
基于发音空间特征的构音障碍患者的病情分级
2021-09-23 02:13段淑斐王俊芹DINGAMCamille张雪英
复旦学报(自然科学版) 2021年3期
段淑斐,王俊芹,DINGAM Camille,张雪英,孙 颖
(1.太原理工大学 信息与计算机学院,山西 太原 030024;2.天津大学 电气自动化与信息工程学院,天津 300072)
构音障碍(Dysarthria)是指由于中枢神经系统的损伤,致使患者言语运动不协调,从而导致言语障碍的现象[1].运动性构音障碍属于构音障碍中的一种,它是由于神经和肌肉的器质性病变,造成与构音相关的肌肉收缩力减弱及运动不精确或不协调[2],进而出现呼吸、喉发音、共鸣、构音和韵律等异常[3].因此对于构音障碍的正确诊断、评价是患者康复治疗中必备的一项内容,对于构音障碍病情严重程度的评估或病情分级在言语治疗中也起着至关重要的作用[4].目前在对构音障碍的分析评估上,病情分级的方法通常是主观分析为主,客观分析为辅[5],在针对病患的诊断和治疗中主要依赖于评估者的主观感受,且需要评估者具有较高的专业技能水平,这样会限制诊断的准确率,且结果不具有广泛性.随着机器学习、人工智能技术的发展,对构音障碍的研究也已不限于医学领域,例如研究者可以将病理语音及发音特征提取出来,利用计算机进行数据分析与病情分级,为构音障碍患者的诊断评估提供较为准确客观的方法,并且研究结果能推动医学上自动分级检测技术的发展.
在现有的对构音障碍识别的研究中,研究者大多通过提取音频特征,如音频的能量特征与基音周期[6]、共振峰集中率[7]、韵律特征与倒谱系数的融合特征[8]等进行分析,用以区别构音障碍患者与正常人.上述研究虽然增强了构音障碍识别的客观性,但对于运动性构音障碍而言,了解构音器官的运动模式,获得动态发音空间的位置信息,才是帮助构音障碍患者的有效方法[9].因此为了探究构音障碍患者的动态发音空间及位置信息,张丞然[6]通过计算每个目标因素的发音位置点的分布,发现构音障碍患者的发音区域比正常说话人的区域要小,且更靠近口腔前部.然而,患者在语音的连接中发生构音障碍的可能性比在单音素水平上更高[10-11],在日常交流中,词汇和句子是基本、有效的语言,短语发音除了可以很好地检验说话人表达单个单词的能力[12],还可以检验连续发音时语音连接的流畅性.对构音障碍患者的发音空间进行的探索不仅可以用来寻找构音障碍患者与正常人发音特征之间的差异,还可以用于对构音障碍患者进行病情分级.2015年的Interspeech计算机辅助语言学大赛[4]就关注了帕金森患者的病情分级,如Willamson等[13]提出了基于通道延迟相关和协方差矩阵的帕金森病理分级系统.然而该挑战任务主要集中在提取语音的频谱和韵律特征方面,缺乏发音特征.
本文基于多伦多大学开发的TORGO数据库[15],首先对连续发音时不同说话者舌部的发音运动轨迹以及空间位移进行对比,探究构音障碍与发音空间的关系.随后利用K-means算法计算出空间的质心,在SPSS软件[14]中对此质心数据进行单变量方差分析、箱线图分析,进一步对构音障碍者与正常人、不同病情程度的构音障碍患者之间的差异进行分析.最后选取质心和位移中值两个发音空间特征,分别采用J48决策树以及随机森林(Random Forest,RF)分类器对正常人、轻度、中度、重度构音障碍患者进行病情分级,最后对4种不同人群的正确分类率进行比较.
1 TORGO数据库
1.1 数据库组成
TORGO数据库是由加拿大多伦多大学计算机科学与语音语言病理学系联合Holland-Bloorview儿童康复医院共同开发的包含了近23 h的英文语音数据,以及与声音数据同步的发音运动数据.受试者包括8名构音障碍患者(3女5男)、7名正常说话者(3女4男).其中构音障碍患者为脑瘫和肌萎缩性侧索硬化患者,这两种病因也是最常见的导致患者语音残疾的原因.数据库中所有数据集合都包含4种阅读文本,语料分别由非词短语(Non-words)、短语(Short words)、限制句子(Restricted sentences)和非限制句(Non-restricted sentences)构成.
鉴于舌部在发音中的重要作用,我们只选择在舌部上的3个传感器位置点作为研究对象,这3个位置点分别在舌面上的Sensor 3舌尖(Tongue Tip,TT——舌尖后的1 cm处),Sensor 2舌中(Tongue Middle,TM——舌尖线圈后面的3 cm处)和Sensor 1舌根(Tongue Back,TB——舌中线圈后面2 cm处),如图1所示.
1.2 数据库筛选
为了探究不同病情严重程度的构音障碍患者其发音空间的异同,并进行病情分级研究,因此选择了两名轻度患者DS01、DS02;一名中度患者DS03;一名重度患者DS04作为研究对象.此外,另选两名正常说话人NS01、NS02作为对照.所有说话者发音的文本内容均选择为短语,再对短语内容进行进一步筛选,使得每位说话者所说的文本内容均相同.数据库筛选的情况如表1所示,表1中DS(Dysarthria speaker)表示有构音障碍的说话者,NS(Normal speaker)表示正常说话者.
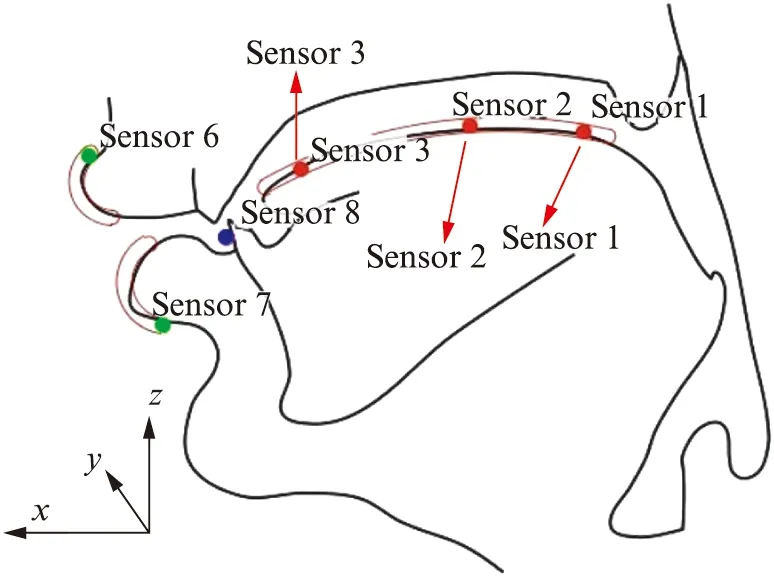
图1 传感器位置点Fig.1 Sensor position point
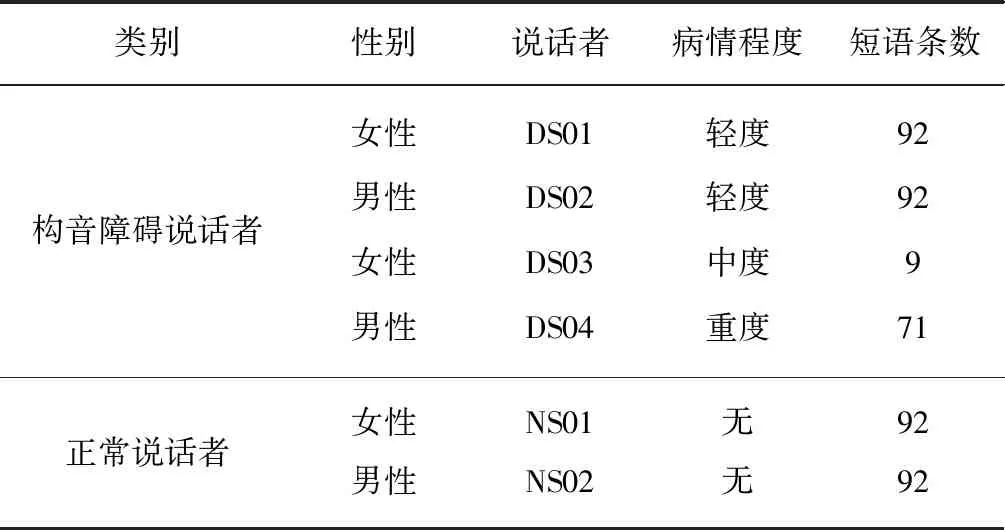
表1 数据库筛选情况Tab.1 Database filtering
1.3 数据预处理
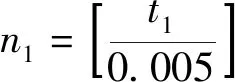
2 构音障碍患者的发音空间
2.1 发音轨迹与位移
利用统计分析软件SPSS绘制出说话者在讲短语时舌部运动轨迹的3维散点图,对比不同说话者的发音空间以及位置分布.此处以短语“yes”为例,列出DS01(轻度)、DS03(中度)、DS04(重度)患者与NS01(正常人)舌尖处运动的3维散点图,如图2所示.
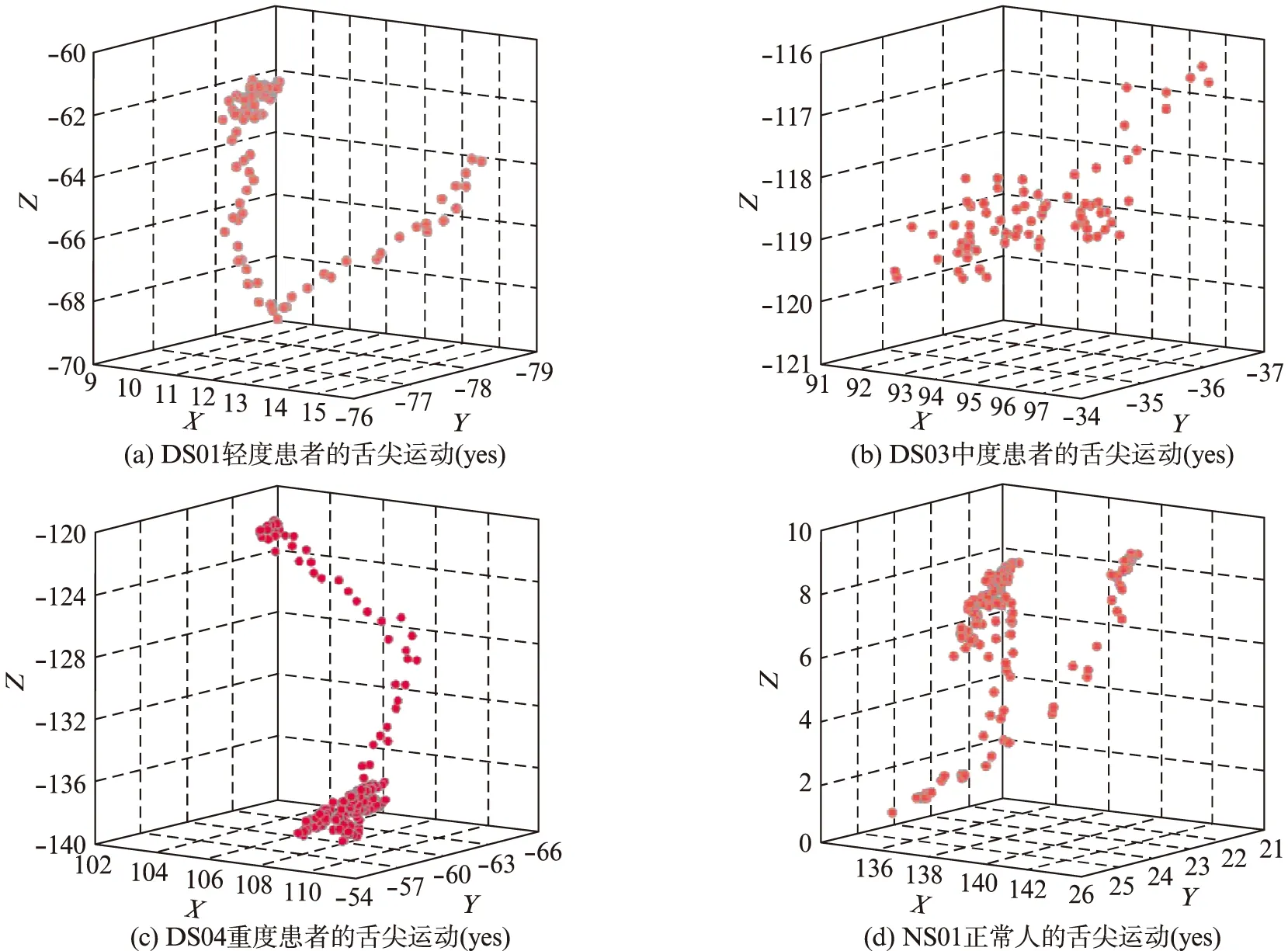
图2 讲短语“yes”时舌尖处的3维散点图对比Fig.2 Comparison of three-dimensional scatter diagram of tongue tip when speaking the phrase ‘yes’
通过对比观察说话者讲话时舌部固定发音位置点的3维运动散点图(运动轨迹),可以对构音障碍患者的病情严重程度进行简单地判断.从图2中即可初步判断DS01轻度至DS04重度患者病情程度呈递增趋势,因为他们的发音轨迹较NS01的相似性逐渐减小,NS01在讲“yes”时舌尖呈现“Y”字形的运动轨迹,DS01轻度患者的舌尖呈现“V”字形的运动轨迹,而DS03中度患者的舌尖呈现一条类似“V”字形右半部分的轨迹且较为杂乱,DS04重度患者舌尖的运动轨迹则与NS01无任何相似之处.
说话者在讲第i条短语(例如“yes”)时,在固定发音位置点(例如舌尖)的某一方向上(例如X方向)的发音位置数据用向量Xi表示,表示录制第i条发音短语的位置数据,1≤i≤n,n为所讲短语的条数.则在讲“yes”时舌尖处X方向上的最大及最小位移分别是
Xmax,i=max(Xi)i=1,2,…,n,
(1)
Xmin,i=min(Xi)i=1,2,…,n.
(2)
那么在该方向上的位移中值为
(3)
如图3所示,列出不同说话者在讲短语“yes”时舌尖分别在前后(X方向)、左右(Y方向)、上下(Z方向)上最大位移Xmax,i与最小位移Xmin,i的对比,以及位移中值Xmed,i.
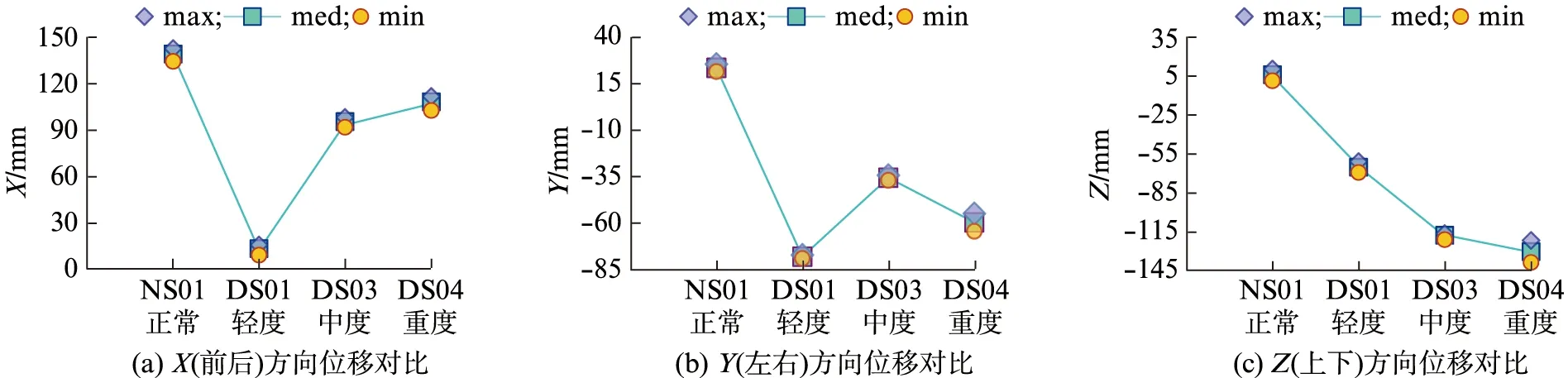
图3 讲短语“yes”时舌尖位移的对比Fig.3 Comparison of displacement of tongue tip when speaking the phrase ‘yes’
在图3中,3名患者在X,Y,Z3方向上舌尖的位移均比正常人的位移小,由此可以发现相比于正常人,构音障碍患者舌部在口腔中发音时位置更偏后、偏左、偏下(向前为X的正方向、向右为Y的正方向、向上为Z的正方向);只观察上下(Z)方向上的位移数据,可以发现重度患者的舌尖位移最低、轻度患者的舌尖位移最高,说明病情越严重,其舌尖位移的位置越低,舌部越无力抬起.此外,在前后(X)与左右(Y)方向上,均为轻度患者与正常患者的位移差最大.
2.2 发音空间的数据分析
2.2.1 K-means聚类算法
K-means算法的基本思想是:先确定常数K,该常数代表聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧氏距离),将样本点归到最相似的类中.再重新计算每个类的质心(即为类中心),重复此过程直至质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心.
当以欧氏距离作为衡量样本与质心之间的相似度时,K-means算法的目标函数为
(4)
其中:N是数据数目;C是划分簇的数目;rc是一个0到1之间的变量,当数据点xn被归类到C簇时为1,否则为0.K-means算法的目标就是最小化这个目标函数.
由于此处每条短语的发音轨迹只有一个,即只有一个聚类类别,因此常数K为1,聚类中心μ是距离每一个样本点xn的欧氏距离均最小的点,将其作为该发音运动轨迹的质心,该质心可以表示如下:
μ=min{‖xn-μ‖2|n=1,2,…,N}.
(5)
为进一步探究不同病情程度的构音障碍患者之间的差异性,我们利用K-means聚类算法求出各说话者在讲每一条短语时发音运动轨迹的质心.
以DS03患者的质心数据为因变量,分别以DS01患者和DS04患者的质心数据为协变量进行单变量方差分析,其显著性结果如表2(见 第292页)所示.若结果中p<0.05,则说明两个变量之间存在显著性差异,反之说明两个变量之间不存在显著性差异,且p越接近于1,两变量间的差异性越小(由于DS04患者没有舌根处的发音运动数据,因此只进行了舌中、舌尖处质心数据的显著性对比分析).
在表2中,可以看到无论在舌中还是舌尖处,在上下(Z)方向上3种病情程度的患者之间的p值均小于0.200,平均值为0.078;而在前后(X)、左右(Y)方向上的显著性均大于在上下(Z)方向,其中前后方向上不同病情患者间p值均值为0.538,左右方向不同病情患者间p值均值为0.861.说明不同病情严重程度的构音障碍患者之间的发音运动主要差异在上下方向上.
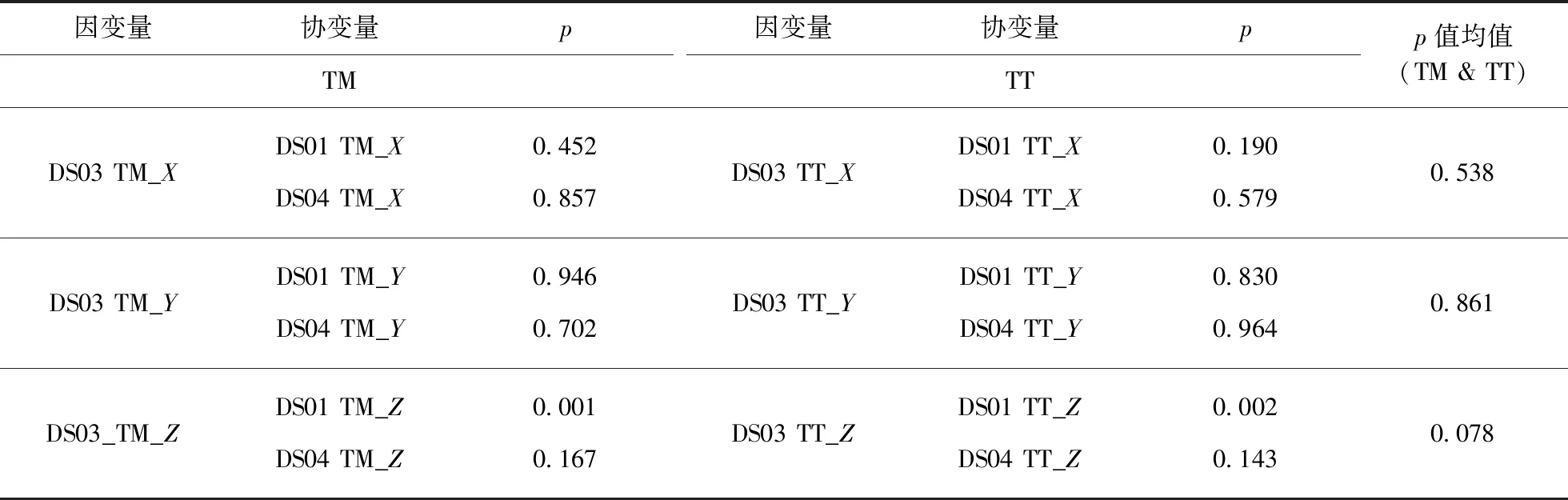
表2 DS03中度与DS01轻度、DS04重度患者之间的显著性分析结果Tab.2 Significant results among DS01 mild,DS03 moderate and DS04 severe patients
2.2.3 箱线图分析
在箱线图的数据统计描述中,5个统计量分别是最小值、第一四分位数Q1(下四分位数)、中位数Q2、第三四分位数Q3(上四分位数)与最大值,四分位距dIQR=Q3-Q1.在Q3+1.5dIQR和Q3-1.5dIQR处为内限,内限之外的点用圆圈标注为异常值;在Q3+3dIQR和Q3-3dIQR处为外限,外限之外的点用星型标注为极端值,此处将异常值与极端值统称为偏离值.
式(5)是发出某一短语时固定发音位置点的3维质心,那么在n条短语的发音中在Y(左右)方向上的最大值、最小值分别为
μy,max=max(μyj)j=1,2,…,n,
(6)
μy,min=min(μyj)j=1,2,…,n.
(7)
将n条短语发音的Y方向的质心数据从小到大排序为{μy1<μy2<…<μyj<…<μyn},j=1,2,…,n.那么下四分位数、中位数、上四分位数分别为
μyQ11≤Q1=(n+1)×0.25≤j≤n,
(8)
μyQ21≤Q2=(n+1)×0.5≤j≤n,
(9)
μyQ31≤j≤Q3=(n+1)×0.75≤n.
(10)
图4所示为DS01(轻度)、DS03(中度)与NS01(正常人)舌尖(TT)处质心数据在Y方向上的箱线图对比,由此图可以得到如下结论:
南昌大学教授彭迪云提出,乡村振兴首先要做好乡村脱贫,乡村脱贫要借助金融的力量,金融是现代经济的核心,金融扶贫是打赢脱贫攻坚战的重大举措和关键支撑。金融助推国家精准扶贫,不但是金融相关部门的责任与使命,更是整个金融行业潜力的再发掘的重要机遇。他在论文中以江西为例专门就农村金融精准扶贫的成效进行了评价,并提出了应对的政策建议。

图4 舌尖处左右方向的质心数据箱线图Fig.4 Boxplot of phonological centroid data for the left and right of the tongue tip
(1)构音障碍患者在左右(Y)方向上的发音位置质心偏离值分布与正常人的相反.即正常人在左右方向上的发音位置质心偏离值分布偏左,而构音障碍患者在左右方向上的发音位置质心偏离值分布偏向右边.
(2)对比构音障碍患者与正常人,发现构音障碍患者的偏离值分布较为分散且范围较大,而正常人的偏离值分布较为集中且范围小.
(3)在构音障碍患者之间进行比较,可以发现患者的病情较严重时,其发音运动的质心箱图中四分位距更大,且中位数位置也更偏.
3 实 验
本节选取发音运动轨迹的质心与位移中值两个发音空间特征,分别输入到J48决策树和随机森林分类器中,进行对正常人、轻度构音障碍患者、中度构音障碍患者、重度构音障碍患者的分类识别,共有4种组合方式.J48决策树的置信因子设置为0.25,每个叶的最小实例数量设置为2.然后,从筛选后的数据中,选取65%作为训练集,35%作为测试集,并采用5折交叉验证法来检验特征以及识别网络的性能.
3.1 构音障碍患者病情分级的识别率
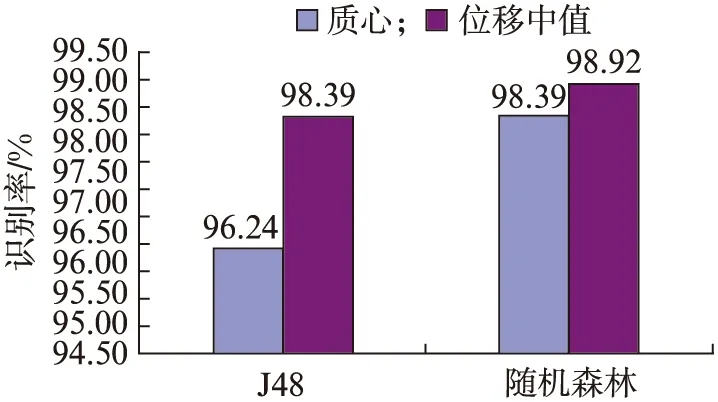
图5 两种分类器对短语发音空间特征的识别率Fig.5 Recognition rate of two classifiers for phrase pronunciation space features
采用两种分类器对两种发音空间特征进行分类的识别率见图5,可以发现用随机森林分类器对不同病情程度的构音障碍患者和正常人识别的识别率均比用J48决策树的要高.另外,在说话者的发音空间特征方面,对位移中值的识别率总是大于对质心的识别率.
上述4种组合方式得出的混淆矩阵见表3~表6.其中对轻度DS的误判共有6次、对中度DS的误判共有1次、对重度DS和NS的误判均共有4次,说明4种情况的分类器均对中度DS的预测效果最好.此外,在表4和表6中,两种分类器对位移中心的分类识别中,对中度DS和重度DS均不存在误判,说明对位移中值进行分类,可以很好地区分中度和重度构音障碍患者.
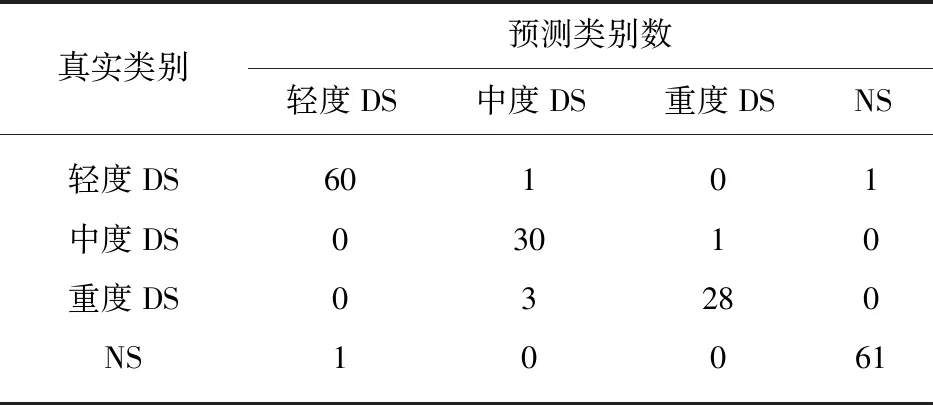
表3 J48决策树对质心的分类Tab.3 Classification of centers of mass by J48 decision tree
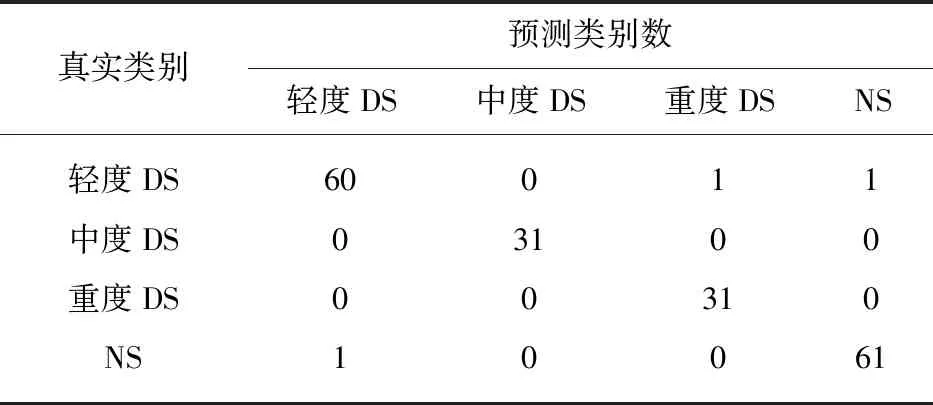
表4 J48决策树对位移中心的分类Tab.4 Classification of displacement centers by J48 decision tree
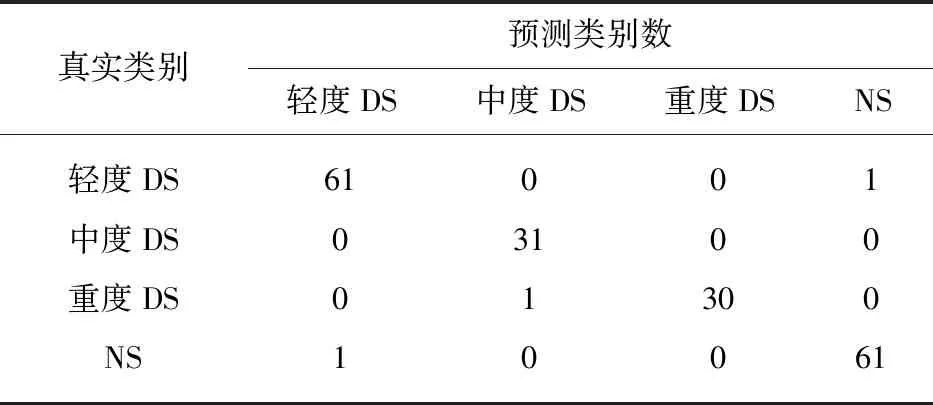
表5 随机森林对质心的分类Tab.5 Classification of centers of mass by random forest
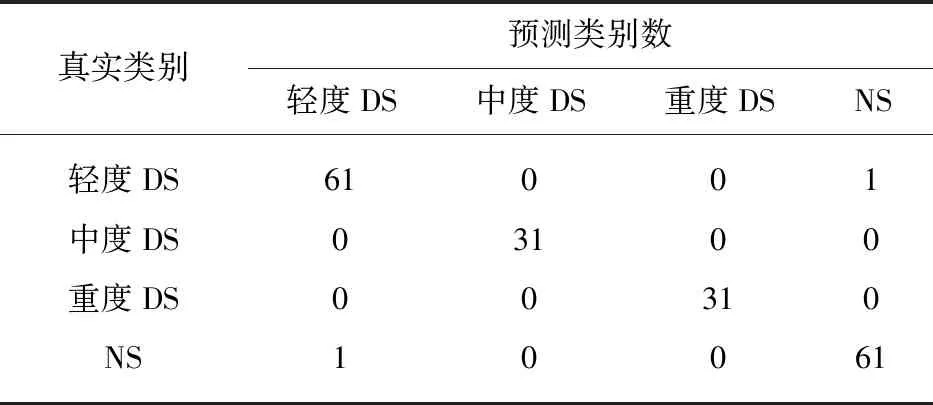
表6 随机森林对位移中心的分类Tab.6 Classification of displacement centers by random forests
3.2 构音障碍患者病情分级的正确分类率
为进一步直观地对比构音障碍患者病情分级的准确率,计算正确分类率来进行分析.正确分类率通过灵敏度(True positive rate)λTP来表示,计算方式如下:
(11)
其中:kTP表示预测类别为正,真实类别为正的样本数,即某一真实类别被正确预测的个数;kFN表示预测类别为负,真实类别为正的样本数,即某一真实类别被错误预测的个数.图6为发音空间特征是质心的正确分类对比图.图7为发音空间特征是位移中值的正确分类对比图.
图6中,对于轻度DS,随机森林进行分类时的正确率为98.39%,比J48决策树提高了1.62%;对于中度DS,随机森林进行分类时的正确率为100%,比J48决策树提高了3.23%;对于重度DS,随机森林进行分类时的正确率为96.77%,比J48决策树提高了6.45%.对于正常人,随机森林与J48决策树的分类正确率相同.
图7中,对于轻度DS,随机森林进行分类时的正确率为98.39%,比J48决策树提高了1.62%.对于中度DS、重度DS、正常人,随机森林与J48决策树的分类正确率相同.
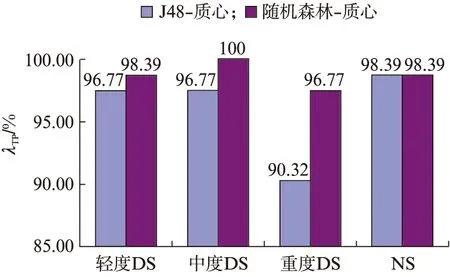
图6 发音特征为质心的正确分类率Fig.6 Correct classification rate of the centroid as the articulatory feature
综上所述,采用随机森林分类器对受试者的舌部位移中值这一发音运动特征进行分类识别时,可以得到最优识别性能,同时也说明了随机森林在对质心与位移中值两个发音运动特征的选择性方面具有一定的优越性.
4 结 语
对于构音障碍患者的评估与治疗的研究越来越多,此前的研究大多是基于声学特征的.对发音运动过程中发音器官的发音位置进行直接测量,得出发音运动特征并对其进行分析研究,更有利于分析构音障碍的特征,寻找构音障碍患者与正常人、构音障碍患者之间的差异.首先,本文基于发音空间特征,分析了构音障碍患者与正常人在讲话时发音位置在空间中的分布,通过对比构音障碍患者与正常人发音运动的3维散点运动轨迹,发现了构音障碍患者发音时舌部较正常人偏后、偏左、偏下的结论,以及正常人与构音障碍患者之间、不同病情程度的构音障碍患者之间的差异主要在上下运动方向,且病情越严重,患者舌部越无力,运动位置越靠下.其次,对使用K-means聚类算法找出的质心与位移中值两个发音空间特征,分别采用J48决策树以及随机森林分类器对正常人,轻度、中度、重度构音障碍患者进行分类识别,发现采用随机森林分类器对受试者的舌部位移中值发音运动特征进行分类识别时可达到最优识别性能.在今后的研究中,可以寻找更准确的发音空间特征或是发音运动特征,进行构音障碍患者的病情分级研究.本文采用公开数据库进行试验,但是数据库中的被试构音障碍患者人数较少,且存在被测点发音位置数据缺失的情况,而且在实验中,本文所用数据库中的数据是经过同一文本内容的筛选后得到的,进一步减少了数据量,因此在算法的普适性方面有待后续研究进行完善.
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汉语世界(The World of Chinese)(2022年3期)2022-06-15
北京航空航天大学学报(2021年4期)2021-11-24
电子技术与软件工程(2019年8期)2019-07-16
中学生数理化·教与学(2019年5期)2019-06-06
杂文月刊(2018年11期)2018-09-06
爆笑show(2016年4期)2016-06-17
科技知识动漫(2016年3期)2016-03-22
