
非完备数据的宽带客户流失预测
2021-09-08 02:25张芸宋双
中国新通信 2021年14期
张芸 宋双


【摘要】 在实际数据中,由于人为、设备等原因,不可避免的会出现数据缺失问题。针对缺失值的处理方法一是删除,二是填充。若数据缺失较少,删除存在缺失值的样本不失为一个快速简单的方法,但若缺失值较多,大量删除样本就会损失掉重要信息,不利于模型的建立,预测效果也会不理想。本文从非完备数据出发,采用SimpleImputer、KNNImputer、IterativeImputer三种方法来填充缺失的数据,建立宽带客户流失随机森林分类模型,经过对比分析得出IterativeImputer方法补充缺失值分类效果更好的结论。
【关键词】 缺失值填充 随机森林
引言:
在大数据的时代,虽然有海量的数据,但是数据也存在严重的缺失情况。缺失值(missing data)是指单元格中应有而未能记录的数据。数据缺失通常分为三种:完全随机缺失、随机缺失、非随机缺失。当我们所用数据的重要信息存在缺失情况时,就要对其进行填充。由于填充的数据非真实数据,因此会对分析结果产生一定的影响。若能找到一种合适的数据填充方法,使得填充的数据与真实值更接近,就能大大提高数据分析的效果。
本文首先介绍三种缺失值填充的方法,分别是SimpleImputer、KNNImputer、IterativeImputer。然后在电信宽带客户数据集上分别用三种缺失值填充的方法对缺失值进行填充,最后建立宽带客户流失的随机森林分类模型。通过对比直接删掉缺失值以及三种缺失值填充方法,分析得到填充缺失值是否对模型分类效果有提高,以及哪种缺失值补充方法最好。
一、缺失值填充方法
数据缺失已经成为一种不可避免的现象。针对分类问题,如果某一特征对分类结果影响很小或无影响,那么该特征可以直接删除;若某一特征对分类结果存在很大的影响,且缺失值占总样本的比例适中,就可以进行数据填充。基于此,许多学者研究该如何进行数据填充,才能使填充的数据更加接近真实值。
国外学者对缺失值填补的研究要早于国内,最早关于缺失值的相关研究可以追溯到1976年Rubin[1]对数据缺失三大机制的定义。近期,Gerhard等[2]提出了基于KNN的插补方法,将KNN算法中的邻居改为按照距离进行加权。Lei等人[3]利用多视图矩阵完备的方法对缺失值进行插补,Zhang 等人[4]基于链式法则对缺失值进行填充,Verma 等人[5]利用 LSTM 对缺失值进行处理等。
1.1 SimpleImputer
SimpleImputer缺失值填充方法是除了删掉缺失值以外最简单的一种方法,包含了四种最常用的填充方式,分别是均值填充、中位数填充、众数填充和常数填充。该方法可以在sklearn中直接调用。
1.2 KNNImputer
KNNImputer方法的思想是找到数据空间中距离最近的K个样本,然后通过这K个样本来估计缺失数据点的值。缺失值可以用K个相邻样本点的均值、中位数、众数或者常数进行填充。KNNImputer预测的步骤是选择其他不存在缺失值的列,同时去除需要预测缺失值的列、存在缺失值的行,然后计算欧氏距离找到K个近邻点。如果是离散的缺失值,则使用KNN分类器,投票选出K个邻居中最多的类别进行填补;如果是连续的变量,则用KNN回归器,使用K个邻居的平均值进行填补。
1.3 IterativeImputer
IterativeImputer采用的是回归的思想通过无缺失的数据建立回归模型,来预测缺失的数据。具体步骤为:将每个缺失值设为y,不含缺失值的特征设为x,构建x和y的函数。通过循环迭代方式,使用一个回归模型在已知y(未缺失)的样本上对(X,y)进行拟合。然后使用这个回归模型来预测缺失的y值。以迭代的方式遍历每个有缺失值的特征,然后重复n轮,最后一轮的计算结果被返回。
二、实验过程及结果
基于以上介绍的三种缺失值填充方法,本文将这三种方法应用在电信宽带客户数据上,首先对客户流失数据进行预处理,选出有重要影响的特征,然后对存在缺失值的特征用三种方法分别进行缺失值填充,建立随机森林分类模型,最后通过评价指标得出结论。
2.1 数据预处理
本文选取云南省某公司某月的宽带客户数据作为研究数。因为并不是所有特征都对客户是否流失都有显著的影响,所以需要进行特征选择。特征分为两类,一类是分类特征,一类是数值型特征。
针对分类特征,分别画出特征在正负样本上的饼图,观察其是否有显著的差异,若某特征在正负样本上的差异超过10%,则认为该特征对客户是否流失有显著的影响,否则认为无影响。针对数值型特征,分别画出特征在正负样本上的箱线图,若箱线图有明显的差异,则认为该数值型特征对客户是否流失有显著的影响,否则认为无影响。
2.2 建立缺失值補充模型
数据预处理后,发现电信宽带客户数据中AVG_IPTV_ACTIVE_CNT(近3月月均IPTV活跃天数)、FLUX_MAX_TIME_PROP(流量使用峰值时段占全天流量占比)这两个特征对客户流失有重要影响,且这两个特征存在缺失值,通过SimpleImputer、KNNImputer、IterativeImputer这三种方法分别对缺失值进行填充,最后得到了完备的电信宽带客户数据。
2.3 随机森林
本文选用随机森林作为分类模型。随机森林就是集成学习思想下的产物,将许多棵决策树整合成森林,并合起来用来预测最终结果。首先,用bootstrap方法生成m个训练集,然后,对于每个训练集,构造一颗决策树,在节点找特征进行分裂的时候,并不是对所有特征都能找到使得指标(如信息增益)最大的,而是在特征中随机抽取一部分特征,在抽到的特征中间找到最优解,应用于节点,进行分裂。随机森林实际上对样本和特征都进行了采样(如果把训练数据看成矩阵,那么就是一个行和列都进行采样的过程),这样可以避免过拟合。
2.4 評价指标
本文选用的指标为精确率(precision)、召回率(recall)、F1-score。
2.5 实验结果及分析
此样本为极度不平衡数据,而基于现实问题,我们更关注模型对少数类样本的预测能力,由于负样本(多数类样本)的效果都挺好,此处就不进行展示,表中数据为正样本(少数类样本)的结果。
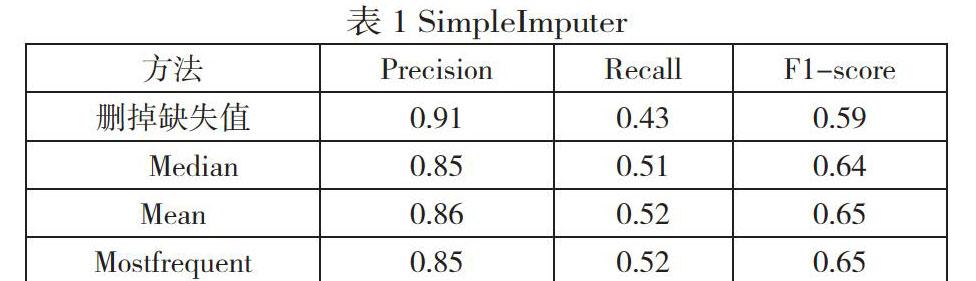
2.5.1 SimpleImputer
从表1的实验数据可以看出负样本的各项指标均高于正样本的各项指标。SimpleImputer的三种数据填充方法均比直接删掉缺失值的效果好,召回率提高了0.8-0.9,虽然精度下降了0.13-0.14,但是综合指标提高了0.5-0.6。总的来说SimpleImputer数据填充方法是有效果的。
从上表的数据可以看出KNNImputer数据填充方法和SimpleImputer的效果差不多,都比直接删掉缺失值的效果好。
2.5.3 IterativeImputer
从上表的实验数据可以看出IterativeImputer数据填充方法是三种方法中效果最好的,精确率值比直接删掉缺失值只降低了0.01,比SimpleImputer和KNNImputer方法提高了0.03-0.05,召回率提高到了0.54,比直接删掉缺失值提高了0.11,比其他两种数据填充方法提高了0.02-0.03,综合指标F1-score比直接删掉缺失值提高了0.09,比其他两种方法提高了0.03-0.04。
三、结束语
数据的质量影响着模型的效果,既然数据缺失不可避免,我们可以力所能及的补充缺失的数据。上述实验结果证明了补充缺失数据建立的模型要优于直接删掉缺失值的模型,其中IterativeImputer数据补充方法最好,综合指标F1-score值达到了0.68,提高了随机森林模型的预测效果。还有诸多从不同个角度研究补充缺失值的方法,后续可以继续阅读相关论文,尝试其他补充缺失值的方法,看能否进一步的提高模型的效果。
参 考 文 献
[1] RUBIN D B. Inference and Missing Data[J].Biometrika,1976,63(3):581-592.DOI:10.1093/biomet/63.3.581.
[2] Tutz G,Ramzan S.Improved methods for the imputation of missing data by nearest neighbor method [J] . Computationl Statistics & Data Analysis, 2015,90(C):84-99.
[3] ZHANG L, ZHAO Y, ZHU Z, et al. Multi-View Missing Data Completion[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(7): 1296–1309. DOI:10.1109/TKDE.2018.2791607.
[4] ZHANG Z.Multiple Imputation with Multivariate Imputation by Chained Equation (MICE) Package [J]. Annals of Translational Medicine,2016,4(2):1-5. Doi:10.3978/j.issn.2305-5839.2015.12.63
[5] VERMA H, KUMAR S. An Accurate Missing Data Prediction Method Using LSTM Based Deep Learning for Health Care[C]//Proceedings of the 20th International Conference on Distributed Computing and Networking. . DOI:10.1145/3288599.3295580.
猜你喜欢
债券(2021年1期)2021-02-04
债券(2020年4期)2020-08-04
债券(2018年11期)2018-02-21
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
债券(2016年10期)2016-11-28
少儿科学周刊·少年版(2015年3期)2015-07-07
