
基于BiGRU-Capsule的多标签文本分类
2021-10-05 12:53肖萍婉王子牛高建瓴
智能计算机与应用 2021年5期
肖萍婉,王子牛,高建瓴
(贵州大学 大数据与信息工程学院,贵阳550025)
0 引 言
在大数据时代,每天都在产生各种类型的数据,数据量大且具有多样性。多标签文本在日常生活中十分常见,例如:一条微博可能同时标注“明星”、“综艺”、“搞笑”、“娱乐”等多个标签;一则体育新闻可能同时标注“体操”、“奥运会”、“体育”等标签。多标签文本分类在现实生活中有许多实际应用,如视频注释、主题识别[1]、情感分析[2]、信息检索[3]等。因此,多标签文本分类任务是自然语言处理领域一个十分重要却又富有挑战性的任务。
1 相关研究
目前,多标签文本分类的研究方法可分为3种类型,分别是算法适应方法、问题转换方法和神经网络方法。算法适应方法是根据已存在的传统单标签文本分类算法,进行相对应的改进后,得到适应处理多标签分类的算法。Elissee等人提出Rank-SVM(Ranking Support Vector Machine)方法[4],是将经典的支持向量机运用到多标签分类中;陆凯等人提出的ML-KNN方法[5],是先利用K近邻算法得到近邻样本的标签,然后未知示例的标记集合是通过最大化后验概率推理得到。问题转换方法是将多标签分类任务转化为传统的单标签分类任务,目前单标签分类任务已经有许多成熟的算法可以选择。如,二元分类算法BR(Binary Relevance)[6],是将多标签学习问题分解为多个独立的二元分类问题,但存在缺乏发现标签间相互依赖的能力,这将会导致预测标签的性能降低;标签统一算法LP(Label Powerset)[7],是将每个有可能的标签重新整合成一组新的标签集合,再将问题转化为单标签分类任务;分类器链算法CC(Classifier Chains)[8],是将多标签学习任务转换为二元分类问题链,链上每个节点对应于一个标记,通过模拟标签之间的相关性进行分类;文献[9]设计了基于流式多目标回归器iSOUPTree的多标签分类方法;文献[10]设计了一种基于去噪自编码器和矩阵分解联合嵌入多标签分类算法Deep AE-MF;如此等等。上述两个类型的方法都是依赖于大量特征工程的传统机器学习方法。
近年来,随着深度学习的发展,和机器学习方法相比,深度学习可以自动学习文本特征,具有泛化性更强的优点。因此,研究者提出了许多基于神经网络的方法,深度神经网络被广泛应用于多标签文本分类任务。Berger等人[11]在词嵌入层,利用预训练模型word2vec来捕获单词顺序,将向量输入到CNN和GRU上,相比传统的词袋模型分类性能得到提升;Baker[12]设计了一种基于CNN架构的标签共现的多标签文本分类方法;Liu等[13]针对极端多标签文本分类中巨大标签空间引发的数据稀疏性和可扩展性,考虑到标签共现问题,提出了XML-CNN,用卷积神经网络设计了动态池处理文本分类;Chen等人[14]提出CNN与RNN的融合机制模型,将CNN的输出作为RNN的输入,来捕获文本的局部和全局语义信息,再进行多标签的分类任务;Yang等[15]首次提出将序列生成思想应用于多标签文本分类;Qin等[16]延续序列生成思想,构建新的训练目标,以便RNN能发现最佳标签顺序;Hinton等[17-18]提出的胶囊网络模型,采用向量神经单元和动态路由更新机制,改进了卷积神经网络模型,克服了CNN的弊端,在图像处理领域已取得较好成果;Zhao等人[19]首次将胶囊网络模型应用在文本分类任务上,其分类效果比CNN有一定的提升。
2 BiGRU-Capsule模型
多标签文本分类问题的目标,是为每个未分类文本样本标注合适的类别标签。可定义为:X=Rm表示输入样本有m维特征空间,Y={y1,y2,…,yn}表示所有类别标签集合,共有n个类别标签。通过训练样本集学习得到了一个分类器f:X→2Y。 其中,xi∈X是输入空间X的训练样本,yi∈Y是xi的类别标签集合。每个样本都有一个标签集合与之关联,最后通过分类器得到测试样本的所属标签集合[20]。基于BiGRUCapsule的多标签文本分类模型整体结构如图1所示。

图1 BiGRU-Capsule模型整体结构Fig.1 Overall structure of BiGRU-Capsule model
传统的卷积神经网络在池化层中进行标量计算的操作,在该过程中可能会导致文本特征的丢失。针对上述问题,“神经网络之父”Hinton提出了胶囊模型,该模型将池化层的标量计算改为向量计算,用神经元向量代替传统卷积神经网络的单个神经元节点,从而确保更多信息不丢失,该神经元向量就是“胶囊”(Capsule)。本文模型是在胶囊模型的基础上构建的,该模型经过BiGRU和胶囊模型分别提取到文本的全局和局部特征,最后使用sigmoid分类器输出标签。
2.1 LSTM模块
循环神经网络(RNN)是一种用于处理序列数据的神经网络。标准的RNN结构中有重复的神经网络模块,以链式的形式存在。这个重复模块只有单一神经网络层,因此RNN在处理长时间依赖会出现梯度消失和梯度爆炸的问题。为此,Graves等人[21]提出了长短时记忆网络(Long Short-Term Memory,LSTM)。LSTM模型在RNN的基础上加入了记忆单元和门控机制,使其可以选择性的记住或遗忘信息,从而使时间序列上的记忆信息可控,具备长期记忆功能,在更长的序列中有更好的表现。LSTM的重复模块有4个神经网络层,以一种非常特殊的方式进行信息的交互,每个LSTM模块都具有记忆能力。一个LSTM重复模块如图2所示。

图2 LSTM模块Fig.2 LSTM module
LSTM重复模块的神经网络计算公式如下:

其中,it、ft、ot分别表示输入门、遗忘门、输出门;x、h、c表示输入层、隐藏层、记忆单元;W是权重矩阵;b是偏置向量。
单向LSTM只能提取输入文本上文特征,而不能采集到下文的文本特征,为了能够得到文本全局的语义信息,Schuster等人[22]提出了双向循环神经网络。将单向网络结构变为双向网络结构,在一定程度上解决了梯度爆炸或梯度消失问题,并且利用当前词的上下文信息提取出输入文本的全局特征表示。将前后2个输出向量,得到最终提取的文本特征向量ht,如式(7):

2.2 BiGRU模块
GRU可以看做LSTM的一种变体,2014年由Cho等人[23]提出。将LSTM中隐藏状态和细胞状态合并成一种状态,相比LSTM的模型要简单,参数更少、更容易收敛,缩短了训练时间,常用来构建大训练量的模型。GRU首先读取词嵌入向量xt以及隐藏层状态向量ht-1后,经过门控,计算产生输出向量和隐藏层状态向量ht。 计算公式如下:

其中,σ是sigmoid函数;zt是一个更新门,控制信息流入下一个时刻;rt是一个重置门,控制信息丢失,二者共同决定隐藏状态的输出。本文所使用的BiGRU结构如图3所示。

图3 BiGRU结构Fig.3 BiGRU structure
2.3 Capsule模块
胶囊网络(CapsNet)的创新,在于提出了输入是向量,输出也是向量的方法。传统的卷积神经网络通过池化层来获取文本的局部特征,但在池化层的操作过程中会造成信息的损失,降低了模型的效率,难以有效地进行编码,且缺乏文本表达能力。胶囊网络中使用神经元向量代替传统神经网络的单个神经元节点,该神经元向量就是所谓的“胶囊”(Capsule)。通过动态路由(Dynamic Routing)训练神经网络,自动的学习单词之间存在的联系,实现向量的信息传递,不仅获取单词在文本中的位置信息,还可以捕获文本的局部空间特征。Capsule中的激活向量是某个类别特定实体的特征表示,对每个不同的类别,输出不同的向量。向量的模长表示属于该类别的概率,用激活向量的方向表征对应实例的参数。在传统的神经网络中,一般选择Sigmoid、Relu等作为激活函数,但在胶囊网络中提出了新的激活函数Squashing。 一个Capsule结构如图4所示。计算方法如式(12)-式(16)所示。

图4 Capsule结构Fig.4 Capsule structure

其中,u为上一层的胶囊输出;cij为耦合系数,用来预测上一层胶囊和下一层胶囊之间的相似性;sj为squashing函数的输入;W为变换矩阵参数;vj为输出向量;bij的初始值设置为0。
3 实验结果及分析
3.1 实验数据集
为了验证模型的有效性,实验采用今日头条2018新闻标题多标签语料数据集,该数据集共包含2 914 000条新闻标题1 070个标签。取其中23 677条新闻标题作为训练集,5 261条新闻标题作为测试集。
3.2 实验环境及参数设置
本文的实验环境为linux操作系统openSUSELeap42.3,intel(R)Core(TM)i5-7500的CPU,GeForce RTX 2080Ti的GPU;编程语言为python3.6,基于Keras框架,TensorFlow后端实现。为了提高训练的效率,实验模型参数设置为:句子最大长度为50,patience为5,batch_size为32,dropout率为0.5,BiGRU隐藏层维数为256,胶囊数量为32,实验最大迭代次数为20。
3.3 实验评价指标
在多标签文本分类中,一般采用sigmoid函数作为输出层的激活函数,使用二分类交叉熵函数(binary_crossentropy,BCE)作为损失函数。即将最后分类层的每个输出节点使用sigmoid激活函数激活,然后对每个输出节点和对应的标签计算交叉熵损失函数。公式如下:
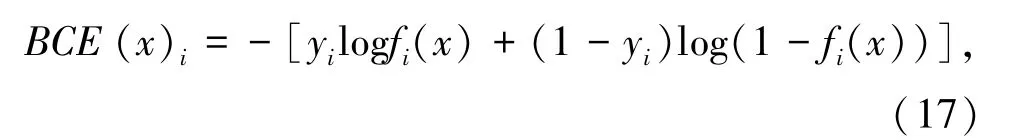
其中,x为输入;C为分类类别数;i属于[1,C];yi为第i个类别对于的真实标签。
本文采用的准确率(accuracy)是keras中的top_k_categorical_accuracy。准确率的计算公式如下:

其中,T代表正确分类的文本数量;F代表错误分类的文本数量;N代表属于该类但未被分到该类别的文本数量。accuracy的计算公式,是得到预测对的样本数与总样本数的比值。categorical_accuracy要求:样本在真值类别上的预测分数,是所有类别预测分数的最大值才算预测正确。不同的是,accuracy针对的是真实标签(y_true)和预测标签(y_pred),都为具体标签的情况,而categorical_accuracy针对的是y_true为one-hot标签,y_pred为向量的情况。对于top_k_categorical_accracy来说就是计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确。
假设有4个样本,其y_true为[[0,0,1],[0,1,0],[0,1,0],[1,0,0]],y_pred为[[0.1,0.6,0.3],[0.2,0.7,0.1],[0.3,0.6,0.1],[0.9,0,0.1]]。则categorical_accuracy计算方法为:
(1)将y_true转 为 非onehot的 形 式,即y_true_new=[2,1,1,0]。
(2)将y_pred转为标量标签。其原理是:选取预测向量中最大值所在索引位置作为预测标签,即得到y_pred_new=[1,1,1,0]。
(3)将y_true_new和y_pred_new代入公式(18)中计算,得到最终的categorical_accuracy为75%。
top_k_categorical_accuracy的计算方法与k息息相关。将y_pred转为标量标签的原理是:选取预测向量中最大k个值所在索引位置作为预测标签,top_k_categorical_accuracy具体计算方法为:
(1)将y_true转 为 非onehot的 形 式,即y_true_new=[2,1,1,0]。
(2)计算y_pred的top_k的label。如k=2时,y_pred_new=[[0,1],[0,1],[0,1],[0,2]]。
(3)根据每个样本的真实标签是否在预测标签的top_k内,来统计准确率。以上述4个样本为例,2不在[0,1]内,1在[0,1]内,1在[0,1]内,0在[0,2]内,4个样本总共预测对了3个。因此,k=2时top_k_categorical_accuracy=75%。
本文使用的数据集的标签数有1 070类,每个样本的标签数多且不定,因此将k设置为33。(在实验结果与分析中,将top_k_categorical_accuracy简写为tk-acc。)
3.4 实验结果与分析
今日头条2018新闻标题多标签语料数据集多标签文本分类结果见表1。
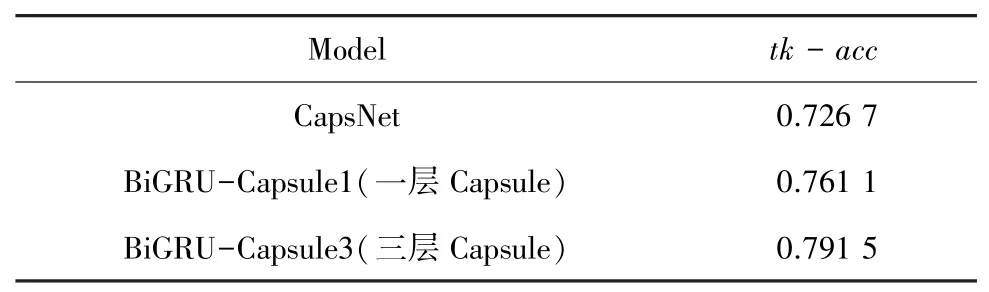
表1 多标签文本分类结果Tab.1 Multi-label text classification results
本文实验的主要模型是基于胶囊网络中的capsule,且在实验过程中发现,叠加多层胶囊能达到较好的效果。因此,设置CapsNet模型和一层胶囊模型与本文模型做对比实验。由实验结果可见,本文实验模型效果最好。其准确率随着迭代次数的变化曲线如图5所示。BiGRU-Capsule模型对比CapsNet模型和BiGRU-Capsule1,在准确率上分别提升了3.48%、3.04%。证明与只能获取局部特征的CapsNet模型相比,本文实验模型的效果更佳。CapsNet模型平均训练一轮的时间约279 s,BiGRUCapsule1模型平均训练一轮的时间约376 s,BiGRU-Capsule3模型平均训练一轮的时间约110 s,可见本文模型的训练时间比其它两个模型的训练时间更短。实验结果表明,本文实验模型不仅提高了模型的准确率,同时加快了训练速度。

图5 模型准确率变化曲线图Fig.5 The model accuracy rate change curve
4 结束语
本文提出了一种基于BiGRU-Capsule的模型,用于多标签文本分类研究。利用BiGRU对词的上下文信息提取文本的全局特征,Capsule有效提取文本的局部特征。实验结果表明,本文提出的模型在F1指标上优于对比模型,有效地提升了多标签文本分类的性能。然而,在多标签文本分类领域,仍然有许多问题值得探索,因此下一步工作将研究预训练模型的输出特征与本文设计的模型输出特征进行各种融合操作。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
妇女之友(2018年8期)2018-09-17
软件(2017年6期)2017-09-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学阅读指南·高年级版(2009年3期)2009-03-27
家庭医药(2009年1期)2009-02-05
