
基于Hadoop技术的并行计算模式定向数据挖掘方法
2021-09-22 06:13叶苗张国华
电子技术与软件工程 2021年15期
叶苗 张国华
(南京师范大学泰州学院 江苏省泰州市 225300)
信息技术迅猛发展,互联网数据呈指数倍增长态势,传统计算机体系架构已难以有效处理当前的大规模数据。因此,云计算技术应运而生,为海量数据挖掘领域提供良好契机[1]。随着网络技术日新月异的发展,许多传统的数据挖掘策略已不再适用于不断更新换代的数据类型与应用环境,其已对挖掘精度与实时性提出了更高的要求。因此,研究一种更理想的海量数据挖掘方法具有重要的现实意义。
为满足当前数据挖掘技术的应用需求,本文利用Hadoop技术与并行计算模式,设计出一种定向数据挖掘方法。其中,Hadoop平台具有管理存储在多台计算机上数据分块的能力,凭借优秀的运算能力、存储能力、调度能力,在数据挖掘[2]方向被广泛应用;设计校验修正公式与控制允许误差范围的容忍度阈值,提升校验公式两边数值相等概率,确保挖掘结果的可靠性,校验节点存储容量与性能值的一致性;通过MapReduce计算模式下朴素贝叶斯分类算法,提升定向数据挖掘精度与效率。
1 Hadoop技术下并行计算模式定向数据挖掘
1.1 基于云计算平台实现HDFS分布式文件系统存储
1.1.1 HDFS分布式文件系统
将分布式文件系统引入云计算平台中,管理存储在多台计算机上的数据分块,该系统以Hadoop分布式为基础,主要组成部分是一个主数据节点与多个从数据节点。前者将元数据服务给予分布式文件系统内部,掌控全部文件;后者则用于备份、存储若干个切分存储文件得来的数据块。系统客户端决定着新建文件过程中的数据块大小与备份数量。利用标准的TCP/IP[3]协议完成HDFS(Hadoop Distributed File System)分布式文件系统内部各节点间通信。该系统体系框架如图1所示。

图1:HDFS结构示意图
1.1.2 数据存储
大规模数据存储主要通过分布式文件系统中的数据节点实现。为此,评估Hadoop集群内节点性能,根据得到的节点性能值,选取存储数据块的合适节点,按比例在各节点存储一定数量的数据块[4]。具体过程描述如下:
(1)节点性能评估:假设i表示任意服务器节点,处理器性能值、内存性能值以及磁盘I/O性能值分别是Ci、Mi与Di,则该节点对应性能值Pi表达式如下所示:

式中,各指标对服务器性能不同权值影响的参数是α、β、γ,且满足下列等式:

为确保挖掘结果的可靠性,校验修正各节点性能值的测量结果。假设有N个节点,其中,节点i完成的任务个数为Si,Hadoop集群里各任务数据具有相同规格,所以,节点i在固定时段中处理的数据量也可以用Si表示,则推导出下列校验公式:

若Hadoop集群中的任意两节点均满足该校验公式,说明基于当前Hadoop应用场景,测得的节点性能值具有有效性。设定一个控制允许误差范围的容忍度阈值p,令校验公式两边数值等率更高,则改写校验公式为下列表达式,将其作为实际应用中测量结果校验标准:
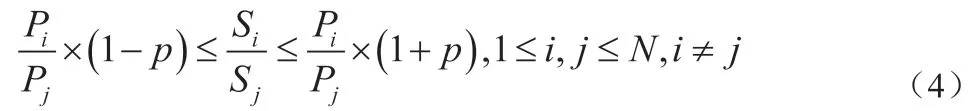
其中,节点i任务数量Si与主数据节点总任务数SA关系如下所示:

(2)存储节点选取:根据各节点数据处理能力,在分布式文件系统中完成大规模数据文件存储,利用节点存储容量校验策略,选取有效存储节点,校验节点存储容量与性能值的一致性。
假设U1,U2,...,UN是各节点存储集群的数据量规格,P1,P2,...,PN是相应节点性能值,UA表示集群存储数据量规格,则任意节点i存储集群的数据量规格Ui应使下列不等式成立:

式(6)的作用是校验数据量存储规格与节点i性能值的匹配程度。其中,节点i存储集群的数据量规格Ui与集群存储数据量规格UA关系如下所示:

1.2 基于HDFS平台构建HBASE分布式数据库
以分布式文件系统作为运行基础,构建HBASE分布式数据库,为大量数据提供任意、实时的读写访问服务,提升数据可靠性与系统鲁棒性。该数据库通过学习使文件系统中大表数据库的所有功能得以实现,完成大规模数据的存储与处理。
1.3 基于Hadoop技术设计MapReduce并行计算模式
1.3.1 并行分布式计算
由Map映射功能与Reduce归约功能组成的MapReduce并行分布式计算模式,是一种具有处理大量数据能力的并行分布式编程模式。用户利用界定的Map函数,处理key/value(即键/值对)与取得的中间结果,经Reduce函数结合所有拥有相同key值[5]中间结果的value值。Map函数的作用是分块处理输入数据,将数据块划分至不同节点加以并行运行;Reduce函数功能是归约中间生成key值的value值,并依据某分块函数,分类中间生成的key值。
1.3.2 MapReduce计算模式下朴素贝叶斯分类
Map函数的分布计算中难以实时交互各Mapper节点信息。为获取计算模式运行结果,需凭借最终产生的中间结果,且确保各节点有相同且独立的任务。基于此,利用设计的朴素贝叶斯分类算法,求取待分类定向数据与不同类别的分类概率[6],划分定向数据至最大分类概率的类别内,完成定向数据挖掘。
若定向数据类别C1,C2,...,Cm的数量为m,各数据对应属性个数为n,则采用下列n+1维属性向量X的表达式来表示各定向数据:

针对待分类的定向数据X',判定其与类别Ci的从属结果,且满足下列不等式:

为使定向数据X'属于类别类别Ci的概率超过其余类别,应最大化处理P(Ci|X'),引用下列朴素贝叶斯公式实现:
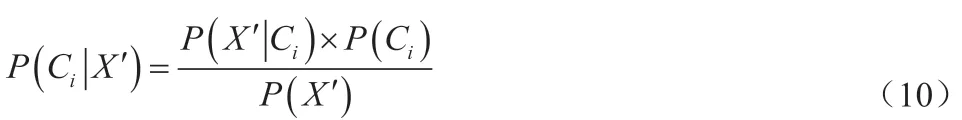
式中,用=P(X')表示常数,P(Ci)与P(X'|Ci)的计算公式分别为:

式中,D内Ci类别的训练元组数为|Ci,D|。
若求解目标是P(x'k|Ci),判定其属性Ak种类:当属性Ak为离散时,P(x'k|Ci)是属性取x'k下Ci类别中元组数量与所有定向数据内Ci类别中元组数量的比值;当属性Ak为连续时,服从高斯分布,其均值与标准差分别是μ与σ,则P(x'k|Ci)用下列界定表达式指代:

根据解得的最大概率类别,完成该定向数据X'分类、挖掘。
在MapReduce并行分布式计算模式执行该算法的过程中,Main函数主要负责读取数据集、转换Reduce的整合结果以及计算节点上的分类器读取,Map函数的功能是统计离散属性取值、求解连续属性均值与标准差以及划分各待分类定向数据,而Reduce函数则用于根据要求统计、输出分类与挖掘结果。各函数具体实现描述如下:
(1)Map函数:假设分布式文件系统的定向数据id号与内容分别是key与value,已知数据集中各定向数据及对应属性;若属性是离散型,则将定向数据类别的属性取值个数累积起来,若属性是连续型,则求取属性取值的总和与平方和;当前分片经过遍历、统计,输出所得结果。
(2)Reduce函数:读取Mapper节点全部临时信息;整合离散型统计结果,获取概率;针对L个定向数据的连续属性,若∑X'表示属性取值总和,∑X'2表示平方和,采用下列两公式求取属性均值μ与标准差σ;统计完全部项目后,输出MapReduce程序的最终结果。

(3)Main函数:读取输出的最终结果;当键值对标记为离散属性时,按照属性号、取值、标签号、概率的形式进行变换与输出;当键值对标记为连续属性时,按照属性号、取值、均值、标准差的形式进行变换与输出。
2 实际案例应用
选取某市中心城区扩展建设用地,在本文设计的基于Hadoop技术的并行计算模式定向数据挖掘方法的支持下,探索城市建设用地的空间格局与演变特征。该城市建设项目中涉及到的数据分别有建成区域面积与总土地面积、建设用地种类、方位数据以及时间数据。建设用地扩展趋势如图2所示。

图2:建设用地扩展趋势示意图
根据本文方法挖掘得到的连续七年城区建成区域面积变化数据与建设用地不同方向扩展强度堆积数据可知:该市中心城区的建设用地面积呈线性扩展趋势;前两年建设扩展方向以西部为主,后三年主要扩展南部方向建设,2013、2014连续两年在东部方向进行了较高强度扩展,扩展形式以圈层渐进式展开,后期扩展强度有所减缓。
3 结语
数据挖掘技术目标是从海量低价值数据里发掘可用的高价值数据,为拓宽该项技术的应用领域。本文以Hadoop技术为基础,提出一种并行计算模式的定向数据挖掘方法[7]。针对爆炸式增长的庞大数据,需结合更新、更理想的分类算法,进一步优化挖掘效果。为此,在未来的研究阶段,探索Hadoop平台启用时间的缩减策略,加快平台小数据处理速度;应尝试探究相关运行参数,合理配置Hadoop云计算平台,进一步提升数据挖掘效率,也为城市管理者制定城市建设方案提供依据和参考。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电子制作(2019年13期)2020-01-14
中国铸造装备与技术(2017年6期)2018-01-22
新校长(2016年8期)2016-01-10
电测与仪表(2015年1期)2015-04-09
电测与仪表(2015年19期)2015-04-09
设备管理与维修(2015年9期)2015-03-16
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
