
改进的GM(1,1)模型公路货物运输量预测①
2021-10-30 07:27袁志兵
建材技术与应用 2021年5期
□□ 袁志兵
(义乌工商职业技术学院,浙江 金华 322000)
引言
货物运输量预测精度的高低对运输管理部门在路网规划及运输政策的制定方面极为重要,准确预测货物运输量不仅可以制定合理的发展规划和提供合理的论据,还可以对公共交通资源配置进行合理性指导。国内外对货物运输量的预测从未间断过,通过对货物运输量预测的研究进行分析发现,预测方法主要分为两大类:一是以传统的数学方法为基础的预测模型,时间序列预测模型[1-2](包括平滑预测法、ARMA模型预测法)、回归模型[3-5](包括非线性回归和线性回归)、灰色预测模型[6-7];另一类则是基于人工神经网络的预测方法[8-9](BP神经网络、遗传神经网络、小波神经网络等)。
时间序列法需要大量的历史数据且预测精度偏低,回归模型需要较多解释变量并确定准确的函数形式。神经网络预测则是适用于非线性、复杂的情形下,且需要设定较多参数,训练过程也较为繁杂,在货运量预测中效果不佳[10]。传统的灰色预测模型适用于“贫信息、小样本”的不确定性系统,但在背景值精度不高的情况下会造成模型精度下降,本文拟通过建立二次函数重构背景值来改进GM(1,1)模型。
1 传统GM(1,1)模型
GM(1,1)模型预测是采用累加的方式使样本具有指数变化规律,继而使用一阶微分方程对其求解,再将结果逐步减去获得最终值,即为灰色预测结果,以对未来时间段的数值进行预测[11]。
(1)
z(1)为x(1)的相邻均值生成序列:
(2)
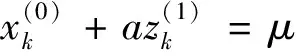
(3)
式中:α、μ——待辨识参数。
(4)
(5)
(6)
由灰色预测理论可知,α为系统发展系数,数据变化关系则由μ值来反映。
(7)
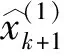
k=1,2,…,n
(8)
2 GM(1,1)模型改进
2.1 背景值优化
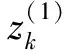
(9)
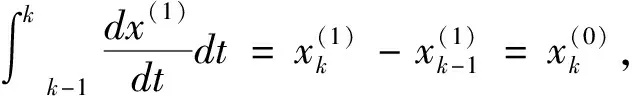
2.2 构建背景值函数
(2)确定累加序列函数分布类型。
(3)采用spss软件对累加序列进行分析,构建相应回归方程,对回归方程进行参数有效性分析。
3 模型验证与应用
3.1 建立模型
根据国家统计局公布的数据,选取2008年到2019年全国公路货运总量为样本量,其数值见表1(记2008年为时间序列1,依次标号)。将前9个数据作为灰色预测模型的原始时间序列数据,对后3组数据进行预测。对传统灰色预测模型记为GM0(1,1)模型,对背景值优化后的预测模型记为GM1(1,1)。

表1 2008~2019年全国公路货运总量 亿t
对前9组货运量进行累加求和,得到累加序列的货运量,其数值如图1所示。
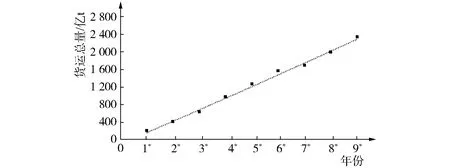
图1 连续9组时间序列累积货运量
根据前述相邻年份货运总量关系曲线变化趋势,拟采用指数、对数以及二次函数等关系进行年份和货运总量的拟合分析,拟合模型见表2。
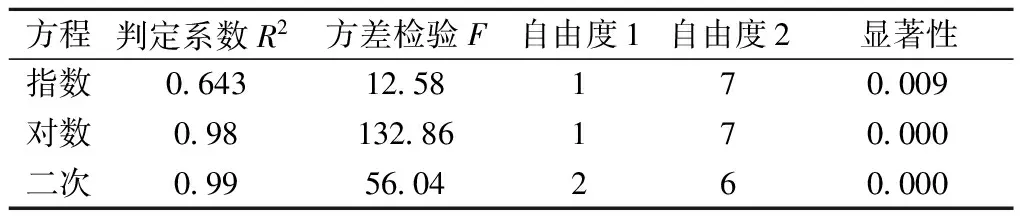
表2 相邻时间序列与货运总量关系模型
根据表2的分析结果,相邻时间序列与货运总量的对数和二次方程拟合效果都较好,考虑对数函数变量较少且显著性小,故采用对数方程描述相邻时间序列与货运总量的相关关系。拟合函数见式(10):
Y=4.12X2+213.1X-90.31
(10)
式中:Y——相邻年份货运累积量;
X——预测年份。
根据相邻年份货运累积货运量与预测年份关系可得到参数矩阵:
根据灰色预测理论以及权重函数可得到货运量预测模型GM1(1,1)为:
(11)
3.2 模型验证
通过改进的GM(1,1)货运量预测模型,对后3个时间序列进行预测及精度检验,结果见表3。
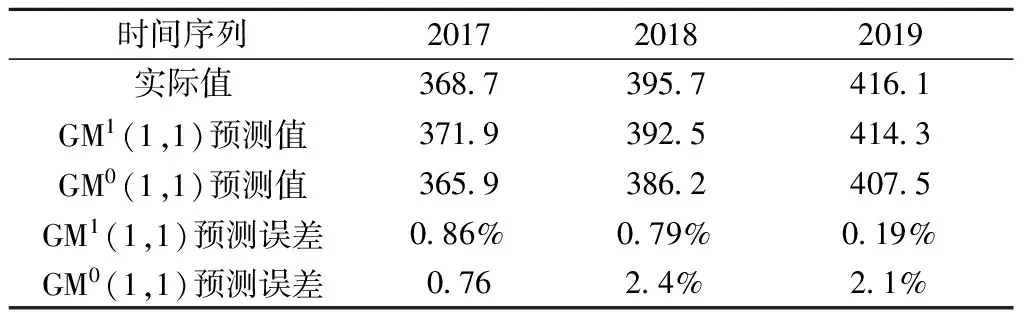
表3 2017~2019年全国公路货运量预测值与实际值比较
精度检验采用后验差检验,是用后验差比和小概率误差进行检验的一种模型检验方法。后验差之比记为:
(12)
原始序列方差为:
(13)
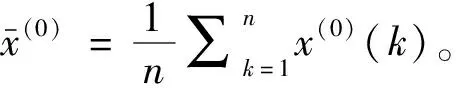
残差均方差为:
(14)
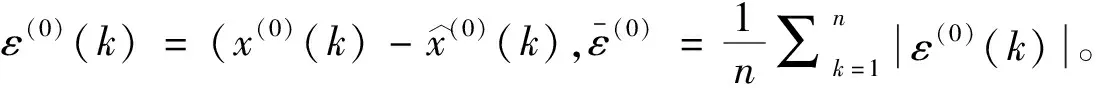
4 结语
(1)货物运输量虽有着不确定因素的影响但其具有典型的灰色性质,通过背景值优化的GM(1,1)模型建立,整个运输量系统具有着稳定的可预测性,可为我国运输政策制定及行业的发展夯实基础。
(2)基于背景值优化的GM(1,1)预测模型对2017~2019年货运量进行预测,预测结果显示货运量分别为371.9、392.5、414.3(单位为亿t),通过精度检验,模型效果较好,具有统计学意义。
(3)因本文调研样本量有限,2020年疫情影响下货运量也会随之变化。需在进一步的研究中扩充样本量,使得预测值更接近实际值。
猜你喜欢
小猕猴智力画刊(2021年11期)2021-11-28
大飞机(2021年4期)2021-07-19
人民交通(2018年16期)2018-03-27
大陆桥视野(2017年13期)2017-12-23
儿童故事画报·自然探秘(2016年4期)2016-06-24
科学启蒙(2016年5期)2016-05-10
上海预防医学(2014年2期)2014-06-03
