
基于EEMD-RVM的土石坝渗流量时间序列预测模型
2021-09-14 09:55刘永涛郑东健孙雪莲曹立林
水利水电科技进展 2021年3期
刘永涛,郑东健,孙雪莲,曹立林
(1.河海大学水利水电学院,江苏 南京 210098; 2.河海大学水文水资源与水利工程科学国家重点实验室,江苏 南京 210098;3.中国电力工程顾问集团华东电力设计院有限公司,上海 200063; 4.江苏省连云港市通榆河北延送水工程管理处,江苏 连云港 222023)
土石坝由于其经济性、施工技术简便及对地形地质适应性强等优势在坝工领域应用最广泛。在国际大坝委员会的3次溃坝事故调查报告中[1],土石坝的溃坝数量占大坝溃坝总数的70%,其中约25%土石坝的溃决是由坝体渗透破坏导致。为保证运行期土石坝的渗流安全,需结合监测资料对土石坝的渗流进行监控。运行期土石坝渗流监测内容一般为坝后渗流量与坝内渗压水头,其中渗流量是土石坝运行性态的直接表征[2]。因此,研究土石坝渗流量的变化趋势对准确评价大坝安全具有重要意义。大型土石坝工程由于监测资料详实、可靠,因此很多算法可以较好地实现环境量与渗流量之间的映射关系,并且渗流量的预测精度较高,能满足工程应用要求[3-4]。而对于占我国大坝总数90%[5]以上的中小型土石坝,一般监测资料会存在不同程度的缺测,特别是环境量。另一方面,由于规律性不强的降雨、变化的水位、坝体的时效变形等因素对渗流量变化影响较大,因此土石坝渗流的监测数据一般具有非线性及非平稳性,所以在不考虑环境量的情况下研究渗流量时间序列并准确预测比较困难。综上,在不直接考虑大坝环境量对渗流的影响前提下,为了更简便高效地进行中小型土石坝渗流量预测,以渗流量时间序列作为研究对象十分必要。
目前,在缺失环境量的情况下,为解决土石坝渗流量预测中的过拟合和结果不唯一等问题,一些学者在渗流量预测中引入了不同的学习算法[6-7]。这些算法,无论是传统算法还是智能优化算法都存在诸多问题[8],如参数初始值对预测结果的准确性影响较大、算法的鲁棒性总体较差、算法迭代过于复杂且收敛缓慢、预测结果容易陷入局部最优且总体精度较低,所以渗流量时间序列的预测算法在理论研究和应用中均有待提高。为解决智能算法在非平稳时间序列的上述难题,Huang等[9]提出了经验模态分解(empirical mode decomposition,EMD)算法,但EMD存在端点效应和模态混叠程度高的问题;针对EMD存在的问题,Wu等[10]对EMD进行改进,提出了集合经验模态分解(ensemble empirical mode decomposition,EEMD)算法。目前,EEMD算法已应用于环境、水文、医学、地质等多个行业[11-13],但将其应用到土石坝渗流量预测中的研究甚少。
Tipping[14]建立的相关向量机理论(RVM)模型不仅解决了支持向量机(SVM)模型结构稀疏度不高的问题,还简化了核函数的计算程序,提高了计算效率。高杰等[15]给出了基于RVM的边坡可靠度计算方法,解决了极限状态函数无法显式表达、难以求解导数的问题,并且计算速度快、精度高;平善明等[16]通过RVM模型预测了短期风速,并较好地解决了由于间歇性和不稳定性导致风速拟合预测低的问题。
综上,EEMD算法可以较好地解决大坝渗流监测值非平稳性所带来的过拟合问题,RVM算法可以在大坝渗流值的训练拟合和预测过程中提高算法收敛速率、预测精度以及模型的健壮性。因此,笔者运用EEMD算法对大坝渗流监测序列进行模态分解,结合高斯核函数的RVM模型对分解分量进行拟合训练,构建基于EEMD-RVM土石坝渗流量时间序列的预测模型,在不考虑环境变量的前提下,以期提高土石坝渗流量预测的可靠性和精度。
1 土石坝渗流量预测模型
1.1 EEMD原理
在原始时间序列中多次加入足够多的不同白噪声,再将新的时间序列进行多次EMD分解得到多组本征模态函数;然后根据白噪声均值为零的特点对各组本征模态函数分量作平均,可得到EEMD分解的IMF分量I和剩余量R[17]。过程如下:
首先,把高斯白噪声M次加入原始时间序列得时间序列:
xi(t)=x(t)+ni(t) (i=1,2,…,M)
(1)
式中:x(t)为原始时间序列;xi(t)为第i次添加白噪声的时间序列;ni(t)为等长度白噪声信号。
然后,利用EMD算法分解新的时间序列,可得本征模态函数Ci,j(t)及一个剩余项ri(t):
(2)
式中:Ci,j(t)为第i次添加白噪声EMD分解所得到的第j个本征模态函数分量;ri(t)为剩余项;J为IMF分量的个数。
最后,利用互不相关的随机序列之间均值为零的特性,将M组Ci,j(t)分量及剩余项ri(t)求算术平均得到最终的IMF分量I及剩余量R(t)。
(3)
(4)
式中:Ij(t)为EEMD最终分解分量;R(t)为最终剩余量。
1.2 RVM模型原理
tn=u(yn;ω)+εn
(5)
其中ω=(ω0,ω1,…,ωn)T
式中:yn为输入向量值;tn为输出目标值;ω为权重向量;εn为零均值的高斯噪声且相互独立,方差为σ2;N为样本数;K(y,yn)为核函数。
设tn为独立分布,数据序列完整概率为
(6)
其中t=(t1,t2,…,tN)T
Φ=(φ(y1),φ(y2),…,φ(yN))
φ(yn)=(1,K(yn,y1),K(yn,y2),…,K(yn,yN))T
当训练序列中的参数增多时,σ2和ω的最大似然估计会出现过拟合现象,从而在预测过程中容易出现训练模型中的控制参数溢出现象。为避免发生上述现象,本文结合SVM原理及Bayesian先验特点,对一些参数附加约束条件[18],以降低拟合及预测过程中的误差,提高模型精度。因此对权重ω赋予一个均值为零的高斯分布:
(7)
式中:α为超参数,服从Gamma先验分布。
由Bayesian知识和先验分布p(ω,α,σ2)得后验分布ω:
(8)
其中Σ=(σ-2ΦTΦ+A)-1μ=σ-2ΣΦTt
A=diag(α0,α1,…,αN)S=N+1
式中:Σ为后验协方差;μ为后验均值。
对式(8)的ω积分,得到由α、σ2表示的边缘分布为
其中Ψ=σ2I+ΦA-1ΦT
式中:Ψ为中间变量;I为单位向量。
最大化求解超参数边缘分布,通过迭代计算α和σ2,可得优化参数:
(10)
(11)
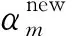
t*=μTφ(y*)
(12)
通过快速序列稀疏Bayesian算法计算超参数和噪声方差,则模型高斯核函数为[19]
K(y,yn)=exp(-g‖y-yn‖2)
(13)
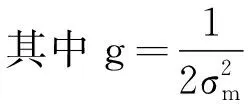
式中:σm为函数的宽度参数。
1.3 土石坝渗流量预测模型构建
在不考虑环境量的前提下,本文综合利用EEMD算法和RVM算法的优点和特性将其串联,构建基于EEMD-RVM土石坝渗流量时间序列的预测模型。首先运用EEMD模型对土石坝渗流量监测序列进行模态分解,然后通过RVM模型对分解的各分量进行拟合训练,再将预测时间t代入训练好的分量函数得到分量预测值,最后将每个分量的预测结果相加求和则可得到渗流量预测结果。该模型具体实现过程如图1所示。
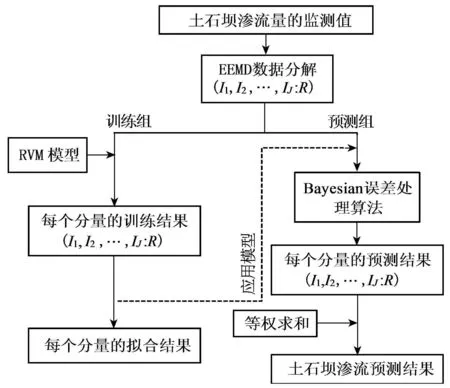
图1 基于EEMD-RVM土石坝渗流量预测模型
2 算例验证
2.1 EEMD分解渗流量时间序列
以某土石坝为例,该坝位于我国东南地区,最大坝高120.0 m,坝顶高程760.00 m,坝顶长度259.8 m,坝顶宽度9.0 m。坝址以上控制流域面积453 km2,水库校核洪水位(洪水频率0.05%)759.10 m,设计洪水位(洪水频率1%)756.20 m,正常蓄水位755.00 m,总库容2.65亿 m3,为多年调节水库。该坝渗流量采用量水堰人工测读,监测频率为一周一次,选取2015年1月7日至2017年8月31日的129个渗流量监测值作为计算训练组;选取2017年9月15日至12月29日的15个渗流量监测值为预测组。训练渗流量时间序列样本的时间作为输入值,相应的渗流量作为输出值,基于EEMD-RVM建立土石坝渗流量的预测模型。
首先对渗流量监测数据进行平稳化处理,基于EEMD算法进行分解、重组。EEMD算法分解参数有2个:高斯白噪声标准差S(一般为0.01~0.40)和添加白噪声次数M(一般为50~200)。对于平稳性较好的渗流序列,S、M均可以取小点,具体取值由序列特征决定。
取2015年1月7日至2017年8月31日的渗流量监测数据为训练组。在原始监测时间序列添加100组白噪声序列,每组高斯白噪声标准差S设为0.2进而可得I分量6个和剩余分量1个,分解结果如图2所示。
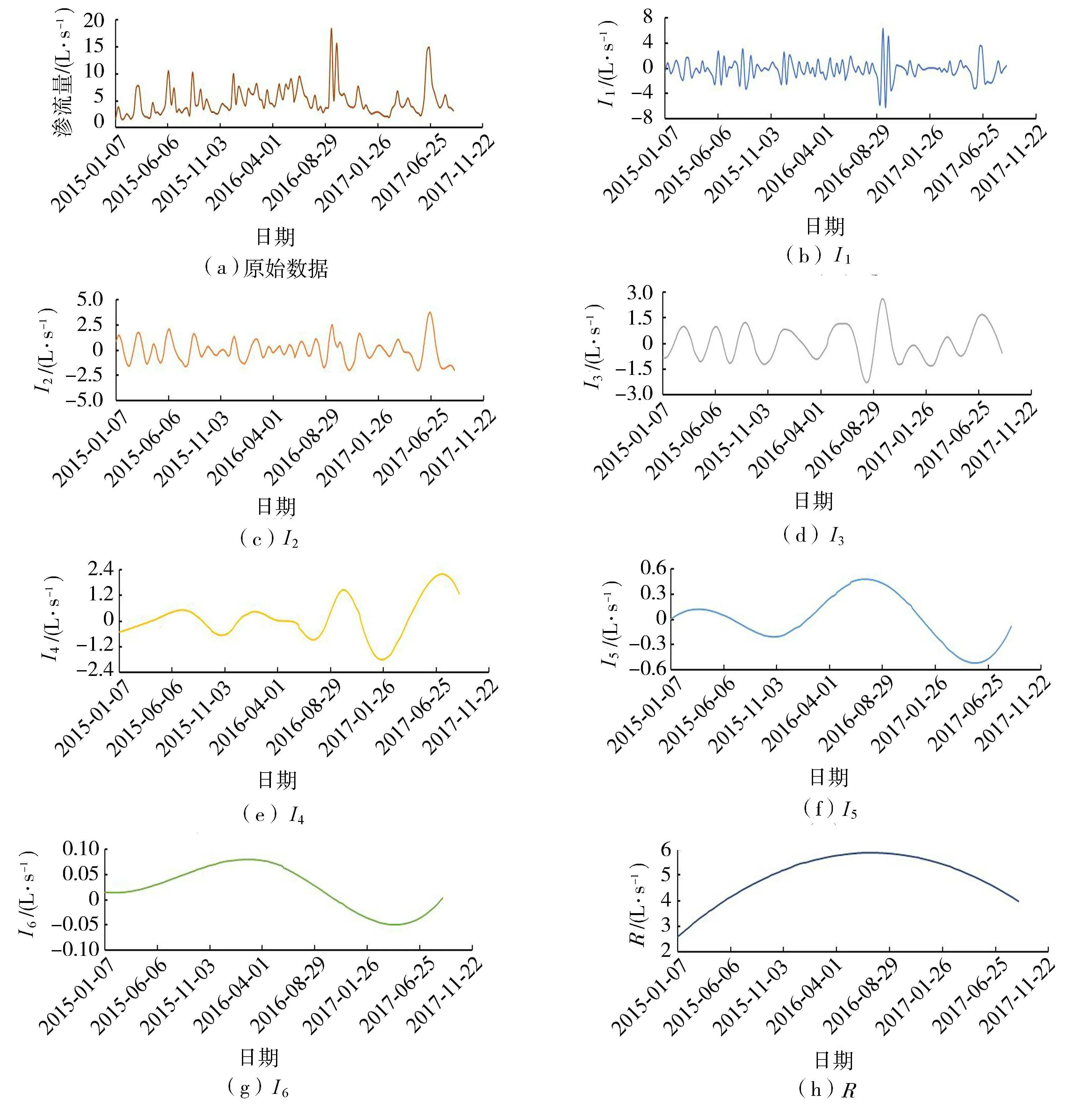
图2 EEMD分解的IMF分量及R分量结果
2.2 RVM对各分量的训练拟合
EEMD分解得到渗流量的分量后,采用RVM算法对分量进行训练拟合。RVM算法相关参数参考前人研究成果[20]取定:惯性因子取值范围0.3~0.8,核参数中g取值0.01~1.0,学习因子C1取值为1.2~2.5,学习因子C2取值为1.5~2.55,核函数的位置因子ν取值为0.01,速度因子γ取值为1.00。
通过RVM模型可拟合6个I分量及剩余分量R的函数,通过对比实测值与RVM模型拟合值得到拟合误差,进而通过快速序列稀疏Bayesian算法对拟合结果进行误差处理,然后对各个分量的拟合值求和得渗流量拟合值。该坝渗流量的拟合结果如图3所示,拟合结果的判定系数为0.98,表明该模型的拟合精度高。
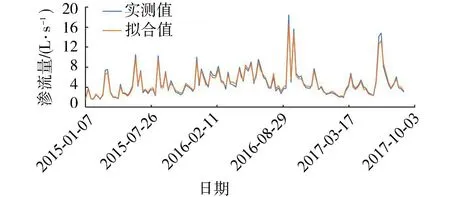
图3 EEMD-RVM模型渗流量拟合过程线
2.3 渗流量预测结果及误差分析
将预测集的2017年9月15日至12月29日的15个时间点代入已训练好的各I分量及R分量的函数求得各分量值,再把各分量的值相加得到土石坝渗流量的最终预测结果。为分析该模型的精度,给出传统的GA-BP模型以及RVM模型预测结果,各模型预测结果如图4。3种模型渗流量预测值的相应平均残差结果如图5所示,其中EEMD-RVM模型、GA-BP模型与RVM模型3种模型的预测渗流量的平均绝对值残差分别为0.222 L/s、0.674 L/s和0.653 L/s,平均相对误差分别为14.9%、49.7%和48.8%。由此说明,EEMD-RVM模型可以大幅提高渗流量预测精度,并且对突跳值更敏感,整体预测结果更好,对环境量存在缺测的中小型土石坝水库的渗流量预测提供了新方法。
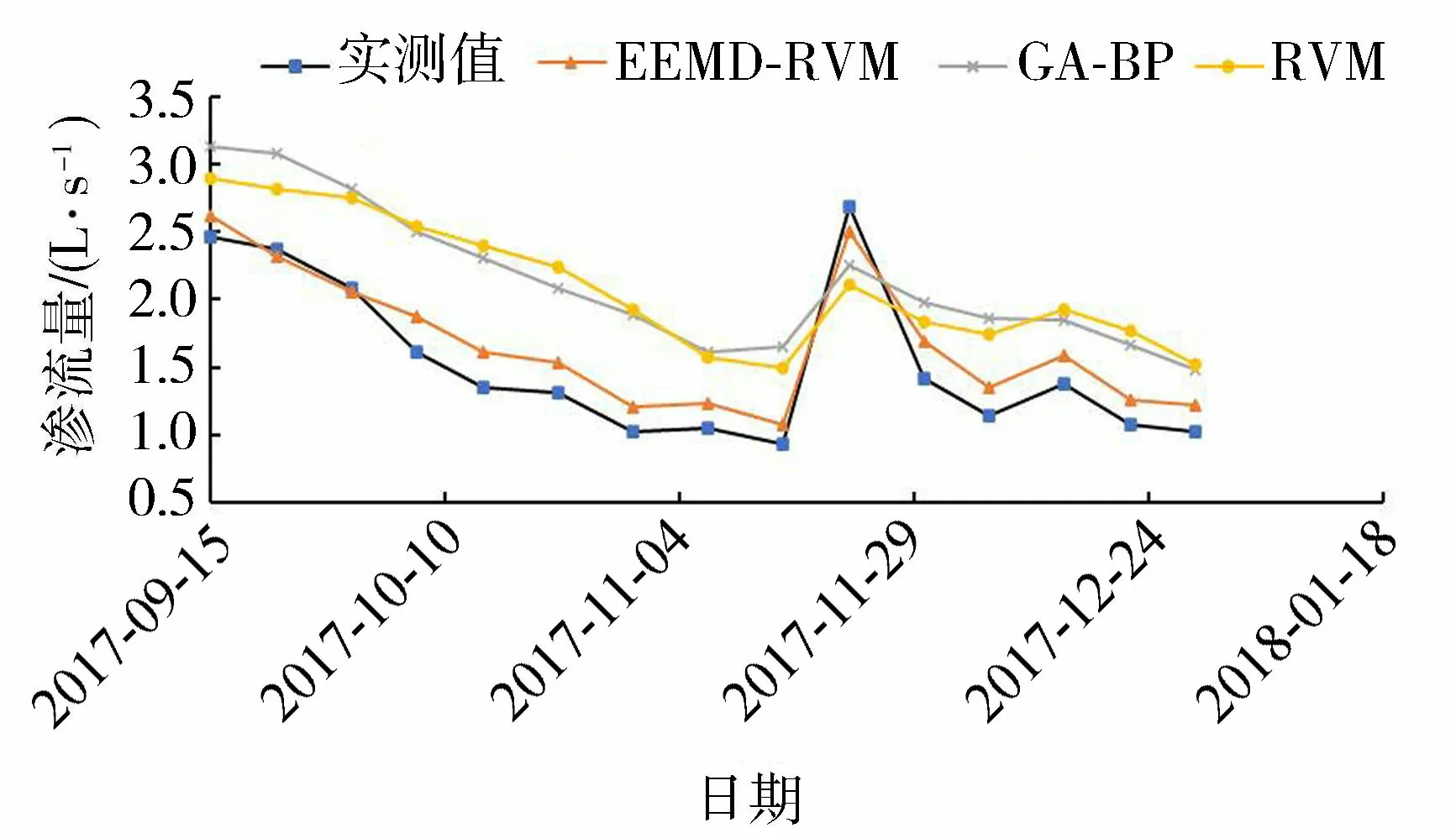
图4 3种模型渗流量预测结果对比
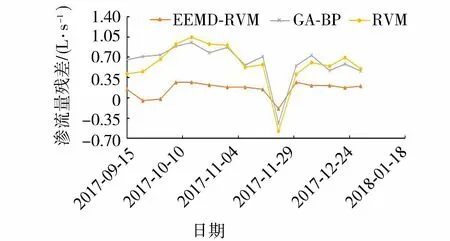
图5 3种模型预测结果残差对比
由实例计算可知EEMD-RVM渗流预测模型的精度和可靠性较高,为了增加该模型的适用性以及方便大坝管理人员的实际应用,对模型的样本数和相关预测情况进行说明。
a.一般研究大坝渗流预测问题,在训练过程中训练集有大样本和小样本2种。本文模型研究的是大样本情形。对于大样本训练,一般取一年以上,这样可以较完整地捕捉到降雨、水位等年变化因素对渗流影响的规律特性。又由于大坝的渗流特性随着运行时间的增加而渐变,所以如果训练样本过多,则不能较好地反映当前的大坝渗流情况。因此,建议本文模型的训练样本取1~2 a。对于小样本,由于渗流实测资料较少,所以一般取所有测量值为研究对象。
b.对于预测时长的确定,时长并不是越长越好,因为时长越长必然带来误差增加,以至后期误差较大的预测值不具有工程指导意义。在水工建筑物的预测研究中,一般取训练集时长的10%~20%为预测集的时长。由于渗流的不稳定性,大坝的渗流预测比其他预测,如位移、应力的预测更难。所以为了提高渗流预测的精度,建议预测时长取训练集时长的10%~15%。
c.在渗流实测过程中,不可避免会出现突跳值的情况。对于突跳值的预测,一直是研究的难题。一般突跳值有2种:突增和突减。其中渗流的突增往往对于大坝安全更不利,建议增加预测值的安全裕度以对工程管理提供可靠的支持。本文算例在预测过程中的2个突跳点(2017-11-22和2017-12-15)的预测相对误差分别为7.06%和15.21%,对于该坝建议对突跳点的预测值增加5%~15%的安全裕度。由于每座大坝的渗流情况不同,可以对过去渗流情况进行训练并比较预测值与实测值的误差,分析出突跳点的预测误差。根据预测误差情况,可以调控预测结果和提高预测值的安全裕度以方便工作人员更好地管理和决策。
3 结 论
a.EEMD算法将渗流量时间序列分解处理为平稳子序列,可以有效地提高非平稳渗流监测数据的分析精度。
b.EEMD-RVM模型与RVM模型及GA-BP模型的结果对比可知:常规模型对渗流量时间序列的预测误差较大,EEMD-RVM模型较大幅度地提高了预测精度,表明该模型在土石坝渗流量时间序列中具有较高的可靠性。
c.通过实例和验证结果可得,EEMD-RVM模型在工程应用上可行,操作性较高,精度满足要求。对于环境量监测缺失较为严重的中小型土石坝,特别是中小型病险坝,该模型可以快速进行渗流量预测研究,为提高中小型土石坝的渗流安全提供了新的途径和方法。
猜你喜欢
商品与质量(2021年43期)2022-01-18
建材发展导向(2021年19期)2021-12-06
建材发展导向(2021年11期)2021-07-28
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
水电站设计(2020年4期)2020-07-16
水利规划与设计(2020年1期)2020-05-25
中华建设(2019年4期)2019-07-10
百科知识(2018年6期)2018-04-03
少儿科学周刊·少年版(2016年4期)2017-02-15
山东工业技术(2014年21期)2014-01-15
