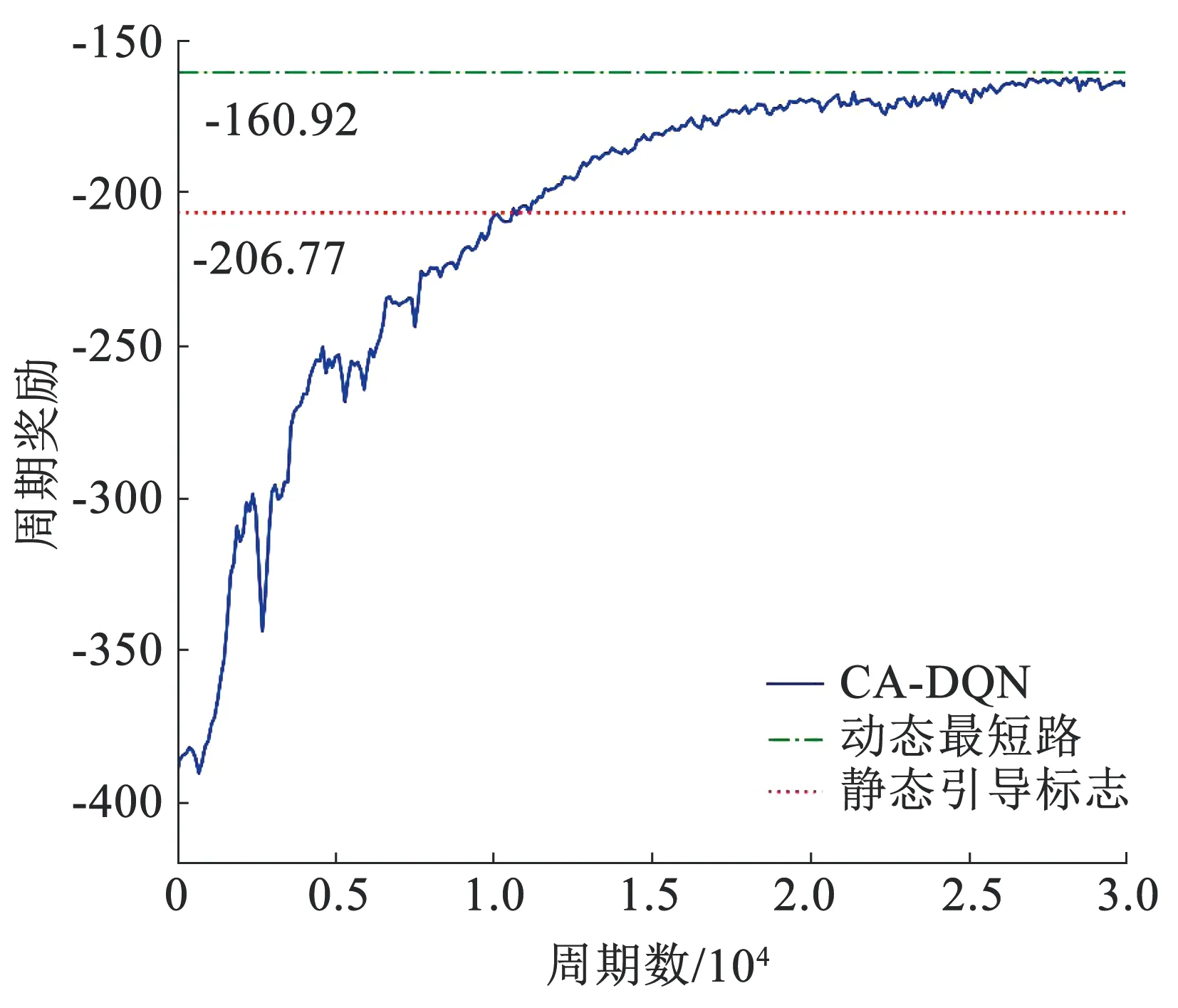
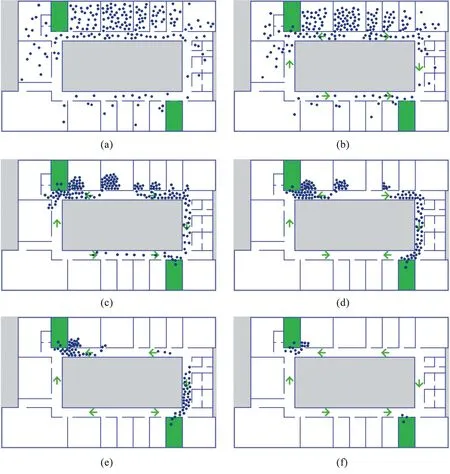
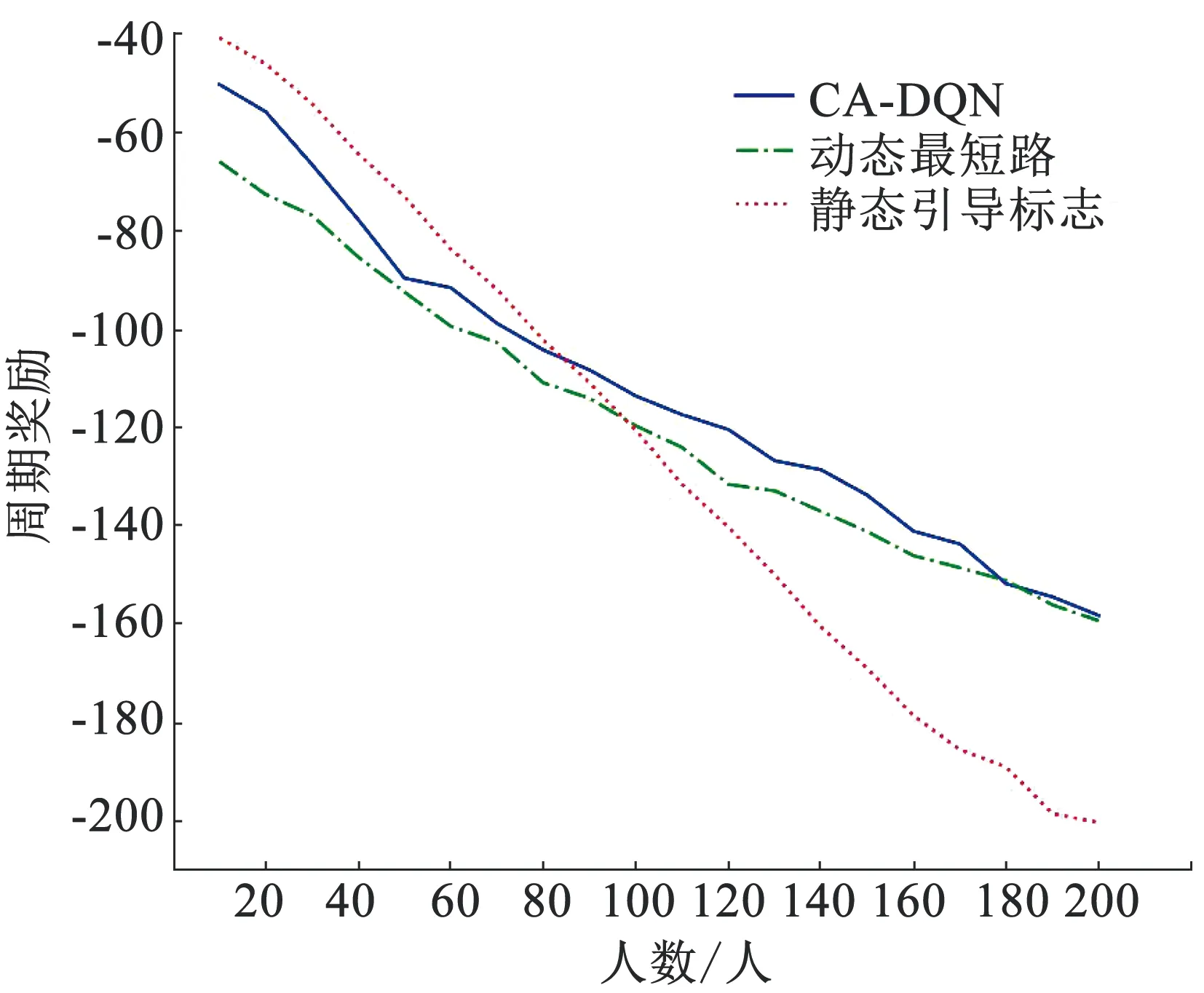
3.2 实验结果与分析



4 结 论
猜你喜欢
卫星应用(2022年7期)2022-09-05
玩具世界(2022年1期)2022-06-05
卫星应用(2022年3期)2022-05-23
体育教学(2022年4期)2022-05-05
卫星应用(2022年1期)2022-03-09
恋爱婚姻家庭(2020年27期)2020-10-09
环球慈善(2019年6期)2019-09-25
漫画月刊·哈版(2019年4期)2019-04-18
百花洲(2018年1期)2018-02-07
瞭望东方周刊(2017年45期)2017-12-08
