
用于巡航导弹突防航迹规划的改进深度强化学习算法
2021-08-29 07:00马子杰武沛羽谢拥军
电子技术应用 2021年8期
马子杰,高 杰,武沛羽,谢拥军
(北京航空航天大学 电子信息工程学院,北京 100191)
0 引言
巡航导弹是一种能机动发射、命中精度高、隐蔽性强、机动性能强的战术打击武器,但近年来由海陆空防御武器整合得到的体系化信息化反导防御系统态势感知能力和区域拒止能力都得到了极大的提升,巡航导弹的战场生存能力受到威胁,提升巡航导弹规避动态威胁的能力成为其能否成功打击目标的关键[1-3]。传统的巡航导弹航迹规划方法中将雷达威胁建模为一个静态的雷达检测区域,这难以适应对决策实时性要求较高的动态战场环境,而且其缺乏探索先验知识以外的突防策略的能力,需要研究能应对动态对抗的巡航导弹智能航迹规划算法。
深度强化学习是人工智能领域新的研究热点[4-6]。随着深度强化学习研究的深入,其开始被应用于武器装备智能突防,文献[7]利用深度强化学习提出了一种新的空空导弹制导律,提高了打击目标的能力。文献[8]针对目标、打击导弹、拦截导弹作战问题,探究了是否发射拦截导弹、拦截导弹的最佳发射时间和发射后的最佳导引律。文献[9]利用深度价值网络算法探究了静态预警威胁下的无人机航迹规划问题,提升了航迹规划的时间。文献[10]将雷达威胁建模为一个静态的雷达检测区域,在二维平面探究了巡飞弹动态突防控制决策问题,提高了巡飞弹的自主突防能力。
综上所述,目前巡航导弹智能突防研究中针对预警雷达的威胁建模都属于静态建模,其设定预警机威胁区域固定,而实际战场环境中预警机是动态的,因而其威胁区域也是动态变化的。因此,本文提出了两点改进:(1)对预警机威胁进行动态建模,给出了预警机雷达探测概率的预测公式;(2)使用深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法训练时引入了时序相关的奥恩斯坦-乌伦贝克随机过程作为探索噪声,解决了收敛难度加大的问题,进而缩短了算法的训练时间。
1 DDPG 算法及其改进
DDPG[11-13]是深度强化学习应用于连续控制强化学习领域的一种重要算法,将确定性策略梯度算法与Actor-Critic 框架相结合,提出了一个任务无关的模型,并可以使用相同的参数解决众多任务不同的连续控制问题。DDPG 采取经验回放机制,通过目标网络的参数不断与原网络的参数加权平均进行训练,以避免振荡。深度确定性策略梯度算法流程如下:
输入:环境;
输出:最优策略的估计;
参数:学习率α(w)、α(θ)、折扣因子γ、控制回合数和回合内步数的参数、目标网络学习率α目标。
(1) 初始化网络参数:θ←任意值,θ目标←θ,w←任意值,w目标←w。
(2) For episode=1,M do(M 为仿真最大回合数)
(3) 用对π(S;θ)加扰动进而确定动作A
(4) 执行动作A,观测到收益R 和下一状态S′
(5) 将经验(S,A,R,S′)储存在经储存空间D
(6) For t=1,T do(T 为仿真终止时间)
(7) 从存储空间D 采样出一批经验B
(8) 为经验估计回报U←R+γq(S′,π(S′;θ目标);w目标)

1.1 DDPG 算法求解流程
DDPG 算法的网络结构为Actor-Critic 网络结构,其中Actor 网络输入状态,输出动作,Critic 网络输入状态和动作,输出在这一状态下采取这个动作的评估Q 值,其示意图如图1 所示。由于巡航导弹、目标和预警机的状态动作信息是一个在时间上连续的序列,因此由状态构成的样本之间并不具备独立性,只使用单个神经网络结构学习过程很不稳定。为解决这个问题,DDPG 算法引入了经验回放机制,引入目标Actor 网络和目标Critic 网络,与现实网络独立训练。首先现实Actor 网络与环境进行交互训练,得到状态S、动作a、奖励r、下一时刻状态S′,将这4 个数据放入经验池中,得到一定的样本空间后,现实Critic 网络从经验池中提取样本进行训练得到Q 值;目标网络也进行同样的训练,每间隔一定时间就利用现实网络参数更新目标网络。训练完成后可以通过Actor 网络得到高维的具体动作,可解决连续动作空间学习问题。其求解流程如图2 所示。
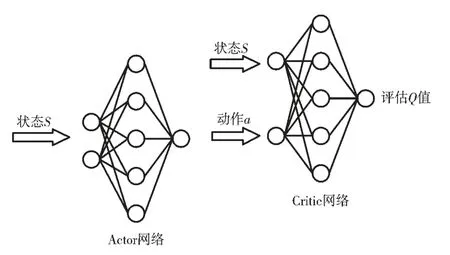
图1 Actor-Critic 网络结构
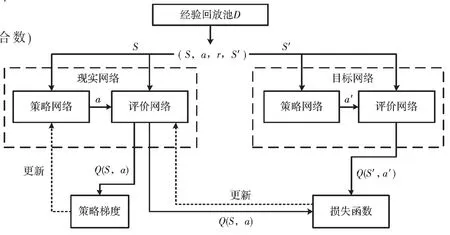
图2 DDPG 算法流程图[10]
1.2 DDPG 算法的改进
1.2.1 时序相关的探索噪声
传统的DDPG 算法中的探索噪声为高斯噪声,其在时序上不相关,对时序相关的问题探索能力差,探索时间长;导弹突防过程属于惯性过程,引入时序相关的奥恩斯坦-乌伦贝克随机过程可以提高在惯性系统中的控制任务的探索效率,使训练更快收敛。奥恩斯坦-乌伦贝克过程满足的微分方程为:

其中,xt为过程刻画的量;θ为比例系数;μ是xt的均值;Wt为维纳过程,是一种随机噪声;σ 是随机噪声的权重。
1.2.2 动态预警威胁
预警机是一种装有远距离搜索雷达、数据处理、敌我识别以及通信导航、指挥控制、电子对抗等完善的电子设备,用于搜索、监视与跟踪空中和海上目标并指挥、引导己方飞机执行作战任务的作战支援飞机,起到活动雷达站和空中指挥中心的作用,是现代战争中重要的武器装备。DDPG 算法应用于突防策略研究时,一般将预警机雷达威胁简化为一个静态的禁飞区,但这样无法反映真实作战场景下巡航导弹遇到的动态预警威胁,因此在解决巡航导弹突防航迹规划问题时,需要在DDPG 算法中引入预警机雷达动态探测概率预测公式。
E2-D 预警机的雷达在一定的虚警概率下,一次扫描对目标的发现概率为[14]:

式中:
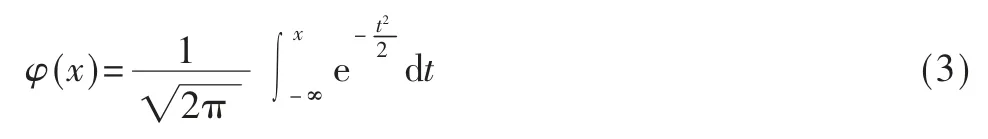
其中,no为一次扫描脉冲积累数,yo为虚警时的检测门限,S/N 为信噪比。
对其曲线进行拟合可得预警雷达探测瞬时概率与目标的雷达散射截面积值σ 和目标与雷达的R的计算公式为:

其中,R的单位为km,σ的单位为m2;c1与c2和雷达的工作模式和场景有关,本文分别取为1.5和1.5×10-8.5。
2 巡航导弹突防决策模型
巡航导弹突防过程为一个马尔科夫决策过程(Markov Decision Process,MDP),需要对导弹运动模型、状态空间、动作空间、奖励函数进行建模。
2.1 导弹运动模型
可以对突防过程的弹道进行简化:导弹和预警机均可视为质点,巡航导弹采用3自由度质点运动。
2.2 状态空间设计
由于对抗双方均设为质点,可以将巡航导弹、目标、预警机的质心位置ot、弹目质心位置的距离lt以及航向角φt作为状态空间,即状态空间为st=[ot,lt,φt]。
2.3 动作空间设计
巡航导弹处在一个连续的动作空间,其动作空间设为巡航导弹在x、y、z 3 个方向的速度分量,即vx、vy、vz。
2.4 奖励函数设计
2.4.1 导弹成功击中目标奖励
巡航导弹采取突防策略的主要目的是在避开预警威胁的情况下,成功击中目标。其奖励函数为:

2.4.2 导弹和目标相对距离奖励
导弹可目标的距离越近,导弹击中目标的可能性越大,其奖励函数为:

其中,lt为导弹与目标当回合的距离。
2.4.3 导弹速度和弹目连线夹角奖励
导弹速度和弹目连线夹角即为视线角,视线角越小,巡航导弹击中目标的可能性越大,其奖励函数为:

其中,φt为导弹与目标当回合的视线角。
2.4.4 视线角变化率奖励
视线角变化率奖励的具体形式为:

其中,φt-1为导弹与目标上一回合的视角。
2.4.5 探测概率降低奖励

其中,Pd为雷达探测概率,k 为比例系数。
综合考虑上述5 种奖励模型,每回合巡航导弹的动作奖励为:

训练完成后的总奖励为:

3 仿真结果与分析
3.1 仿真场景及武器性能参数
仿真场景主要对巡航导弹、攻击目标、预警机的位置、机动参数和机动范围进行设置。作战场景如图3 所示,主要为巡航导弹、目标和预警机的空间位置关系。预警机在7 500 m 高度以“跑道形”巡逻线探测巡航导弹,直边长度为70 km,弧线半径为15 km,航线中心点坐标为东经119.5°、北纬20°、海拔7 500 m。巡航弹目标为位于东经120°、北纬20°、海拔15 m的宙斯盾舰船,巡航导弹的发射点位于东经117.5°、北纬20°、海拔15 m。其中巡航导弹的最大巡航速度为300 m/s,目标的最大速度为200 m/s;当巡航导弹和目标的相对距离小于0.05 km时假定巡航导弹击中目标。

图3 巡航导弹突防典型作战场景
3.2 软硬件环境及参数设置
仿真的软件环境为:Windows 10、Python3.7以及TensorFlow 架构,硬件环境为GTX2060 和64 GB DDR4 内存。Actor、Critic 神经网络结构均采用2 层隐藏层的全连接神经网络,隐藏单元数为256 和32;超参数设置如下:学习率为0.000 1,折扣因子为0.95,目标网络更新系数为0.005,经验回放池容量为10 000。
3.3 仿真结果分析
分别使用传统DDPG 算法和改进DDPG 算法对巡航导弹应对动态预警威胁突防进行训练,其每回合奖励值曲线如图4 所示,数据对比如表1 所示。

图4 算法改进前后不同训练回合数下的奖励值

表1 算法改进前后数据对比
改进后的DDPG 算法由于其探索噪声时序相关,探索能力更高,收敛速度更快,相较于传统的算法模型训练达到稳定时间缩短了一半,训练收敛后改进算法每回合探索步数更少,因而其稳定每回合奖励值更低。训练完成后模型能在1 s 内生成巡航导弹自主避开预警威胁打击目标的机动轨迹指令。
图5 为模型训练完成后测试模型得到的一个攻防场景图,其中预警机巡航轨迹为跑道型轨迹,目标直线航行,巡航导弹避开预警威胁后成功击中目标。

图5 典型作战场景下训练后攻防轨迹图
4 结论
本文首先构建了巡航导弹突防时的典型作战场景,给出了预警机雷达探测概率的预测公式;然后采用一种基于时序相关探索噪声的改进DDPG 算法求解得到了巡航导弹快速智能突防算法。仿真实验表明,在预警机雷达威胁下采用上述算法巡航导弹可以实现快速主动突防。该模型的训练时间大约为30 min,训练完成后可在1 s 内生成突防机动轨迹,远远超过传统航迹规划算法的速度;而且该算法具备良好的适应性和延展性,可用于广泛的作战场景中。
猜你喜欢
环球时报(2022-08-18)2022-08-18
军民两用技术与产品(2021年9期)2021-11-27
小哥白尼(军事科学)(2021年5期)2021-08-30
红领巾·探索(2020年5期)2020-05-19
军事文摘(2020年24期)2020-02-06
小学科学(学生版)(2018年9期)2018-09-21
家教世界(2017年11期)2018-01-03
西北工业大学学报(2015年4期)2016-01-19
舰船科学技术(2013年12期)2013-08-15
