
基于词频比的改进Jaccard系数文本相似度计算
2021-09-13 11:49中国人民大学信息学院
内江科技 2021年8期
◇中国人民大学信息学院 谢 红
基于词频比的改进Jaccard系数文本相似度计算,交集中词的权重不是相同的,而是按照词频比确定权重。通过短文本实验和长文本实验,基于词频比的改进Jaccard相似度比传统Jaccard相似度更加科学合理,适合法律法规、政策文件等说明性文本的相似度计算。
1 引言
文本相似度计算是指通过一定的策略比较两个或多个实体(包括词语、短文本、文档)之间的相似程度,得到一个具体量化的相似度数值[1]。相似度数值用[0,1]闭区间的实数表示,数值越大,文本相似度越高。
文本相似度计算广泛应用在信息检索、文本分类、文本聚类、文本查重、问答系统、推荐系统等领域。
目前,计算文本相似度的方法通常有四类:基于字符串(String-Based)的方法、基于语料库(Corpus-Based)的方法、基于知识库(Knowledge-Based)的方法和混合方法[1-4]。其中,基于字符串的方法是从字符串匹配度出发,以字符串共现和重复程度为相似度的衡量标准[5]。在基于字符串的方法中,最基础的是利用Jaccard系数计算文本相似度。
2 Jaccard系数
Jaccard系数用来比较样本集合之间的相似性与差异性,是计算机领域中考察文本相似度时常用的一种方法[6]。
给定两个集合A和B,当集合A与B不同时为空集时,即A与B的并集不是空集时,Jaccard系数定义为A与B交集的大小除以A与B并集的大小,即:
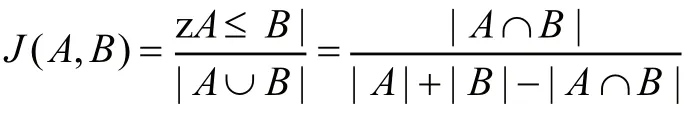
当集合A与B都是空集时,Jaccard系数定义为1。
Jaccard系数值越大,表明样本之间相似度越高。
由于集合元素的互异性,Jaccard系数用于文本相似度计算时不考虑词在文本中出现的次数,即不考虑词的频率,交集中每个词的权重都是相同的,例如X=|A∩B|={x1,x2,…,xn},那么每个词xi的 权重都是1/n,设词xi在 文本1中的出现的频率是f1,在文本2中的出现的频率是f2,当f1f2或f1f2时,词xi按照1/n权重参与文本计算相似度的计算显然是不精确的,而采用基于词频比的改进Jaccard系数文本相似度计算更加合理、准确。
3 基于词频比的改进Jaccard系数
3.1 原理
基于词频比的改进Jaccard系数文本相似度计算的原理是,交集中词的权重不是相同的,按照词频比确定权重,具体算法是:
设X=|A∩B|={x1,x2,…,xn},设词xi在 文本1中的出现的频率是f1,在文本2中的出现的频率是f2,比较f1和f2的 大小,当f1≤f2时,词xi的 权重是f1/ f2,否则权重是f2/ f1,将交集中所有词x1,x2,…,xn的 权重求和,最后将交集权重和除以并集元素个数作为文本相似度。
基于词频比的改进Jaccard相似度显然比Jaccard相似度更加合理,通常情况下,基于词频比的改进Jaccard相似度都会小于Jaccard相似度,只有在交集为空,或者所有交集中的词频都是“1”的情况下,两者相似度相等。
3.2 步骤
基于词频比的改进Jaccard系数文本相似度计算的步骤主要有分词、去停用词、统计词频并按词排序、计算交集中的词频比、计算相似度。
具体算法是:分词前去掉空格和符号,只保留文字和数字,然后采用jieba分词;去停用词,去掉文本中语气助词、副词、介词、连词等实际意义不大的词,如“的”、“在”、“和”、“接着”等;建立字典并按词排序,建立词列表和词频列表;求出词的交集和并集,统计交集个数和并集个数,只保留交集列表中的词频,因为非交集的词在计算相似度时的值是零,所以不必保留,这样可以有效减少列表长度和计算时间;将进行相似度比较的两个文本的交集词频存放在两个列表中,低词频存放在minList[i],高词频存放在maxList[i],计算对应词频比minList[i]/maxList[i],将对应词频比求和,即:
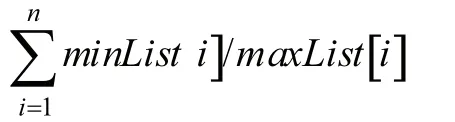
最后除以并集列表的长度;通过以上步骤求出基于词频比的改进Jaccard系数的文本相似度。
4 实验与结果分析
实验采用python 3.5编程实现,无论是短文本实验,还是长文本实验,基于词频比的改进Jaccard相似度都比传统Jaccard相似度更加科学合理。
4.1 短文本实验与结果分析
短文本相似度实验可以直观解释基于词频比的改进Jaccard系数计算文本相似度的原理。参与计算的两个短文本分别是短文本1:爸爸爱妈妈,妈妈爱爸爸。短文本2:我爱爸爸和妈妈。停用词表为“和”。
程序运行结果如下:
读入的文本1为:爸爸爱妈妈,妈妈爱爸爸。
分词后的文本1为:爸爸 爱妈妈 妈妈 爱爸爸。
去停用词后的文本1为:爸爸 爱妈妈 妈妈 爱 爸爸。
读入的文本2为:我爱爸爸和妈妈。
分词后的文本2为:我爱爸爸 和妈妈。
去停用词后的文本2为:我爱爸爸 妈妈。
文本1的列表为:['爸爸','爱','妈妈','妈妈','爱','爸爸']。
文本1的字典排序为:[('妈妈',2),('爱',2),('爸爸',2)]。
文本1的词为:['妈妈','爱','爸爸']。
文本1的词频为:[2,2,2]。
文本2的列表为:['我','爱','爸爸','妈妈']。
文本2的字典排序为:[('妈妈',1),('我',1),('爱',1),('爸爸',1)]。
文本2的词为:['妈妈','我','爱','爸爸']。
文本2的词频为:[1,1,1,1]。
交集列表为:['妈妈','爱','爸爸']。
并集列表为:['妈妈','我','爱','爸爸']。
交集个数为:3;并集个数为:4;Jaccard相似度为:3/4=75.00%;交集低词频列表为:[1,1,1];交集高词频列表为:[2,2,2];词频比为:[0.5,0.5,0.5];基于词频比的改进Jaccard相似度为:1.5/ 4=37.50%。
实验结果表明,基于词频比的改进Jaccard相似度明显比Jaccard相似度更加精确。
4.2 长文本实验与结果分析
长文本相似度实验采用《中华人民共和国教育法》作为测试数据。法律法规颁布以后,为了与时俱进,常常会进行修正和修订,比较相关法律法规的相似度有利于研究法律法规的延续性和差异性。《中华人民共和国教育法》于1995年颁布,2009年第一次修正,2015年第二次修正。经过3次相似度对比实验,实验结果如下:
2009年修正的教育法对比1995年颁布的教育法:交集词个数为:806;并集词个数为:814;Jaccard相似度为:99.02%;基于词频比的改进Jaccard相似度为:98.14%。
2015年修正的教育法对比1995年颁布的教育法:交集词个数为:779;并集词个数为:929;Jaccard相似度为:83.85%;基于词频比的改进Jaccard相似度为:77.67%。
2015年修正的教育法对比2009年修正的教育法:交集词个数为:778;并集词个数为:922;Jaccard相似度为:84.38%;基于词频比的改进Jaccard相似度为:78.82%。
实验结果分析:1995颁布的教育法共有84条法条,2009修正的教育法共有83条法条,其中修改1条,删除1条,2015修正的教育法共有86条法条,其中修改15条,增加3条。因为2009修正的教育法修改的法条非常少,2015修正的教育法修改的法条比较多,所以3次实验结果完全符合实际情况。
5 结语
基于词频比的改进Jaccard系数计算文本相似度算法简单,实现方便,运行高效,不需要语料库和知识库,适合法律法规、政策文件等说明性文本的比较。这种方法的不足之处是每个词语都是独立的,没有考虑词语之间的顺序,也不包含语义信息,所以“我爱妈妈”和“妈妈爱我”的相似度是100%,“我爱妈妈”和“我爱母亲”的相似度是50%,这时候的相似度计算是不准确的,需要采用其他方法进行比较。
猜你喜欢
文萃报·周二版(2022年17期)2022-04-30
健康之家(2021年19期)2021-05-23
小学生学习指导(中年级)(2021年4期)2021-04-27
甘肃教育(2020年2期)2020-09-11
课堂内外(初中版)(2020年5期)2020-06-19
亚太教育(2018年5期)2018-12-01
长江丛刊(2017年27期)2017-12-01
中学生数理化·中考版(2015年10期)2015-09-10
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
