
基于微博平台的用户评论数据采集
2021-09-16 19:28黄红桃江盈锋
科技创新导报 2021年14期
黄红桃 江盈锋

摘 要:微博的热点事件会产生大量评论数据,这些数据是进行舆情分析和网络水军识别等数据挖掘的基础。论文分析对比常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口两种方法,采集新浪微博热点事件下的用户评论数据。一般网络爬虫技术多使用广度搜索,这里采用深度搜索,能够更精确地获得某个热点事件下的用户评论数据。
关键词:数据挖掘 微博 用户评论 网络爬虫 Selenium Json
中图分类号:TP393.09;TP274.2 文献标识码:A文章编号:1674-098X(2021)05(b)-0132-05
Data Collection of User Comments Based on MicroBlog Platform
HUANG Hongtao JIANG Yingfeng
(School of Information, Guangdong University of Foreign Studies, Guangzhou, Guangdong Province, 510006 China)
Abstract: Hot events on MicroBlog will generate a large amount of comment data, which is the basis for data mining such as public opinion analysis and online water army identification. The paper analyzes and compares commonly used web crawler technologies and frameworks, using Selenium framework and Json data interface respectively to collect user comment data under hot events on Sina MicroBlog. Generally, web crawling technology uses breadth search, and deep search is adopted here to obtain user comment data under a hot event more accurately.
Key Words: Data mining; MicroBlog; User comments; Web crawler; Selenium; Json
根據2021年2月发布的第47次《中国互联网络发展状况统计报告》,截至2020年12月,我国网民规模达9.89亿,较2020年3月增长8540万,互联网普及率达70.4%,较2020年3月提升5.9个百分点。截至2020年12月,我国手机网民规模达9.86亿,较2020年3月增长8885万,网民使用手机上网的比例达99.7%,较2020年3月提升0.4个百分点。数据表明我国的网民基数很大,并且网民使用手机上网的比例非常高。这就使得网民进入网络的社区交流平台(如微博、知乎)进行交流的门槛变低,机会变多。很多的网民包括不少网络水军在热点事件中参与了评论,使得这些事件产生大量数据。
新浪微博是国内的用户量极大、活跃度也很高的网络社交平台。一次热点事件常常会有数以万计、十万计甚至百万以上的评论数据。这些数据是进行舆情分析,网络水军识别等数据挖掘的基础。
论文研究相关的网络爬虫技术,并以此来对用户评论数据进行批量、自动化地采集。
1 相关技术
1.1 爬虫技术的类别
爬虫技术具有如下的一些分类。
1.1.1 通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler)[1],爬行对象从一些种子URL扩充到整个 Web,主要为门户站点搜索引擎和大型Web服务提供商采集数据。由通用网络爬虫的结构大致可以分为页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL队列初始URL集合几个部分。通用式爬虫多用于广度搜索优先策略。
1.1.2 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler)[2],是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。聚焦网络爬虫和通用网络爬虫相比,增加了链接评价模块及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
1.1.3 增量式爬虫
增量式网络爬虫指的是对已经爬取过的网页不再进行爬取,只爬取新产生的网页,即增量式更新。与其他类型的网络爬虫相比,只关注新增的数据,网页的下载量大大减少,降低了爬虫的存储空间与网络带宽的消耗,但是增加量抓取算法的复杂度和实现的难度[3]。
1.1.4 Deep Web爬虫
从网页在网站上呈现的不同的位置结构的角度来分析,可简单将网页分为浅层态网页与深层态网页。深层态网页是指那些不能被通用搜索引擎所搜录的存储在web数据库中的态网页,其通常需要一定条件才能获取(如登录)。相对深层态网页而言,浅层态网页是指web上被搜索引擎搜录的浅层态网页。Deep Web往往具有较强的主题性,各Deep Web主题领域中蕴含的数信息专业性更强,内容更加丰富[4]。
1.2 常见的爬虫框架
1.2.1 Selenium
Selenium是一个可操纵浏览器实行自动化测试的框架。可以通过简单的指令控制浏览器自动化运行,如同真实用户在操作一般,比如输入验证码。Selenium是自动化测试工具,支持各种浏览器,包括 Chrome、Safari、Firefox等主流界面式浏览器。因此可用来爬取任何网页上看到的任何数据信息,且几乎可以避开绝大部分反爬虫监控[5]。
1.2.2 Json 接口
Json(JavaScript Object Notation,JS对象标记)是一种轻量级的数据交换格式。它使用不同于编程语言的特殊的文本格式来进行保存数据和传递数据的操作。简洁明了、清晰易懂的层次结构使得Json成为理想的数据交换语言。更容易人们读取和编写、机器解析和生成,并有效地提升网络传输效率。Json文本格式具有兼容性非常高、有相似于C语言体系的习性行为、独立于其他编程语言等特点。这些特性使Json成为理想的数据交换语言[6],并用于提供json数据接口的网页进行数据采集。
1.2.3 Scrapy
Scrapy是一个通过Python实现的爬虫框架,架构清晰,模块之间的耦合程度相对较低,而且可扩展性也比较强,能够灵活完成各种需求,具有使用简单、代码量小、可维护性好等特点[7]。Scrapy框架不仅能够通过抓取网页来获取数据,还可以通过访问API接口获取其他对应的数据,实现对web资源多层次、快速的抓取,被应用于各类网站的抓取工作,提取其中有价值的结构数据[8]。
2 数据采集
本次数据采集基于网络社交平台——新浪微博,采集的具体评论数据是https://weibo.com/1792951112/K3S5HcgZi?filter=hot&root_comment_id=0&type=comment#_rnd1619007657759 博文下的用戶评论。通过该博文的评论数目可以看出该博文下的评论数据非常多,已经达到了百万级别的评论数据。接下来会采用爬虫将其数据捕获下来,并做一些分析。
根据采集的数据特性,以下选用增量式爬虫和Deep Web爬虫技术、selenium框架和json数据接口,分别对该微博评论数据进行采集。
2.1 使用Selenium框架采集数据
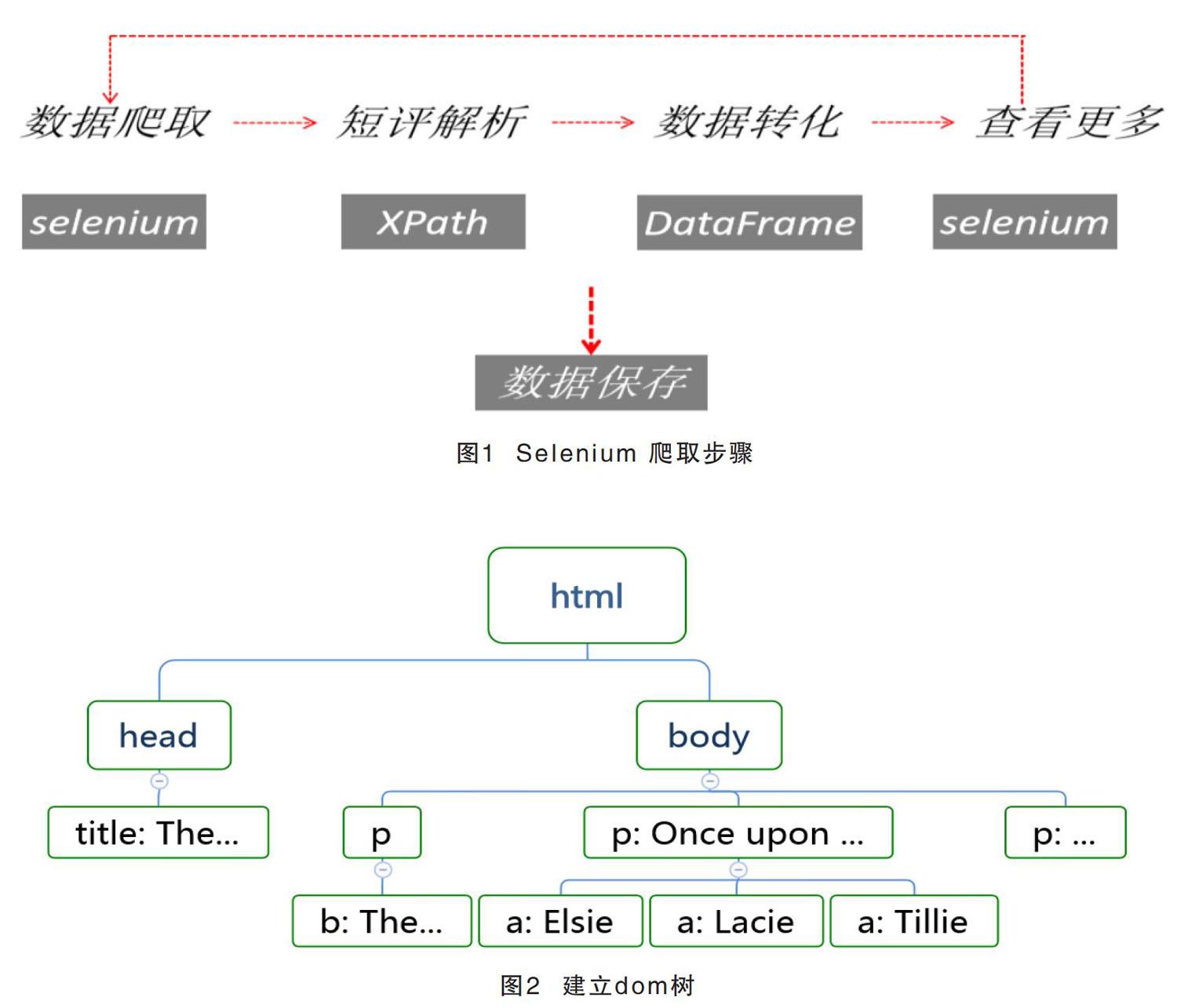
Selenium爬取评论的基本步骤如图1所示。
首先要获取其网页源代码(在网站上按F12查看),然后根据其源码构造dom树如图2所示。
接下来就可以运用XPath解析dom树,并根据相关的结点进行数据爬取,部分代码如下所示。
user_data = requests.get(i)
dom_url = etree.HTML(user_data.text,etree.HTMLParser(encoding='utf-8'))
follow = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][1]/text()')
fan = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][2]/text()')
boke = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][3]/text()')
数据爬取完成之后可以选择保存在xml、csv、txt等文本文件,这里选择保存在csv文件中。
2.2 采用Json数据接口采集数据
与Selenium不同,Json数据接口可以相对直接获取数据,因为其数据的组成结构是Json的格式,不过需要找到数据的接口。
因为微博的网页版是不提供数据接口且反爬机制较先进,所以这里选用手机端的微博,手机端的微博的用户评论是瀑布流式刷新的并且提供了Json的数据接口,例如其中一个接口:https://m.weibo.cn/comments/hotflow?id=4609229132925240&mid=4609229132925240&max_id_type=0, 其结构如下所示。
{ok: 1, data: {data: [,…], total_number: "100万+",…}}
data: {data: [,…], total_number: "100万+",…}
data: [,…]
0: {created_at: "Sat Feb 27 15:09:20 +0800 2021", id: "4609230964787737", rootid: "4609230964787737",…}
1: {created_at: "Sat Feb 27 15:04:59 +0800 2021", id: "4609229871121970", rootid: "4609229871121970",…}
…..
18: {created_at: "Sat Feb 27 15:05:08 +0800 2021", id: "4609229908872568", rootid: "4609229908872568",…}
max: 50000
max_id: 45846235480040570
max_id_type: 0
status: {comment_manage_info: {comment_permission_type: -1, approval_comment_type: 0}}
total_number: "100万+"
ok: 1
在此结构下获取其用户评论较为直接,不过一个Json数据接口通常只能提供10×19条用户评论,所以需要重新获取下一个接口。由于手机端的微博是瀑布流式刷新用户评论的,所以可以直接控制页面往下拉刷新就可获取下一个Json数据接口。观察其数据接口链接可得知链接之中只有max_id和max_id_type會发生变化,因此通过多个Json数据链接可得出规律,下一个链接的max_id是上一个链接的Json字典里的max_id(json结构的倒数第六行),而max_id_type是在0和1两个值之间取值。这个先用0判断一下Json返回值的ok是否为1就可以判断,若是max_id_type就取0,否则取1,部分代码实现如下所示。
while (i < count):
while_starttime = datetime.datetime.now()
try:
if i == 0:
r = requests.get(one, headers=headers)
else:
b = '&max_id_type=0'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
flag = r.json()
flag1 = r.json()['ok']
if flag1 == 0:
b = '&max_id_type=1'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
js = r.json()
users = js['data']['data']
接下来就是对Json数据进行分解获取,得到的数据同样可以保存为xml表格、csv文件、txt文本文件等。
2.3 采集结果
两种方法爬取的结果,都包含用户id(用户的唯一标识)、用户名、评论时间、评论内容、评论获赞数等,本次爬取共获取了6000多条数据,可以为接下来的用户评论的数据挖掘提供较大的数据量,结果如图3所示。
3 结语
本文使用两种方法,均采用深度优先的搜索,获取微博用户评论数据。Selenium框架是先对网页源代码进行解析,生成dom树,再通过dom树来获取其中的用户评论数据。Json数据接口则是通过对Json数据结构的解析,直接获取微博用户的评论数据。实验中,使用两种方法对微博某一热点事件下用户评论数据的采集,都取得不错的结果。
两种数据采集方法各有优缺点。Selenium可以模拟真实人的行为进行抓取数据,基本不受网页的限制,但前期过程会较为繁琐且爬取的效率不太高。Json数据接口直接简单,但获取数据需要详细的寻找出隐藏的接口位置,有时还需要寻找下一个接口并总结其链接规律,还有就是部分网站不提供数据接口。在实际操作可以根据具体需求,结合这两种技术的优缺点来选取其中一种方法。
参考文献
[1] 曾健荣,张仰森,郑佳,等.面向多数据源的网络爬虫实现技术及应用[J].计算机科学,2019,46(5):304-309.
[2] Guo S, Bian W, Liu Y, et al. Research on the application of SVM-based focused crawler for space intelligence collection[J]. Electronic Design Engineering,2016,24(17):28-34
[3] 叶婷.基于关键词的微博爬虫系统的设计与实现[D].杭州:浙江工 业大学,2016.
[4] 杨晓夫.汽车票务DeepWeb数据采集关键技术研究[D].重庆:重庆交通大学,2016.
[5] 吕博庆.基于爬虫与数据挖掘的电商页面信息分析[D].兰州:兰州大学,2018.
[6] 陈哲.基于微博热点事件的可视化系统的开发与实现[D].北京:首都经济贸易大学,2018.
[7] 孙瑜.基于Scrapy框架的网络爬虫系统的设计与实现[D].北京:北京交通大学,2019.
[8] 崔新宇.基于情感分析的商品评价系统设计与实现[D].邯郸:河北工程大学,2020.
猜你喜欢
教育传媒研究(2023年6期)2023-11-23
电力与能源(2017年6期)2017-05-14
中国新通信(2016年21期)2017-01-06
人间(2016年26期)2016-11-03
人民论坛(2016年27期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
