
基于挖掘读者隐性偏好的数字图书推荐算法
2021-09-22 02:17李冬
安徽电子信息职业技术学院学报 2021年4期
李冬
(商丘职业技术学院,河南 商丘 476001)
一、引言
随着现代信息技术的高速发展,智能化、数字化技术相关应用在人们学习、生活中大量普及,数字图书资源在这一时代背景中迅猛发展,面对丰富多样的数字图书资源,提高读者粘合度、满意度,是数字图书保持发展活力的关键;挖掘读者的隐性偏好,根据其个性化的需求,通过智能化信息过滤技术为其推荐相关资源,是提高数字图书服务效率和质量重要举措。
基于各种算法建立起来的数字图书推荐系统是根据读者的个人偏好,提供差异化图书推荐的有效方法,算法是推荐系统高效、准确运行的基础和关键。基于数字图书内容的协同过滤算法推荐给读者的图书准确率较好,基于读者评分推荐算法推荐的图书质量较高,但这些都难以挖掘读者潜在的、隐性的图书偏好,推荐结果难以满足读者更广泛的阅读需求。关联语义链网络能够有效的组织web上松散的数字图书资源,结合协同过滤算法,构造能够挖掘读者隐性图书偏好的推荐系统,以达到向读者更好的推荐数字图书的目的。
二、相关问题
挖掘读者的隐性偏好需要将读者深层次的图书需求与相关信息产生关联,语义化能够有效揭示资源之间的关系,进而提供高层次的自动化、智能化的信息处理服务。
语义化是一种知识组织的抽象方法,是在资源中建立有针对性的、适宜的语义标签,通过资源语义标签的内容反映出特定资源的语义特征,从而在一定程度上实现计算机对特定资源特征与内容的理解和掌控[1]。
语义关联是指将所有与读者需求相关的信息通过一定的规则进行关联,建立数字图书资源间的语义联系,推荐系统通过算法将关联信息进行过滤和处理,智能化的给出推荐结果。
三、推荐原理及算法
(一)关联语义链算法构造
关联语义链网络是一种对网络资源进行管理的数据模型,可以将具有语义关系的、松散的语义节点链接起来,语义节点包含图片、文字等资源[2]。
本文采用支持度公式(1)与置信度公式(2)的关联规则筛选方法,公式(1)、(2)如下:

其中,N(ki)为ki出现的次数,N(kikj)为ki和kj共同出现的次数。这里将语义元素作为关键词,置信度为规则的权值。
关联语义链算法构造首先通过语义节点计算语义向量和规则,找出关键词;然后计算出两个语义节点的关系语义链权值;然后将语义规则与语义向量做“与”操作,得出语义节点之间的权值,重复计算,直到构造完成[3]。
通过公式(3)计算关联语义链值,并将结果作为权重,语义链值在(0,1)之间。其中(ki→kj)ki和kj为之间的链接权值,(ki→kj)为所有语义节点语义链值的和。
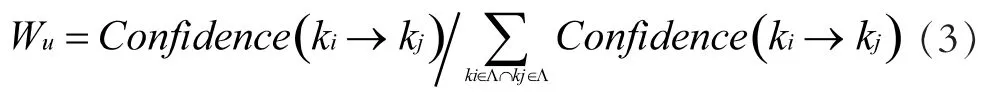
(二)算法推荐模型
根据数据库中数字资源之间的语义节点关键词,通过置信度、关联规则计算,最后计算得出关联语义链接权值,与协同过滤(Collaborative Filtering,CF)[4]算法相结合,构造能够挖掘读者隐性图书偏好的推荐算法,算法模型如图1所示:
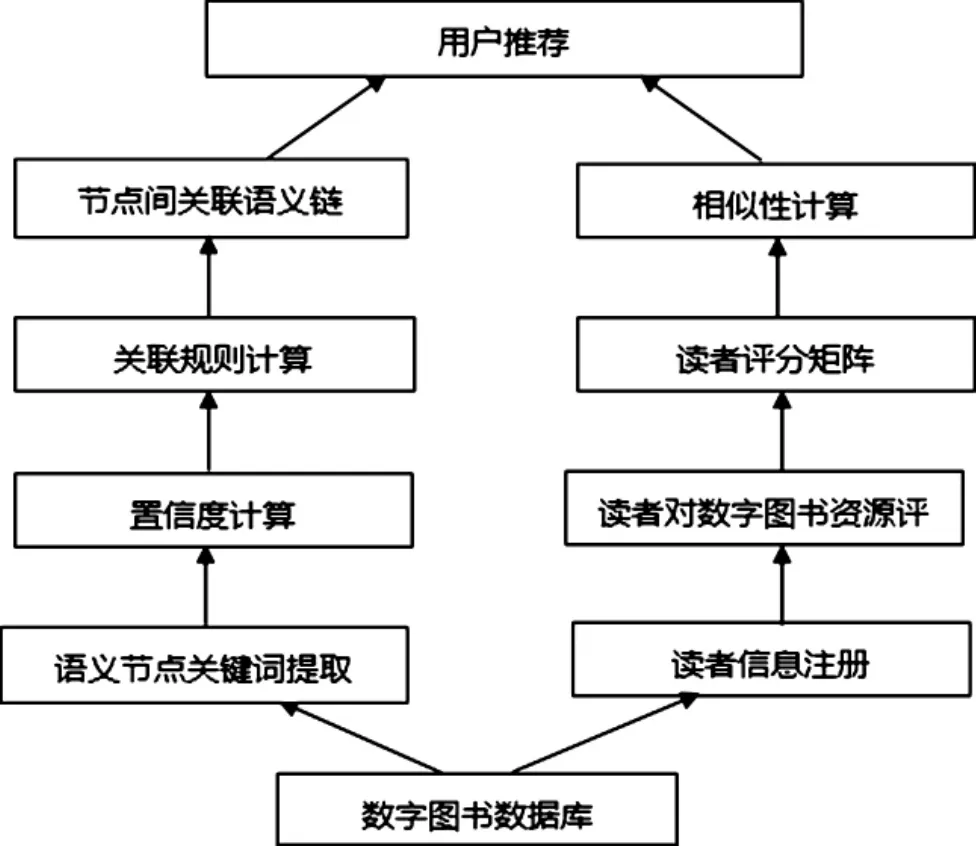
图1 本文算法推荐模型
数字图书数据库收录了读者ID、性别、年龄、专业以及数字图书ID、名称、作者、出版社、图书简介、读者评论、评分等,并建立数据库;通过数据库收集的读者信息及相关数字资源数据,进行项目相似性计算,同时根据数据库中数字资源之间的语义节点关键词,计算得出关联语义链接权值,运用公式(4)[5]计算得分,进行用户推荐。

(三)算法设计流程
(1)关联语义链链接权值计算
使用汉语词法分析系统[6]将图书数字资源进行分词、停用词过滤,筛选和统计保留下来的词名,得到关键词,运用上文提到的公式(3),计算关联语义链链接权值,操作如下:

计算数字图书资源之间的链接权值Wu;

(2)相似性计算
最近邻方法可以对一个不知类别的样本找出最相似的近邻用户进行分类,相似性计算是基于读者评分,建立用户评分矩阵,找出与目标用户相似的用户群体,相似性计算的精准度决定着图书推荐质量,通过Pear-son相似度公式计算,将数字图书资源之间的链接权值Wu加入公式中,如公式(5)所示,ru为读者对图书资源评分的平均值,U(i)、U(j)分别为数字图书资源i、j评分的读者合集,操作如下:

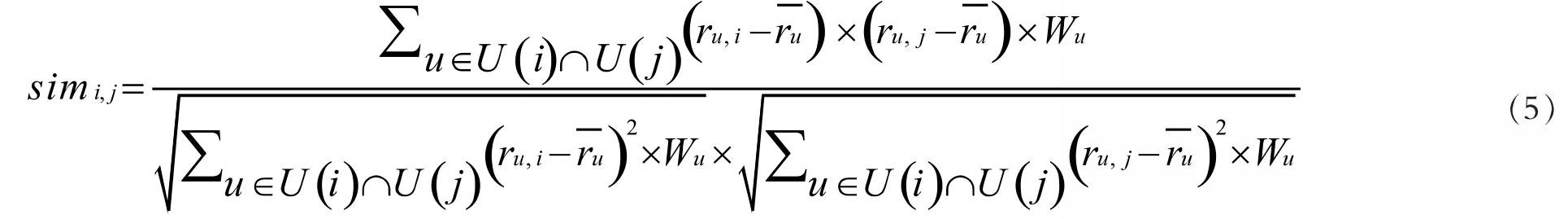
(3)数字图书推荐
图书推荐通过邻居集对图书的评分,通过平均加权法,运用上文公式(5)来预测目标用户u对图书i的评分,进而产生推荐。
四、实验分析
(一)实验数据
本文采用商丘职业技术学院图书馆数字图书资源库中的数据集开展实验,从数字图书资源库中计算机、经济、政治、建筑等学科中选取100本数字图书信息作为数据来源,请商丘职业技术学院不同专业、不同年级本、专科生100人对图书进行评分,收回有效评分9882条,无评分记录或评分偏离有效评分范围视为无效评分。图书资源库提供的数据信息包括数字图书名称、简介等,包含了图书的关键词和简要介绍,利用关键词可以建立起图书之间的关联网络,在此基础上,根据相关数据进行训练和实验检验。
(二)评价指标
平均绝对偏差MAE(Mean Absolute Error)体现预测评分与真实评分之间的偏差平均值,计算公式如式(6·)所示:

公式中,n为读者数量,Pi为预测读者评分集合{P1,P2,…,PN},ri为实际读者评分集合{r1,r2,…,rN},计算出的MAE值越小,误差越小,推荐效果越好。
(三)实验结果及分析
该实验验证本文提出的基于关联语义链的数字图书推荐性能,实验设定样本间隔数为20,邻居数为10,通过计算Top-N推荐结果与协同过滤算法CF进行对比,得出的MAE值如图2所示,图中为不同样本数20-320个运行结果,实验考虑了数据稀疏性对实验结果的影响。
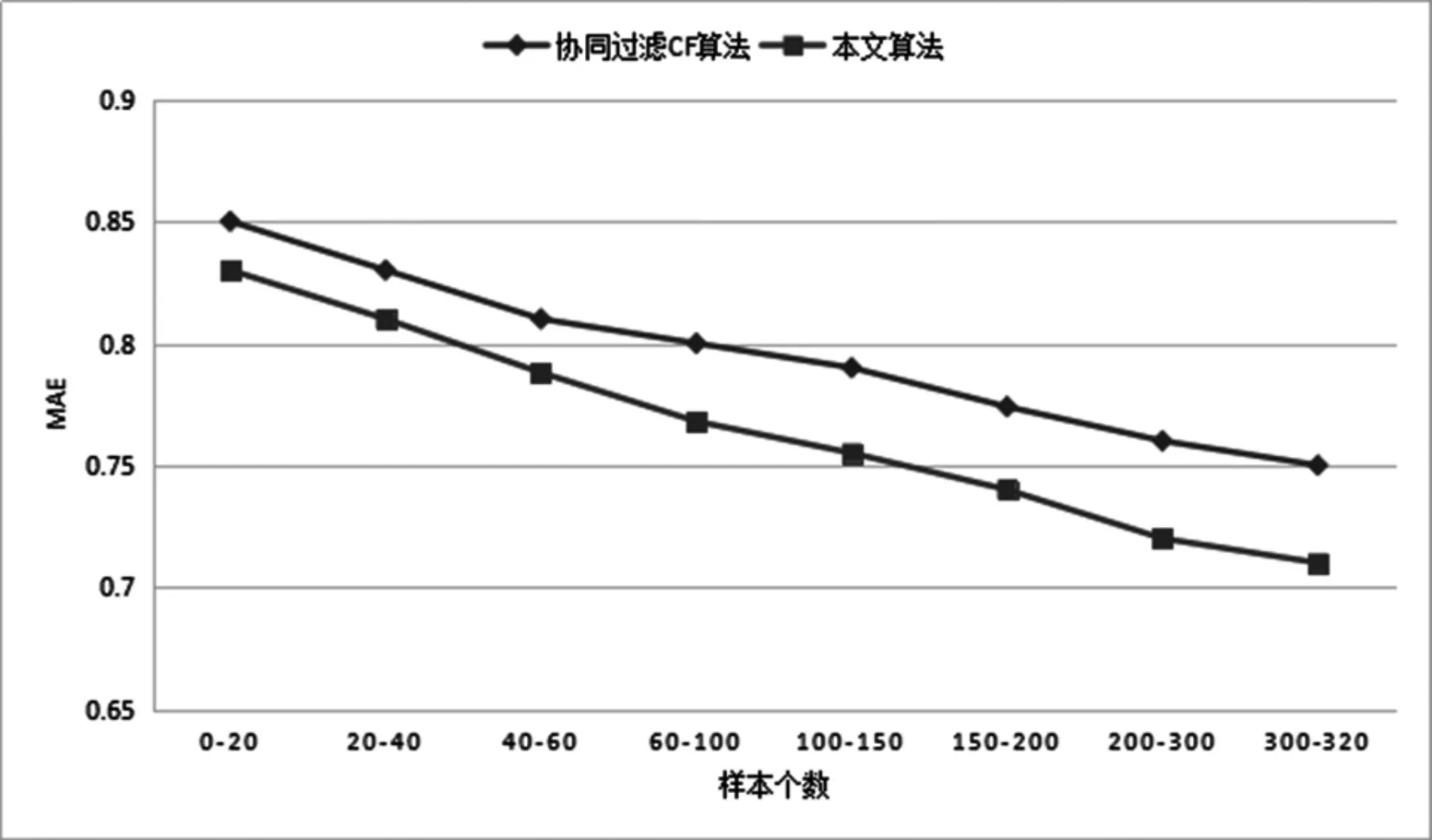
图2 样本个数对应模型的MAE
实验表明,基于关联语义链的数字图书推荐方法与协同过滤CF算法相比较,MAE值均最小,表明本文提出的数字图书推荐方法的有效性,随着已知评分数据源的增加,MAE值不断下降,预测质量也越高,实验证明了该方法能够有效挖掘读者图书隐性偏好,在一定程度上提高了数字图书的推荐性能,获得了较好的推荐效果。
五、结束语
挖掘读者隐性图书偏好,从海量的数字图书资源中向读者有效推荐具有重要意义。本文通过对语义化、语义关联、关联语义链的介绍,阐明了关联语义链在图书信息链接中的作用,结合协同过滤算法,给出了基于关联语义链的数字图书推荐方法,通过实验验证了该方法与协同过滤算法相比较,MAE值均最小,表明该方法优于协同过滤CF算法,具有更好的数字图书推荐性能。
猜你喜欢
今传媒(2022年12期)2022-12-22
成都信息工程大学学报(2022年3期)2022-07-21
新世纪智能(数学备考)(2021年9期)2021-11-24
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
自动化学报(2017年7期)2017-04-18
新媒体研究(2017年1期)2017-03-07
读者(2017年5期)2017-02-15
现代电子技术(2016年15期)2016-12-01
