
基于深度学习方法的PM2.5精细化时空估算模型
2021-09-03 07:13孙义博曾巧林商豪律刘霄宇单菁菁中国社会科学院生态文明研究所北京0070中国环境科学研究院生态研究所北京000重庆邮电大学计算机科学与技术学院重庆0006中国科学院空天信息研究院数字地球重点实验室北京0009中国信息通信研究院北京009
中国环境科学 2021年8期
耿 冰,孙义博,曾巧林,商豪律,刘霄宇,单菁菁* (.中国社会科学院生态文明研究所,北京 0070;.中国环境科学研究院生态研究所,北京 000;.重庆邮电大学计算机科学与技术学院,重庆 0006;.中国科学院空天信息研究院数字地球重点实验室,北京 0009;.中国信息通信研究院,北京 009)
为了应对日益严重的空气污染问题,我国大规模建立地面PM2.5监测站点,对重污染天气进行监测及预警[1-3].众多学者也在此基础上开发了 PM2.5浓度估算模型[4-8].但是,地面 PM2.5监测站点仅能提供空间上“点”尺度的观测,有限的空间范围不足以代表PM2.5在空间上的异质性, 而PM2.5的空间信息对于研究空气污染与经济、地理及人口之间的关系至关重要.
近年来,随着卫星遥感技术的发展,使得区域尺度的污染信息获取成为可能,利用卫星反演的大气气溶胶光学厚度(AOD)估算大空间尺度的地表PM2.5浓度也已被广泛采用[9-13].
目前,已有多种卫星遥感数据反演的AOD产品被用于估算地表PM2.5浓度的时空分布[14-17].
与此同时,多种类型的统计模型被提出并应用于PM2.5浓度的估算中[18-22],这些模型均以AOD作为主要指示因子,结合气象观测及其他类型的统计参数估算地面 PM2.5的时空分布.例如,早期的研究采用一元线性回归模型仅采用AOD作为指示因子来估算PM2.5浓度[23];或更为复杂的采用多元或广义线性回归模型,考虑更多的地表及气象参数用以提高 PM2.5的估算精度[24-25].但是在真实的环境中,PM2.5浓度的分布是一个与多种因素有关的非线性过程,在时间和空间上存在着强烈的可变性,因此学者们开发了更为复杂的模型对PM2.5浓度与AOD关系的时空变异性进行描述,例如地理(和时间)加权回归模型[10]、混合效应模型[26]以及广义加权混合模型等[27].然而,本质上这些统计模型仍然是线性的,模型内部简化了PM2.5与AOD及其他指示因子之间的复杂关系,使PM2.5浓度估算结果仍然存在较大的不确定性.随着计算机技术的发展,机器学习(包括深度学习)方法以其强大的非线性建模能力越来越多地被用于 PM2.5浓度的估算中[28],例如支持向量回归模型[29]、随机森林模型[30]、人工神经网络模型[24]、贝叶斯方法[31]、广义回归神经网络模型[32]以及深度信念网络[33]等,这些模型在对PM2.5浓度的估算方面均表现出比传统统计模型更好的性能.在指示因子的选择方面,这些机器学习模型除了采用AOD和常规的气象观测参数之外,还使用了包括相邻时间和空间上观测的 PM2.5信息、土地利用信息、植被指数信息、NO2浓度信息、人口密度、海拔高程[26,33]以及路网密度信息等,这些信息或多或少与PM2.5浓度分布相关.考虑的影响因子越多,越能够提高PM2.5估算精度.但是,过多的人工设计的特征不仅耗时耗力,而且过于复杂的特征选择也不利于模型的工程化实施.此外,目前的模型大多仅对日平均 PM2.5浓度进行估算,且空间分辨率相对粗糙(大于 3km).尽管此类模型可以有效降低目标函数的复杂性,但却忽略了PM2.5浓度每小时的时空变异性.针对以上问题,为了有效地开展 PM2.5浓度精细化时空尺度(即每小时和1km的时空分辨率)估算,需要一种非线性表达能力更强并且容易实现工程化的模型.
深度学习方法[34]作为当前最先进的机器学习技术之一,以其优异的非线性表达能力在许多领域都取得了超过传统机器学习方法的显著成果.目前,已有研究人员采用深度学习方法来估算 PM2.5浓度的时空分布[33,35-36],但是相关的模型规模仍然相对较小,并且很大程度上依旧依赖于人工特征选择,并没有充分利用深度学习方法通过更深更宽的网络结构来表达高度复杂目标函数的优点.因此,本文以北京市 2017年的 PM2.5观测数据为基础,提出了一种典型的深度学习模型(PM2.5-DNN),仅采用卫星遥感反演的AOD数据以及常规的气象观测要素(例如气温、地表温度、风速、风向、相对湿度、压强以及能见度)来估算PM2.5浓度的时空分布.
1 数据与模型
1.1 研究区与数据来源
1.1.1 研究区概况 北京市位于华北平原,中心经纬度为 116.41°E,39.92°N,总面积约 16410.54km2,2019年常住人口约2153.6万人.其地处暖温带半湿润半干旱季风区,气候四季分明,夏季炎热多雨,冬季寒冷干旱,春秋短促.本文采用了北京市2017年全年观测的每小时PM2.5浓度数据和气象观测数据.研究区域地理空间范围以及 PM2.5站点和气象观测站点的分布见图1所示.
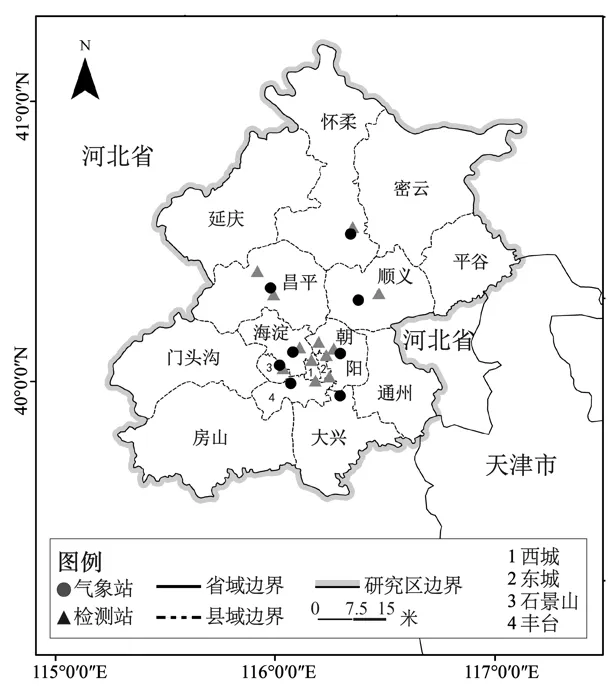
图1 研究区及PM2.5监测站和气象观测站点分布Fig.1 Distribution of study area and PM2.5 monitoring stations and meteorological observation stations
1.1.2 卫星AOD数据 本文卫星遥感数据采用葵花-8气象卫星数据.葵花-8属于第3代地球静止气象卫星,其观测范围为东西 80°E~160°W,南北 60°N~60°S,距离地面高度 35800km,星下点位于 140.7°E[17].卫星搭载的主要传感器为AHI(高像素葵花成像仪),可见光最高分辨率为 0.5km,红外-近红外最高空间分辨率为 1km,最高时间分辨率为 10min,是目前全球最先进的气象观测传感器之一.
葵花-8号卫星 AOD数据产品的反演采用了Yang等提出的新暗目标算法(New-DT),该算法主要利用葵花-8卫星的可见光和近红外波段数据反演空间分辨率为1km的每小时AOD数据产品.
1.1.3 环境及气象观测数据 2017年PM2.5监测站点数据来自国家环境监测中心网站,共采用了北京市12个PM2.5监测站点.2017年北京市气象观测数据来自于中国气象数据中心网站,本文所用到的主要气象观测数据包括气温(A_temp)、地表温度(S_temp)、风速(wing_S)、风速方向(wind_D)、相对湿度(RH)、地表压强(SP)和能见度(VIS).为了获得与PM2.5浓度相关性最佳的气象观测数据,本文选用了在 PM2.5监测站半径为 5km区域内的气象观测站,最后共选择了8个气象观测站点.PM2.5监测站点与气象观测站点的分布如图1所示.
1.1.4 数据预处理 由于模型的构建需要将 PM2.5浓度数据、AOD数据以及气象观测数据一一对应,因此需要对所有数据进行预处理,使之形成时间和空间上一致的数据集,用于对所构建的PM2.5浓度估算模型进行训练与验证.其中 AOD数据提取 PM2.5监测站点位置所在栅格的数值.对于气象观测数据,由于 PM2.5监测站点的分布与气象观测站点的分布不同,本文使用了PM2.5周围5km范围内的气象观测站点观测均值作为与之匹配的气象观测数据.此外,由于较小的太阳高度角会导致大气路径变长,使得大气漫反射的比例变大,从而导致卫星遥感反演的AOD数据产品的精度变差.因此,为了有效避免太阳高度角对AOD数据反演精度的影响,本文仅使用北京时间9:00~16:00之间8h的葵花8号卫星影像反演AOD数据,并同时获取与AOD数据时间上一致的 PM2.5浓度与气象观测数据.最后,去掉数据中的缺失值以及由于降雨影响导致的无效数据,并将数据进行归一化处理(零均值,单位方差).经过预处理后,共得到可用数据17059条.
1.2 模型构建方法
1.2.1 深度网络模型(PM2.5-DNN) 深度学习属于机器学习中的一类模型,它通过构建非常深的神经网络来学习输入数据的多级表示特征,从而表达复杂及抽象的概念或模式[34].与传统神经网络模型相比,深度学习模型通常由超过三层的隐含层构成.并且可以在没有进行预训练的情况下直接对深度网络进行端到端的监督训练.
本文采用AOD数据和常规的气象观测参数作为输入变量,通过深度学习模型直接构建输入变量与 PM2.5浓度之间的高时空分辨率(每小时,1km)关系模型.模型的输入参数为:葵花 8卫星反演的AOD、空气温度(A_temp)、地表温度(S_temp)、风速(wind_S)、风向(wind_D)、相对湿度(RH)、压强(SP)、可见度(VIS)以及年积日(DOY),模型的输出为PM2.5浓度的估算值.对模型隐含层神经单元数据的确认采用启发式搜索方法,将隐含层的神经单元个数设为 10,并以 10为步长进行迭代的训练和验证,并统计验证误差,直至验证误差稳定且不再降低,然后以相同的方式来确定多个隐含层的神经元个数,直至整个模型的验证误差不再降低为止.模型的训练采用 ReLU作为激活函数,输出层采用线性函数作为激活函数,最终确定的深度学习网络模型结构如图2所示,结构为9-300-300-100-20-1.
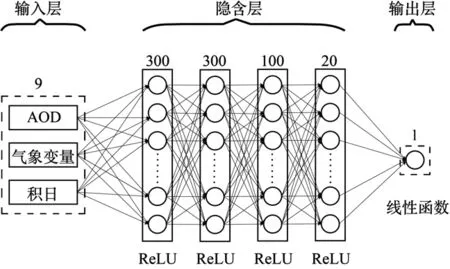
图2 本文所采用的深度网络模型结构Fig.2 The structure of the deep network model
模型的训练和应用流程如图 3所示,在训练阶段通过采用误差反向传播方法对输入的训练数据集进行学习,获得能够表征输入数据时空特征的模型内部参数,并对模型的训练结果进行验证,在获得可靠的验证精度后即可应用训练好的模型,通过输入 AOD影像及栅格化后的气象观测数据,对 PM2.5浓度的时空分布进行估算.
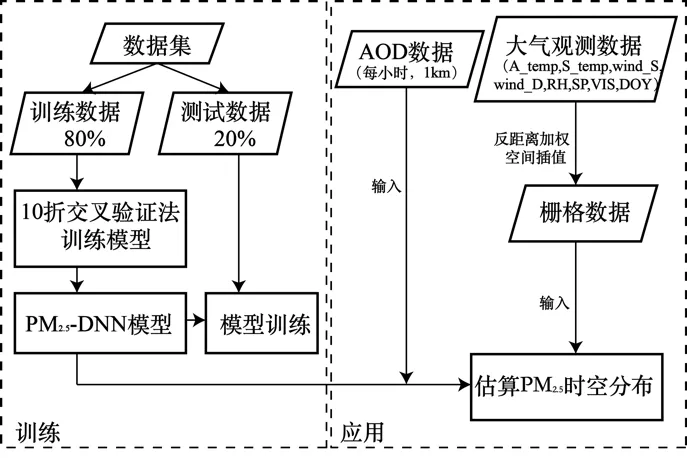
图3 模型训练和应用流程图Fig.3 Model training and application flow chart
1.2.2 线性混合效应模型(LME) 线性混合效应模型(LME)是目前估算 PM2.5时空分布的主要方法之一,是既包含了固定效应参数又包含随机效应的统计回归模型.其中固定效应表示模拟因子对 PM2.5的多年平均影响状态,而随机效应则用于解释 PM2.5与AOD以及其他气象因子之间的日变化关系,以随机截距或者随机系数的形式表示.线性混合效应模型可以表达为:
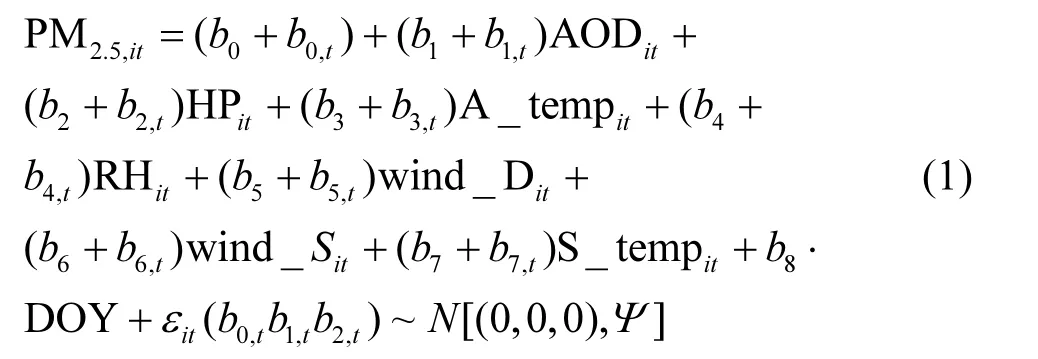
式中:PM2.5,it表示第i个监测站点在时间t的 PM2.5浓度值;bo和bo,t分别代表模型的固定截距和随机截距;b1~b9和b1,t~b8,t分别代表各自变量参数的固定效应斜率和各变量的随机效应斜率;εit第i个监测站点在时间t的随机误差项,b0,t、b1,t和b2,t为其参数;Ψ为随时间变化的随机效应方差-协方差矩阵.
1.2.3 地理加权回归模型(GWR) 地理加权回归模型(GWR)区别于传统回归方法之处在于不同辅助变量的回归系数不再是利用全局信息所获得的常量进行估算,而是用邻近观测值进行局部加权回归从而得到相关系数,并考虑了数据的空间位置.其公式可表达为:
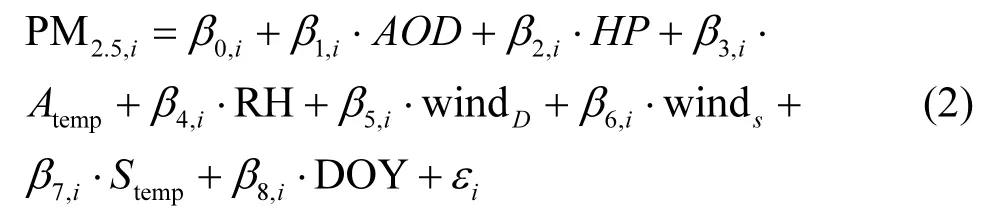
式中:PM2.5,it表示第i个监测站在时间t的PM2.5浓度值,β0,i为模型的固定截距;β1,I~β9,i分别代表各自变量参数的回归系数,εi为第i个监测站点的回归残差.
1.2.4 支持向量回归模型(SVR) 支持向量回归(SVR)模型是支持向量机模型在回归问题上的应用模型,该模型会在尽可能拟合现有数据的情况下考虑模型的泛化误差,从而尽量避免模型的过拟合,使得学习到的模型能够在未知数据上具有良好的预测性能.SVR模型在PM2.5模拟方面已有了较多的应用,以下对其原理进行简单叙述.
给定数据集{(xi,yi),i,…,m},x为输入因子,y为输出因子,SVR模型可以表示为:
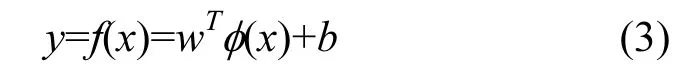
式中:w是权重向量;φ(x)是将输入数据从输入空间映射到特征空间的核函数;b是常数项.对模型的训练是使风险函数最小,风险函数可表示为:

式中:等号右侧第一项是对模型复杂程度的惩罚项;第二项是模型输出值与真实值之间误差的惩罚项;常数 C是用来调整惩罚比例的系数.本文使用径向基函数(RBF)为核函数,表示为:
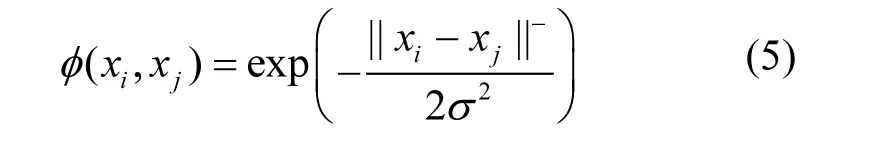
在对SVR模型的训练中,采用了格网搜索方法来确定模型超参数(σ,C),即设定σ和C的范围在4到-4之间,以 0.8为间隔进行遍历计算,找到模型验证误差最小的超参数组合即为最优参数.
1.2.5 随机森林回归模型(RFR) 随机森林(RF)算法是通过集成学习的思想将多颗决策树集成的一种分类与回归算法.随机森林引入集成学习思想和随机子空间思想,通过实现样本选取随机性和特征选取随机性,对样本单独构建决策子树,结合集成学习思路将各决策子树的结果按照一定规则汇总作为最后输出.对于回归模型而言,汇总规则为取平均值.
对一组由决策子树{h(x,θt),t=1,2,…,T}构成的决策组合模型.其中θt为服从独立同分布的随机变量,x为自变量,T为决策子树的个数.回归模型的估算结果为:
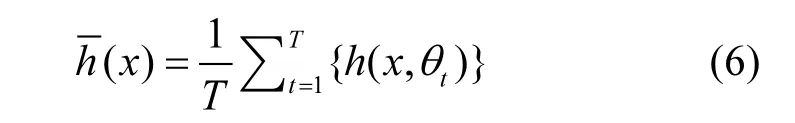
2 结果与讨论
2.1 深度网络模型PM2.5-DNN的训练和验证
将数据集随机分隔为训练数据集(80%)和测试数据集(20%)分别应用于模型的训练阶段和测试阶段.对模型的训练采用带动量项的随机梯度下降算法,并采用从均匀分布中采样的方式对 PM2.5-DNN模型的初始权重进行初始化.此外,超参数的设置也会显著的影响模型训练结果,超参数主要包括学习速率,动量以及为防止过度拟合而引入的dropout和正则化因子[37].本文对超参数的设置采用了格网搜索的方法,即设置各超参数取值范围,然后以一定的步长进行迭代训练,找出获得最佳验证性能的数值作为后续模型训练时采用的超参数.本文最终确定的模型训练超参数设置情况为:批量大小为 100,学习速率为0.04,动量为0.8,dropout为0.1,L2正则化因子为 0.0002,同时采用早停法来避免模型的过度拟合.对模型的训练采用10折交叉验证方法,即将训练数据集随机平均分为10等份,轮流将其中9份作为训练数据,1份作为验证数据进行模型训练,最后将10次训练的验证结果的均值作为模型的性能[37].
采用相关性系数(R2)、均方根误差(RMSE)、平均预测误差(MPE)以及相对预测误差(RPF)作为模型性能的评价指标.
模型训练结构如图 4所示,在模型的训练阶段,模型的总体性能分别为:R2=0.95,RMSE=10.6μg/m3,MPE=1.64μg/m3,RPE=25.47%;在模型的测试阶段,模型的总体性为:R2=0.88,RMSE=18.78μg/m3,MPE=0.73μg/m3,RPE=42.98%.通过对比训练阶段和测试阶段的 R2可以看,出模型在训练阶段存在一定的过拟合现象,导致了所构建的PM2.5-DNN模型在测试阶段对高浓度范围PM2.5的低估和低浓度范围PM2.5的高估.但同时测试结果的相关性系数和误差水平仍然表现的非常稳健,表明本文所构建的 PM2.5-DNN模型对PM2.5浓度的估算仍然非常有效.
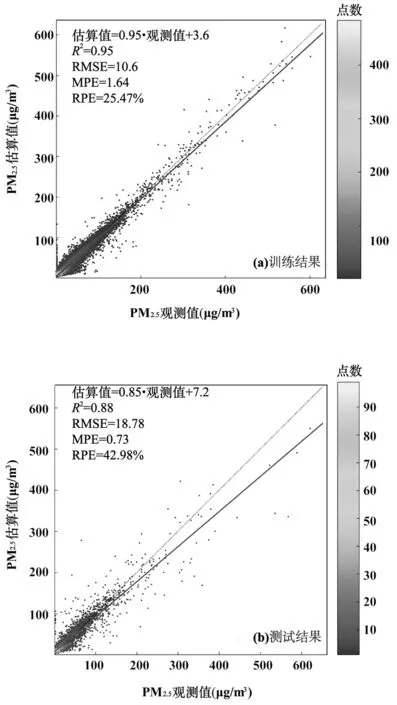
图4 PM2.5-DNN模型的总体性能评价Fig.4 Performance evaluation of PM2.5-DNN model
2.2 深度网络模型与其他模型的对比
从表 1可见,机器学习方法(包括 SVR,RFR和PM2.5-DNN模型)表现出了比传统方法(LME和GWR)更好的估算性能.PM2.5-DNN与SVR和RFR模型相比表现出了更加优异的估算性能,这主要得益于PM2.5-DNN模型的深层结构,能够从大量数据中直接学习高度复杂的函数关系.同时,本结果也表明,深度网络模型在PM2.5浓度的估算方面具有极高的应用潜力,可以直接通过端到端的方式进行训练,即直接使用容易获得的观测因子进行建模便能够获得最佳的估算性能.
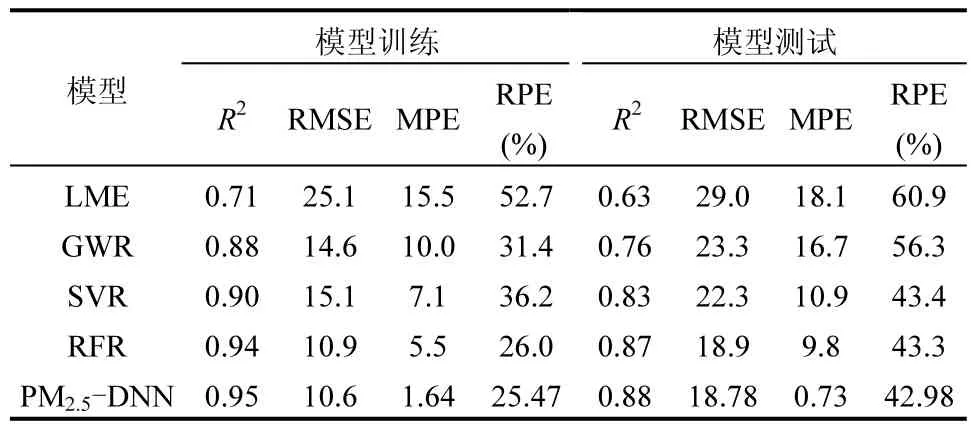
表1 不同PM2.5估算模型之间的结果对比Table 1 Results comparison of different PM2.5 estimation models
2.3 北京市PM2.5浓度的精细化时空分布估算
2.3.1 每小时PM2.5浓度估算分析 为获得能够覆盖整个北京市区域的气象观测插值数据,本文采用了覆盖整个京津冀区域内的气象观测站点并采用基于反距离加权方法(IDW)进行插值获得北京市气象栅格数据.然后将训练好的PM2.5-DNN模型应用于卫星AOD栅格数据及插值生成的气象栅格数据生成2017年北京市每小时PM2.5浓度栅格图.图5中,最大PM2.5浓度分别为:89.92、82.37、91.42、89.89、89.73、83.27、80.6和91.62μg/m3.结合与地面PM2.5监测站点的数据相对比, PM2.5-DNN模型估算的PM2.5浓度时空分布与地面实测结果均吻合较好,表明本文所构建的PM2.5-DNN模型具有较好的时空估算性能.
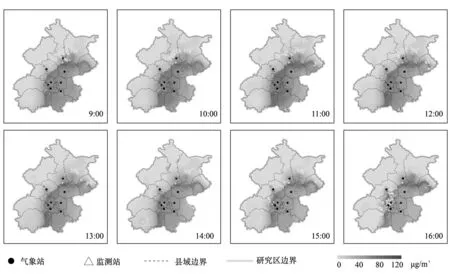
图5 每小时PM2.5浓度模拟结果与监测站点的对比Fig.5 Hourly PM2.5 concentration estimated by PM2.5-DNN model compared with the monitoring site
2.3.2 各月份PM2.5浓度分布估算分析 从各月份PM2.5浓度分布来看,北京市2017年1~12月份最大PM2.5浓度分别为:51.56、39.05、34.05、34、57.48、29.23、18.49、15.09、32.67、27.41、46.77 和39.47μg/m3.在PM2.5浓度时空分布中可知,冬季节污染最为严重,夏季空气质量最优.研究结果也清晰地展示了2017年5月发生的北京市PM2.5重度污染过程(图6).
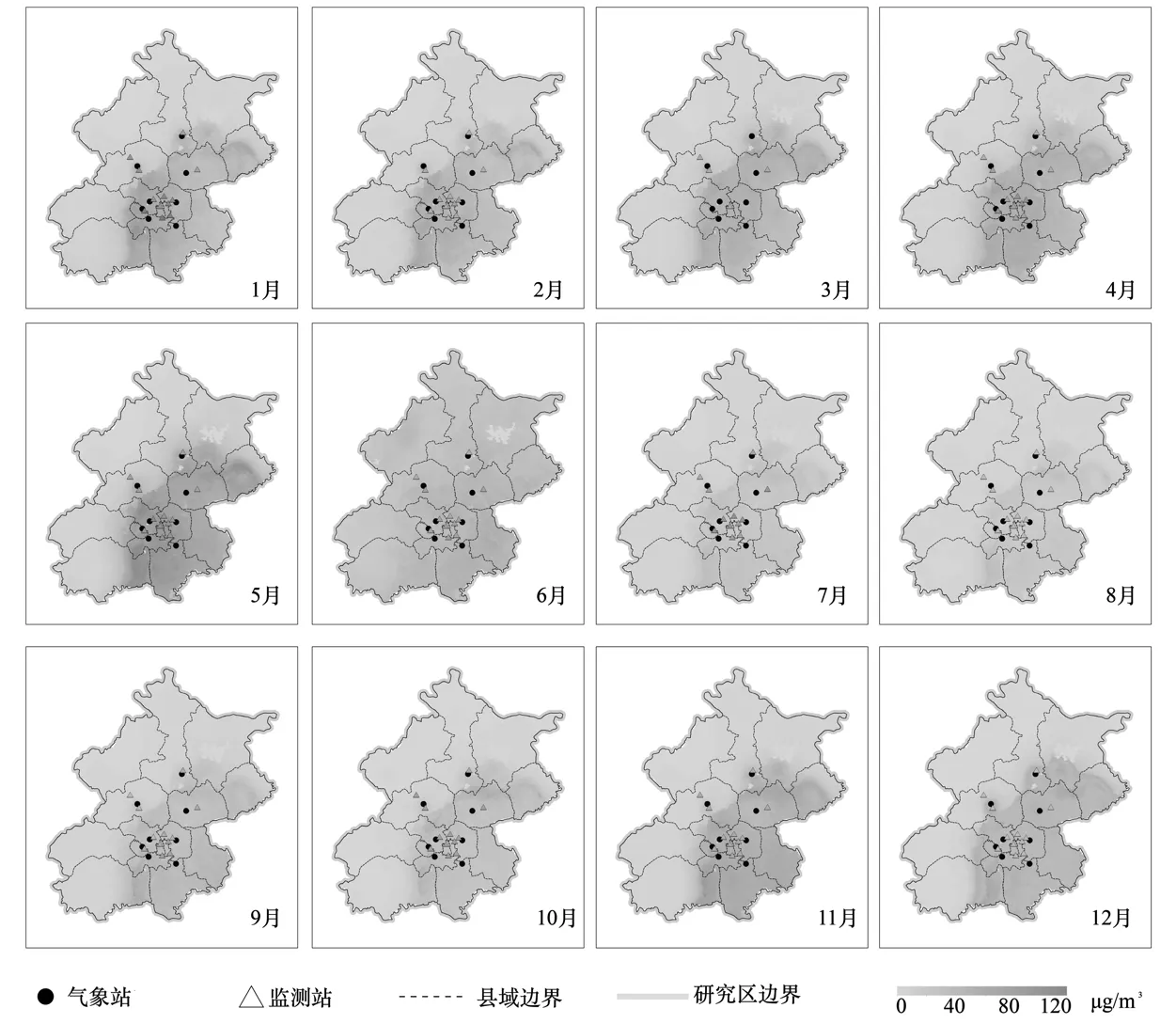
图6 PM2.5-DNN模型生成的2017年各月份PM2.5浓度分布Fig.6 PM2.5 concentration distribution per month in 2017 generated by PM2.5-DNN model
2.3.3 各行政区PM2.5浓度分布分析 北京市共16个行政区,但仅有12个观测站点,无法实现观测站点的行政区全覆盖,利用PM2.5-DNN模型可生成更加精细的 PM2.5浓度时空分布数据.从计算结果可知(表 2),2017年北京市 PM2.5浓度最大值出现在房山和丰台,其次为昌平、海淀、石景山,延庆PM2.5浓度最低.城六区(东城、西城、朝阳、海淀、丰台、石景山)年平均 PM2.5浓度均高于其他地区,生态涵养区(门头沟、平谷、怀柔、密云、延庆、昌平和房山的山区)PM2.5浓度较低.
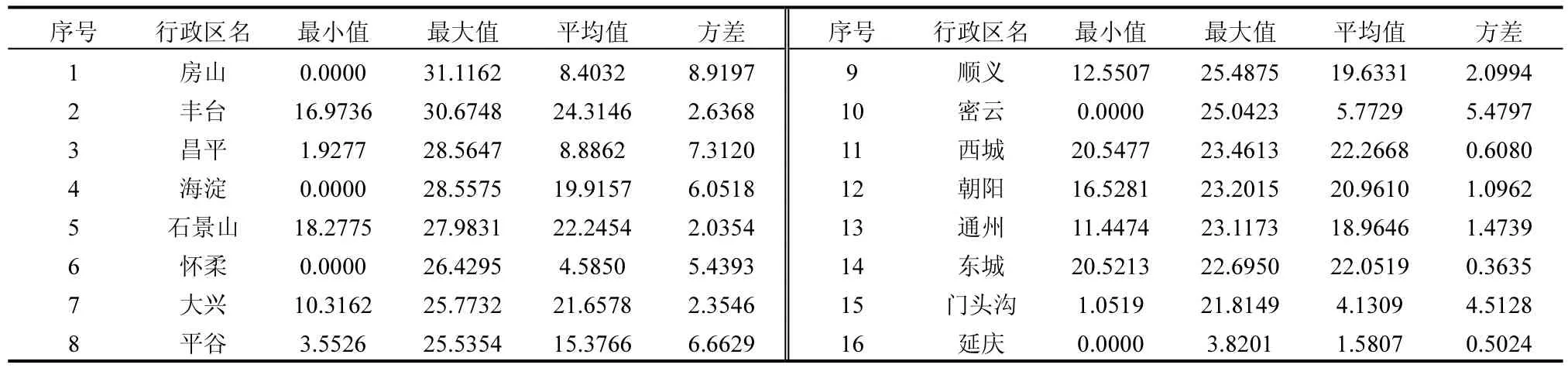
表2 PM2.5-DNN模型生成的2017年各行政区PM2.5浓度分析Table 2 Analysis of PM2.5 concentration in each administrative district in 2017 generated by PM2.5-DNN model
同时,本文将所用12个观测站点的年度平均值与其所在栅格单元的 PM2.5-DNN模型模拟结果的年度平均进行了对比,其中 R2=0.89,RMSE=20.04μg/m3,与模型的测试结果一致,进一步论证了所构建的PM2.5-DNN模型的可靠性(图7).

图7 各站点年平均观测值与估算值对比Fig.7 Comparison of annual average observation values and estimated values of each station
2.4 讨论
与 LME、GWR、SVR以及RFR相比,本文提出的基于深度网络模型的 PM2.5-DNN模型仅采用容易获得的观测因子就可以获得最佳的估算性能.结合卫星遥感反演的AOD数据,采用PM2.5-DNN模型实现了PM2.5浓度1km逐时的时空精细化模拟.
在模型应用方面,由于模型的建立主要是基于2017年北京市内的12个PM2.5监测站点、8个气象观测站点以及葵花-8号卫星的AOD数据产品,考虑到其他年份或区域会出现不同的PM2.5时空模式,模型应用的最佳方式是进行内插,因此本文仅对 2017年北京市PM2.5浓度的时空分布进行了模型估算.对于深度网络模型而且,随着模型的深度(隐含层数)和广度(每层神经单元个数)的增加以及模型构建时输入数据量的增大,所训练的深度网络模型就越能更好地对复杂 PM2.5时空变化模式进行模拟.因此,采用更多年份及更多观测站点的数据进行深度网络模型的构建,实现全国区域多年份的PM2.5浓度时空精细化模拟是本文下一步的研究重点.此外,由于云层覆盖造成的AOD数据在空间上的数据缺失,造成了PM2.5浓度时空分布数据在部分空间上的不连续,这也是本文存在的不足之一.
3 结论
3.1 提出一种基于深度学习方法的地面PM2.5浓度时空估算模型 PM2.5-DNN,该模型仅需要常规的气象观测数据(包括气温,地表温度、风速、风向、相对湿度、压强以及能见度)结合卫星遥感反演的AOD数据,就可以对地表 PM2.5浓度进行高时空分辨率的估算.
3.2 深度学习模型在构建复杂关系模型中具有较强的性能,与线性混合效应模型、地理加权回归模型、支持向量回归模型、随机森林回归模型相比,PM2.5-DNN模型表现出更高精度的估算性能,其测试结果R2可以达到0.88.
猜你喜欢
中等数学(2022年5期)2022-08-29
四川党的建设(2022年8期)2022-04-28
小学生学习指导(低年级)(2020年11期)2020-12-14
成都信息工程大学学报(2019年1期)2019-05-20
四川环境(2019年6期)2019-03-04
作文大王·低年级(2018年10期)2018-12-06
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
中国环境监察(2016年8期)2016-10-23
中国质量监管(2016年10期)2016-07-10
