
面向舆情监测的话题追踪方法*
2021-09-15 08:34陈黎明黄瑞章秦永彬陈艳平刘丽娟
计算机与数字工程 2021年8期
陈黎明 黄瑞章 秦永彬 陈艳平 刘丽娟
(1.贵州大学计算机科学与技术学院 贵阳 550025)(2.贵州省公共大数据重点实验室 贵阳 550025)(3.贵州师范学院 贵阳 550018)
1 引言
如今各大新闻网站会对各种各样的事件进行报道,这些大量的新闻报道中既存在着正能量的有利信息,也可能隐藏着负面或者敏感的信息。一条普通新闻一旦被关注可在极短的时间传播开来,往往会从普通事件演变成爆点事件,继而引发政府公信力下降等问题。因此,舆情监管部门对新闻报道高度重视,要求加强监测力度,密切关注事态发展。
话题检测与跟踪(Topic Detection and Tracking,TDT)[1]是一种面向新闻信息流的处理技术,旨在自动识别新话题和持续跟踪已知话题,其中话题由一个种子事件以及与其直接相关的事件组成。话题追踪作为TDT子任务,其目的是依据给定的新闻集合或描述在后续辨认出话题相关报道,能够用于快速获取话题信息,协助有关部门进行舆情监测和分析。
舆情监测的对象为热点或敏感话题,需要人为介入的机制,因此更倾向于使用一组关键词来进行话题追踪,方便在追踪过程中进行调整。根据关键词来进行特定话题追踪,有以下难点:1)舆情新闻数据容易遗漏。使用关键词进行简单匹配会引入大量无关数据,所以需要衡量词语在文章中的重要性,常用来衡量词语重要性的方法难以处理词语出现频率较低的情况,这会导致当新闻中与话题相关的信息出现频率较低时难以追踪到此类新闻数据。2)用户给定的关键词可能不全,不足以全面描述话题,造成追踪结果不理想。3)随着时间的变化,话题重心也在变化,会产生话题漂移现象,话题关键词也随之变化,初始给定的关键词需要动态更新。
为了解决上述问题,本文提出了一种面向舆情监测的话题追踪方法,根据用户给出的关键词监督信息进行话题追踪,充分考虑人为介入的应用场景;针对舆情新闻数据容易遗漏的问题,本文通过对话题关键词进行加权的TextRank算法来提取有倾向的关键词作为文本特征表示,进而提升追踪效果;针对关键词不完全的问题,对舆情数据进行分析,通过点互信息对话题关键词进行补全;针对话题漂移的现象,在话题追踪过程中根据关键词衰减指数[2]对话题关键词进行动态调整。实验结果表明,本文方法在面向舆情监测的话题追踪任务上取得了较好的效果。
2 相关工作
话题追踪是在后续新闻报道中辨认出已知话题所相关的新闻报道[3],可以为新闻事件的追踪及判断决策提供辅助支持[4]。针对话题追踪的研究集中在分类或聚类算法的选择与融合、自适应话题追踪几个方面。
基于分类的追踪方法利用训练好的分类器来进行话题相关性分析。文献[5]使用SVM算法训练了一个是否相关的分类器,避免了需要类型标签的问题。文献[6]在改进型DF文本特征的基础上,通过构建朴素贝叶斯模型来实现话题追踪。文献[7]提出了一种基于改进KNN的话题跟踪算法,解决了由于数据不平衡和跟踪代价较高的问题。虽然分类算法使用广泛,但需要大量训练数据。此外随着时间的发展,话题的重心在动态变化,会产生话题漂移的现象,简单的分类算法已经不能满足动态话题追踪需求。
基于聚类的追踪方法常见的是SinglePass算法以及K-means算法。文献[8~10]使用了改进的SinglePass算法来进行话题追踪,其主要研究在于选取不同的文本特征来提升聚类效果。虽然这类算法效率较高,但容易受输入顺序的影响。文献[11]提出了一种改进的K-means算法,基于新闻报道相似性选择初始聚类中心点,保证各新闻话题集群具有很好的区分度。文献[12]根据K-means聚类结果对子话题向量集进行动态调整,能够更精确地对话题继续追踪。但K-means算法又具有其局限性,如对初始中心点的选择敏感和用户必须自定义分组K等。
由于话题漂移现象的存在,自适应话题追踪得到了进一步发展。此类算法在话题追踪时将新特征融入至初始模型并对特征项权重进行实时修正,进而改进追踪效果。文献[13]提出了一种基于词汇相关性的自适应追踪方法。文献[14]利用最小特征平均可信度阈值更新策略来完善话题模型。文献[15]基于时间的分布属性调整特征向量权重分配,实现话题模型的自适应学习更新。文献[16]根据报道时间特点研究了动态阈值话题追踪方法。文献[17]提出一种基于关联语义网络的话题追踪方法,解决了无法详细描述话题追踪趋势的问题。文献[18]利用了主题新颖性和消退概率来追踪话题。
相比于上述方法,本文方法基于关键词对特定话题进行追踪,更适用于舆情监测的应用场景。
3 方法介绍
3.1 方法概述
本文方法流程如图1所示。待追踪新闻由新闻标题和正文组成,话题表示为一组关键词,人为给定的关键词监督信息作为其初始值,用户可以在追踪的过程中进行介入,修改话题关键词。在每批待追踪舆情新闻数据到来时,追踪流程按以下步骤进行处理。首先,通过对话题关键词进行加权的TextRank算法提取新闻关键词。其次,通过点互信息对话题关键词进行补全。最后,计算每篇新闻文本和话题的关键词相似度,相似度大于阈值的新闻文本被判定为与话题相关,并对话题关键词进行反馈更新。接下来,将对这些步骤做详细介绍。
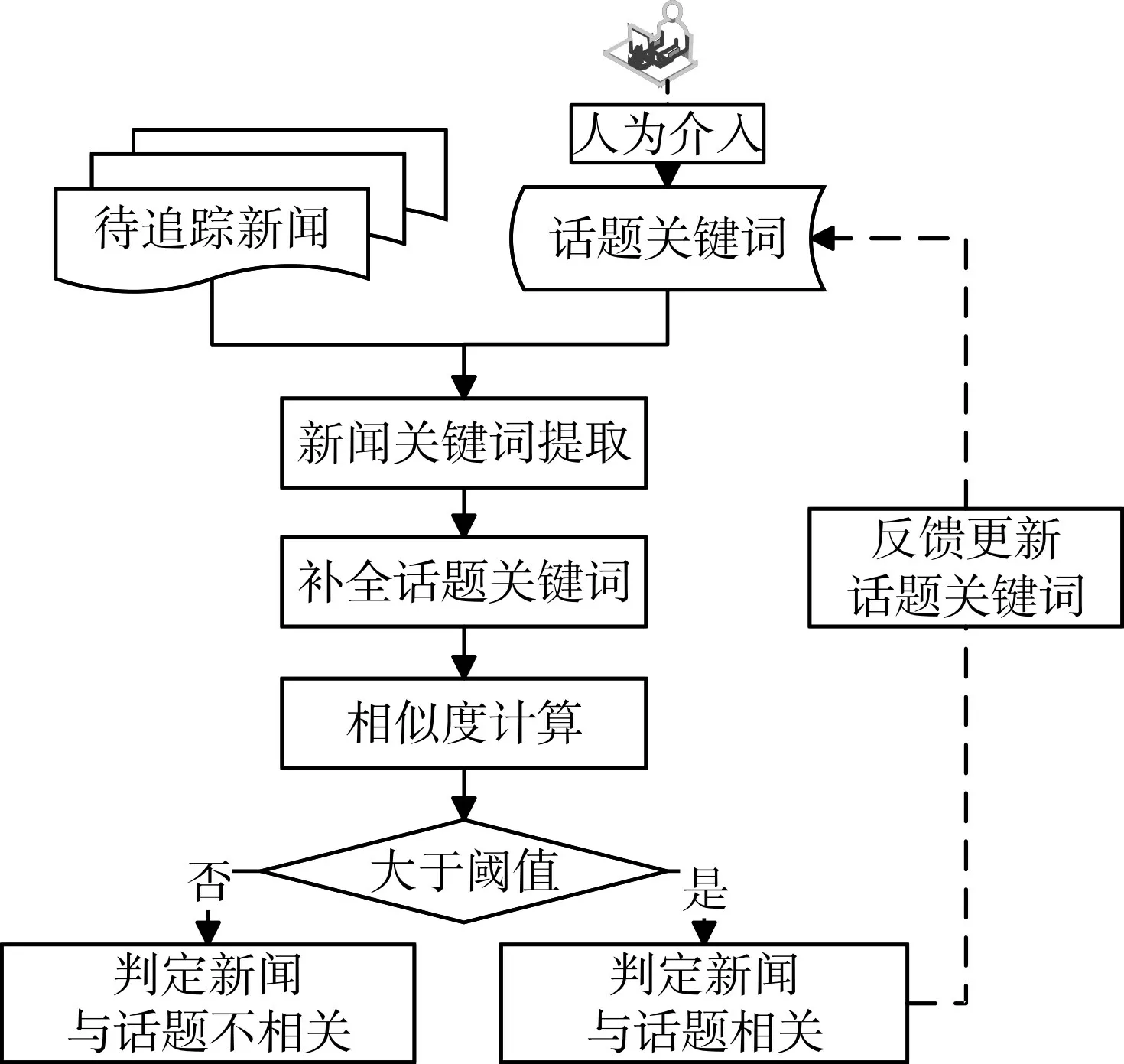
图1 话题追踪方法流程
3.2 新闻关键词提取
目前最常见的关键词抽取算法为TextRank[19],它是一种基于词汇图模型的算法,把文档看作是由词汇构成的图结构,依靠文档自身的结构关系,即可实现关键词抽取,简单有效,但传统TextRank算法忽略了词语本身的重要性信息[20]。当在追踪某个的特定话题时,仅关心特定的一些词语,这些词的重要程度比其他词语高,比如话题关键词。因此,本文对传统TextRank算法进行了改进,对话题关键词加权,提高话题关键词在新闻中出现时被作为新闻文本关键词提取出来的概率。
设G(V,E)是由给定文本的词汇构成的一个图结构,那么对于该文本中任何一个词语Vi,其基于加权TextRank算法的权值迭代公式为
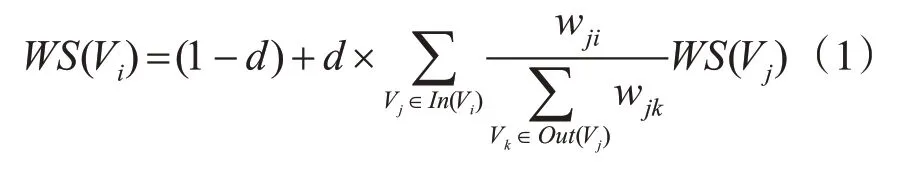
式(1)中d为调节系数,一般取0.85;I n(Vi)表示指向节点Vi的所有节点的集合;Out(Vj)表示节点Vj指向的所有节点的集合。wji为节点Vj的词语重要性影响力传递到节点Vi的权重,其计算公式如下:
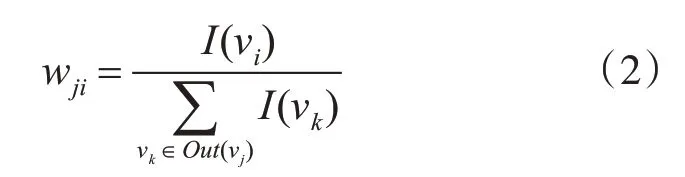
式(2)中I(vi)表示节点Vi的重要性取值,设λ为对词语进行加权的参数,本文中λ取2,则I(vi)赋值如下:

基于式(1)~(4)进行迭代运算,当式(1)两次迭代结果之间的差异非常小时停止迭代运算,该值一般取0.0001。然后按照大小对WS(V)进行降序排序,选取前8个候选词作为新闻文本关键词。
3.3 相似度计算和话题追踪
Jaccard相似度用来比较样本集之间的相似性,Jaccard系数值越大,说明相似度越高。设KT为话题关键词集合,K N为新闻文本关键词集合,则Jaccard系数计算如式(5)所示。
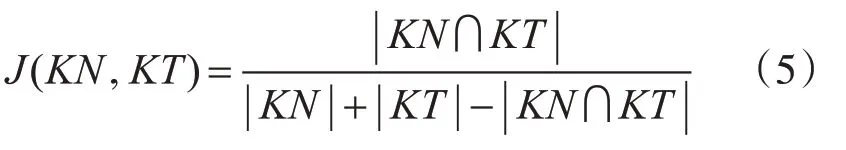
通过式(5)计算追踪话题和新闻文本之间的相似度,相似度大于阈值α的新闻文本被判定为与话题相关,相似度低于阈值的则判定为与话题不相关。
3.4 话题关键词更新
为了充分补全话题关键词,采用点互信息PMI(Pointwise Mutual Information)来挖掘潜在的关键词。PMI被用来衡量两个关键词之间的关系,PMI的大小代表了它们关系的强弱。PMI的计算公式如下:

通过式(6)计算出新闻文本关键词对的PMI,挑选出PMI大于阈值μ的关键词对。如果一个关键词和任意两个话题关键词的PMI大于阈值,则添加该关键词到话题关键词集中,对话题关键词进行补全。
此外,针对话题漂移现象,需要融入新的话题特征,对话题关键词进行更新。当一篇新闻被判定为与话题相关时,采用基于关键词衰减指数的算法来对话题关键词进行动态更新,详细描述如算法1所示。设话题候选关键词向量为V(K)=(K1:w1,K2:w2,…,Kn:wn),其中K表示话题候选关键词,w表示候选关键词权重。第一次进行更新时,V(K)用话题关键词进行初始化,w的初始值为2。
算法1话题关键词更新算法
输入:
话题候选关键词向量V(K)
新闻文本关键词集合K N
衰减指数θ
输出:
更新后的话题关键词集合K Tupdated
更新后的话题候选关键词向量Vupdated(K)
1)for每个关键词Ki∈KNdo
2) ifKi i n V(K)then
3)wi←wi+0.5
4) else在V(K)中添加(Ki,0.5)
5)for每个关键词Kj i n V(K)do
6) ifKj∉KNthen
7)wj←wj*θ
8)输出Vupdated(K)
9)Vupdated(K)按权重w大小进行排序
10)初始化KTupdated为空
11)forKm i n Vupdated(K)do
12) 在KTupdated中添加Km
13) ifKTupdated的关键词个数>8 then
14) break
15)输出KTupdated
4 实验及分析
4.1 实验数据及评价标准
为了验证所提方法的有效性,本文从新浪、凤凰、搜狐、网易等新闻网站收集了2018年11月~2019年1月共28125篇新闻作为实验原始数据。从原始数据中选取五个话题进行追踪,并对其进行标注,除五个话题外,其它数据均为反例。话题名称和对应的新闻数量如表1所示。

表1 数据集
实验使用准确率P、召回率R和两者综合性能指标F值三个指标进行量化考察,F值越高,话题追踪性能越好。设TP为在追踪结果中被判定属于某话题且实际也属于该话题的新闻数量,FP为在追踪结果中被判定属于某话题但实际不属于该话题的新闻数量,FN为在追踪结果中被判定为其它类别但实际属于该话题的新闻数量。则准确率P、召回率R和F值的计算公式如下:

4.2 话题追踪对比实验
为了验证本文方法在话题追踪上的效果,选取基于SinglePass的追踪方法和文献[2]方法作为对比方法。实验设置相似度阈值α为0.1,衰减指数θ为0.8,时间窗口为天,并选取两篇种子新闻作为对比方法的初始类心,其中基于SinglePass的追踪方法选取的文本特征表示方法是TF-IDF。实验结果如表2所示。
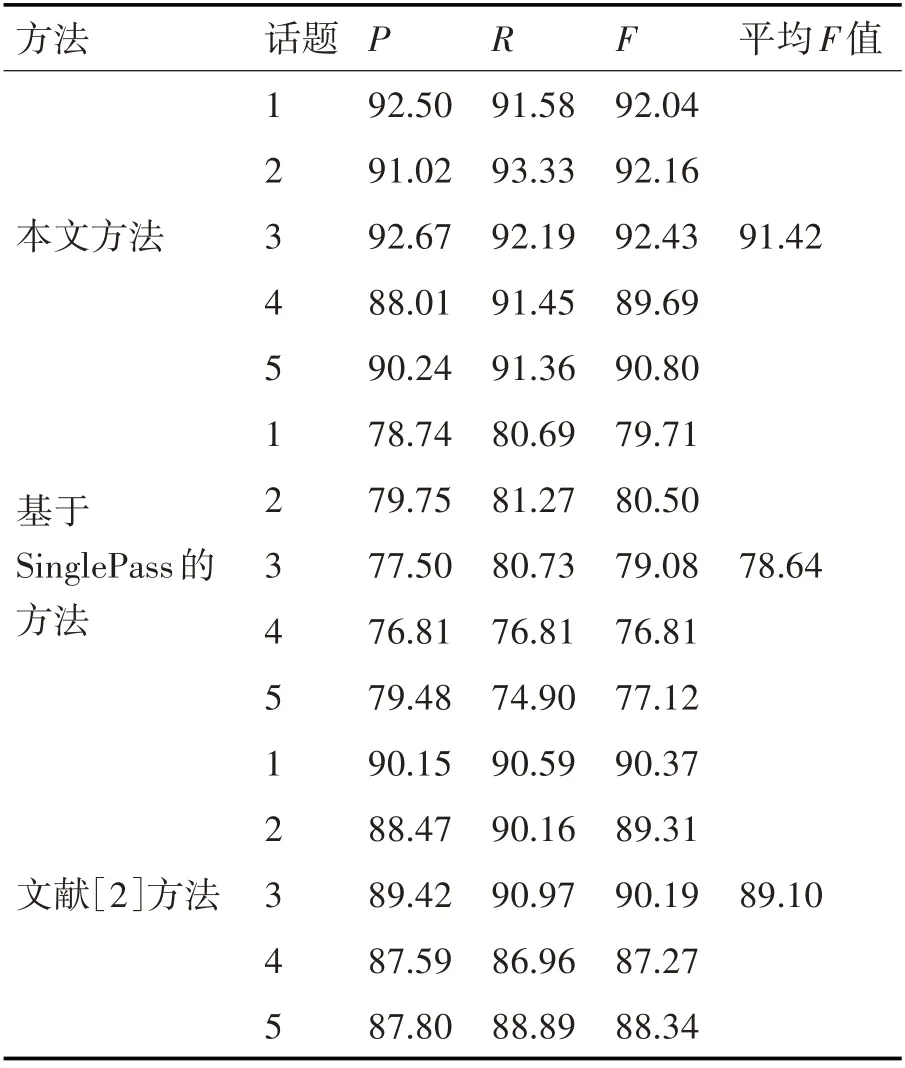
表2 话题追踪方法实验结果
从表2可以看出,本文方法优于基于Single-Pass的追踪方法,原因是选取了有倾向的关键词作为新闻文本特征表示,而基于SinglePass的方法选取的文本特征表示方法是TF-IDF,当新闻中关键词出现频率比较低时,其所占权重较小,导致聚类效果不理想,而有倾向的关键词加大了重要词的权重,能够提取出关键词出现频率低的新闻。此外,本文方法和文献[2]方法都有反馈更新话题关键词的机制,然而本文方法在平均F值上比其高出2.32%,主要是因为本文利用PMI对话题关键词进行了补全以及引入了话题关键词候选向量,在反馈更新策略上做了改进,从而取得了较为优越的结果。
4.3 话题关键词分析
本文基于关键词对舆情话题进行动态追踪,关键词的变化影响着话题自适应追踪的效果。表3展示了本文方法在追踪“孟晚舟被捕”话题过程中关键词的变化。从表中可以看出,话题发生了漂移现象,重心从“被捕”发展成为了“保释”,这表明本文方法能够有效地应对话题漂移现象,对话题进行自适应追踪。

表3“孟晚舟被捕”关键词变化
5 结语
本文提出了一种面向舆情监测的话题追踪方法,根据给出的关键词信息来进行特定的话题追踪,充分考虑到了舆情监测需要人为介入的应用场景,解决了舆情新闻容易遗漏、关键词不完整、话题漂移的难点,取得了较好的追踪效果。在未来的工作中,拟研究如何根据追踪到的新闻数据梳理话题发展脉络。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
北京化工大学学报(自然科学版)(2022年1期)2022-03-13
建材发展导向(2021年19期)2021-12-06
速读·下旬(2021年11期)2021-10-12
现代计算机(2021年10期)2021-05-28
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
消费电子(2016年12期)2017-01-19
网络传播(2014年12期)2015-03-16
