
运用自然语言处理技术及时发现群众反映的热点问题
2021-09-12 14:51方小宇罗补干周铄洋郭丽莎
科技尚品 2021年7期
关键词:热点问题
方小宇 罗补干 周铄洋 郭丽莎


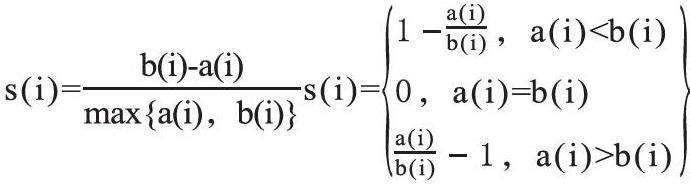
摘 要:某一时段内群众集中反映的某一问题被称为热点问题。面对纷繁复杂的各类留言,人工寻找最需解决的问题即热点问题,会耗费很多的时间和精力。因此,利用自然语言处理技术在众多留言中挖掘热点问题,是社会治理创新发展的新趋势,有助于政府及时了解民意,提升服务效率。为了解决这个问题,通过对搜集的留言进行数据预处理,运用Single-Pass聚类算法,对留言进行聚类,利用轮廓系数进一步优化聚类效果,最终通过TextRank的自动文摘算法计算每个标题的权重并排名。权重越大的标题,说明群众反映的问题最强烈,以此实现对热点问题的及时发现。
关键词:热点问题;Single-Pass聚类;TextRank
中图分类号:TP391文献标识码:A文章编号:1674-1064(2021)07-096-03
DOI:10.12310/j.issn.1674-1064.2021.07.047
1 国内外研究现状
热点事件提取是话题检测与跟踪(Topic detection and tracking,简称TDT)的一个分支[1],TDT是信息检索的研究领域之一,包含五种任务,如表1所示。
TDT以事件信息组织为特征,以事件为目标。因此,大部分研究将TDT技术应用于事件检测中(event detection)。相比传统的信息检索,TDT更倾向于处理动态非确定的概念,类别和基于内容的话题。然而传统的信息检索技术如文本分类、话题模型(topic model)、LSA等适合文档分类和索引的方法,但却不太适合事件和新事件发现,因而Allan、Laverenko等人提出基于传统全文相似度的上界来检测[2]。
事件检测有许多种方法,主流的方式是采用聚类,这样检测事件可以借鉴传统的信息检索方法聚类对文档进行聚类,将关联文档按照一定的度量方法,通常是相似度,将相关文档放到同一个类中。每一个类代表一个单独的事件或者话题。聚类可以分为两类,一类是层次聚类(Hierarchical clustering)建立关系,将关系相近的簇聚成一类,分层进行聚类;另一类平聚类(flat clustering)并不利用层次关系聚类[3]。
Single-Pass聚类的类别生成是通过较新的数据与先前所有簇的相似程度。如果足够相似,那么新的数据将被聚到先前的簇中;如果不够相似,则作为新簇。Single-Pass被广泛用于TDT中的新事件检测任务中,Ron Papka提出了将Single-Pass聚类用于在线的新事件检测中[4],每一个类用簇的平均值作为质心向量来表示。Hila Beckert提出一种集成方法,从文档结构中提取标题词、描述词、地点和时间作为特征进行Single-Pass的聚类,侧重相似度的度量,提出了归一化互信息方法进行评价[5]。
2 主要步骤和任务
热点问题挖掘主要包括文本预处理、文本聚类、聚类评估和热点问题排行四个模块。
2.1 基于Single-Pass聚类算法的留言聚类分析
首先将文本进行预处理,并建立VSM(Vector Space Model)向量,其能够以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。然后运用Single-Pass算法对文本进行聚类分析。
Single pass算法的基本流程[7]是,首先将第一篇到达的文本设为种子文件,然后后面依次到达的文本与已有的文本进行相似度比较,得到与先前文本最大的相似度。如果这个相似度大于给定的阀值,则将这个文本分配到与其相似度最大的文本所在的话题类中去;如果将此文本与所有的己存在文本比较,其相似度都小于给定的阈值,则以此文本建立一个新的聚类[6],该算法流程如图1所示。
通过聚类,可以获得每条回复所属的话题(label列),聚类结果显示共有254类。
2.2 基于轮廓系数的聚类效果评估
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式,最早由Peter J.Rousseeuw在1986年提出。其结合内聚度和分离度两种因素,可以用来在相同原始数据的基础上,评价不同算法或者算法不同运行方式对聚类结果所产生的影响。评估方法如下:
计算样本i到同簇其他样本的平均距离ai。ai越小,说明样本i越应该被聚类到该簇。将ai称为样本i的簇内不相似度,簇C中所有样本的ai均值称为簇C的簇内不相似度。
計算样本i到其他某簇Cij的所有样本的平均距离bij,称为样本i与簇Cj的不相似度。定义为样本i的簇间不相似度:bi=min{bi1,bi2,bik},bi越大,说明样本i越不属于其他簇。
根据样本i的簇内不相似度ai和簇间不相似度bi,定义样本i的轮廓系数:
判断:si接近1,则说明样本i聚类合理;si接近-1,则说明样本i更应该分类到另外的簇;若si近似为0,则说明样本 在两个簇的边界上。
笔者运用轮廓系数法对聚类结果进行评估,使用sklearn的silhouette_score方法实现,结果如图2所示。
由图2可知,随着阈值的提高,轮廓系数也相应上升,聚类结果也有大幅提升,因此笔者重新选择较大的阈值来获取所需聚类结果。
2.3 基于TextRank的自动文摘算法
TextRank是一种基于图的用于文本的排序算法[8],基本思想来自Google的PageRank算法[7]。类似于网页的排名,对于词语可得到词语的排名,对于句子也可得到句子的排名,所以TextRank可以进行关键词提取,也可以进行自动文摘。其用于自动文摘时的思想是:将每个句子看成PageRank图中的一个节点,若两个句子之间的相似度大于设定的阈值,则认为这两个句子之间有相似联系,对应的这两个节点之间便有一条无向有权边,边的权值是相似度,接着利用PageRank算法即可得到句子的得分,把得分较高的句子作为文章的摘要。
TextRank算法的主要步骤如下:
预处理:分割原文本中的句子得到一个句子集合,然后对句子进行分词以及去停用词处理,筛选出候选关键词集;
计算句子间的相似度:在原论文中采用如下公式计算句子1和句子2的相似度:
对于两个句子之间相似度大于设定阈值的两个句子节点,用边连接起来,设置其边的权重为两个句子的相似度。
计算句子权重:
其中,Wi表示第i个句子的权重,Join(i)代表与第i个句子相连的全部句子集合,Similar(a,b)表示a与b的相似度。由该公式多次迭代计算直至收敛稳定之后,可得各句子的权重得分。
形成文摘:将句子按照句子得分进行倒序排序,抽取得分排序最前的几个句子作为候选文摘句,再依据字数或句子数量要求,筛选出符合条件的句子组成文摘。
3 热点问题排行
3.1 基于统计的总体问题的热点排行
热点问题(hot problem)的热门程度依赖于两个因素,一个是热门词语出现在留言中的次数,另一个是该词在多少个留言中出现。热点问题不可能一直热门,随着时间流转,热门程度会衰减,新的热点问题会出现。因此,笔者将热点问题定义为,一个问题在一段时间内频繁出现。
根据对热点问题的定义,笔者认为一个事件在一段时间内发生的次数越多,则其热度越高,即热度高的事件,留言出现的频率也越高,同时,热度受到持续时间的影响也不应过大。因此,笔者结合上述分析给出热度指数的计算公式:
其中,Hot为事件的热度指数,n为该事件在留言中出现的条数,N为总留言数,T为事件的持续时间,当持续事件小于10天时,文章取T=10。
3.2 基于TextRank自动文摘算法的热点内部话题排行
利用TextRank算法进行热点内部话题排行的过程:首先对每簇热点问题合并所有的留言标题,接着用TextRank算法计算每个标题的权重,然后按照权重排序,得到标题的排行文件,用权重最高的标题当成主话题,至此过程结束。最终得到的热点问题排行前五的结果如表2所示。
由表2看出,每条热点都通过热度指数大小进行排序,通过增加一列“hot_rate”来代表问题的热度。该值越大,代表该类问题的热度越高,由此就实现对群众反映强烈的热点问题的汇总。
参考文献
[1] J.Allan,J.Carbonell,G.Doddington,et al.Topic detection and tracking pilot study:Final report[C].In Proceedings of Broadcast News Transcription and Understanding Workshop.Lansdowne,VA:NIST,1998:94-218.
[2] J.Allan,V.Laverenko.First story detection in TDT is hard[C].In Proceedings of the 9th international conference on Information and Knowledge Management(CIKM).New York,NY,USA:ACM press,2000:374-381.
[3] David M,Blei Ng,Andrew Y.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[4] C.D.Manning,P.Raghavan,H.Schiutze.Introduction to information retrieval[M].New York,USA:Cambridge University Press,2008:108-200.
[5] Ron Papka,James Allan.On-line new event detection using single pass clustering[R].Technical Report:UM-CS-1998-021.MA,USA:University of Massachusetts Amherst,1998:20-30.
[6] Hila Becker,Mor Naaman,Luis Gravano.Event identification in social media.Twelfth International Workshop on the Web and Databases(WebDB 2009)[C].Providence,Rhode Island,USA:Association for the advancement artificial intelligence,2009:110-104.
[7] 張培伟.基于改进Single-Pass算法的热点话题发现系统的设计与实现[D].武汉:华中师范大学,2015.
[8] 蒲梅,周枫,周晶晶,等.基于加权TextRank的新闻关键事件主题句提取[J].计算机工程,2017,43(8):219-224.
猜你喜欢
晚晴(2019年9期)2019-11-01
法制博览(2017年1期)2017-02-14
科教导刊·电子版(2016年29期)2016-12-23
青春岁月(2016年22期)2016-12-23
人民论坛(2016年23期)2016-12-13
中学生数理化·高一版(2016年7期)2016-12-07
中学课程辅导·教师通讯(2014年14期)2015-07-22
中学政史地·高中文综(2009年5期)2009-06-15
中学生数理化·高二版(2008年6期)2008-11-12
