
基于信息熵的食品安全事件聚类方法研究
2021-10-05 12:53辜萍萍
智能计算机与应用 2021年5期
辜萍萍
(厦门大学嘉庚学院 信息科学与技术学院,福建 漳州363105)
0 引 言
近几年,中国的食品安全危机成为发展小康社会的绊脚石,主要集中表现在化学添加剂与农药等滥用、生产流通环节卫生状况差、安全标准不够完善、监管水平有待提高几个方面。2017年2月,国务院印发《“十三五”国家食品安全规划》文件,明确指出“保障食品安全是建设健康中国、增进人民福祉的重要内容,是以人民为中心发展思想的具体体现”[1]。规划中制定了针对食品安全管理的基本原则:预防为主、风险管理、全程控制与社会共治。现阶段,国家不断加大整治力度,从完善政府监管体制到增强全民自主防范意识多渠道多维度进行共治,全面打造老百姓可信赖的食品安全环境。
在智能信息化时代背景下,提高食品安全智慧的监管能力、实施“互联网+”食品安全监管项目、推进食品安全监管大数据资源共享和应用是切实的目标与手段[2]。目前,数据挖掘方法正越来越多地被应用于食品安全相关数据进行知识发现。例如,江苏省食品安全研究基地的李清光等人运用Hierarchical Cluster方法对2005~2014年间发生的有明确时空定位的2 617起食品安全事件进行聚类分析,总结了事件集的区域分布特点以及随时间变化的空间转移趋势[3]。本研究提出一种基于信息熵的食品安全事件聚类分析模型,对食品安全事件中的相关属性特征进行提取,从聚类模式中挖掘代表性的问题,分析不同种类食品的各种不安全因素是否受到日期与地区的某种影响,发现各地区之间是否在食品安全危机状况上存在相似点,从而为监管部门在措施制订过程中提供决策支持,也为普通消费者在采购食用方面提供信息参考。
1 食品安全数据挖掘的意义
数据挖掘中的聚类分析、关联规则、决策树及偏差检测等技术在食品行业管理领域不断被应用及推广,利用这些挖掘技术找出潜藏在数据中的知识,为监管及预防提供依据。其意义主要体现在以下2方面:
(1)数据挖掘技术用于食品安全事件数据的分析,可以发现事件发生的特点、规律以及未来发展趋势,对监管部门分析事件发生的原因、制定监管措施,更有效地预防事件的发生都存在积极的作用,从而利于社会的安定与发展。
(2)通过公众媒体渠道发布数据挖掘的相关结果,让民众了解食品安全事件中更深层次的信息,提醒民众结合平时的采购及饮食习惯,警惕可能存在问题的食物,远离风险源头,保障自身的饮食健康。
2 数据采集与建模
2.1 食品安全数据的采集
无论是食品生产环境受到污染还是制造过程的非法添加,近些年食品安全事件层出不穷。由复旦大学研究生吴恒创办的“掷出窗外”网站从各大主流新闻媒体搜集了最近八年以来全国发生的食品安全事件将近3 600条数据记录,构建成一个相对集中的问题食品资料库[4]。本次研究利用爬虫技术,建立数据爬取模型,将网站地址导入模型,随即获取网页信息,读取每个页面上的50条事件记录,直到所有页面访问完成。每条记录包含新闻标题、新闻日期、事件发生地区、事件主题、相关食品、品牌、不安全因素等多个标签,由于网站中的原始事件列表存在若干无关项或者标签类别不统一,则需要后续的数据集预处理工作。数据筛选的准则是保留所有有助于挖掘算法实施的记录,所以需要完成特征选择与特征工程的相关工作,针对数据记录中确实存在不统一的属性标签或属性值有所缺失的情况,将数据集的属性标签做统一化预处理,将多余属性排除,将残缺数据补全。
2.2 食品安全数据的存储与描述
每一个食品安全事件都是一个数据样本,这些数据样本的所有属性值都是文本型数据,各属性的取值范围见表1。

表1 数据对象各属性取值范围Tab.1 Value range of each attribute of data object
数据存储采用电子表格,以CSV纯文本形式存取二维数据表。表格中的每一行为食品安全事件记录,每一列为一种属性。预处理后得到的食品安全事件数据集格式见表2(因篇幅所限,此处仅提供数据表片段)。

表2 食品安全数据集Tab.2 Food safety data set
3 算法改进与实现
在现实中的分类往往伴随着模糊性,所以用模糊理论来进行聚类分析也更趋于最优。同时,食品安全数据的最大特点是样本的每一个属性经过标准化均取离散型数值,因此该数据模型最适合采用模糊K-Modes算法进行挖掘[5-6]。为了进一步提高算法的有效性,本模型利用加权平均密度的方法自动选取初始聚类中心,并依据信息熵理论重新计算数据集的属性重要性,以此改进传统的算法。
3.1 模糊K-Modes算法思想
传统的模糊K-Modes算法总体思想是对文本型的数据集进行划分归类,假设对于一个由n个对象构成的非空集合U={x1,x2,…,xn},首先随机选取k个对象作为k个初始聚类中心,通过0或1匹配的方法计算相异度矩阵,再根据相异度矩阵计算隶属度矩阵,而后通过隶属度矩阵将n个对象划分到最近的初始聚类中心中,形成k个聚类簇,完成一次聚类,计算收敛函数,再通过更新聚类中心的方法在每个聚类簇中重新定义一个新的中心,重复之前的内容计算相异度矩阵、隶属度矩阵、分配对象,形成k+1个聚类簇,计算收敛函数,比较2次的收敛函数。多次迭代这样的过程,交替更新聚类中心和隶属度矩阵,直到式(1)所示收敛函数的值趋于稳定,即聚类中心不再发生偏移,算法结束。

Fuzzy K-Modes算法利用模糊的概念对数据进行软聚类,大大提高了聚类过程的鲁棒性。
3.2 改进的Fuzzy K-Modes算法
信息熵是同一信源发出的各种信息量的平均,可以表征信息环境的无序程度,在一定程度上解决了系统有序度的度量问题[7-8]。根据信息熵理论来计算每个聚类对象的属性对于分类的贡献度,可以排除无用属性。基于传统的算法思想以及信息熵理论,改进的K-Modes算法具体流程如下:
(1)输入目标的初始聚类中心数k,k≥1;
(2)根据公式(2)计算属性总集合A的信息熵E(A):

E(A)表示整体的信息熵,即所有的属性将数据集U划分的情况。其中,A将数据集U划分成了一个新的集合C,C={A1,A2,A3,……,Ap},对于C中的任意一个元素Ai表示数据集U中与Bi的属性值完全相等的数据集子集,所以Ai⊆U,且|A1|+|A2|+|A3|+……+|Ap|=|U|,|Ai|/|U|即表示属性值与Ai完全相等的元素在数据集U中出现的概率;
(3)计算属性总集合中缺少每个属性后的信息熵E(A-{a}),其中E(A-{a})表示去掉a属性后,剩余的属性对U的划分情况,计算公式与E(A)相同;
(4)根据步骤(2)和步骤(3)获取的结果,计算每个属性的权值Sig(a),式(3):
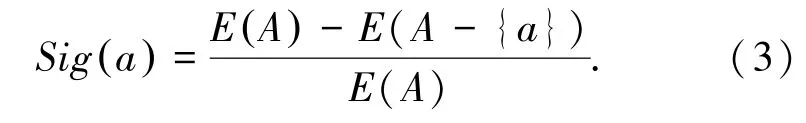
若属性a对数据集U毫无影响则E(A)=E(A-{a}),说明a对数据集U的划分没有起到作用,即Sig(a)=0,说明a的属性重要性为0;反之若属性a对数据集U影响越大,则排除a属性的E(A-{a})与E(A)就相差越大;
(5)遍历数据集U,计算每个属性的平均密度,平均密度的计算公式(4)为:

其中,Densa(x)表示对于A中的任意元素a,对象x在属性a上的平均密度计算方法为式(5):

该公式为了计算得出数据集U中与对象x的属性a的属性值相同的对象的总数;
(6)对于数据集U中的每一个对象x,计算其加权密度WDens(x),式(6):

(7)选取所有对象中加权密度WDens(x)最大的一个,将其设为第一个初始聚类中心,加入聚类中心集合Z;
(8)遍历数据集U中已经选取为聚类中心以外的每个对象x,保存对象的加权密度WDens(x),计算公式与步骤(6)所述相同;
(9)采用0-1相异度度量方法计算对象x与每个已分配好的初始聚类中心的距离之和d(x),式(7)和式(8):

其中,xi,al,xj,al分别表示数据集中xi和xj2个对象在对应属性上的属性值,如果相等则当前属性间的距离赋值为0,如果不相等则赋值为1,累加所有属性的属性间距离,最后得出2个对象之间的距离,即差异度;
(10)对每一个对象x,计算m(x),式(9):

(11)比较所有的m(x),选取m(x)最大的那个对象作为新的初始聚类中心,加入聚类中心集合Z。
(12)判断聚类中心数是否达到k个,即|Z|>k是否成立,如果成立跳转到步骤(13),如果不成立则跳转到步骤(8),继续选择其它的初始聚类中心;
(13)根据步骤(4)所述的Sig(a),计算每个属性的权值weight(a),式(10):

(14)用改进的相异度度量方法计算相异度矩阵,式(11):

其中,δa(xi,xj)参见步骤(9)所述的定义。该公式的含义为任意2个对象之间的距离,当属性值相同时依然为0,当属性值不同时取属性的权值作为距离计算,这样价值高的属性影响力就更大。
(15)计算隶属度矩阵Wl×n,式(12):

其中,k表示当前数据集划分为k个簇,即存在k个聚类中心;Zl表示当前第i个类的聚类中心;Zh表示其它类的聚类中心;
(16)根据隶属度更新聚类中心集合Z,采用属性众数作为聚类中心的新的属性值。即遍历每一个类簇,计算类簇里每一个属性的每一个属性值的总数,用总数最高的属性值替换当前该类簇的聚类中心;
(17)回到步骤(15)重新计算隶属度,根据每个样本的最大隶属度重新归类;如果隶属度不再变化,那么k类的聚类已经完成,跳转至步骤(18);
(18)根据当前隶属度矩阵与相异度矩阵计算聚类准则函数,式(13):

其中,n是数据集的规模,即聚类对象的数量;Zl=[zl1,zl2,...,zlm]是能够代表聚类l的向量,即聚类中心;wi,l∈[0,1]是隶属度矩阵Wl×n的一个元素,表示对象Xi划分到聚类l中的隶属度;∑k l=1~ωli=1;wd是改进后的相异度(距离);α>1是加权指数;
(19)聚类数量k递增1,并回到步骤(1),直到k=n为止,聚类准则函数最小的那一轮聚类为最后的聚类结果。
4 实验结果分析
为了验证算法的有效性,利用著名的算法有效性 指 标 正 确 率AC(accuracy)、 类 精 度PC(precision)、召回率RE(recall)进行实验比对,式(14)~式(16):


其中,k表示数据集当前的聚类数量,|U|表示整个数据集的对象数量,令ai代表被正确分配到第i类的对象数量,令bi代表被错误分配到第i类的对象数量,令ci代表被错误排除出第i类的对象数量。实验中,除了准备好有效性指标之外,还需要有明确分类结果的测试数据集,因此模型中选择加州大学欧文分校提出的用于机器学习的数据库——UCI数据库作为实验数据,其包含335个数据集,是一个常用的标准测试数据集。该数据集中分别含有数值型数据集与文本型数据集,其中的文本型数据集适用于本模型提出的算法有效性实验。每个数据集提供了一份完整的数据记录、分类属性和分类结果集,实验中将数据集导入聚类分析模型执行改进的算法,进而计算PC,AC,RE3项指标值,从而检验算法的有效性。
本文选择UCI数据库中的3个文本型数据集Soybean、Zoo和Vote来检验算法。并通过与其它K-Modes算法进行AC,PC,RE指标值的对比,发现本文所改进的算法具有更高的聚类有效性。实验中选择随机选取初始聚类中心的K-Modes算法(Huang’s k-modes with random)和基于平均密度选取初始聚类中心的K-Modes算法(Huang’s k-modes with Xing’s method)参与比较[10]。实验结果见表3~表5。

表3 Soybean数据集聚类有效性指标表Tab.3 Index table for clustering effectiveness of Soybean data set

表4 Zoo数据集聚类有效性指标表Tab.4 Index table for clustering effectiveness of Zoo data set

表5 Vote数据集聚类有效性指标表Tab.5 Index table for clustering effectiveness of Vote data set
为了更直观展示3种算法在各实验数据集上的有效性指标对比,将AC、PC和RE在不同数据集上分别求出平均值生成折线图如图1所示。

图1 聚类有效性指标平均值对比图Fig.1 Comparison chart of average value of cluster validity index
本次研究中,将改进的聚类算法应用于通过爬虫系统爬取获得的食品安全数据集进行规律挖掘,经过对初始数据集的清洗整理,最后筛选出2 751条有效记录。利用上述算法中对最大聚类数的计算,实验中需要进行52轮聚类,并分别计算聚类准则函数值,取值最小的那一轮聚类为最后的聚类结果。聚类完成后每个类簇的聚类中心,即每个类中最具有代表性的食品安全事件已经被挖掘出来见表6。需要特别说明的是,由于该数据集网站“掷出窗外”近年来暂无更新,因此安全事件发生日期均是若干年前;同时,被曝光的大多数安全事件中缺乏关于食品品牌的具体数据,因此在预处理数据时均已标记为“未知品牌”。

表6 食品安全数据集聚类中心Tab.6 Clustering center of food safety data set
5 结束语
经过UCI文本数据集的实验测试,本文改进的基于信息熵的模糊K-Modes算法与传统的算法相比在聚类正确率、类精度和召回率3项有效性指标上均表现出更加优越的特性。
虽然国家越来越重视百姓的餐饮安全,但问题屡禁不止。利用数据挖掘算法对已经采集到的食品安全事件数据集进行聚类分析,找到每个聚类中心,这些聚类模式代表着数据集中最值得关注的焦点事件,从而引起监管部门的重视以及消费者的警惕。
在下一步研究应用中,继续关注食品安全领域的相关事件,尽可能获取到最新的数据进行数据挖掘,以便对当下的食品质量监管提供参考性建议。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
中国计算机报(2021年9期)2021-04-26
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
电子技术与软件工程(2016年23期)2017-03-06
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年27期)2016-12-15
犯罪研究(2016年5期)2016-12-01
现代养生·下半月(2015年1期)2015-05-26
