
基于粒子滤波的一维非恒定流模拟多变量校正方法
2021-09-14 09:55顾炉华赖锡军
水利水电科技进展 2021年3期
顾炉华,赖锡军
(1.江苏省环境科学研究院,江苏 南京 210036; 2.长江勘测规划设计研究有限责任公司上海分公司,上海 200439; 3.中国科学院南京地理与湖泊研究所,江苏 南京 210008)
为减少数值模型的不确定性,数据同化方法被引入到水文、水动力模型[1-2]。数据同化方法可分为确定性方法和不确定性方法,前者由果及因,根据已知结果反推未知参数,代表方法有变分法[3-4];后者基于统计估值理论,通过实时融入观测实现预报场的动态更新,代表方法有卡尔曼滤波和粒子滤波算法[5-6]。卡尔曼滤波及其改进算法以其在高维度、非线性系统中的良好表现在水文预报领域得到应用与发展,成为实时校正的主流技术之一。但这些算法都假设噪声在空间上为零均值高斯分布,在非高斯系统中应用会出现滤波发散问题。而粒子滤波算法能很好地解决这一问题,粒子滤波又叫顺序蒙特卡罗滤波,是对贝叶斯估值理论的一种蒙特卡罗算法实现。与经验方法、优化插值、连续方法等传统实时校正方法及集合卡尔曼滤波方法相比,粒子滤波算法的优势主要体现为:不受高斯分布假设的约束、能更好表现非线性系统的变化信息、计算效率高、算法容易实现等[7-10]。
关于粒子滤波方法应用于水力学模型的研究目前主要集中在滤波参数选择、算法结构完善、洪水预报等方面。Moradkhani等[11]运用粒子滤波对模型状态变量及参数展开了不确定性分析;Nohs等[12]提出了基于粒子滤波的状态变量和参数同步更新算法;毕海芸等[13-16]提出了残差重采样、分层重采样、聚合重采样等方法,进一步完善了粒子滤波的性能;杨瑞祥等[17]和徐兴亚等[18]分别将粒子滤波应用于水文模型和水动力模型进行洪水预报,对滤波的实用性进行了进一步验证。这些成果丰富了粒子滤波方法的理论和应用。
本文将粒子滤波方法引入一维非恒定流模拟计算中,建立一维水量模拟的多变量校正方法,分析粒子数量、状态变量扰动误差标准差和边界条件的不确定性对滤波性能的影响,比较粒子滤波与集合卡尔曼滤波的性能,为粒子滤波方法在河网水量分析、洪水预报等实际应用提供技术支撑。
1 粒子滤波基本原理
1.1 贝叶斯滤波原理
贝叶斯滤波利用观测数据来构造系统状态的后验概率密度,利用状态转移模型估计系统状态的先验概率密度,再结合最新的观测数据对先验概率密度进行修正,继而得到系统状态的后验概率分布。
首先,建立状态方程和量测方程:
Xk=AXk-1+BUk+Wk
(1)
Zk=Hk+Vk
(2)
式中:Xk为k时刻系统的状态量;Uk为k时刻系统的控制量;A、B为状态系统参数矩阵;Zk为k时刻的观测量;Hk为k时刻量测系统的观测矩阵;Wk、Vk分别为k时刻状态系统和量测系统的噪声。
假设状态系统Xk服从一阶马尔科夫过程且量测系统Zk独立,那么根据条件概率理论,式(1)可表达为先验概率p(Xk|Zk-1),式(2)可表达为似然概率p(Zk|Xk)。由贝叶斯条件概率公式,可推出后验概率p(Xk|Zk)的表达式:
(3)
在实际应用中,大多数的后验概率密度都是很难直接进行解析的,为此引入多重积分的蒙特卡罗方法。
1.2 蒙特卡罗方法
蒙特卡罗方法的核心思想是把待求解的问题抽象为随机事件,通过从已知的概率分布中随机抽样,实现对所求问题的解的近似估计。蒙特卡罗方法的理论基础是大数问题,当样本足够大时,蒙特卡罗估计就等同于贝叶斯后验概率密度。
从p(Xk|Zk)中随机抽取独立分布的N个样本{Xk1,Xk2,…,XkN},状态系统的后验概率密度分布可近似表示为
(4)
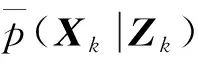
1.3 粒子滤波方法
粒子滤波方法是用蒙特卡罗方法求解贝叶斯后验概率密度的方法,它将每一个样本视作一个粒子,以似然值作为粒子的权重,通过对粒子加权平均得到后验概率密度。粒子滤波可分为4步:模型预报、重要性采样、重采样和粒子扰动。
模型预报是在生成若干个水流状态粒子后,基于数学模型驱动各个粒子平行计算,得到每一个时刻水流状态的预报值。
粒子滤波基于序贯重要性采样,即在蒙特卡罗思想中应用统计学理论中的序贯分析方法,以递推得到后验概率密度函数的最优估计。其实现方式是计算每个粒子的似然值,并将其归一化。本文采用如下似然函数:
(5)
式中:wki为k时刻第i个样本的似然值;σ为相对标准差。
在粒子权重更新的过程中,不可避免地会出现“粒子退化”现象,造成大部分计算资源都用在权重很小的粒子上,因此需要用到重采样技术,其本质是复制大权重粒子,剔除小权重粒子,本文采用多项式重采样,其原理见文献[19]。
重采样之后,需再次对粒子群施加扰动,保证粒子群在大权重粒子占多数的情况下仍有一定的多样性。本文采用如下扰动方法:
X(i)=X(i)(1+N(i)σ)
(6)
式中:X(i)为第i个河道断面的状态量;N(i)为第i个河道断面的伪光滑随机扰动场,服从均值为0、方差为1的正态分布。
2 基于粒子滤波的一维非恒定流水量校正模型
2.1 一维非恒定流模型
本文建立的一维非恒定流模型基于圣维南方程组:
(7)
(8)
式中:Z为水位,m;Q为流量,m3/s;K为流量模数;m3/s;q为单位河长旁侧入流,m2/s;A为过水断面面积,m2;α为动量校正系数;g为重力加速度,m/s2;x为沿水流方向距离,m;t为时间,s;B为水面宽度,m。
采用Preissmann四点加权隐格式离散上述两式得到:
A1jΔQj+B1jΔZj+C1jΔQj+1+D1jΔZj+1=E1j(9)
A2jΔQj+B2jΔZj+C2jΔQj+1+D2jΔZj+1=E2j(10)
式中符号的含义可见文献[20]。对于缓流,在已知上下游边界条件的情况下,可用追赶法求出各系数,进而求得河道各断面每一时刻的水位值和流量值。
2.2 水量校正模型算法流程
首先对水位和流量施加随机扰动,生成N个水流状态粒子;没有观测数据融入的时刻,驱动粒子进行并行计算,形成粒子群搜索空间;在有观测数据输入的时刻,启动粒子滤波模块,对观测数据的类型及误差进行分析;计算每个粒子与观测之间的似然值,得到粒子权重;接着对粒子群进行多项式重采样,计算粒子的平均值并输出。图1为第k时段内粒子滤波水量校正模型算法流程。
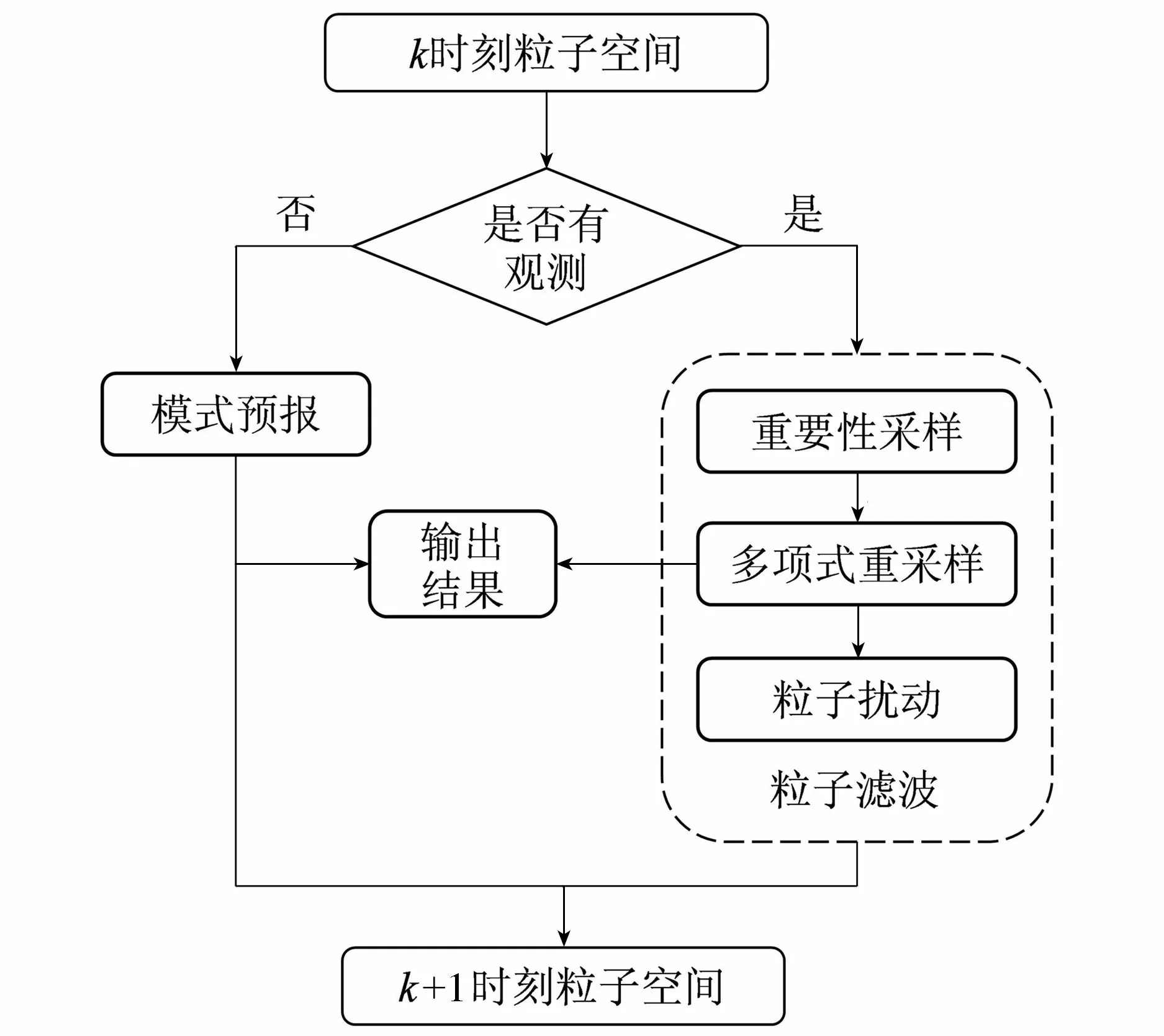
图1 基于粒子滤波的水量校正模型算法流程(第k时段内)
3 合成数值试验
3.1 案例选择
为分析粒子滤波在非恒定流计算中的应用性能,以单一河道洪水演进过程为例开展合成数值试验。该河道全长60 km,上游给定流量边界,下游给定水位边界。共设置4个观测站点,分别布置在距离上游11 km、23 km、35 km和47 km处,观测时间间隔为0.5 h。
3.2 试验设计
选择沿程断面水位和流量组成的矩阵作为水流状态粒子,将上游来流过程作为主要的误差源,将其按比例缩放作为上游预报洪水过程,研究粒子滤波在不同预报误差和粒子扰动误差标准差下的校正性能。将模型在实际流量过程下的计算结果作为真实值,从中抽取水位、流量作为观测数据。此外,本文计算了上游预报洪水过程下纯水动力模型的计算结果作为河道预报水位,与数据同化结果进行对比,以检验粒子滤波对水动力模型精度的改善效果。从粒子数量、边界条件缩放系数、水位和流量扰动误差标准差4个方面设置计算条件,开展情景计算,各试验相关参数见表1。
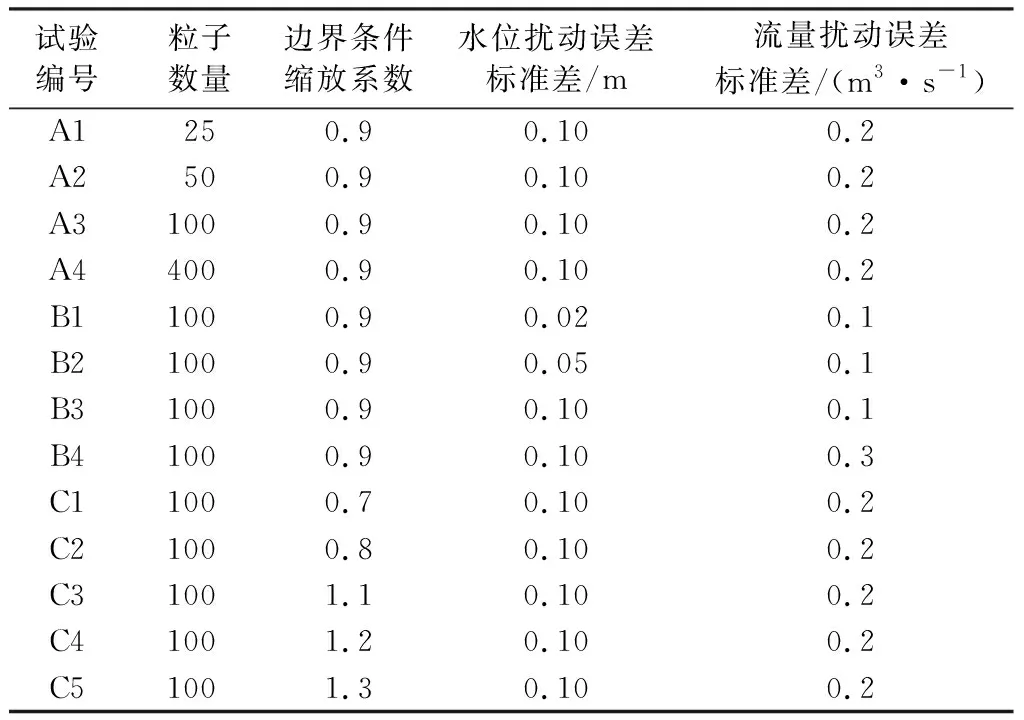
表1 各试验参数值
3.3 试验结果与分析
3.3.1粒子数量对粒子滤波的影响
试验A1~A4的结果显示,粒子数量越多,流量残差和水位残差越小。从图2可以看出,当粒子数量小于100时,流量和水位残差随粒子数量呈快速下降趋势;当粒子数量大于100后,流量和水位残差减小的速度减缓。粒子数量为100时,流量和水位残差分别为17.54 m3/s和0.083 m。更大的粒子数量虽然可以带来更好的效果,但是也会意味着更大的计算量。在本算例中,粒子数量取100可同时满足计算精度与效率的要求。
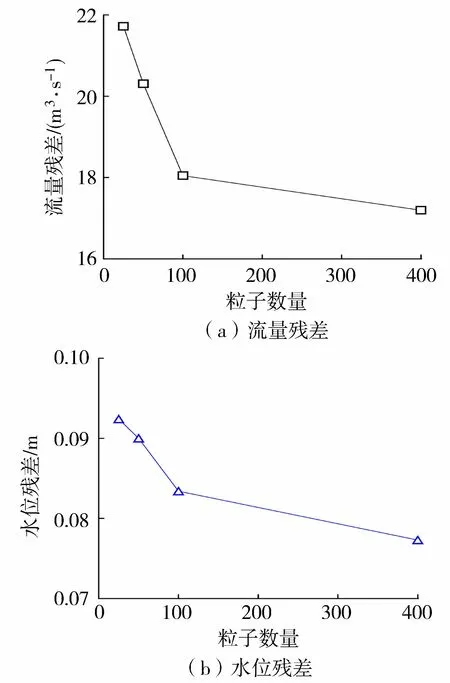
图2 不同粒子数量下水位和流量残差
3.3.2扰动误差标准差对粒子滤波的影响
状态变量扰动误差决定了粒子群搜索空间大小和粒子群分布密度。搜索空间太小将限制粒子活动范围,使其无法到达真实值附近;搜索空间太大又会造成粒子群分布密度降低,真实值周边缺乏有效粒子。采用纯水动力模型的计算结果(预报值)获得的水位残差为0.160 m,流量残差为35.45 m3/s,水位精度为0.950,流量精度为0.942。测试结果显示,试验B3中参数设置对发挥粒子滤波效果最有利,水位残差和流量残差分别为0.078 m和17.37 m3/s,较预报值情况下降低了约50%,水位和流量模拟精度达到99%(表2)。
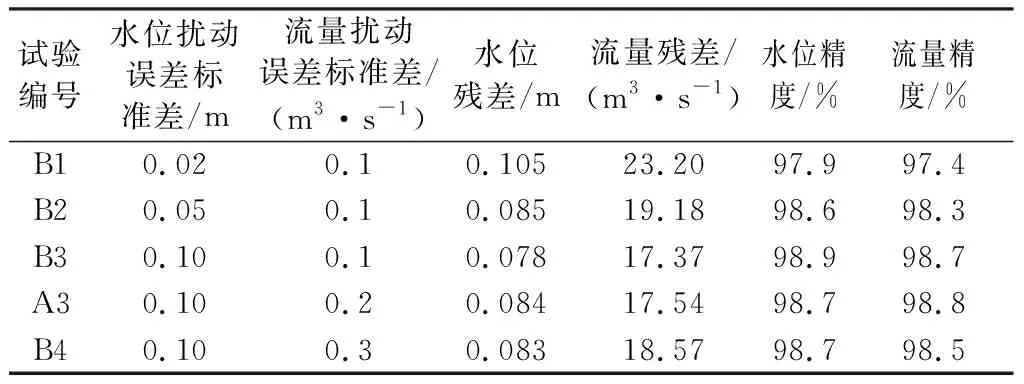
表2 不同扰动误差标准差下水位和流量残差统计
3.3.3边界条件对粒子滤波的影响
由表3可知,当边界条件缩放系数取0.9和1.1时,水位残差分别只有0.08 m和0.07 m,对应的流量残差均小于20 m3/s;当边界条件缩放系数取0.7和1.3时,水位残差均达到0.26 m,流量残差分别高达54.54 m3/s和64.57 m3/s。平均纳什效率系数(NSE)也显示,当边界条件相对误差在20%以内,即边界条件缩放系数在0.8~1.2之间时,粒子滤波效果较好,模拟精度可达94%以上;当边界条件相对误差大于20%时,滤波后精度小于90%(表3)。
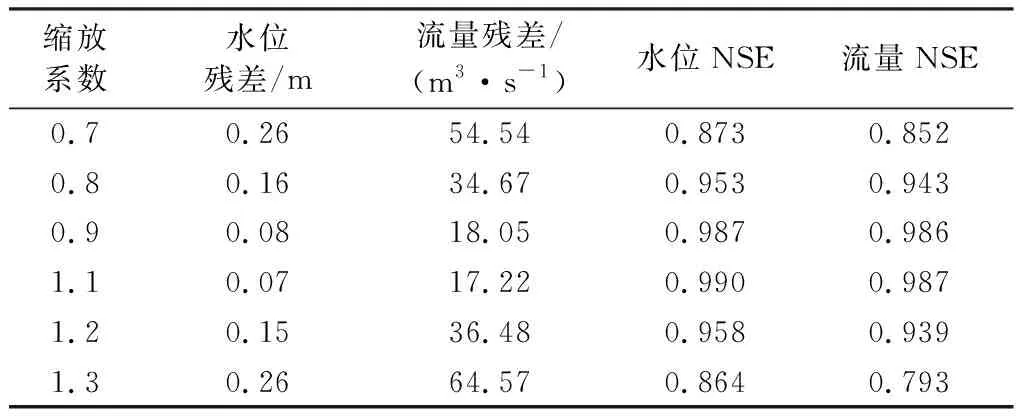
表3 不同缩放系数下水位和流量残差统计
3.3.4粒子滤波与集合卡尔曼滤波的比较
将粒子滤波与文献[6]中基于集合卡尔曼滤波的多变量交替校正方法进行对比,为保证结果的合理性,模型边界条件、状态变量扰动误差标准差、集合与粒子个数等主要参数均保持一致。选取距上游边界10 km(断面1)、30 km(断面2)、50 km(断面3)3个断面流量过程作为比较对象,总体而言,粒子滤波与集合卡尔曼滤波都具有很好的滤波效果,3个断面的平均流量预报精度分别达到了98.4%和98.8%,集合卡尔曼滤波算法在结果的准确性和稳定性上更具优势,洪峰时刻采用集合卡尔曼滤波分析出的洪峰流量比粒子滤波更接近真实值;洪水后期,采用粒子滤波分析出的流量围绕真实值上下波动,而采用集合卡尔曼滤波获得的流量与真实值紧密贴合(图3)。粒子滤波由于无需进行复杂的矩阵计算,从而具有更高的计算效率。在本文使用的案例中,使用集合卡尔曼滤波算法完成一次洪水过程的水量校正需要的CPU时间为883 s,而粒子滤波只要379 s,计算效率约是前者的2.3倍。
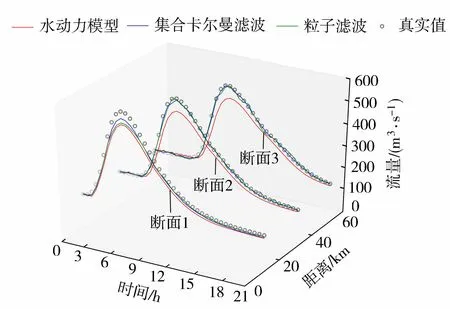
图3 不同河道断面流量过程比较
4 实例验证
4.1 案例选择
选取太湖流域河网水量模型对粒子滤波的实际应用性能进行验证,验证时段为2012年全年。以河网节点水位作为状态变量,以太湖(西山)、常州、金坛、溧阳等13个站点的逐日实测水位作为更新模型状态的观测资料,水位扰动误差标准差取为实际值的5%,考虑到模型计算量过大,为减少计算时间,本案例中将粒子数取为50。这种选择虽会在一定程度上减弱滤波效果,但是不妨碍验证粒子滤波算法在太湖河网水量同化中应用的有效性。太湖流域河网及水文站分布见图4。
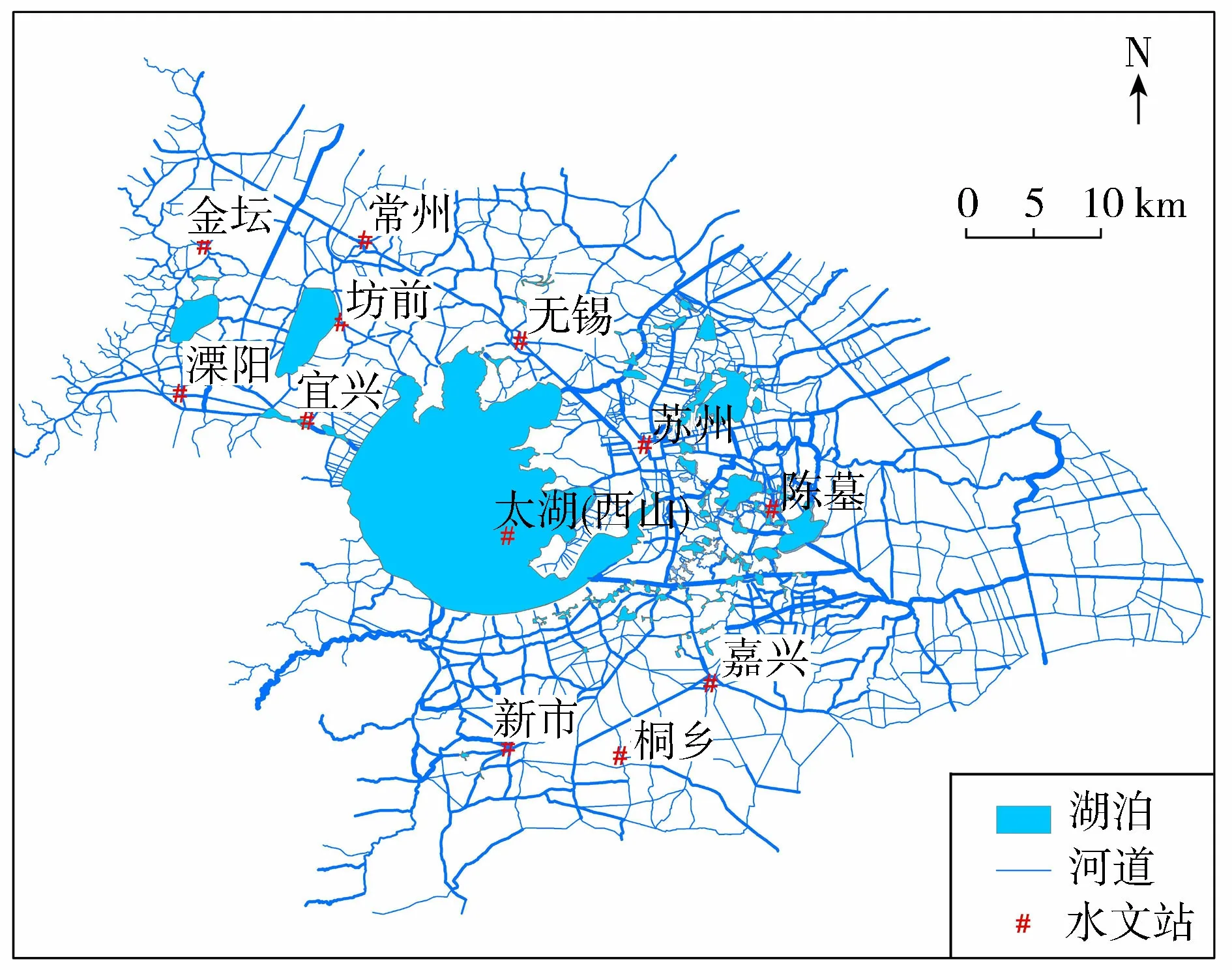
图4 太湖流域河网及水文站分布
4.2 计算结果与分析
平原河网地区河道多为往复流,流量站少于水位站,且大型水利枢纽多以水位作为调度控制指标,水位对流域水资源的管理与调度更具意义,因此本次分析仅关注流域水位过程。
河网概化、边界条件、闸站调度等方面的不确定性使得太湖流域河网水量模型模拟出的太湖(西山)、溧阳、苏州、新市4站的水位与实测值存在较大差距。滤波后的模拟效果有了很大改善,但是不同站点的改善效果存在差异(图5)。太湖(西山)站、溧阳站和苏州站滤波效果较好,滤波后的水位与实测水位十分吻合,水位残差从滤波前的0.17 m、0.40 m、0.10 m分别降为0.05 m、0.10 m和0.05 m,纳什效率系数也分别达到了91%、82%和84%;新市站的滤波效果稍差,滤波后的水位仍低于实测水位,但相比于河网水量模型预报结果,水位残差从0.29 m降至0.18 m,降幅为38%。总体而言,粒子滤波应用于实际河网水量校正可有效改善模拟精度。
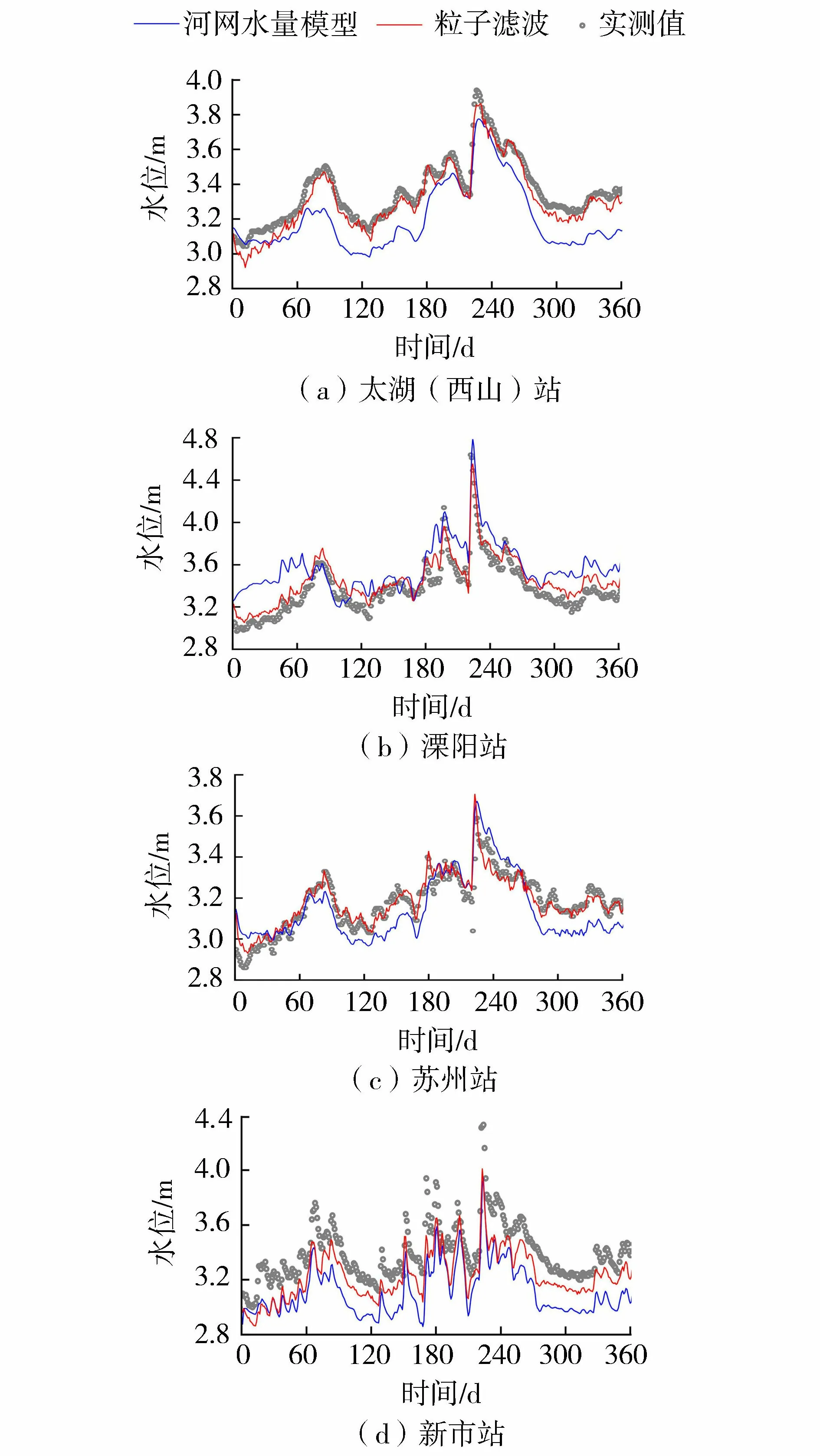
图5 主要水文站水位过程对比
5 结 语
本文建立了基于粒子滤波的一维非恒定流水量校正模型,通过对水流状态粒子进行统计估值,实现模型状态变量的最优估计。探讨了多变量校正方法在一维非恒定流计算中的性能,并分析了粒子数量、状态变量扰动误差和边界条件的不确定性对滤波效果的影响。结果证实了粒子滤波可显著改善模拟精度,且具有较高的计算效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年7期)2021-08-13
北京航空航天大学学报(2020年10期)2020-11-14
国学(2020年1期)2020-06-29
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年23期)2019-02-23
家庭影院技术(2018年11期)2019-01-21
北京航空航天大学学报(2017年9期)2017-12-18
