
基于流量摘要的僵尸网络检测①
2021-09-10 07:31肖喜生杜冠瑶魏金侠
计算机系统应用 2021年8期
肖喜生,龙 春,杜冠瑶,魏金侠,赵 静,万 巍
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学 计算机科学与技术学院,北京 101408)
根据僵尸网络威胁报告Spamhaus Botnet Threat Update Q1-2020[1]调研,传统的C&C 相关的僵尸网络数量减少了一半,但新的恶意软件已大量涌现,这些新兴恶意软件利用特定的云基础设施进行非法活动.黑客利用僵尸网络进行点击欺诈、分布式拒绝服务攻击(DDoS)、发送垃圾邮件和窃取个人信息等恶意活动,僵尸网络中的主机通常在所有者不知情、未授权的情况下被黑客劫持.然后,黑客通过控制这些主机一起攻击更多主机.僵尸网络也可以通过在网络空间中传播恶意软件或勒索软件达到攻击的目的.因此,检测僵尸网络并防范其攻击是网络安全研究的重要任务.
随着技术的发展,用于感染主机和运行僵尸网络的恶意软件为了逃避检测也迅速发展,从而令许多常用的僵尸网络检测技术失效.例如,僵尸网络通过改变其通信协议来逃避检测[2].在一开始,僵尸网络使用IRC (Internet Relay Chat)协议来控制其他主机.此后,网络空间中逐渐出现采用P2P 协议通信的僵尸网络,其中每个主机都充当客户端和服务器;然后基于HTTP协议的僵尸网络开始流行[3].2016年,Methbot 僵尸网络成为有史以来最大的数字广告恶意软件,该恶意软件通过位于美国的ISP 获得了数千个IP 地址.Mirai 僵尸网络[4]在同年年底席卷了整个互联网,Mirai 发动了几次大规模DDoS 攻击破坏了大量主流站点.还有一些更复杂更隐蔽的僵尸网络通过更改其通信模式来长时间隐藏而不被发现.因此,僵尸网络检测算法需要与时俱进,要能迅速适应不断进化的僵尸网络.
现有的僵尸网络检测技术仍存在以下问题:
(1)大多数检测方法能够很好的拟合训练数据,然而在测试数据上显现出效果不佳的问题,普遍存在着模型过拟合的情况;
(2)检测模型泛化能力差,针对已知的单一类型的僵尸网络检测效果较好,但面对未知类型僵尸网络乏力;
(3)大部分检测方法忽略了网络流量中的时序通信模式,导致在实际网络环境中检测效果不佳,应用性不强;
考虑到上述问题,本文提出了基于流量摘要的僵尸网络机器学习检测方法,首先将原始流数据按照源主机IP 地址聚合,划分适当的时间窗口,利用Spark 计算所选原始特征的统计特征生成流量摘要记录,对时间窗口内该主机的通信行为进行建模,然后构建机器学习分类模型用于检测僵尸流量.最后利用CTU-13数据集对本文提出的方法进行验证,实验结果表明本文提出的方法能够有效检测僵尸流量,并且能够检测未知僵尸网络.
1 相关工作
目前,僵尸网络检测领域已有大量的国内外学者开展了相关方面的研究,传统的方法有人工分析或黑白名单过滤,或通过手动维护相应的签名数据库进行简单的匹配.
Gadelrab 等[5]通过分析已知僵尸网络的几种恶意软件样本,确定了一组特征,这些特征可以帮助区分正常和僵尸网络流量.Gu 等[6]在他们的工作中研究了僵尸网络恶意软件感染的生命周期.2008年,他们在后续的研究[7]中提出了一种基于网络的异常检测方法来识别局域网中的C&C 僵尸网络,而无需先验签名数据库和C&C 服务器地址.他们的方法能够识别网络中的C&C 服务器和受感染的主机.他们通过部署蜜罐来验证其方法的有效性.其他一些文献[2,8,9]论述了基于蜜罐的僵尸网络检测方法的局限性.蜜罐在检测多种漏洞利用方面存在局限性,无法扩展到其他恶意攻击,也不能实时检测攻击.此外,在自己的环境中构建的蜜罐不是开源的,并且由于公开僵尸网络数据集的缺乏,无法比较实验的结果.Garcia 等[10]认为先前僵尸网络检测方法没有进行任何对比,因此他们采集并开源了一个具有标签的僵尸网络数据集CTU-13,其中包括僵尸流量、正常流量和背景流量.他们为僵尸网络检测方法设计了一种新的评价指标并且比较了(BClus和CAMNEP)与BotHunter[6]的检测结果.由于一些僵尸程序的预先编程性质,致使僵尸网络流量表现出重复的行为模式,仍有大多数研究没有考虑到网络流量中的时序模式[11,12].尽管有其他一些论文考虑了时间模式,但仍然有一定的局限性.他们只考虑某些特定源IP 地址中的时间特征,而没有考虑整体的网络流量,使得在实时僵尸网络检测中效果不佳[13,14].另外,一些现有的研究仅限于传统的基于IRC、P2P和HTTP 协议的僵尸网络.因此,这些方法无法检测各种类型的僵尸网络或未知的僵尸网络.
基于机器学习的方法是最近比较流行的僵尸网络检测方法,安全管理员可以使用训练好的机器学习模型识别僵尸网络.基于机器学习的方法可从僵尸网络数据集中自动提取代表性和容易区分的特征,不需要有关僵尸网络流量的任何先验信息.
支持向量机(SVM)由于其出色的泛化性能被广泛用于许多安全应用中[15,16].Hoang 等[17]提出了一个基于机器学习的僵尸网络检测模型,论文使用域名服务查询数据并使用KNN、决策树、随机森林和朴素贝叶斯算法.实验结果表明,随机森林算法的准确率最高,达到了90.80%.但是同时假阳性率也相对较高.Haddadi 等[18]比较了5 种不同的僵尸网络检测方法,其中包括两种基于签名的方法BotHunter和Snort,其余方法将机器学习算法应用于不同的特征集,包括基于数据包有效负载和基于网络流的特征.他们在包含25 个僵尸网络的数据集上执行多分类和二进制分类测试,实验结果表明,基于流的特征是对僵尸网络通信进行建模的最具代表性的特征,C4.5 算法则达到了最高的分类准确性.Drašar 等[19]详细说明了检测异常的特征选择方法,他们评估了基于流的特征对检测精度的影响.Stevanovic 等[20]提出了基于流的僵尸网络检测方法,选择了39 个流特征(例如源端口、目标端口、数据包大小的标准差和流持续时间)用于对恶意流量进行建模.他们评估了8 种监督机器学习算法,包括朴素贝叶斯、决策树、SVM、贝叶斯网络分类器和逻辑回归.结果表明,随机森林算法识别僵尸网络的准确率最高,达到了95.7%.Chen 等[21]通过监督式机器学习算法快速检测复杂网络中的僵尸网络.他们将基于流和基于会话的特征组合以建立分类模型,并在CTU-13 数据集上进行了实验,同时分析了各种算法的性能,其中随机森林算法达到了94%的精度.Niu 等[22]使用XGBoost 算法在HTTP 流量上检测受感染的主机,检测准确率达到98.72%,假阳性率小于1%.
分析以上研究发现,现有的检测方法只针对特定的僵尸网络,并且会遗漏一些僵尸网络主机之间特定的时序通信模式.此外,针对单条流或单个主机的处理会导致较高的时间和计算开销,此类检测技术也就无法应用于实时僵尸网络检测.如何更加有效地提取僵尸网络流特征,如何提高检测方法的泛化性并提高检测效率及精度,需要进一步研究.因此,本文提出基于流量摘要的僵尸网络机器学习检测方法,以改善上述问题.
2 基于流量摘要的僵尸网络检测方法
2.1 机器学习技术
机器学习是人工智能的一种应用,它使学习系统能够自动学习并从历史经验中进行改进.机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法[23].在本文中,仅考虑了监督学习技术在僵尸网络检测中的性能,这里本文选择在之前研究中被证明具有较好性能的监督机器学习算法,包括决策树、随机森林和XGBoost.
(1)决策树
决策树(Decision Tree,DT)是一种预测模型,代表的是对象属性与对象值之间的一种映射关系.决策树通过创建一组决策规则来对对象进行分类,这些规则是根据训练数据的特征集提取的.在决策树中,叶子代表类,树中的每个子节点及其分支代表导致分类的特征的组合.因此,对对象进行分类时首先检查根节点的值,然后在对应于那些值的树下继续向下.对每个节点重复执行此过程,直到遍历到叶节点为止.决策树通常使用信息增益(IG)和基尼系数来选择决策树的特征.本文的实验使用的决策树算法是优化的CART 算法.
(2)随机森林
随机森林(Random Forest,RF)是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定.该算法的核心思想是创建一系列决策树,这些决策树单独训练并得出独立的结果,随机森林选择选择的结果即为最多的树预测的结果.
(3)XGBoost
XGBoost 模型是为在不平衡的数据集上运行而构建的,因为重新采样是在内部进行的,因此它可以抵抗数据不平衡.XGBoost 被称为极限梯度提升,是一种顺序决策树.通过不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,拟合上次预测的残差.XGBoost 方法不同于传统的基于决策树的集成学习方法,它在损失函数里加入了叶子结点权重和单个决策树模型复杂度等正则项,这样可以防止决策树模型过于复杂,进而防止过拟合.
2.2 流量摘要
为了准确地描述特定时间窗口内主机的流量行为,本文提出了一种基于统计特征的网络流量摘要方法,利用该方法得到的流量摘要记录包括特定时间窗口内主机发送流量的统计特征.
首先,根据网络流数据集中的源IP 地址对流进行分组.然后,提取传输层协议的特征,包括TCP和UDP协议,这是上层应用层协议的基础.本文选择的4 个流特征为:Dur,TotPkts,TotBytes和SrcBytes.表1列出了从网络流量数据中提取的基于TCP 协议的流特征及其描述.针对UDP 协议的流特征提取这里不再赘述.

表1 基于TCP的流特征集描述
针对根据源IP 地址聚合后的网络流,具体的流量摘要方法如下:给定一个时间窗口值t,计算t内基于TCP和UDP 协议选择的上述4 个特征计算4 个统计值,包括最小、最大、均值和标准差值.对于每个新特征名称,其前缀反映其统计特征,然后描述协议类型.例如,特征名称Mean_TCP_Dur 表示在时间窗口t内使用TCP 协议通信的持续时长平均值.在处理了每个源IP 地址的每个时间窗口之后,获得了流量摘要记录的集合,其中共包含32 个提取的特征.图1详细描述了流程摘要过程.通过对给定时间窗口的网络流进行流量摘要,计算传输层协议统计特征,以获取时间窗口内该主机的时序通信行为模式,为之后的僵尸流量检测提供数据支撑.

图1 流量摘要过程描述
上述的流量摘要任务涉及到复杂的聚合和统计任务,使用传统的单机处理方法非常耗时,一种有效的方法是使用分布式大数据处理技术[24],将任务分配给不同的计算节点,然后对结果进行汇总.因此本文使用流行的大数据处理框架Apache Spark 来进行流量摘要任务处理.
2.3 基于流量摘要的僵尸网络检测方法
本文提出了一种基于流量摘要的僵尸网络机器学习检测方法,如图2所示.本文的方法分5 个步骤:流采集、流量摘要、数据预处理、分类和评估.第1 步,流采集可以从某些路由器或其他网络流采集器(例如NetFlow 采集设备)收集网络流数据.本文使用开源的僵尸网络数据集.在第2 步,本文为流量摘要任务部署了一个Spark 集群环境,利用Spark 技术快速完成流量摘要记录生成.第3 步,将流量摘要记录汇总成新数据集,并对其进行重新标记,然后进行特征预处理,这里由于生成的特征都是数值型特征,因此进行归一化处理,特征预处理后将数据集划分为训练集和测试集.在第4 步,基于流量摘要记录数据集训练不同的机器学习分类模型,所用的分类算法为决策树,随机森林和XGBoost,用于分类僵尸流量和非僵尸流量.最后一步,通过实验验证本文提出的检测方法,利用分类评价指标评估比较不同分类算法在流量摘要数据集的检测性能,并讨论不同时间窗口值对检测结果的影响.

图2 基于流量摘要的僵尸网络检测流程
3 实验分析
为了验证本文检测方法的效果,本节在流量摘要生成的新数据集上比较了决策树、随机森林和XGBoost算法的分类性能,然后验证了不同时间窗口值对分类结果的影响.
3.1 数据集
本文使用开源的僵尸网络数据集CTU-13[10],该数据集包含13 种僵尸程序感染场景.原始流量为PCAP格式,由多个数据包组成,对PCAP 文件进行进一步处理可以获得NetFlow 文件,这些文件包含标签并可以很好地区分客户端和服务器.文献[10]使用单向NetFlow表示流量并标记标签,但作者认为不应该使用这些单向NetFlow 文件,因为使用双向NetFlow 文件效果更好.双向NetFlow 相对于单向NetFlow 具有几个优点.双向NetFlow 文件解决了客户端和服务器的区分问题,包含了更多的信息,并且包含了更详细的标签.因此,本文也使用双向NetFlow 文件进行实验.
3.2 数据预处理
根据前文对流量摘要的描述,原始流数据首先根据预先给定的时间窗口(例如10 s的时间窗口)按源IP 地址进行分组,此过程还包括计算该时间窗口下不同的协议的统计特征生成流量摘要记录.分别处理了13 个CTU-13 数据集的攻击场景之后,获得了13 个流量摘要记录组.然后根据源IP对流量摘要记录重新标记.例如在场景1中,主机147.32.84.165是被感染的僵尸主机,因此由该IP 聚合的流量摘要记录将被标记为僵尸流量.本文选择不同的时间窗口进行聚合,包括5 s、10 s、15 s、30 s和60 s,以验证不同时间窗口值对分类结果的影响.表2显示了整个CTU-13 数据集进行流量摘要后标签分布结果,其中数字0 表示正常流量或背景流量,数字1 表示僵尸流量.
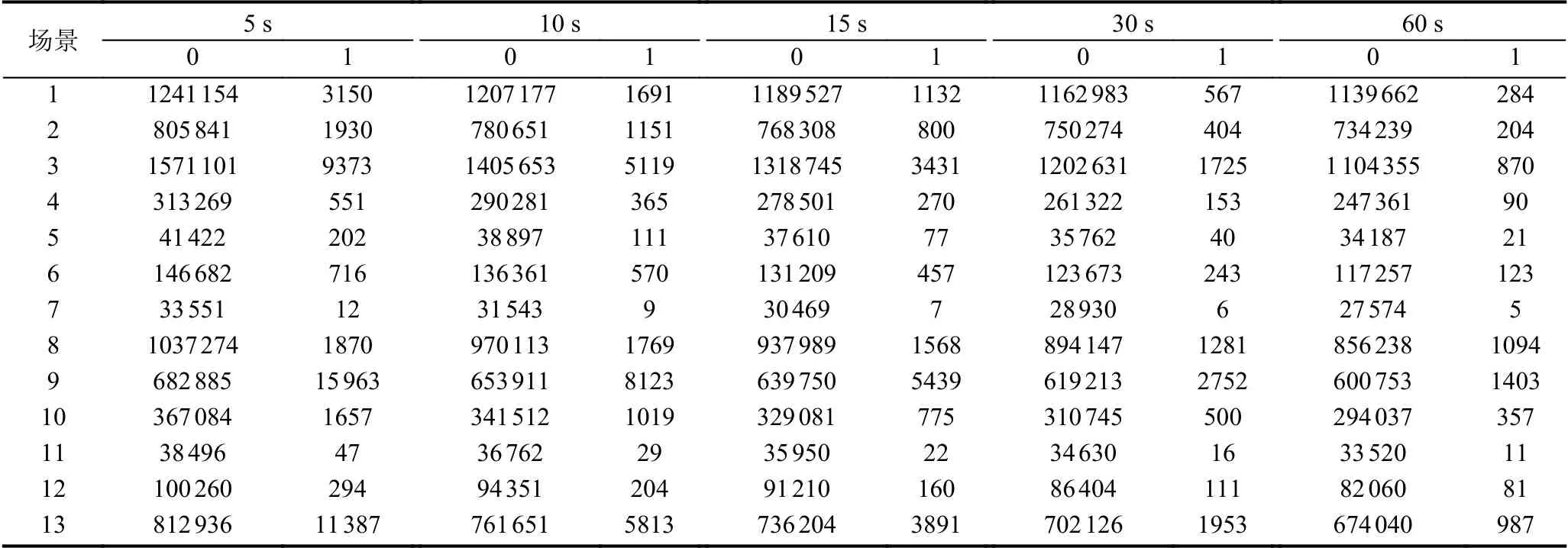
表2 流量摘要数据集标签分布
由于流量摘要数据集包含的32 个特征都是数值型特征,在数据处理过程中需要处理数值分布区间较大的情形,因此需要对数据进行归一化处理,将原本随机分散的数据经过处理压缩到一个较小的分布区间,避免离散点对检测结果产生较大的影响.
3.3 数据集过采样
CTU-13 数据集存在严重的类别不平衡问题,尤其是在流量摘要处理之后,这种不平衡现象更加严重,如表2所示,僵尸流量在整个网络流量中占比极少.为了解决类别不平衡的问题,本文采用了一种称为SMOTE(Synthetic Minority Oversampling TEchnique)[25]的过采样技术来克服极端的类别不平衡问题.SMOTE的核心思想是在少数类样本及其邻居之间插入随机生成的新样本,这可以增加少数类样本的数量并改善类别不平衡的状况.
3.4 结果与分析
本文实验在准确率(Acc)、精确率(Pre)、召回率(Rec)和F1 值上进行对比,各性能指标公式如下所示:

其中,TP代表着真实值属于正类,预测值属于正类的数量;TN代表着真实值属于负类,预测值属于负类的数量;FP代表着真实值属于负类,预测值属于正类的数量;FN代表着真实值属于正类,预测值属于负类的数量.
本文首先分别在数据集的所有场景上进行实验,时间窗口为10 s,3 种机器学习算法的分类结果如表3所示.结果表明,所有算法均具有较好的分类效果,其中XGBoost 在各种指标上具有最稳定的性能.

表3 各个场景下的分类结果
为了进一步验证本文方法的检测性能,对比文献[26]中使用随机森林对Neris 僵尸网络进行检测的结果,本文同样使用随机森林算法进行对比实验,Neris 僵尸网络包括场景1、2和9,轮流选择1 个场景用于测试,剩下两个场景用于训练,10 s 时间窗口的实验结果如表4所示,其中本文的实验结果用*标记.
从表4可见,本文的方法在所有分类指标上均有提升,上文的实验在单一类型恶意软件的僵尸网络检测上具有良好的效果,为了检测未知的僵尸网络,必须考虑更多类型恶意软件的僵尸网络.参考文献[9]建议,本文将场景1、2、6、8、9 组合用于测试,将其他场景用于训练.训练集中的僵尸程序包括Rbot,Virut,Sogou和NSIS.ay,测试集中的僵尸程序Neris,Menti和Murlo.以10 s的时间窗口对整个数据集进行的实验结果如图3所示.

表4 Neris 僵尸网络分类结果
从图3可以看出,XGBoost 分类器在检测未知僵尸流量上具有最优的检测性能,其中精确率达到了96.50%,F1 值也达到了79.55%,由于使用分类器的默认参数,因此以后的工作可以研究针对参数进行优化,进一步提升分类器的检测性能.

图3 全数据集分类结果(10 s 时间窗口)
为了进一步验证不同时间窗口值对分类结果的影响,本文选择了5 s,10 s,15 s,30 s和60 s 等不同的时间窗口,利用分类性能较好的XGBoost 进行实验.结果如表5所示.
从表5可以看出,10 秒的时间窗口下进行流量摘要得到的综合结果最好,其中准确率(Acc) 达到了82.60%,召回率(Rec) 达到了67.66%,F1 值达到了79.55%,这3 项指标为所有时间窗口实验下的最大值.综上所述,由于时间窗口较小,无法捕获僵尸网络流量的时序特征,时间窗口较大则无法满足现实应用中近实时检测的需要,导致检测结果不佳,在实际应用中可划分更加细粒度的时间区间进行实验以确定最佳的时间窗口值.

表5 不同时间窗口下的全数据集分类结果
4 总结
本文提出了基于流量摘要的僵尸网络机器学习检测方法,首先将原始流数据按照源主机地址聚合,划分适当的时间窗口生成流量摘要记录,然后构建决策树、随机森林和XGBoost 机器学习分类模型.在CTU-13 数据集上的实验结果表明,本文提出的方法能够有效检测僵尸流量,并且能够检测未知僵尸网络,此外,借助Spark 大数据技术也能满足现实应用中快速检测的需要.未来的工作将研究针对分类器参数的优化方法,以进一步提高检测未知僵尸网络的检测能力.
猜你喜欢
今日农业(2022年16期)2022-11-09
出版人(2020年4期)2020-11-14
科学与信息化(2019年28期)2019-10-21
汉语世界(The World of Chinese)(2019年1期)2019-03-18
科学与财富(2016年32期)2017-03-04
中国信息化周报(2014年48期)2014-12-23
科普童话·百科探秘(2014年11期)2014-11-21
海外英语(2013年11期)2014-02-11
决策与信息·下旬刊(2013年1期)2013-03-11
