
基于YOLOv3的智慧现场安监技术研究
2021-09-10 10:10程晓陆高超叶晓琪斯荣
机电信息 2021年22期
关键词:目标识别
程晓陆 高超 叶晓琪 斯荣

摘 要:在智能电网发展的大背景下,目前的电网生产安监管理模式已经不适应智能电网的要求,安监管理模式和方式的创新迫在眉睫。鉴于此,首先收集电网违规场景图片构建VOC数据集,利用LabelImg软件对数据集进行标注;然后采用YOLOv3深度学习目标识别算法实现对数据集的训练、调试,并分析模型的性能指标;最后输入额外的目标样本测试成功,为后续更多新技术应用的研究开发提供了新的思路和方向。
关键词:深度学习算法;YOLOv3;目标识别;电力安全监察
0 引言
随着智能电网的发展,本就存在诸多问题的安监模式已越来越不适应当前电网的要求。毋庸置疑,電网安监需要做出改变,但目前提出的安监模式改革大多是针对管理体系,很少有人提出安监方式的改变。
针对管理体系,孙睿等人提出了适应智能电网的“大安全”运营管理体系[1],这一概念是对现有安全责任、安全保证和安全监督管理三大基本体系的提升和拓展,真正以“全员、全过程、全方位”为原则,以人员、设备/系统和管理体系本身为管理对象,全面强化和提升安监管理部门对安全生产活动的管理职能。该管理模式的目标是立足三大基础管理体系,实现运营安全管理体系与智能电网技术支撑体系的有效融合,最终实现“精益安全作业、安全数据集约管理、安全监督工作专业化、全过程安全风险预控、安全事件迅速响应和安全决策智能化”。
近年来,人工智能发展势头迅猛,在很多领域都得到了卓有成效的运用,这也给安监技术的改变创新带来了契机,而提升安全监督信息化水平也是创新电力安监模式的主要方向。应用智能安监设备,能够辅助现场人员提前发现风险,在作业中有效规避风险;与安全生产子系统进行数据对接,减少现场录入工作量,在提升工作效率的同时,有助于提升现场风险管理水平。
基于深度学习的目标检测算法[2-4]主要分为基于建议框的方法(R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、FPN)和免建议框的方法(YOLO、SSD、DSSD、RetinaNet)。2015年,YOLO算法的出现使得深度学习目标检测算法开始有了两步(two-stage)和单步(single-stage)之分。YOLO算法通过共享卷积特征的方式提取候选框和进行目标识别,检测速度较Faster R-CNN有近10倍的提升。2016年,微软研究院的Jifeng Dai等人提出R-FCN算法,通过共享卷积层特征实现目标提取。后续的SSD算法,利用卷积核来预测边界框的类别分数和偏移量,不仅提高了检测精度,同时还提升了检测速度。
这些发展使得深度学习目标检测算法开始能够满足实时检测任务的需求。但到目前为止,将深度学习应用于电力安监技术的研究几乎没有[5],本文希望通过研究为后续深度学习算法在安监技术领域的应用提供一些新的想法和方向。
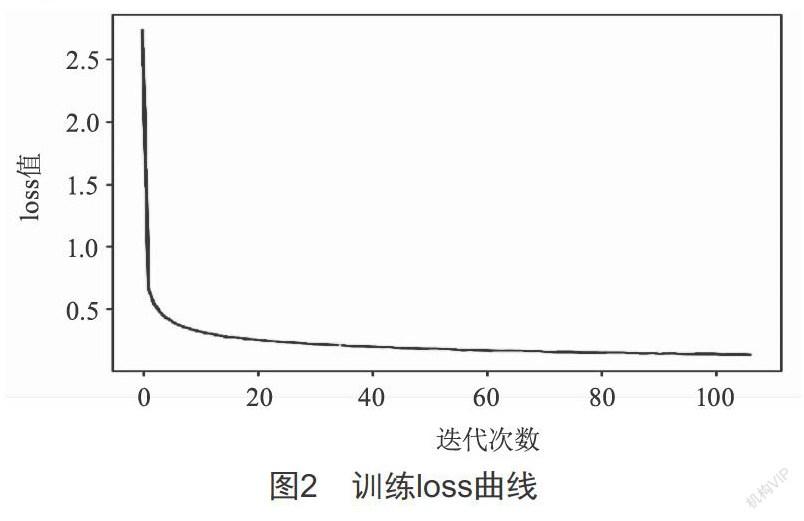
本文收集电网违规场景图片以构建数据集,用图片标注软件LabelImg对数据集中的样本进行准确标注,输入进YOLOv3网络对其进行模型训练,分析得到的模型性能指标并进行测试,进一步探索了智慧现场中电力安全工作的创新方向。
1 YOLOv3目标识别算法
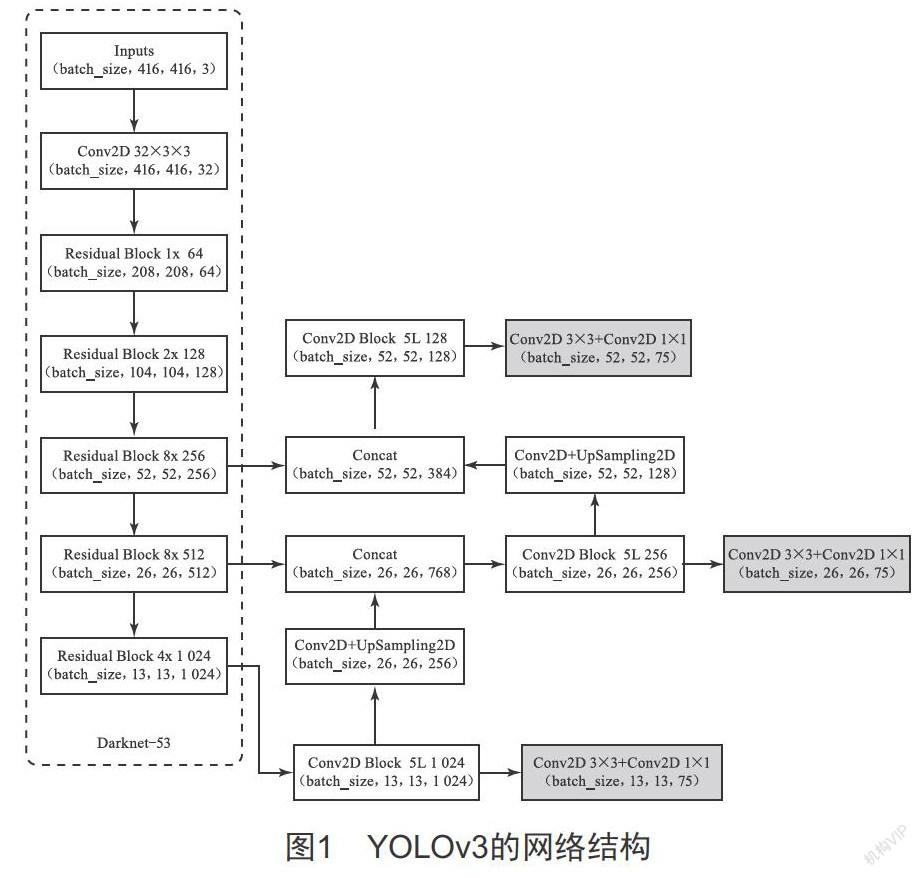
YOLOv3的网络结构是基于Darknet-53的特征提取结构,具体如图1所示。
可以将YOLOv3的总体结构分为两个部分,分别为主干特征提取网络和预测卷积操作。主干特征提取网络的主要功能是提取目标物体的特征,其实也就是不断卷积的过程。输入416×416×3(其中416×416是图片大小,3为通道数)的图片,然后对其不断进行下采样的操作,将输入图片的高和宽不断压缩,将通道数不断扩张,从而获得一堆特征层(可表示输入进来的图片的特征)。
之后,选取最后3个特征层,输入到第二部分的预测卷积操作,3个特征层的大小分别为:13×13×1 024、26×26×512、52×52×256。预测卷积操作是首先将13×13×1 024的特征层进行五次卷积,将得到的结果分别进行两种处理:一种是在两次卷积后进行分类预测和回归预测,检测图片中是否存在真实物体,若存在真实物体再判断这个物体的种类并调整先验框;另一种是在进行上采样后将特征层转换为26×26×256,然后与26×26×512的特征层进行堆叠对比,这实际上也是构建特征金字塔的过程,利用特征金字塔可进行多尺度特征融合提取更有效的特征。而对堆叠结果的操作同13×13×1 024特征层的操作相同。这样的网络结构十分简单,也正是因为如此,YOLO网络的识别速度极快。又因为检测是以整个图像作为输入,内部数据的联系相对紧密,这样一来就可以降低对背景的错误识别概率,同时网络的适应性较好,在测试集与训练集内的数据不完全相同时依然有较好的识别效果,与同期的识别算法相比,YOLOv3的准确率能达到其两倍以上。
2 电网违规场景数据集的建立
2.1 样本图片的获取
本文选择了具有一定实际意义的“未佩戴安全帽”为违规施工场景,那么目标识别算法就需要通过学习训练以达到识别出“安全帽”和“头部”的目的。所以,首先通过网络平台的图片搜索引擎获取了1 018张样本图片,图片包含了人员不佩戴安全帽和人员佩戴安全帽的各个角度,以确保目标识别算法的训练效果。
2.2 图像标注
本文选择了LabelImg软件对样本图片进行标注。标注的标签类型为“head”和“hat”。用LabelImg软件标注后会得到标注目标的PASCAL_VCO格式的xml标记文件。文件中的信息包含图片的大小(宽度、高度、深度)和标记目标边界框的左上角和右下角的坐标,以便得到目标物体的中心点坐标,从而学习并记忆该目标物体的特征。
猜你喜欢
数字技术与应用(2016年10期)2017-04-01
科技创新与应用(2017年6期)2017-03-23
中国新通信(2017年3期)2017-03-11
中国水运(2017年1期)2017-02-27
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
科学与财富(2016年28期)2016-10-14
现代电子技术(2014年22期)2014-11-14
